









图卷积在 CV 的全局推理中的应用(Global Reasoning)
1. Graph-Based Global Reasoning Networks. (CVPR 2019)
| 基本思想 | 主要技术创新 GloRe |
|---|---|
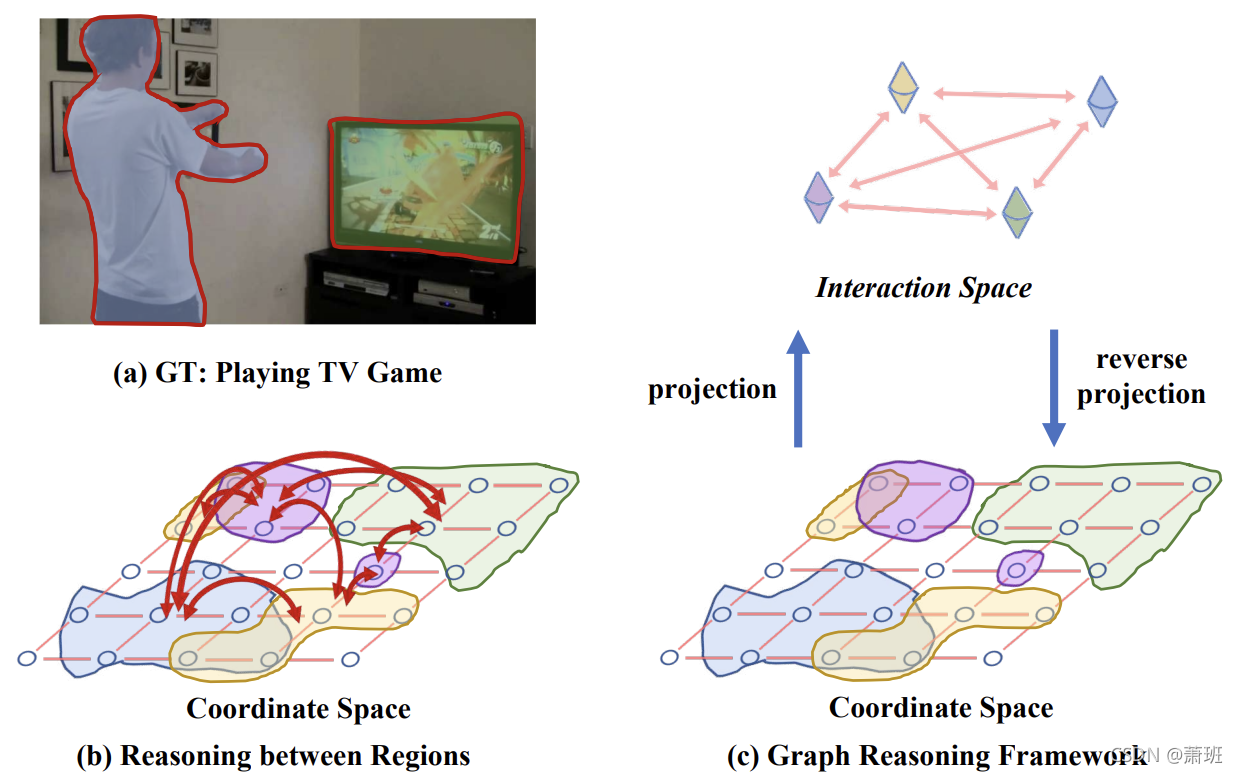 | 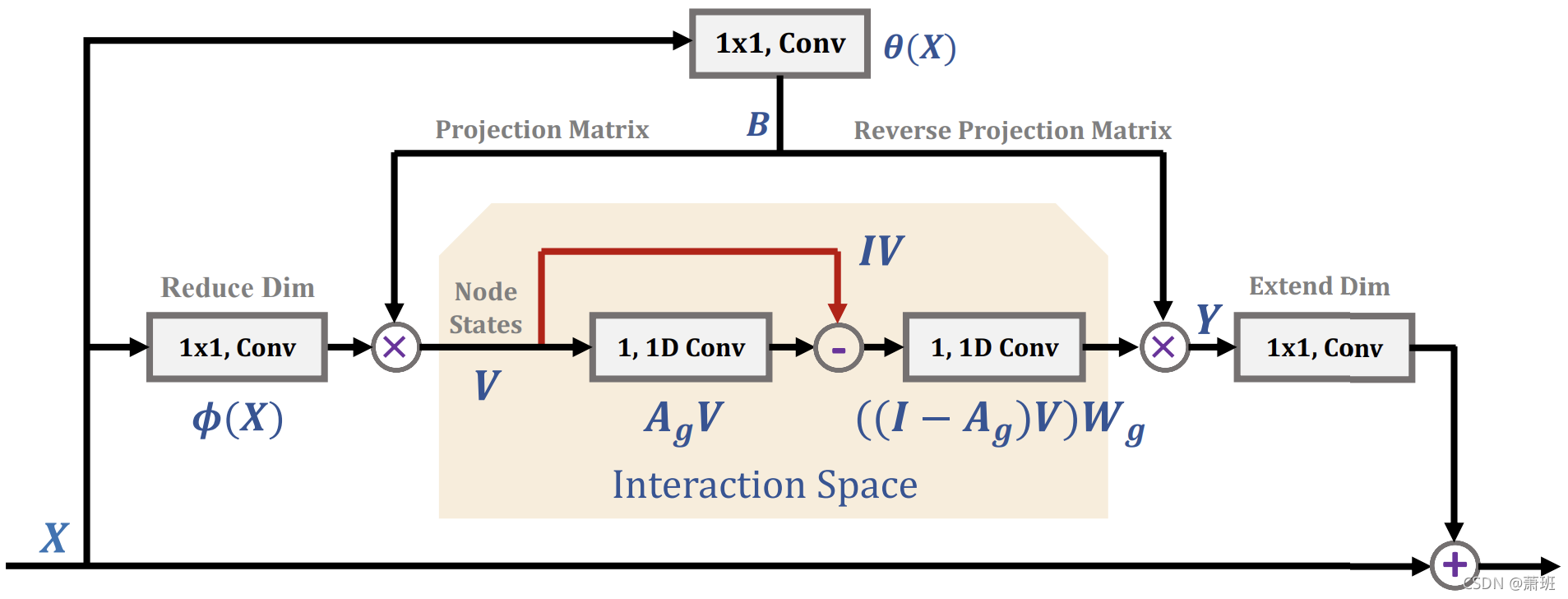 |
| 1️⃣ 仅依靠卷积的感受野有限,要么堆叠卷积层; 2️⃣ 图卷积天然考虑全图节点之间的关系,具有全局感受野; 3️⃣ 因此对中间层特征通过 GloRe 模块作全局交互来实现类似特征增强的目的;4️⃣ 具体地,将特征从坐标空间投影到交互空间,图卷积增强后,再逆投影回坐标空间,继续 CNN 中前馈。 | 1️⃣ 常规特征
X
∈
R
B
×
C
×
H
×
W
X\in\mathbb R^{B\times C\times H\times W}
X∈RB×C×H×W,分别经过
1
×
1
1\times1
1×1 卷积
ϕ
\phi
ϕ 降维得到
ϕ
(
X
)
∈
R
B
×
C
′
×
H
×
W
\phi(X)\in\mathbb R^{B\times C'\times H\times W}
ϕ(X)∈RB×C′×H×W,reshape 得到
ϕ
(
X
)
∈
R
B
×
C
′
×
L
\phi(X)\in\mathbb R^{B\times C'\times L}
ϕ(X)∈RB×C′×L;经过
θ
\theta
θ 得到
θ
(
X
)
∈
R
B
×
N
×
H
×
W
\theta(X)\in\mathbb R^{B\times N\times H\times W}
θ(X)∈RB×N×H×W,经过 reshape 得到投影矩阵
B
∈
R
B
×
N
×
L
