







CS224W: Machine Learning with Graphs
Stanford / Winter 2021
09-theory
Key Idea: How powerful are GNNs?
本节图,相同颜色的节点代表它们具有相同的特征向量
-
GCN (mean-pool): Element-wise mean pooling + Linear + ReLU non-linearity
-
GraphSAGE (max-pool): MLP + element-wise max-pooling
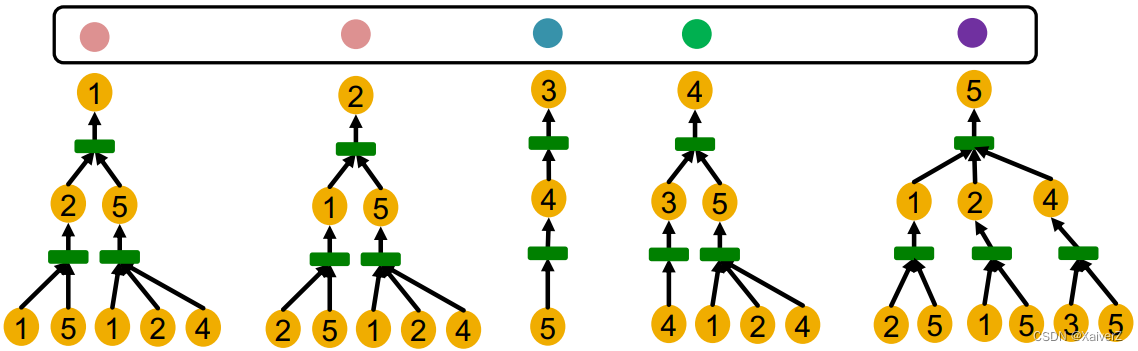
Local Neighborhood Structures
Key Question: How well can a GNN distinguish different graph structures?
-
我们考虑一个节点的(k-hop)局部邻居结构
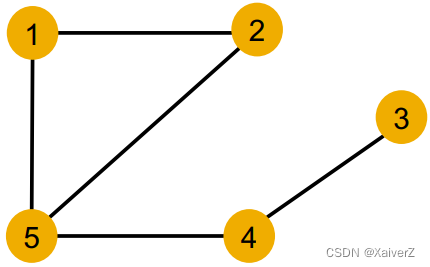
-
节点1和5有不同局部邻居结构,因为它们的度明显不同
-
节点1和4也有不同的局部邻居结构,虽然它们的度都为2,但它们邻居节点的度不同
-
但是,节点1和2有相同的局部邻居结构,它们在图中是对称的(本身、邻居、邻居的邻居…的度都相同),所以无法区分它们
-
Computation Graph
-
从节点1和2的Computation Graph考虑
