







 本文深入解读《Graph WaveNet for Deep Spatial-Temporal Graph Modeling》论文,介绍了如何利用图卷积层(GCL)和时间卷积层(TCL)结合自适应邻接矩阵,有效处理时空图数据,获取节点的空间和时间依赖关系。文章详细阐述了自适应邻接矩阵的构建、Gate TCN的工作原理,并展示了Graph WaveNet在交通网络数据集上的实验应用。
本文深入解读《Graph WaveNet for Deep Spatial-Temporal Graph Modeling》论文,介绍了如何利用图卷积层(GCL)和时间卷积层(TCL)结合自适应邻接矩阵,有效处理时空图数据,获取节点的空间和时间依赖关系。文章详细阐述了自适应邻接矩阵的构建、Gate TCN的工作原理,并展示了Graph WaveNet在交通网络数据集上的实验应用。
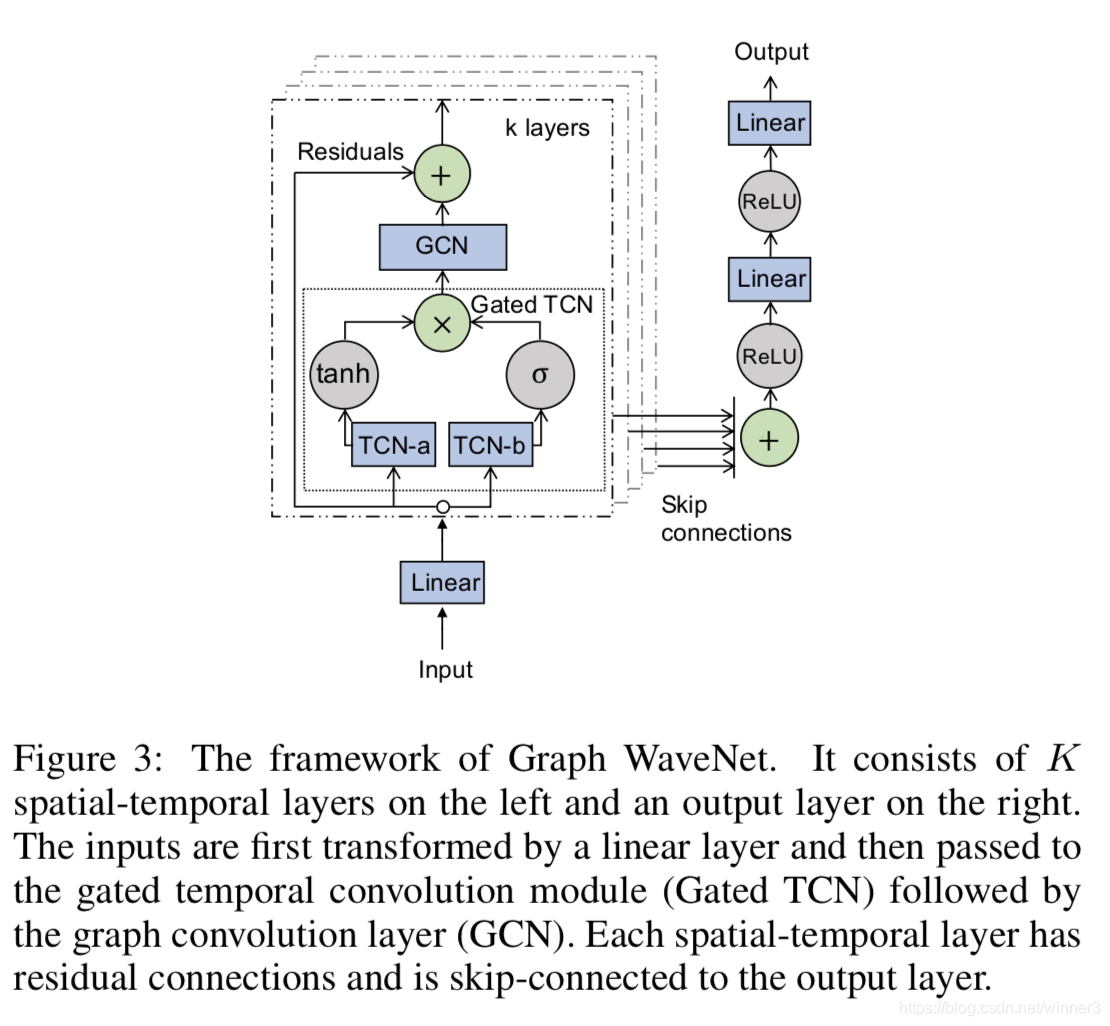
基于时空图采用Graph WaveNet建模,其能够有效的处理大范围时间序列的时空图数据。在该模型架构中,主要包括两个模块,分别为GCN和TCN。两个模块融合获取时间空间的依赖关系。
该模型的框架如下:
目录
一、本论文的创新点如下:
- 构建能够保留其隐含空间关系的自适应邻接矩阵。自适应邻接矩阵在没有先验知识的前提下,从数据中挖掘隐含的图结构。
- 提出了同时高效获取时空依赖关系的框架,该框架的核心思想是将扩张因果卷积与图卷积融合,进而每个图卷积层能够处理在不同细粒度下,由扩张因果卷积提取的每个节点信息的空间依赖关系。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3668
3668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









