







正则化–《机器学习》课程笔记
过拟合问题
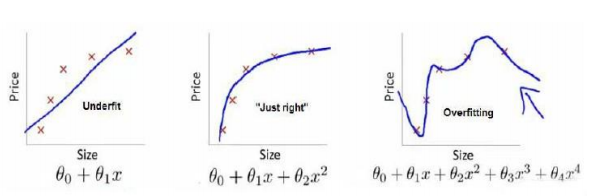
如图,第一个就是一个欠拟合(underfitting)的实例,第三个就是一个过拟合的实例(overfitting),往往过拟合和欠拟合都不能很好地反映逻辑回归以及线性回归问题的情况。
如图:
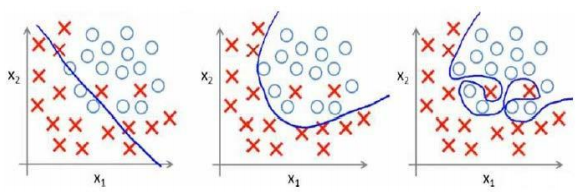
面对这种问题,我们可以采取两种方法来进行解决:
- 丢弃一些不能帮助我们正确解决问题的特征,或者是手工选择保留哪些特征,使用模型选择的算法来帮忙(如PCA–主成分分析算法)
- 正则化,保留所有的特征,但是减少参数的大小
(思考为何这种方法可以有效地避免过拟合的现象)
以下我们使用正则化的方法来解决过拟合的现象:
代价函数
由于要减小高阶项的系数,因此可以使用如下代价函数:
minθ12m∑mi=1((hθ(x(i))−y(i))2+1000θ23+10000θ24)
相当于我们对除
θ0
以外的参数进行惩罚。
于是有代价函数:
ȷ(θ)=12m[∑mi=1((hθ(x(i))−y(i))2+λ∑nj=1θ2j)]
其中, λ 称为正则化参数(Regularization Parameter), 如果其过大,那么会将所有 θ 都最小化,那么会呈现出一条 y=θ0 的直线,但是如果正则化参数过小,那么又不能很好地解决过拟合的问题。
我们如何将正则化的思想引入到逻辑回归和线性回归之中呢,下面就进行详细的介绍:
正则化线性回归
使用梯度下降算法对于含有正则化参数的代价函数进行初始化。
算法描述:
repeat until convergence {
θ0:=θ0−α1m∑m1(hθ(x(i))−y(i))x(i)0
θj:=θj−α1m∑m1((hθ(x(i))−y(i))x(i)j+λmθj)
for i=1→n
}
对 θj 进行整理得到:
θj:=θj(1−λmθj)−α1m∑m1((hθ(x(i))−y(i))x(i)j
若使用正规化方程来求解,则为:
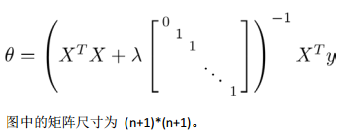
(细致分析其中各个参数值之间的含义)
正则化逻辑回归模型
代价函数为:
ȷ(θ)=−1m[∑m(i=1)y(i) log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i))]+λ∑nj=1θ2j
使用梯度下降算法可以得到:
repeat until convergence {
θ0:=θ0−α1m∑m1(hθ(x(i))−y(i))x(i)0
θj:=θj−α1m∑m1((hθ(x(i))−y(i))x(i)j+λmθj)
for i=1→n
}
虽然形式上和正则化线性回归一样,但是这里是 hθ(x)=g(θTx) 的结果。















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









