







写这篇文章,主要是因为最近有个课题设计,里面用的字符串匹配。
学习后缀树之前,先了解一下Trie这个数据结构Trie是一种搜索树,可用于存储并查找字符串。Trie每一条边都对应一个字符。在Trie中查找字符串S时,只要按顺序枚举S的各个字符,从Trie的根节点开始选择相应的边走,如果枚举完的同时恰好走到Trie树的叶子节点,说明S存在于Trie中。如果未到达叶子节点,或者枚举中未发现相应的边,则S没有被包含在Trie中。


后缀树就是一种压缩后的Trie树。
比如 S:banana,对S建立后缀树。
首先给出S的后缀们
0:banana
1:anana
2:nana
3:ana
4:na
5:a
6:空
为了更清楚的表示后缀,我们在后缀的后面加上$
0:banana$
1:anana$
2:nana$
3:ana$
4:na$
5:a$
6:$
然后对其进行分类:
5: a$
3: ana$
1: anana$
0: banana$
4: na$
2: nana$
6: $

后缀树的应用:
example 1:在树中查找an(查找子字符串)
example 2:统计S中出现字符串T的个数
没出现一次T,都对应着一个不同的后缀,而这些后缀们又对应着同一个前缀T,因此这些后缀必定都属于同一棵子树,这棵子树的分支数就是T在S中出现的次数。

example 3:找出S中最长的重复子串,所谓重复子串,是指出现了两次以上
首先定义节点的 ”字符深度“ = 从后缀树根节点到每个节点所经过的字符串总长。找出有最大字符深度的非叶节点。则从根节点到该非叶节点所经过的字符串即为所求。

后缀树的存储:
为了节省空间,我们不在边上存储字符串,而是存储该字符串在原串中的起止位置。空间复杂度O(n)

后缀树的构造:
最简单的方法,使用Trie的构造方法,时间复杂度为O(n^2)
后缀树也可以在O(n)的时间复杂度内构造,但比较复杂
如
基本思路:先向后缀树中插入最长的后缀串(S本身),其次插入次长的后缀串,以此类推,最后插入空串。
定义后缀链接(Suffix Link)=从节点A指向节点B的指针,B所表示的子串是A所表示的子串的最长后缀。既,根节点到A所经过的字符串s=aw,则从根节点到B所经过的字符串为w。

算法所用符号描述:

后缀树的构造,算法流程:
1)定义SL(root)=root,首先插入S,此时后缀树仅有两个节点。
2)设已经插入了S(i),现在要插入S(i+1),分两种情况讨论:
1:P(S(i))在插入之前已经存在,(如,na,ana,a是na的parent),则P(S(i))有后缀链接,令u=SL( P(S(i)) ),从u开始沿着树往下查找,在合适的地方插入
2: P(S(i))是插入S(i)过程中产生的,此时G(S(i))必定存在并有后缀链接,比如(na,ana,bana) ,令u=SL( G(S(i)) ),w=W( G(S(i)), P(S(i)) ).从u开始,对w进行快速定位,并找到节点v(v可能需要分割边来得到)。令SL( G(S(i)) )指向v,从v开始沿着树往下查找,在合适的地方插入新的节点
不断重复以上步骤,即可完成后缀树的构造。

那后缀树同最长回文有什么关系呢?我们得先知道两坨坨简单概念:
最低共有祖先,LCA(Lowest Common Ancestor),也就是任意两节点(多个也行)最长的共有前缀。比如下图中,节点7同节点10的共同祖先是节点1与借点,但最低共同祖先是5。 查找LCA的算法是O(1)的复杂度,这年头少见。代价是需要对后缀树做复杂度为O(n)的预处理。
广 义后缀树(Generalized Suffix Tree)。传统的后缀树处理一坨单词的所有后缀。广义后缀树存储任意多个单词的所有后缀。例如下图是单词XMADAMYX与XYMADAMX的广义后缀 树。注意我们需要区分不同单词的后缀,所以叶节点用不同的特殊符号与后缀位置配对。
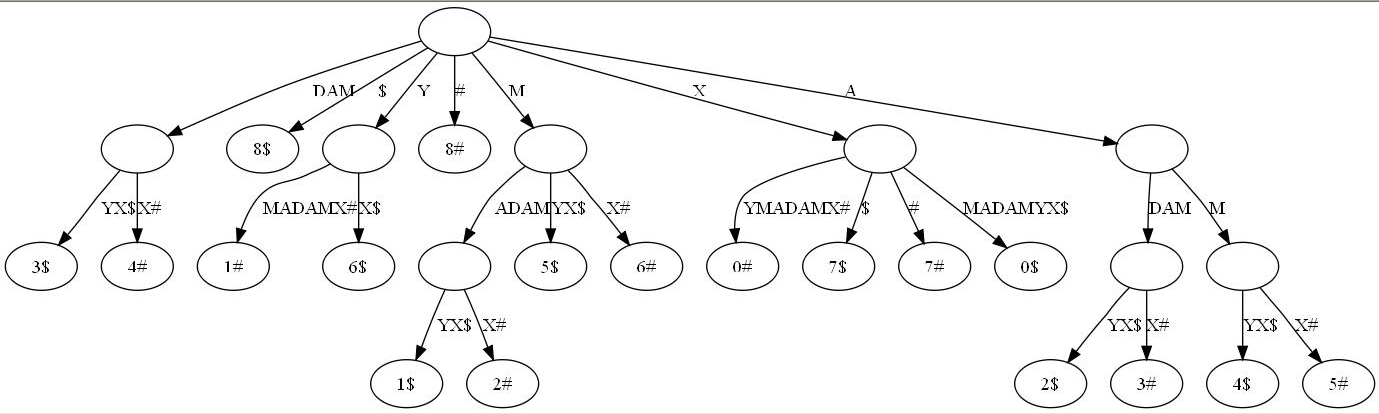
