






1 环境
windos开发环境:
windos10
eclipse
jdk-1.8
hadoop-2.7.7 (为方便提交任务到远程hadoop集群)
hadoop伪分布式环境:
centos7.6
hadoop-2.7.7
jdk-1.8
spark on hadoop 已完成
spark on hadoop 可参考:
https://blog.csdn.net/SCS199411/article/details/90114174
https://blog.csdn.net/feifeileill/article/details/128502067
2 Scala安装
2.1 下载安装包
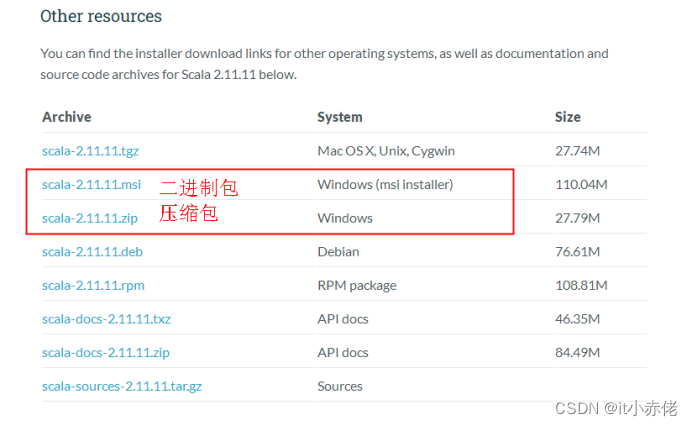
下载安装包,可直接浏览器访问 Scala 2.11.11 | The Scala Programming Language
,根据自己的系统版本进行下载,这里以Windows系统进行演示。
(Windows系统支持下载二进制文件和压缩包,本次下载压缩包)
2.2 解压压缩包
解压压缩包,路径可自行定义。

2.3 配置环境变量
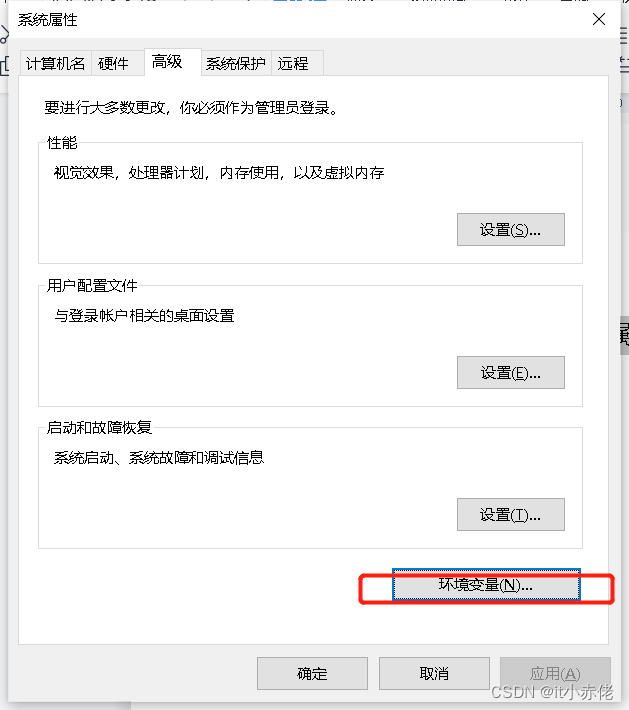
右击【我的电脑】--【属性】--【高级系统设置】--【环境变量】。
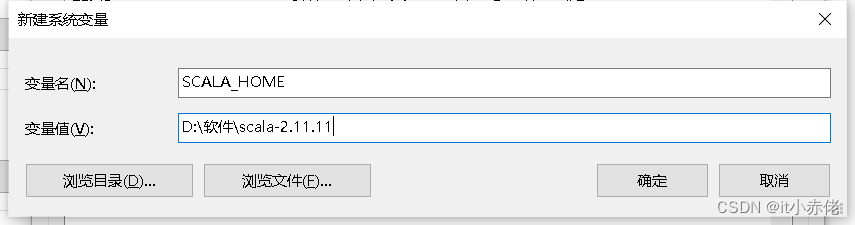
(1)设置SCALA_HOME变量
变量名:SCALA_HOME
变量值:D:\软件\scala-2.11.11,也就是 Scala 的安装目录,根据个人情况有所不同,自行操作。
(2)设置 Path 变量
变量名:Path
变量值:%SCALA_HOME%\bin; (在原有基础上添加路径)
注意:变量之间的分号;(英文格式)不要漏掉。

