







1.概念:
Dropout是解决模型过拟合的一种关键技术。通过Dropout可以防止网络单元中的过度适应问题。Dropout的实现过程是:在训练期间,从大量的不同程度的“稀疏”网络中提取样本数据,在测试阶段,通过简单地使用具有较小权重的单个“非稀疏”网络,从而可以很容易地近似平均所有这些“稀疏”网络的预测效果。
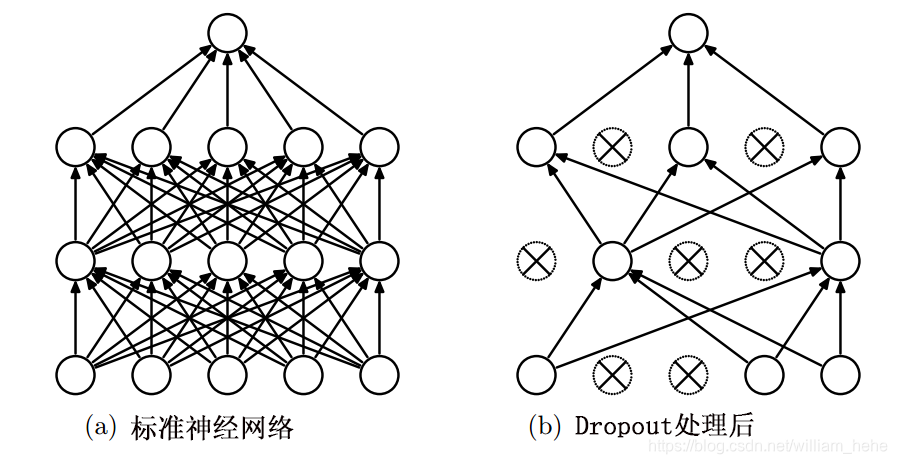
2.代码实现:
import numpy as np
def dropout(x, keep_prob):
d3 = (np.random.rand(*x.shape) < keep_prob) #dropout
print(d3)
x = np.multiply(x,d3)
print(x)
x = x/keep_prob #inverted dropout
return x
a3 = np.asarray([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=np.float32)
a3 = dropout(a3,0.8)
print(a3)3.小结:
Dropout通过随机删除神经网络中的神经单元,从而使得网络不依赖于任何一个特征,从而产生收缩权重的平方范数的效果。Dropout的一大缺点是损失函数不再被明确定义。因为每次迭代都会随机移除一些节点,因此很难检查梯度是否下降的性能。因此,在使用Dropout时,可先令超参数keep_prob=1,然后保证损失函数是单调递减的,然后再调整keep_prob的超参数。
参考文献:
1. Dropout: A Simple Way to Prevent Neural Networks from Overfitting
2.DeepLearning.ai
注:本文属于个人理解,若有错误,欢迎指正!














 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