有了上面的概念,查找最长回文相对简单了。思维的突破点在于考察回文的半径,而不是回文本身。所谓半径,就是回文对折后的字串。比如回文MADAM 的半径为MAD,半径长度为3,半径的中心是字母D。显然,最长回文必有最长半径,且两条半径相等。还是以MADAM为例,以D为中心往左,我们得到半径 DAM;以D为中心向右,我们得到半径DAM。二者肯定相等。因为MADAM已经是单词XMADAMYX里的最长回文,我们可以肯定从D往左数的字串 DAMX与从D往右数的子串DAMYX共享最长前缀DAM。而这,正是解决回文问题的关键。现在我们有后缀树,怎么把从D向左数的字串DAMX变成后缀 呢?到这个地步,答案应该明显:把单词XMADAMYX翻转就行了。于是我们把寻找回文的问题转换成了寻找两坨后缀的LCA的问题。当然,我们还需要知道 到底查询那些后缀间的LCA。这也简单,给定字符串S,如果最长回文的中心在i,那从位置i向右数的后缀刚好是S(i),而向左数的字符串刚好是翻转S后 得到的字符串S‘的后缀S'(n-i+1)。这里的n是字符串S的长度。有了这套直观解释,算法自然呼之欲出:
预处理后缀树,使得查询LCA的复杂度为O(1)。这步的开销是O(N),N是单词S的长度
对单词的每一位置i(也就是从0到N-1),获取LCA(S(i), S(N-i+1)) 以及LCA(S(i+1), S(n-i+1))。查找两次的原因是我们需要考虑奇数回文和偶数回文的情况。这步要考察每坨i,所以复杂度是O(N)
找到最大的LCA,我们也就得到了回文的中心i以及回文的半径长度,自然也就得到了最长回文。总的复杂度O(n)。
用上图做例子,i为3时,LCA(3$, 4#)为DAM,正好是最长半径。当然,这只是直观的叙述。
这篇帖子只大致描述了后缀树的基本思路。要想写出实用代码,至少还得知道下面的知识:
创建后缀树的O(n)算法。至于是Peter Weiner的73年年度最佳算法,还是Edward McCreight1976的改进算法,还是1995年E. Ukkonen大幅简化的算法,还是Juha Kärkkäinen 和 Peter Sanders2003年进一步简化的线性算法,各位老大随喜。
实现后缀树用的数据结构。比如常用的子结点加兄弟节点列表,Directed
优化后缀树空间的办法。比如不存储子串,而存储读取子串必需的位置。以及Directed Acyclic Word Graph,常缩写为黑哥哥们挂在嘴边的DAWG。
- 2,后缀树的用途,总结起来大概有如下几种
(1). 查找字符串o是否在字符串S中。
方案:用S构造后缀树,按在trie中搜索字串的方法搜索o即可。
原理:若o在S中,则o必然是S的某个后缀的前缀。
例如S: leconte,查找o: con是否在S中,则o(con)必然是S(leconte)的后缀之一conte的前缀.有了这个前提,采用trie搜索的方法就不难理解了。
(2). 指定字符串T在字符串S中的重复次数。
方案:用S+’$'构造后缀树,搜索T节点下的叶节点数目即为重复次数
原理:如果T在S中重复了两次,则S应有两个后缀以T为前缀,重复次数就自然统计出来了。
(3). 字符串S中的最长重复子串
方案:原理同2,具体做法就是找到最深的非叶节点。
这个深是指从root所经历过的字符个数,最深非叶节点所经历的字符串起来就是最长重复子串。
为什么要非叶节点呢?因为既然是要重复,当然叶节点个数要>=2。
(4). 两个字符串S1,S2的最长公共部分
方案:将S1#S2$作为字符串压入后缀树,找到最深的非叶节点,且该节点的叶节点既有#也有$(无#)。
- 一个C++的实现:
- //
// Suffix tree creation
//
// Mark Nelson, updated December, 2006
//
// This code has been tested with Borland C++ and
// Microsoft Visual C++.
//
// This program asks you for a line of input, then