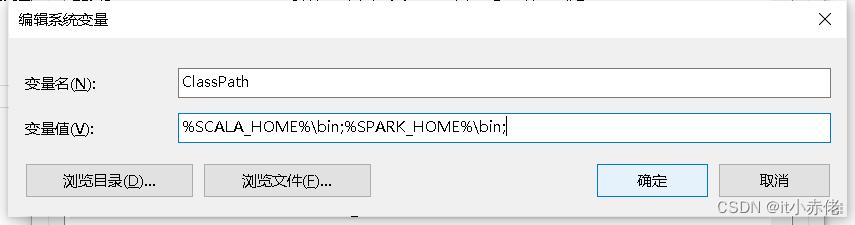
(3)设置 Classpath 变量
变量名:ClassPath
变量值:%SCALA_HOME%\bin;(在原有基础上添加路径)
注意:变量之间的分号;(英文格式)不要漏掉。

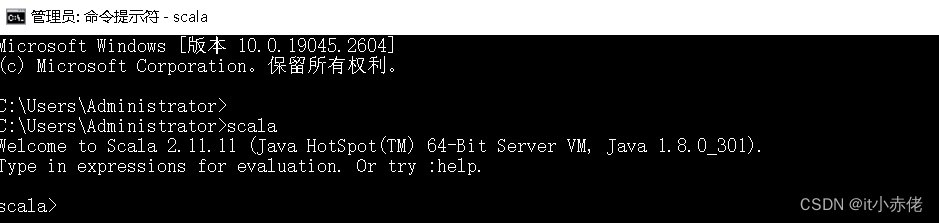
2.4 验证
系统输入框中输入cmd,然后"回车",输入scala,然后回车,检查环境是否配置成功。
3 Spark安装
Spark 在 Java 8+、Python 2.7+/3.4+ 和 R 3.1+ 上运行。对于 Scala API,Spark 2.4.3 使用 Scala 2.12。您将需要使用兼容的 Scala 版本 (2.12.x)。
请注意,从 Spark 2.2.0 开始,已删除对 Java 7、Python 2.6 和 2.6.5 之前的旧 Hadoop 版本的支持。对 Scala 2.10 的支持从 2.3.0 开始被移除。对 Scala 2.11 的支持自 Spark 2.4.1 起已弃用,并将在 Spark 3.0 中移除。
(这里是Scala 2.11不再维护,但是我们运行程序还是可以使用的)
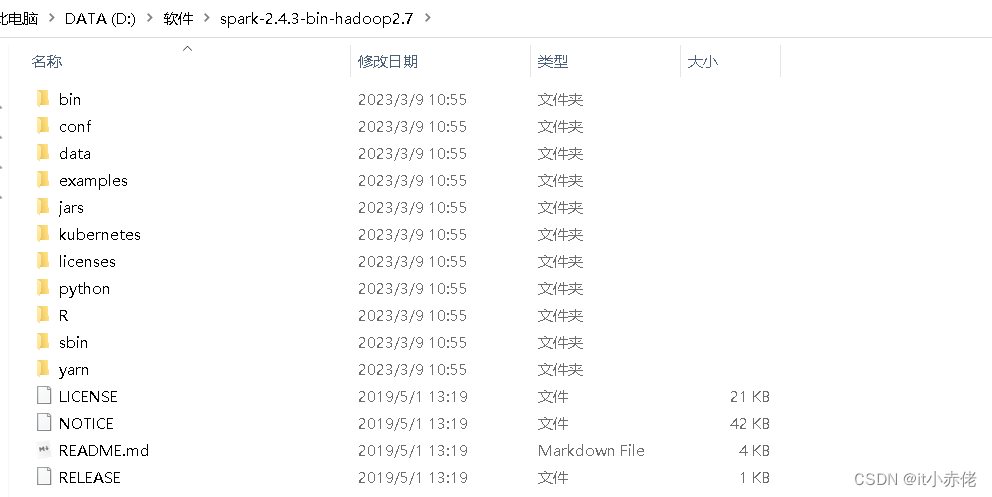
3.1 解压压缩包
保存安装包并解压到指定位置。
3.2 配置环境变量
(1)设置SPARK_HOME变量
变量名:SPARK_HOME
变量值:D:\软件\spark-2.4.3-bin-hadoop2.7,也就是Spark的安装目录,根据个人情况有所不同,应和解压后的路径一致。