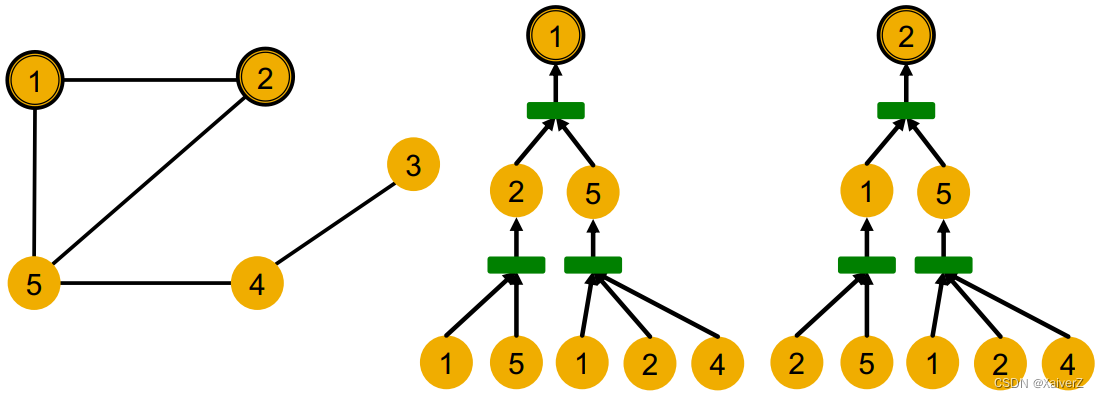
- 节点1和2的计算图完全相同,GNN会对节点1和2产生完全一样的embedding vector(计算图一样,节点特征都一样),所以区分不出
-
Rooted subtree structures
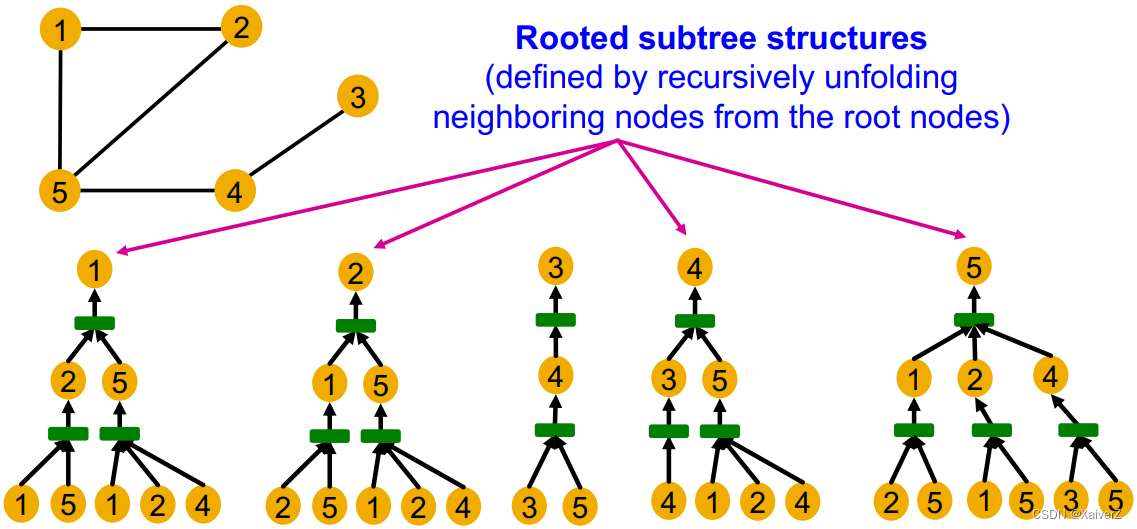
-
Computational graphs are identical to rooted subtree structures around each node
-
GNN’s node embeddings capture rooted subtree structures
-
Most expressive GNN maps different rooted subtrees into different node embeddings (表达能力最强的GNN将不同的rooted subtrees映射到不同的embedding)
- 上述其实说的就是单射函数的概念 (Injective Function),单射函数将不同的输入映射到不同的输出,因此单射函数保留了所有输入的信息
-
Most expressive GNN should map subtrees to the node embeddings injectively
-
同深度的subtree可以被自底向上特征化
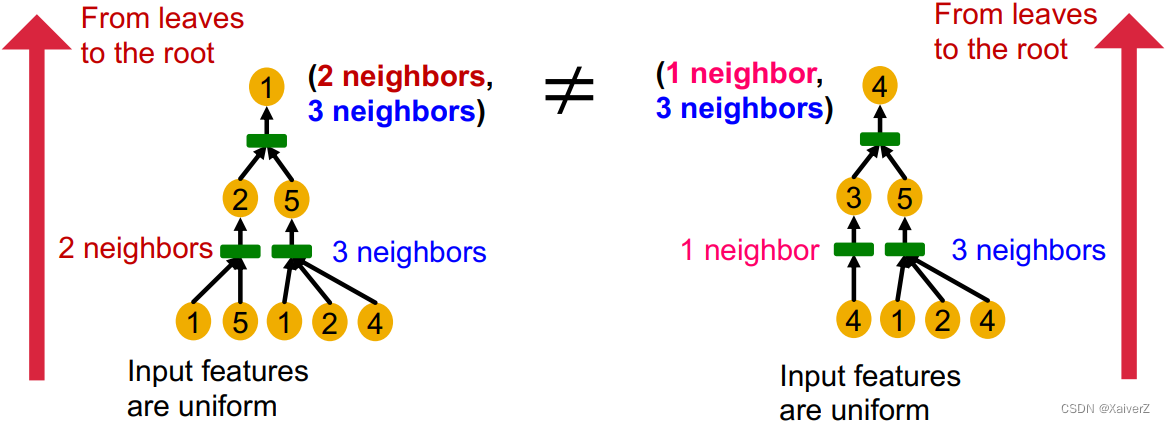
-