// creates the suffix tree corresponding to the given
// text. Additional code is provided to validate the
// resulting tree after creation.
//
#include <iostream>
#include <iomanip>
#include <cstdlib>
#include <cstring>
#include <cassert>
#include < string>
using std::cout;
using std::cin;
using std::cerr;
using std::setw;
using std::flush;
using std::endl;
//
// When a new tree is added to the table, we step
// through all the currently defined suffixes from
// the active point to the end point. This structure
// defines a Suffix by its final character.
// In the canonical representation, we define that last
// character by starting at a node in the tree, and
// following a string of characters, represented by
// first_char_index and last_char_index. The two indices
// point into the input string. Note that if a suffix
// ends at a node, there are no additional characters
// needed to characterize its last character position.
// When this is the case, we say the node is Explicit,
// and set first_char_index > last_char_index to flag
// that.
//
class Suffix {
public :
int origin_node;
int first_char_index;
int last_char_index;
Suffix( int node, int start, int stop )
: origin_node( node ),
first_char_index( start ),
last_char_index( stop ){};
int Explicit(){ return first_char_index > last_char_index; }
int Implicit(){ return last_char_index >= first_char_index; }
void Canonize();
};
//
// The suffix tree is made up of edges connecting nodes.
// Each edge represents a string of characters starting
// at first_char_index and ending at last_char_index.
// Edges can be inserted and removed from a hash table,
// based on the Hash() function defined here. The hash
// table indicates an unused slot by setting the
// start_node value to -1.