(2)设置 Path 变量
变量名:Path
变量值:%SPARK_HOME%\bin; (此为在原有基础上添加路径)
注意:变量之间的分号;(英文格式)不要漏掉。

(3)设置 Classpath 变量
变量名:ClassPath
变量值:%SPARK_HOME%\bin;
注意:变量之间的分号;(英文格式)不要漏掉。
4 Eclipse上创建Scala项目
4.1 安装Eclipse Scala插件
方式一:安装scala 插件,不推荐,官方网站已经挂了
在Eclipse中,依次选择“Help”-->“Eclipse Marketplace”,搜索scala,并安装Scala IDE。
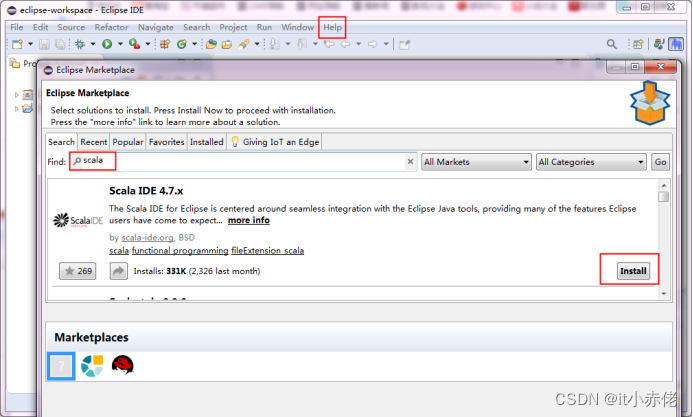
选择同意条款,进而开始下载对应插件,注意安装之后,Eclipse会提示重新开启。

方式二:直接下载完整包,scala-SDK-4.7.0-vfinal-2.12-win32.win32.x86_64.zip
下载地址:
Download Scala IDE for Eclipse - Scala IDE for Eclipsehttp://scala-ide.org/download/sdk.html
解压压缩包,会看到其中有两个文件夹。
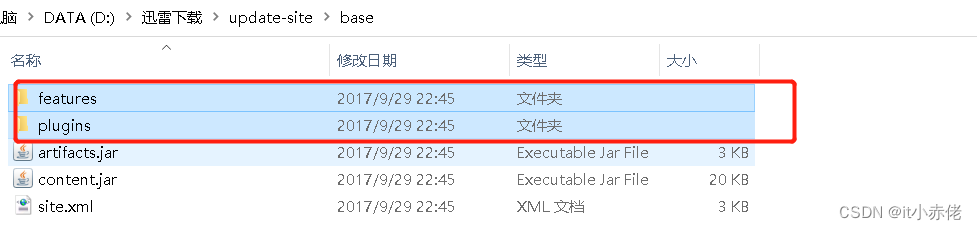
进入现在正在使用的Eclipse的主目录,里面有个“dropin”目录,进入该目录,新建文件夹,
取名“Scala”,然后计入该目录,将刚才红色框选择的两个文件夹拷贝到这里

此时,重启Eclipse,即可看到Scala插件已经安装成功。启动后可能会提示某个组件未启用,点击“OK”,启用该组件并重启Eclipse即可。
4.2 创建Scala项目
重新开启后,就可以创建Scala项目了。