自底向上的过程其实就是Aggregation的过程,所以如果GNN的每一次Aggregation都能完整保留邻居的信息,那么产生的node embedding就能分辨出不同的rooted subtree
-
总的来说,表达能力最强的GNN应该使用一个单射邻居聚合函数(Injective Neighbor Aggregation Function)
-
基于以上讨论,GNN的表达能力取决于使用的邻居聚合函数
-
Neighbor Aggregation
分析不同的聚合策略存在的问题
-
假设不同颜色的节点代表不同的node embedding,且用one-hot vector表示

GCN (mean-pool)
-
Failure case
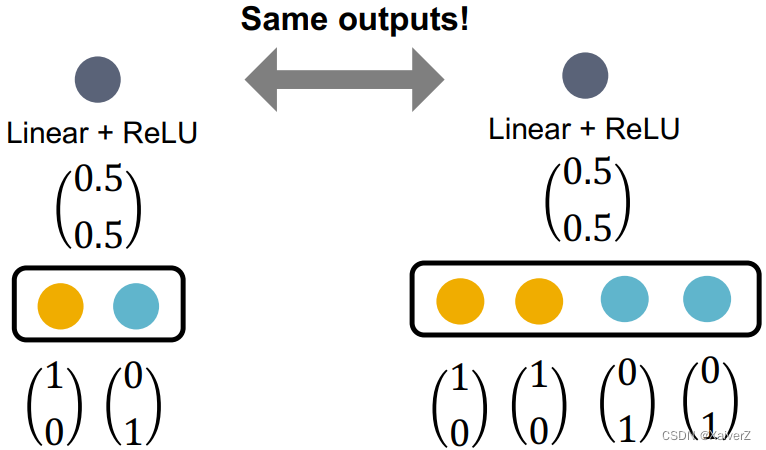
- 使用mean-pool会丢失信息
GraphSAGE (max-pool)
-
Failure case
-
使用max-pool也会丢失信息
-
sum-pool也会丢失信息(-10, 10和5, -5,sum-pool都为0)
-
Designing Most Expressive GNNs
Key Idea: 构造单射的邻居聚合函数
-
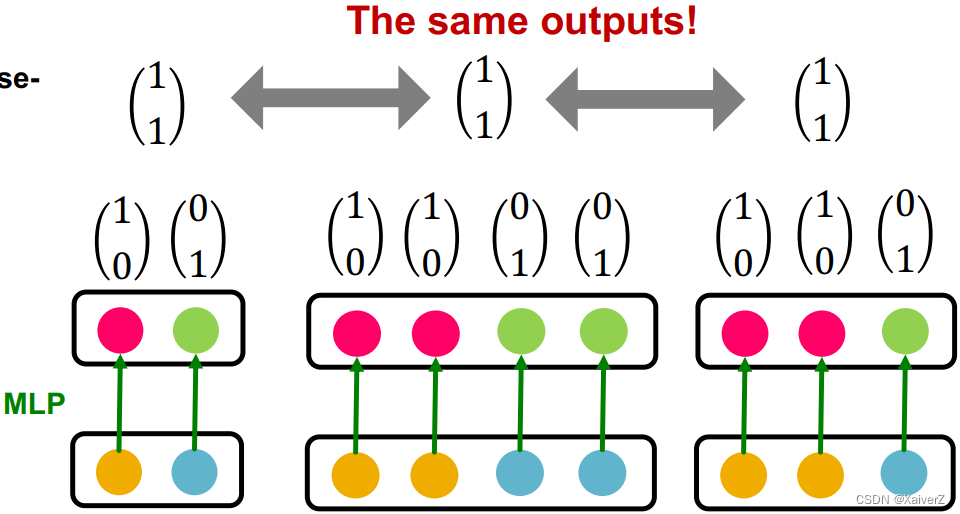
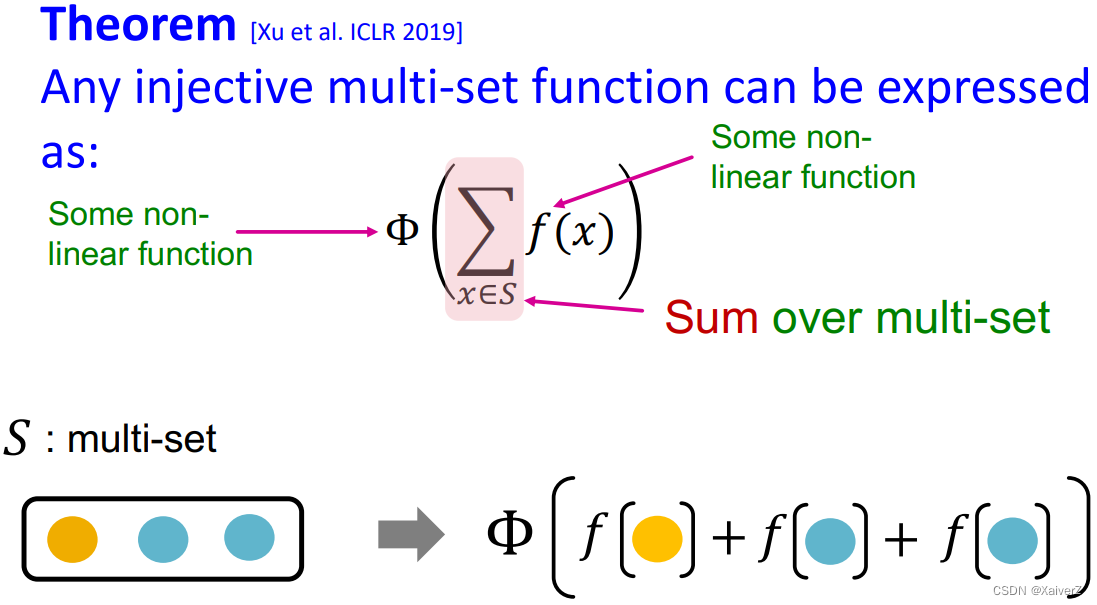
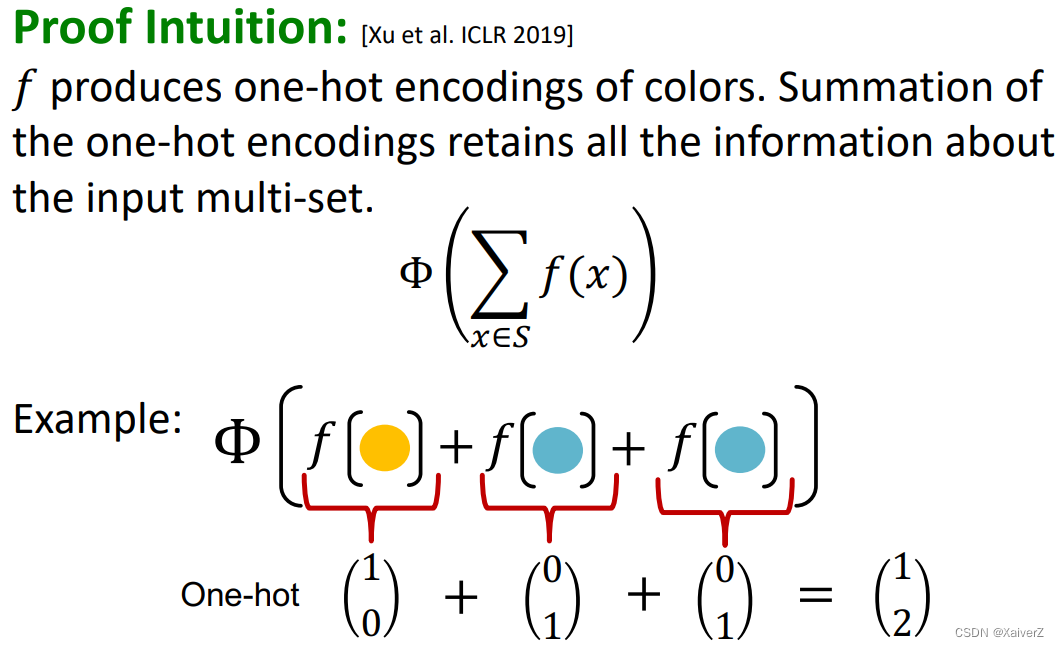
Injective Multi-Set Function
- 单射函数可以被表示为如下图所示形式
-
Thoery: Universal Approximation Theorem
-
根据通用近似定理,具备足够大的hidden dimension、合适activate function的一层的MLP就可以以任意精度近似任何函数
-
所以我们可以用MLP来建模非线性函数$$
MLP Φ ( ∑ x ∈ S MLP f ( x ) ) \operatorname{MLP}_{\Phi}\left(\sum_{x \in S} \operatorname{MLP}_{f}(x)\right) MLPΦ(x∈S∑MLPf(x))
MLP的hidden dimension一般取100-500足够
-
Graph Isomorphism Network (GIN)
GIN
-
GIN使用正是使用如下函数作为聚合策略
MLP Φ ( ∑ x ∈ S MLP f ( x ) ) \operatorname{MLP}_{\Phi}\left(\sum_{x \in S} \operatorname{MLP}_{f}(x)\right) MLPΦ(x∈S∑MLPf(x))
-
先将每条来自邻居节点的消息都经过MLP,然后再将它们element-wise相加,最后再经过另一个MLP
-
GIN‘s neighbor aggregation function is injective
-
No failure cases!