//
class Edge {
public :
int first_char_index;
int last_char_index;
int end_node;
int start_node;
void Insert();
void Remove();
Edge();
Edge( int init_first_char_index,
int init_last_char_index,
int parent_node );
int SplitEdge( Suffix &s );
static Edge Find( int node, int c );
static int Hash( int node, int c );
};
//
// The only information contained in a node is the
// suffix link. Each suffix in the tree that ends
// at a particular node can find the next smaller suffix
// by following the suffix_node link to a new node. Nodes
// are stored in a simple array.
//
class Node {
public :
int suffix_node;
int father;
int leaf_index;
Node() { suffix_node = -1;
father=-1;
leaf_index=-1;}
static int Count;
static int Leaf;
};
//
// The maximum input string length this program
// will handle is defined here. A suffix tree
// can have as many as 2N edges/nodes. The edges
// are stored in a hash table, whose size is also
// defined here.
//
const int MAX_LENGTH = 1000;
const int HASH_TABLE_SIZE = 2179; // A prime roughly 10% larger
//
// This is the hash table where all the currently
// defined edges are stored. You can dump out
// all the currently defined edges by iterating
// through the table and finding edges whose start_node
// is not -1.
//
Edge Edges[ HASH_TABLE_SIZE ];
//
// The array of defined nodes. The count is 1 at the
// start because the initial tree has the root node
// defined, with no children.
//
int Node::Count = 1;
int Node::Leaf = 1;
Node Nodes[ MAX_LENGTH * 2 ];
//
// The input buffer and character count. Please note that N
// is the length of the input string -1, which means it
// denotes the maximum index in the input buffer.
//
char T[ MAX_LENGTH ];
int N;
//
// Necessary forward references
//
void validate();
int walk_tree( int start_node, int last_char_so_far );
//
// The default ctor for Edge just sets start_node
// to the invalid value. This is done to guarantee
// that the hash table is initially filled with unused
// edges.
//
Edge::Edge()
{
start_node = -1;
}
//
// I create new edges in the program while walking up
// the set of suffixes from the active point to the
// endpoint. Each time I create a new edge, I also
// add a new node for its end point. The node entry
// is already present in the Nodes[] array, and its
// suffix node is set to -1 by the default Node() ctor,
// so I don't have to do anything with it at this point.
//
Edge::Edge( int init_first, int init_last, int parent_node )
{
first_char_index = init_first;
last_char_index = init_last;
start_node = parent_node;
end_node = Node::Count++;
Nodes[end_node].father=start_node;
}
//
// Edges are inserted into the hash table using this hashing
// function.
//
int Edge::Hash( int node, int c )
{
return ( ( node << 8 ) + c ) % HASH_TABLE_SIZE;
}
//
// A given edge gets a copy of itself inserted into the table
// with this function. It uses a linear probe technique, which
// means in the case of a collision, we just step forward through
// the table until we find the first unused slot.
//
void Edge::Insert()
{
int i = Hash( start_node, T[ first_char_index ] );
while ( Edges[ i ].start_node != -1 )
i = ++i % HASH_TABLE_SIZE;
Edges[ i ] = * this;
}
//
// Removing an edge from the hash table is a little more tricky.
// You have to worry about creating a gap in the table that will
// make it impossible to find other entries that have been inserted
// using a probe. Working around this means that after setting
// an edge to be unused, we have to walk ahead in the table,
// filling in gaps until all the elements can be found.
//
// Knuth, Sorting and Searching, Algorithm R, p. 527
//
void Edge::Remove()
{
int i = Hash( start_node, T[ first_char_index ] );
while ( Edges[ i ].start_node != start_node ||
Edges[ i ].first_char_index != first_char_index )
i = ++i % HASH_TABLE_SIZE;
for ( ; ; ) {
Edges[ i ].start_node = -1;
int j = i;
for ( ; ; ) {
i = ++i % HASH_TABLE_SIZE;
if ( Edges[ i ].start_node == -1 )
return;
int r = Hash( Edges[ i ].start_node, T[ Edges[ i ].first_char_index ] );
if ( i >= r && r > j )
continue;
if ( r > j && j > i )
continue;
if ( j > i && i >= r )
continue;
break;
}
Edges[ j ] = Edges[ i ];
}
}
//
// The whole reason for storing edges in a hash table is that it
// makes this function fairly efficient. When I want to find a
// particular edge leading out of a particular node, I call this
// function. It locates the edge in the hash table, and returns
// a copy of it. If the edge isn't found, the edge that is returned
// to the caller will have start_node set to -1, which is the value
// used in the hash table to flag an unused entry.
