










写在前面
2016年天猫双十一当天,零点的倒计时话音未落,52秒交易额冲破10亿。随后,又迅速在0时6分28秒,达到100亿!每一秒开猫大屏上的交易额都在刷新,这种时实刷新的大屏看着感觉超爽。天猫这个大屏后面的技术应该是使用流计算,阿里使用Java将Storm重写了,叫JStrom(https://github.com/alibaba/jstorm),最近学习SparkStream和Kafka,可以简单模仿一下这个时实计算成交额的过程,主要目的是实际运用这些技术,也了解一下技术的运用场景,加深对技术的理解。

实时计算模型
下图所示为通用SparkStream时实计算模型,主要分为三部分
数据源
我们这里的数据源选用了Kafka,关于Kafka的安装与使用说明可以参考这里https://kafkadoc.beanmr.com/SparkStream计算
SparkStream是实时计算的核心,这们这里也是近时实计算,选择一个时间窗口,对时间窗口中的数据做离线计算。数据落地
SparkStream算好的结果可以存HDFS/Mysql/Redis等等,我们这里对商品销售额计算过程有涉及累加,所以选择了Redis

业务模型介绍
我们模仿一个电商系统,每时每刻都有订单成交,每一笔成交的数据以一个事件发送到Kafka中,SparkStream每一分中从Kafka中读取一次数据,计算一分钟内每个商品的销售额,然而写入Redis,并在Redis中累加每分钟的数据,Redis中主要存三种结果数量,从开始到当前总销售额、从开始到当前每个商品销售额、上一分钟每个商品的销售额
Kafka生产者,模拟每时每刻订单交易
object OrderProducer {
def main(args: Array[String]): Unit = {
//Kafka参数设置
val topic = "order"
val brokers = "127.0.0.1:9092"
val props = new Properties()
props.put("metadata.broker.list", brokers)
props.put("serializer.class", "kafka.serializer.StringEncoder")
val kafkaConfig = new ProducerConfig(props)
//创建生产者
val producer = new Producer[String, String](kafkaConfig)
while (true) {
//随机生成10以内ID
val id = Random.nextInt(10)
//创建订单成交事件
val event = new JSONObject();
//商品ID
event.put("id", id)
//商品成交价格
event.put("price", Random.nextInt(10000))
//发送信息
producer.send(new KeyedMessage[String, String](topic, event.toString))
println("Message sent: " + event)
//随机暂停一段时间
Thread.sleep(Random.nextInt(100))
}
}
}生产者输出结果:
Message sent: {"price":3959,"id":6}
Message sent: {"price":1579,"id":0}
Message sent: {"price":857,"id":6}
Message sent: {"price":8440,"id":1}
Message sent: {"price":6873,"id":6}
Message sent: {"price":6202,"id":2}
Message sent: {"price":8403,"id":6}
Message sent: {"price":7866,"id":2}
Message sent: {"price":9441,"id":5}
Message sent: {"price":6880,"id":4}
Message sent: {"price":4572,"id":5}
Message sent: {"price":509,"id":3}
Message sent: {"price":7526,"id":0}上述代码主要模拟一家店铺有十件商品,ID从0到9,每隔一小段随机时间成交一单,成交价格以分为单位,每成交一笔就像Kafka中发送一个消息,用这个生产者模拟线上的真实交易,在实际生产中成交数据可以从日志中获取。
Kafka消费者,SparkStream时实计算
object OrderConsumer {
//Redis配置
val dbIndex = 0
//每件商品总销售额
val orderTotalKey = "app::order::total"
//每件商品上一分钟销售额
val oneMinTotalKey = "app::order::product"
//总销售额
val totalKey = "app::order::all"
def main(args: Array[String]): Unit = {