-
GIN is THE most expressive GNN in the class of message-passing GNNs! (GIN在消息传递架构的GNN里是表达能力最强的)
-
-
Relation to WL Graph Kernel
-
GIN其实是WL Graph Kernel的神经网络版本
-
在WL Color Refinement算法中,使用如下函数更新节点信息
c ( k + 1 ) ( v ) = HASH ( c ( k ) ( v ) , { c ( k ) ( u ) } u ∈ N ( v ) ) c^{(k+1)}(v)=\operatorname{HASH}\left(c^{(k)}(v),\left\{c^{(k)}(u)\right\}_{u \in N(v)}\right) c(k+1)(v)=HASH(c(k)(v),{c(k)(u)}u∈N(v))
这里的Hash函数就是单射的,不存在任何哈希碰撞- WL Test: 运行Color Refinement直到颜色稳定,若此时两图的节点颜色集合完全相同,则说明这两张图是同构的(isomorphic),否则是非同构的(non-isomorphic)
-
-
特别的,所有元组的单射函数可以被建模为如下公式 (把自身的特征与邻居的特征都考虑进来)
MLP Φ ( ( 1 + ϵ ) ⋅ MLP f ( c ( k ) ( v ) ) ) + ∑ u ∈ N ( v ) MLP f ( c ( k ) ( u ) ) ) \left.\operatorname{MLP}_{\Phi}\left((1+\epsilon) \cdot \operatorname{MLP}_{f}\left(c^{(k)}(v)\right)\right)+\sum_{u \in N(v)} \operatorname{MLP}_{f}\left(c^{(k)}(u)\right)\right) MLPΦ((1+ϵ)⋅MLPf(c(k)(v)))+u∈N(v)∑MLPf(c(k)(u))