//
Edge Edge::Find( int node, int c )
{
int i = Hash( node, c );
for ( ; ; ) {
if ( Edges[ i ].start_node == node )
if ( c == T[ Edges[ i ].first_char_index ] )
return Edges[ i ];
if ( Edges[ i ].start_node == -1 )
return Edges[ i ];
i = ++i % HASH_TABLE_SIZE;
}
}
//
// When a suffix ends on an implicit node, adding a new character
// means I have to split an existing edge. This function is called
// to split an edge at the point defined by the Suffix argument.
// The existing edge loses its parent, as well as some of its leading
// characters. The newly created edge descends from the original
// parent, and now has the existing edge as a child.
//
// Since the existing edge is getting a new parent and starting
// character, its hash table entry will no longer be valid. That's
// why it gets removed at the start of the function. After the parent
// and start char have been recalculated, it is re-inserted.
//
// The number of characters stolen from the original node and given
// to the new node is equal to the number of characters in the suffix
// argument, which is last - first + 1;
//
int Edge::SplitEdge( Suffix &s )
{
Remove();
Edge *new_edge =
new Edge( first_char_index,
first_char_index + s.last_char_index - s.first_char_index,
s.origin_node );
new_edge->Insert();
Nodes[ new_edge->end_node ].suffix_node = s.origin_node;
first_char_index += s.last_char_index - s.first_char_index + 1;
start_node = new_edge->end_node;
Insert();
Nodes[end_node].father=start_node;
return new_edge->end_node;
}
//
// This routine prints out the contents of the suffix tree
// at the end of the program by walking through the
// hash table and printing out all used edges. It
// would be really great if I had some code that will
// print out the tree in a graphical fashion, but I don't!
//
void dump_edges( int current_n )
{
cout << " Start End Suf First Last String\n";
for ( int j = 0 ; j < HASH_TABLE_SIZE ; j++ ) {
Edge *s = Edges + j;
if ( s->start_node == -1 )
continue;
cout << setw( 5 ) << s->start_node << " "
<< setw( 5 ) << s->end_node << " "
<< setw( 3 ) << Nodes[ s->end_node ].suffix_node << " "
<< setw( 5 ) << s->first_char_index << " "
<< setw( 6 ) << s->last_char_index << " ";
int top;
if ( current_n > s->last_char_index )
top = s->last_char_index;
else
top = current_n;
for ( int l = s->first_char_index ;
l <= top;
l++ )
cout << T[ l ];
cout << "\n";
}
}
//
// A suffix in the tree is denoted by a Suffix structure
// that denotes its last character. The canonical
// representation of a suffix for this algorithm requires
// that the origin_node by the closest node to the end
// of the tree. To force this to be true, we have to
// slide down every edge in our current path until we
// reach the final node.
void Suffix::Canonize()
{
if ( !Explicit() ) {
Edge edge = Edge::Find( origin_node, T[ first_char_index ] );
int edge_span = edge.last_char_index - edge.first_char_index;
while ( edge_span <= ( last_char_index - first_char_index ) ) {
first_char_index = first_char_index + edge_span + 1;
origin_node = edge.end_node;
if ( first_char_index <= last_char_index ) {
edge = Edge::Find( edge.end_node, T[ first_char_index ] );
edge_span = edge.last_char_index - edge.first_char_index;
};
}
}
}
//
// This routine constitutes the heart of the algorithm.
