







最近在跟着赖博做一个图片配诗的小pro,需要用到kNN算法。
先转一篇左耳朵兔子的一篇文章K Nearest Neighbor算法
k-Means算法,主要用来聚类,将相同类别的样本点聚为同一类。
kNN算法,主要用来归类,给定一个待分类的样本点,通过计算样本空间中与自己最近的K个样本来判断这个待分类数据属于哪个分类。
所以这里一个待分类的样本点的类别主要由最近的K个样本中最多的类别,下面这个图是经典的图,说明K的选择不懂,对最终归类结果的影响。
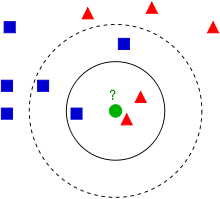
- 如果k=3,最近的3个点中有两个红色一个蓝色,绿色的这个待分类点属于红色类别。
- 如果k=5,最近的5个点中有两个红色三个蓝色,绿色的这个待分类点属于蓝色类别。
Algorithm
上述中k如果取1的话,则待分类点直接被赋予最近点的类别。
Distance Measure
常见的距离公式有以下三种

对于离散变量而言,需要使用Hamming Distance

Distance Metrics in Matlab
考虑一个 mx−by−n 的数据X、Y,将它们看成 m 个 1−by−n 个行向量, xs 和 yt 。
- Euclidean distance
d2st=(xs−yt)(xs−yt)′ - Standardized Euclidean distance
d2st=(xs−yt)V−1(xs−yt)′
V是一个n*n的对角阵,对角线的元素是权重的倒数。 - Mahalanobis distance
d2st=(xs−yt)C−1(xs−yt)′
C是一个方差矩阵。 - City block metric
dst=∑j=1n|xsj−ytj| - Minkowski metric
dst=∑j=1n|xsj−ytj|−−−−−−−−−−−⎷p
更多的metric可以参考online decumentation
选择一个最优k的最好方法是观察样本数据。一般来说,虽然一个较大的K会减少噪声的影响,得到较准确的结果,但是并不是说K较大就有保证。
有两个方法保证类别的判定,
- 第一个方法是在一个独立的数据集上测试k的有效性,经验而言,K的选择一般是3-10.
- 第二个方法可以滤除一些错误的待测点,检查,,
Example
我们现在有一堆样本,每个样本包含两个数值变量——age和loan,label只有两类——Default和Non-Default。对于一个未知的样本(Age=48,loan=142000),我们使用kNN来对它进行分类。
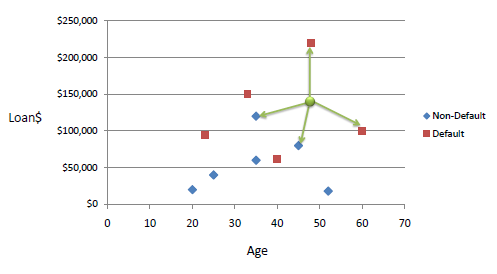
使用欧式距离统计
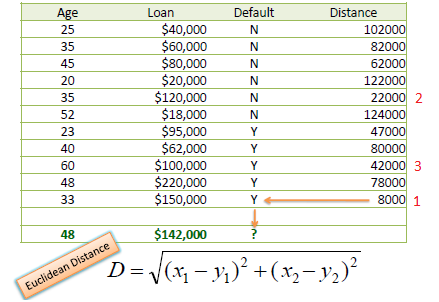
当K=3时,有两个Default = Y 以及一个Default=N,所以未知样本的label是Default = Y
Standardized Distance
为了避免不同样本数据中不同尺度的影响,可以将数据集中归一化。
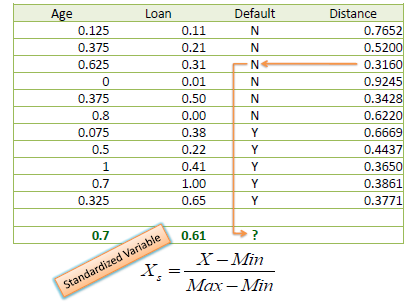
归一化的方法
上文主要来自这个tutorialKNN















 2085
2085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