其中, ϵ \epsilon ϵ是可学习参数。GIN使用的正是如上单射函数进行邻居聚合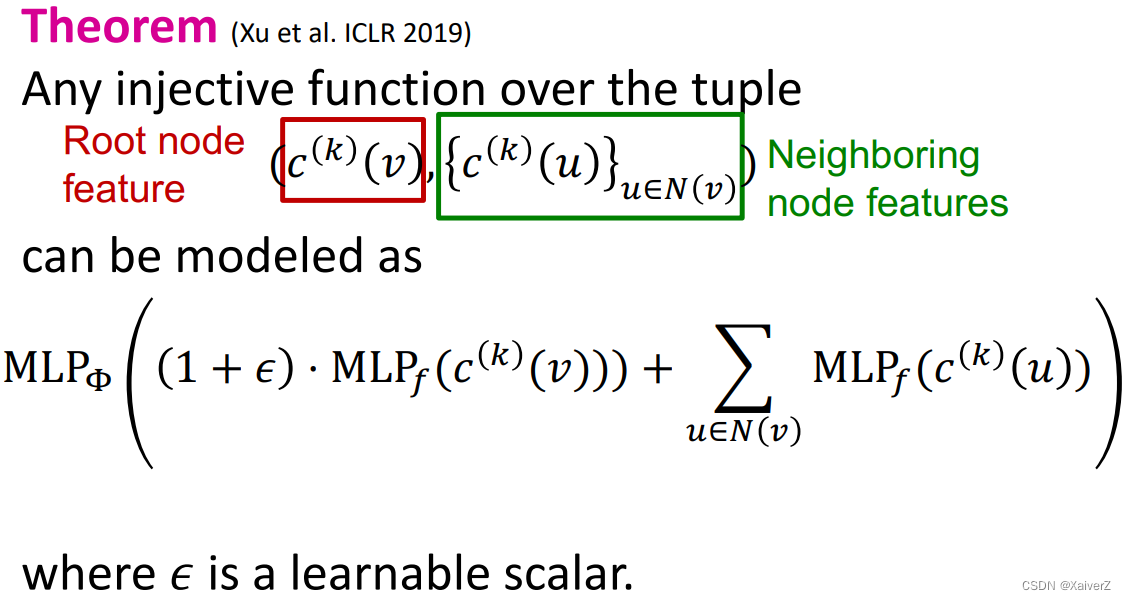
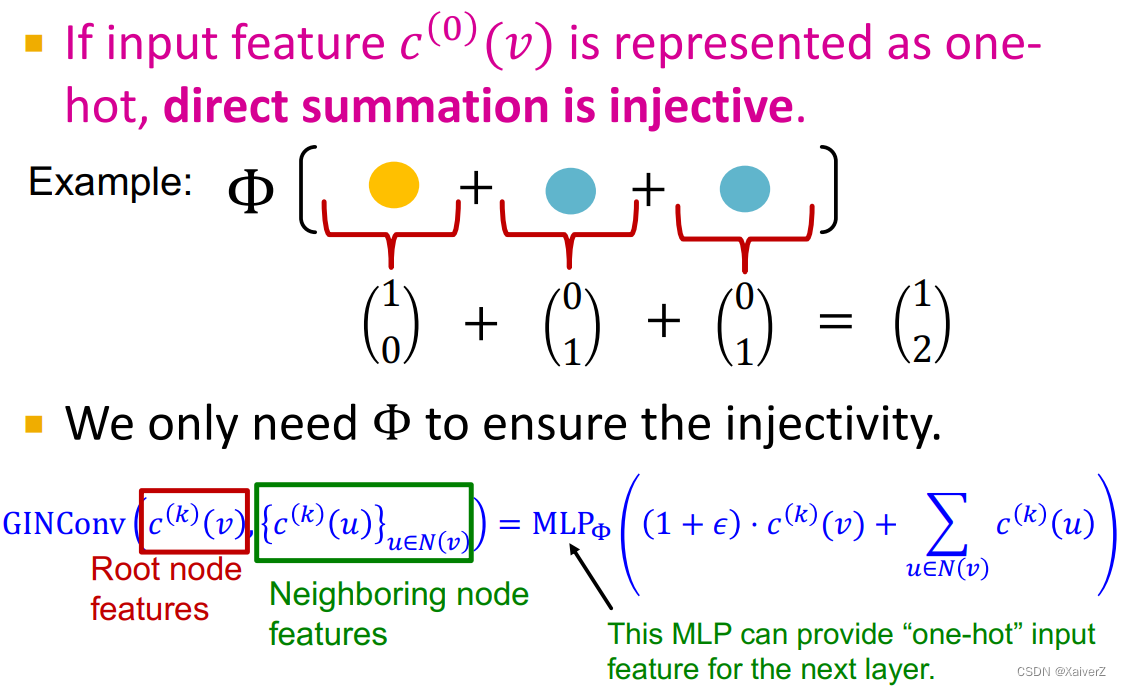
-
GIN相比于WL Graph Kernel的优势
-
节点特征是d-dimensional feature vector,能获得比WL更细粒度的特征
-
GIN有可学习参数可适用于下游任务
-
-
The Power of Pooling
- Graph Pooling分辨能力排序:sum-pooing > mean-pooing > max-pooling
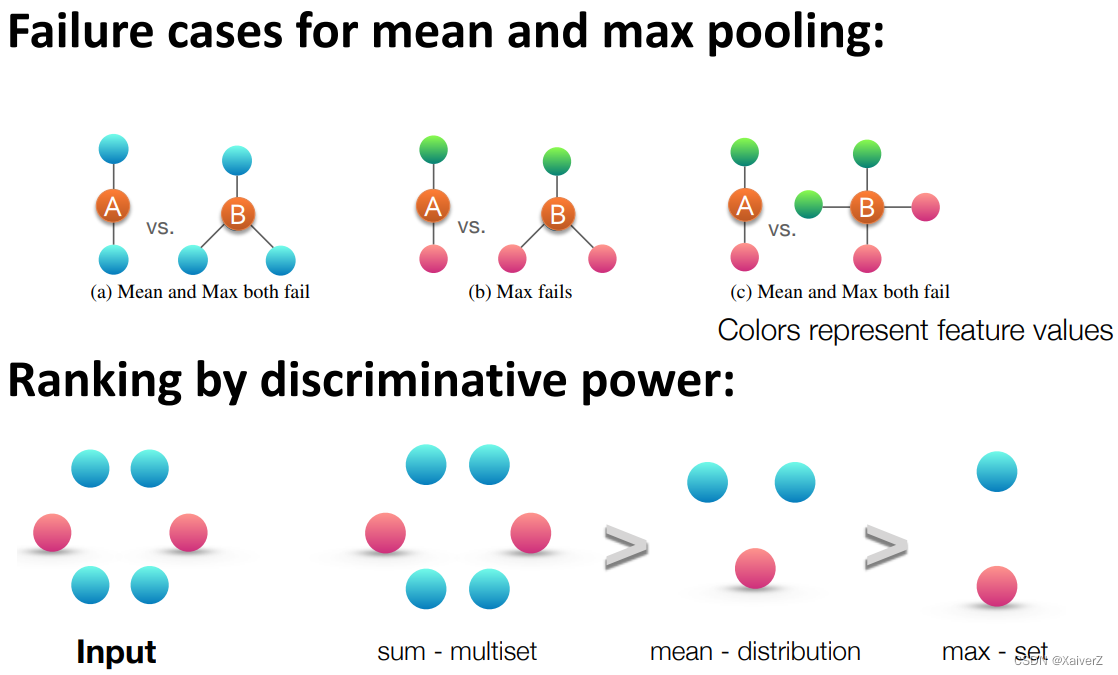
-
Improving GNN’s power
- 一些前沿问题
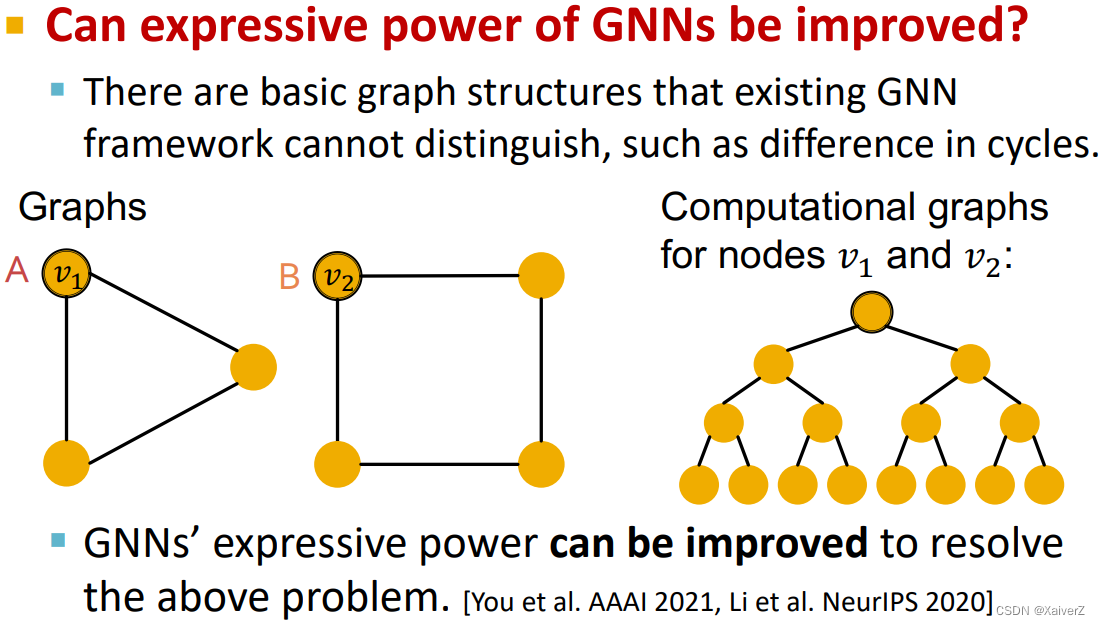














 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