// It is called repetitively, once for each of the prefixes
// of the input string. The prefix in question is denoted
// by the index of its last character.
//
// At each prefix, we start at the active point, and add
// a new edge denoting the new last character, until we
// reach a point where the new edge is not needed due to
// the presence of an existing edge starting with the new
// last character. This point is the end point.
//
// Luckily for use, the end point just happens to be the
// active point for the next pass through the tree. All
// we have to do is update it's last_char_index to indicate
// that it has grown by a single character, and then this
// routine can do all its work one more time.
//
void AddPrefix( Suffix &active, int last_char_index )
{
int parent_node;
int last_parent_node = -1;
for ( ; ; ) {
Edge edge;
parent_node = active.origin_node;
//
// Step 1 is to try and find a matching edge for the given node.
// If a matching edge exists, we are done adding edges, so we break
// out of this big loop.
//
if ( active.Explicit() ) {
edge = Edge::Find( active.origin_node, T[ last_char_index ] );
if ( edge.start_node != -1 )
break;
} else { // implicit node, a little more complicated
edge = Edge::Find( active.origin_node, T[ active.first_char_index ] );
int span = active.last_char_index - active.first_char_index;
if ( T[ edge.first_char_index + span + 1 ] == T[ last_char_index ] )
break;
parent_node = edge.SplitEdge( active );
}
//
// We didn't find a matching edge, so we create a new one, add
// it to the tree at the parent node position, and insert it
// into the hash table. When we create a new node, it also
// means we need to create a suffix link to the new node from
// the last node we visited.
//
Edge *new_edge = new Edge( last_char_index, N, parent_node );
new_edge->Insert();
Nodes[new_edge->end_node].leaf_index=Node::Leaf++;
if ( last_parent_node > 0 )
Nodes[ last_parent_node ].suffix_node = parent_node;
last_parent_node = parent_node;
//
// This final step is where we move to the next smaller suffix
//
if ( active.origin_node == 0 )
active.first_char_index++;
else
active.origin_node = Nodes[ active.origin_node ].suffix_node;
active.Canonize();
}
if ( last_parent_node > 0 )
Nodes[ last_parent_node ].suffix_node = parent_node;
active.last_char_index++; // Now the endpoint is the next active point
active.Canonize();
};
int main()
{
cout << "Normally, suffix trees require that the last\n"
<< "character in the input string be unique. If\n"
<< "you don't do this, your tree will contain\n"
<< "suffixes that don't end in leaf nodes. This is\n"
<< "often a useful requirement. You can build a tree\n"
<< "in this program without meeting this requirement,\n"
<< "but the validation code will flag it as being an\n"
<< "invalid tree\n\n";
cout << "Enter string: " << flush;
cin.getline( T, MAX_LENGTH - 1 );
N = strlen( T ) - 1;
//
// The active point is the first non-leaf suffix in the
// tree. We start by setting this to be the empty string
// at node 0. The AddPrefix() function will update this
// value after every new prefix is added.
//
Suffix active( 0, 0, -1 ); // The initial active prefix
for ( int i = 0 ; i <= N ; i++ )
AddPrefix( active, i );
for(i=0;i<Node::Count;i++)
cout<<i<<" "<<Nodes[i].father<<" "<<Nodes[i].leaf_index<<endl;
//
// Once all N prefixes have been added, the resulting table
// of edges is printed out, and a validation step is
// optionally performed.
//
// dump_edges( N );
// cout << "Would you like to validate the tree?"
// << flush;
// std::string s;
// std::getline( cin, s );
// if ( s.size() > 0 && s[ 0 ] == 'Y' || s[ 0 ] == 'y' )
// validate();
return 1;
};
//
// The validation code consists of two routines. All it does
// is traverse the entire tree. walk_tree() calls itself
// recursively, building suffix strings up as it goes. When
// walk_tree() reaches a leaf node, it checks to see if the
// suffix derived from the tree matches the suffix starting
// at the same point in the input text. If so, it tags that
// suffix as correct in the GoodSuffixes[] array. When the tree
// has been traversed, every entry in the GoodSuffixes array should
// have a value of 1.