B\in\mathbb R^{B\times N\times L}
B∈RB×N×L; 2️⃣ 投影: V = ϕ ( X ) ⋅ B V=\phi(X)\cdot B V=ϕ(X)⋅B; 3️⃣ 图卷积:可学习连接矩阵 A g A_g Ag 与逐点变换矩阵 W g W_g Wg,计算: ( ( I − A g ) ⋅ V ⋅ W g ) ((I-A_g)\cdot V\cdot W_g) ((I−Ag)⋅V⋅Wg); 4️⃣ 逆投影: Y = B T ⋅ ( ( I − A g ) ⋅ V ⋅ W g ) Y=B^T\cdot((I-A_g)\cdot V\cdot W_g) Y=BT⋅((I−Ag)⋅V⋅Wg); 5️⃣ 经过 1 × 1 1\times1 1×1 卷积将维度扩展回 C C C,得到残差部分; 6️⃣ 得到模块输出: O = X + Y O=X+Y O=X+Y. |
这是一个即插即用的模块,文中用它来代替一般的残差块。Pytorch 实现如下,来自👉:
# -*- coding: utf-8 -*-
from torch import nn
class GCN(nn.Module):
def __init__(self, dim_1_channels, dim_2_channels):
super().__init__()
self.conv1d_1 = nn.Conv1d(dim_1_channels, dim_1_channels, 1)
self.conv1d_2 = nn.Conv1d(dim_2_channels, dim_2_channels, 1)
def forward(self, x):
# x --size=(B,N,C')
h = self.conv1d_1(x).permute(0, 2, 1) # (B,N,C') -> (B,C',N)