// 创建 StreamingContext 时间片为1秒
val conf = new SparkConf().setMaster("local").setAppName("UserClickCountStat")
val ssc = new StreamingContext(conf, Seconds(1))
// Kafka 配置
val topics = Set("order")
val brokers = "127.0.0.1:9092"
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers,
"serializer.class" -> "kafka.serializer.StringEncoder")
// 创建一个 direct stream
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
//解析JSON
val events = kafkaStream.flatMap(line => Some(JSON.parseObject(line._2)))
// 按ID分组统计个数与价格总合
val orders = events.map(x => (x.getString("id"), x.getLong("price"))).groupByKey().map(x => (x._1, x._2.size, x._2.reduceLeft(_ + _)))
//输出
orders.foreachRDD(x =>
x.foreachPartition(partition =>
partition.foreach(x => {
println("id=" + x._1 + " count=" + x._2 + " price=" + x._3)
//保存到Redis中
val jedis = RedisClient.pool.getResource
jedis.select(dbIndex)
//每个商品销售额累加
jedis.hincrBy(orderTotalKey, x._1, x._3)
//上一分钟第每个商品销售额
jedis.hset(oneMinTotalKey, x._1.toString, x._3.toString)
//总销售额累加
jedis.incrBy(totalKey, x._3)
RedisClient.pool.returnResource(jedis)
})
))
ssc.start()
ssc.awaitTermination()
}
}消费者每分钟输出
id=4 count=3 price=7208
id=8 count=2 price=10152
id=7 count=1 price=6928
id=5 count=1 price=3327
id=6 count=3 price=20483
id=0 count=2 price=9882
id=2 count=2 price=9191
id=3 count=2 price=8211
id=1 count=3 price=9906Redis客户端
object RedisClient extends Serializable {
val redisHost = "127.0.0.1"
val redisPort = 6379
val redisTimeout = 30000
lazy val pool = new JedisPool(new GenericObjectPoolConfig(), redisHost, redisPort, redisTimeout)
lazy val hook = new Thread {
override def run = {
println("Execute hook thread: " + this)
pool.destroy()
}
}
sys.addShutdownHook(hook.run)
def main(args: Array[String]): Unit = {
val dbIndex = 0
val jedis = RedisClient.pool.getResource
jedis.select(dbIndex)
jedis.set("test", "1")
println(jedis.get("test"))
RedisClient.pool.returnResource(jedis)
}
}
Redis结果
上一分钟商品销售额,有了这个数据就可以做成动态的图表展示时实交易额了
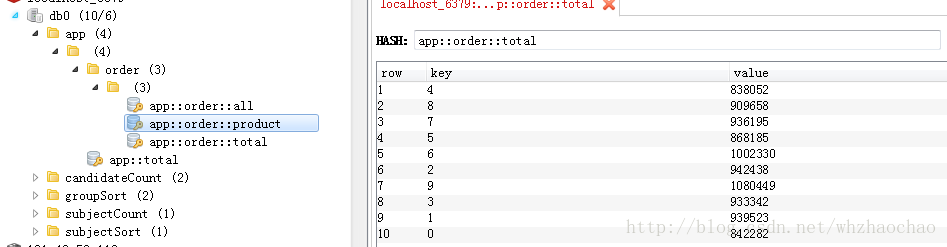
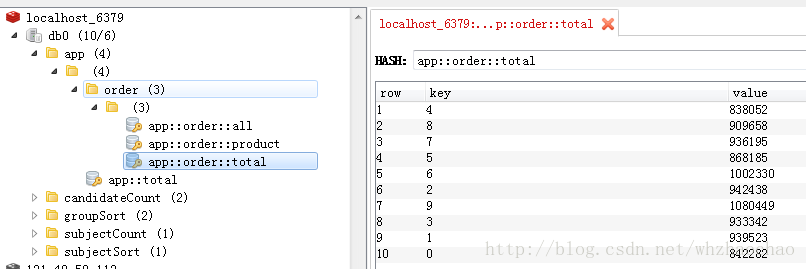
每件商品总销售额
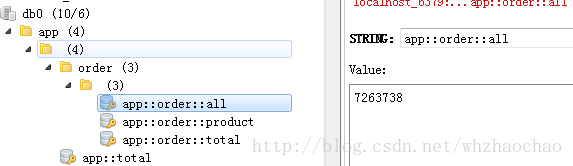
总销售额,这就是天猫大屏上的1111亿了
完整代码地址
原文地址:http://blog.csdn.net/whzhaochao/article/details/77717660
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