//
// In addition, the BranchCount[] array is updated while the tree is
// walked as well. Every count in the array has the
// number of child edges emanating from that node. If the node
// is a leaf node, the value is set to -1. When the routine
// finishes, every node should be a branch or a leaf. The number
// of leaf nodes should match the number of suffixes (the length)
// of the input string. The total number of branches from all
// nodes should match the node count.
//
char CurrentString[ MAX_LENGTH ];
char GoodSuffixes[ MAX_LENGTH ];
char BranchCount[ MAX_LENGTH * 2 ] = { 0 };
void validate()
{
for ( int i = 0 ; i < N ; i++ )
GoodSuffixes[ i ] = 0;
walk_tree( 0, 0 );
int error = 0;
for ( i = 0 ; i < N ; i++ )
if ( GoodSuffixes[ i ] != 1 ) {
cout << "Suffix " << i << " count wrong!\n";
error++;
}
if ( error == 0 )
cout << "All Suffixes present!\n";
int leaf_count = 0;
int branch_count = 0;
for (i = 0 ; i < Node::Count ; i++ ) {
if ( BranchCount[ i ] == 0 )
cout << "Logic error on node "
<< i
<< ", not a leaf or internal node!\n";
else if ( BranchCount[ i ] == -1 )
leaf_count++;
else
branch_count += BranchCount[ i ];
}
cout << "Leaf count : "
<< leaf_count
<< ( leaf_count == ( N + 1 ) ? " OK" : " Error!" )
<< "\n";
cout << "Branch count : "
<< branch_count
<< ( branch_count == (Node::Count - 1) ? " OK" : " Error!" )
<< endl;
}
int walk_tree( int start_node, int last_char_so_far )
{
int edges = 0;
for ( int i = 0 ; i < 256 ; i++ ) {
Edge edge = Edge::Find( start_node, i );
if ( edge.start_node != -1 ) {
if ( BranchCount[ edge.start_node ] < 0 )
cerr << "Logic error on node "
<< edge.start_node
<< '\n';
BranchCount[ edge.start_node ]++;
edges++;
int l = last_char_so_far;
for ( int j = edge.first_char_index ; j <= edge.last_char_index ; j++ )
CurrentString[ l++ ] = T[ j ];
CurrentString[ l ] = '\0';
if ( walk_tree( edge.end_node, l ) ) {
if ( BranchCount[ edge.end_node ] > 0 )
cerr << "Logic error on node "
<< edge.end_node
<< "\n";
BranchCount[ edge.end_node ]--;
}
}
}
//
// If this node didn't have any child edges, it means we
// are at a leaf node, and can check on this suffix. We
// check to see if it matches the input string, then tick
// off it's entry in the GoodSuffixes list.
//
if ( edges == 0 ) {
cout << "Suffix : ";
for ( int m = 0 ; m < last_char_so_far ; m++ )
cout << CurrentString[ m ];
cout << "\n";
GoodSuffixes[ strlen( CurrentString ) - 1 ]++;
cout << "comparing: " << ( T + N - strlen( CurrentString ) + 1 )
<< " to " << CurrentString << endl;
if ( strcmp(T + N - strlen(CurrentString) + 1, CurrentString ) != 0 )
cout << "Comparison failure!\n";
return 1;
} else
return 0;
}
转自 http://hi.baidu.com/%D0%D0%D0%D0%C7%D2%CD%A3%CD%A3/blog/item/2bc94832ff79b3e41b4cff60.html
http://www.cppblog.com/superKiki/archive/2010/10/29/131786.aspx















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