return self.conv1d_2(h).permute(0, 2, 1) # (B,C',N) -> (B,N,C')
class GloRe(nn.Module):
def __init__(self, in_channels, mid_channels, N):
# C , C' , N
super().__init__()
self.in_channels = in_channels
self.mid_channels = mid_channels
self.N = N
self.phi = nn.Conv2d(in_channels, mid_channels, 1)
self.theta = nn.Conv2d(in_channels, N, 1)
self.gcn = GCN(N, mid_channels)
self.phi_inv = nn.Conv2d(mid_channels, in_channels, 1)
def forward(self, x):
B, C, H, W = x.size()
mid_channels = self.mid_channels
N = self.N
B = self.theta(x).view(batch_size, N, -1) # (B,N,H,W) -> (B,N,L)
x_reduced = self.phi(x).view(batch_size, mid_channels, h * w) # (B,C',H,W) -> (B,C',L)
x_reduced = x_reduced.permute(0, 2, 1) # -> (B,L,C')
v = B.bmm(x_reduced) # (B,N,C')
z = self.gcn(v) # (B,N,C')
y = B.permute(0, 2, 1).bmm(z).permute(0, 2, 1) # (B,L,N) \odot (B,N,C') = (B,L,C') -> (B,C',L)
y = y.view(batch_size, mid_channels, h, w) # (B,C',H,W)
x_res = self.phi_inv(y) # (B,C,H,W)
return x + x_res
2. Spatial Pyramid Based Graph Reasoning for Semantic Segmentation. (CVPR 2020)
| 基本思想 | 主要技术创新 SpyGR |
|---|---|
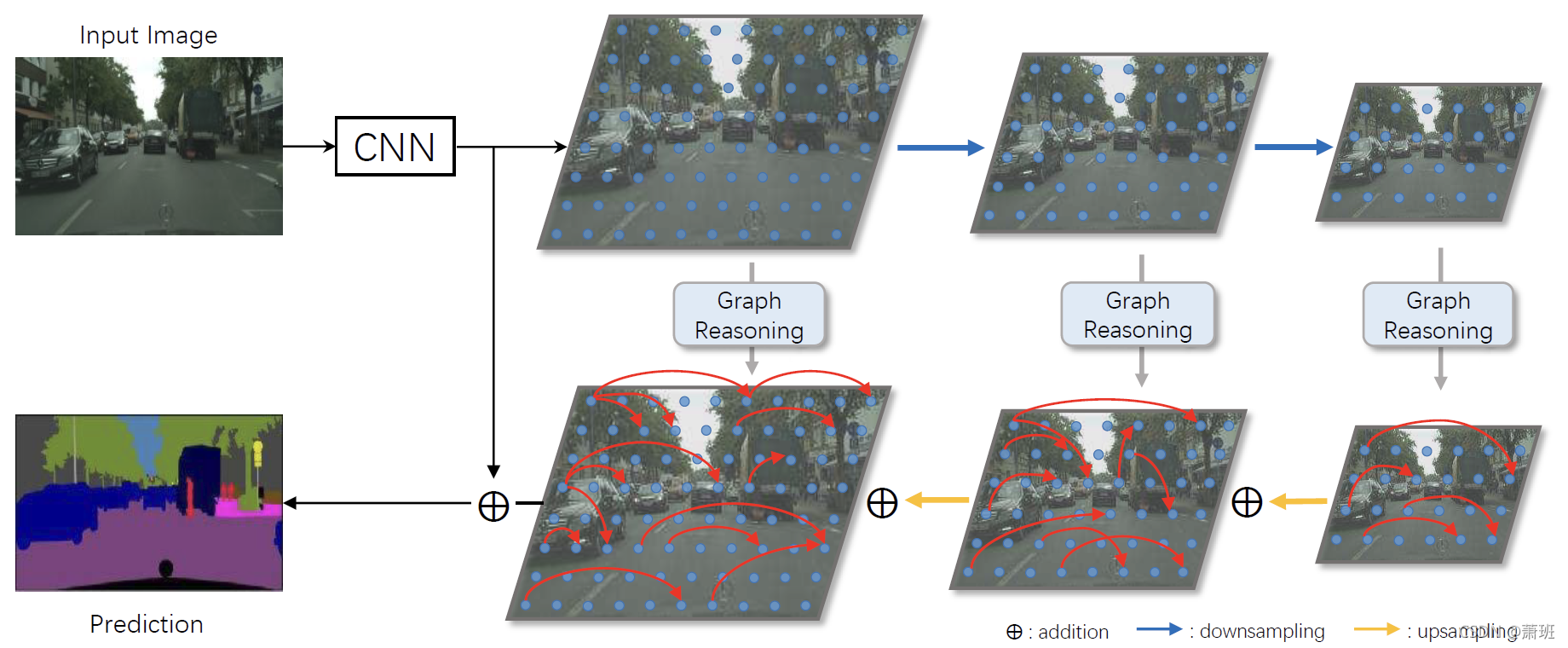 |  |
| 1️⃣ 同样是为了利用图卷积的全图感受野,并且提供一定的可解释性(讲真从这个角度出发,加上文中将 feat 直接看做图,不明白这个图卷积与 Non-local block 有什么区别); 2️⃣ 在每一层 s s s 中,先通过下采样(的卷积模块)抽取特征: X ( s ) = Π d o w n ( X ( s + 1 ) ) X^{(s)}=\Pi_{down}(X^{(s+1)}) X(s)=Πdown(X(s+1)),注意越深层编号 s s s 越小; 3️⃣ 使用 GR 模块作特征增强,上采样后自身的 SR-augmented 版本做加法,即:
Y
(
s
+
1
)
=
G
R
(
X
(
s
+
1
)
)
+
Π
u
p
(
Y
(
s
)
)
Y^{(s+1)}=GR(X^{(s+1)})+\Pi_{up}(Y^{(s)})
Y(s+1)=GR(X(s+1))+Πup(Y(s));其中
Y
(
0
)
=
G
R
(
X
(
0
)
)
Y^{(0)}=GR(X^{(0)})
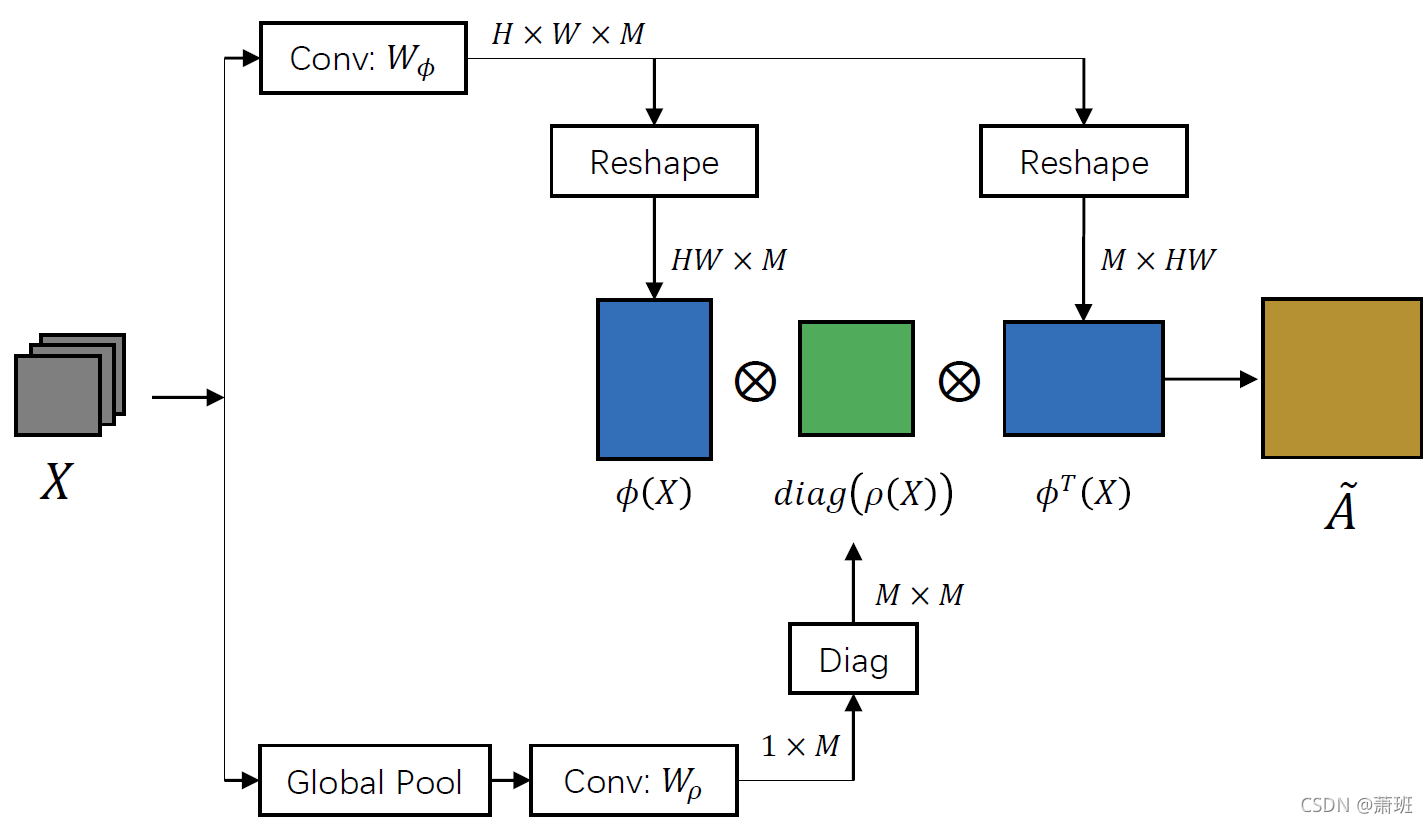
Y(0)=GR(X(0)). | 在 GR 模块中,实际上就是一个图卷积,只不过其中的连接矩阵
A
A
A 与度矩阵
D
D
D 都是 data-dependent 的,这是与 GloRe 的不同;1️⃣ 将整个 feat 看做一个特殊的图结构,省去了投影与逆投影的过程; 2️⃣ 计算连接矩阵: A ^ = ϕ ( X ) ⋅ d i a g ( ρ ( X ) ) ⋅ ϕ T ( X ) \hat A=\phi(X)\cdot diag(\rho(X))\cdot \phi^T(X) A^=ϕ(X)⋅diag(ρ(X))⋅ϕT(X),其中 d i a g diag diag 是从一个 M M M-dim 的向量变换为一个 M × M M\times M M×M 的对角矩阵, ρ ( X ) \rho(X) ρ(X) 即先作全局池化后作 FC 变换; 3️⃣ 此时,图卷积的计算可以表示为: Y = σ ( L ^ X Θ ) Y=\sigma(\hat LX\Theta) Y=σ(L^XΘ),其中拉普拉斯矩阵 L ^ = I − D ^ ( − 1 2 ) ⋅ A ^ ⋅ D ^ ( − 1 2 ) \hat L=I-\hat D^{({-{1\over 2}})}\cdot\hat A\cdot\hat D^{({-{1\over 2}})} L^=I−D^(−21)⋅A^⋅D^(−21),而度矩阵则由连接矩阵计算得到: D ^ i i = ∑ j A ^ i j \hat D_{ii}=\sum_j \hat A_{ij} D^ii=∑jA^ij,即逐行取和后构造对角矩阵。 |
以上是这两天看的几篇文章中,GCN 在图像或视频全局推理中的一种使用方式,用于增大模型感受野。














 2266
2266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