4.3 配置Scala工程版本库
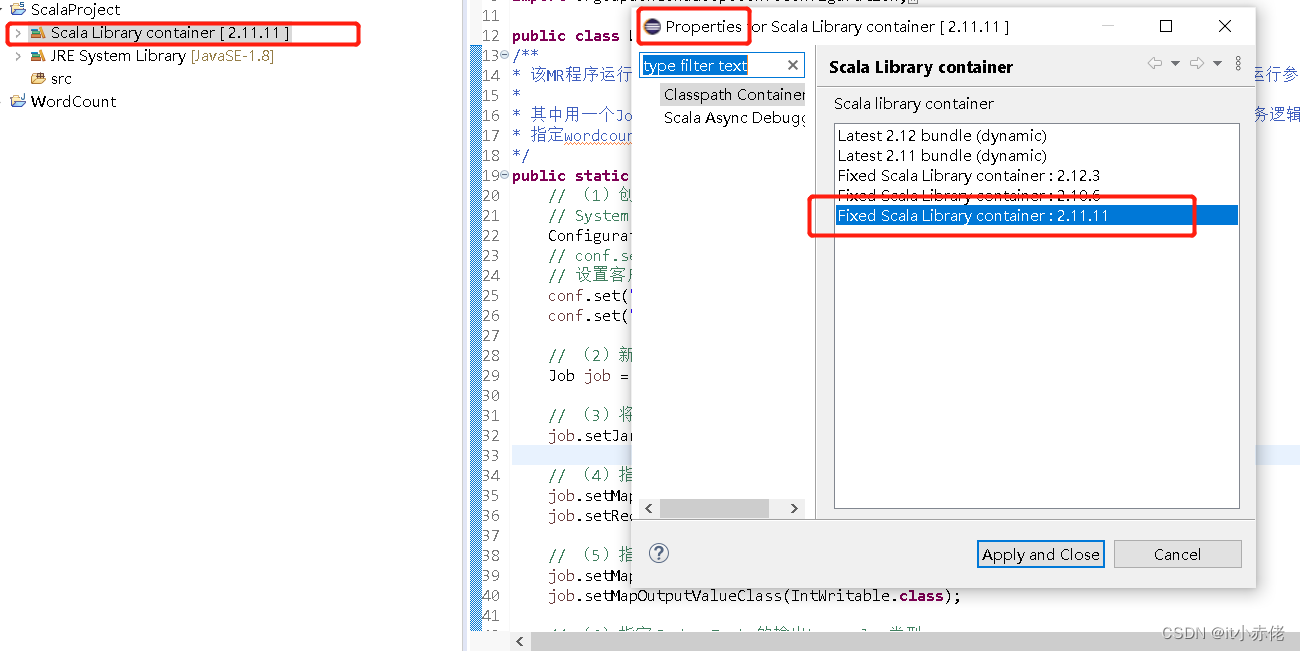
点击【Scala Library container】右键选择【Properties】,这里看到有多个版本库容器,选中我们安装的2.11.11即可。
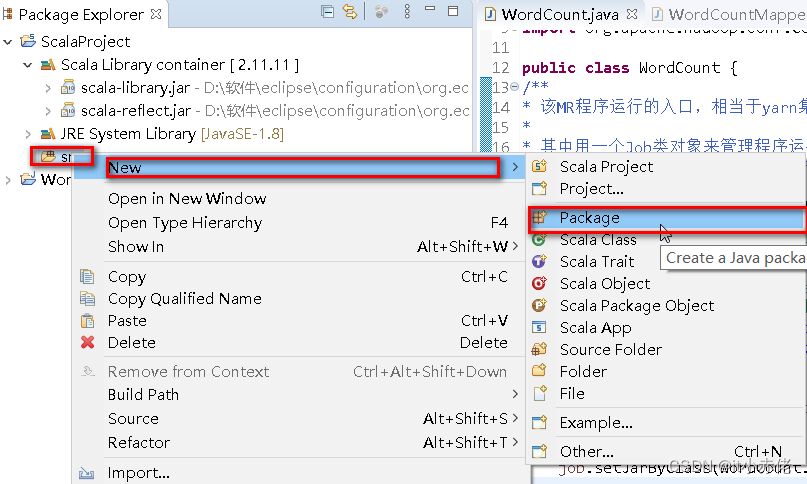
4.4 创建包和类
包名:com.qingjiao.staff

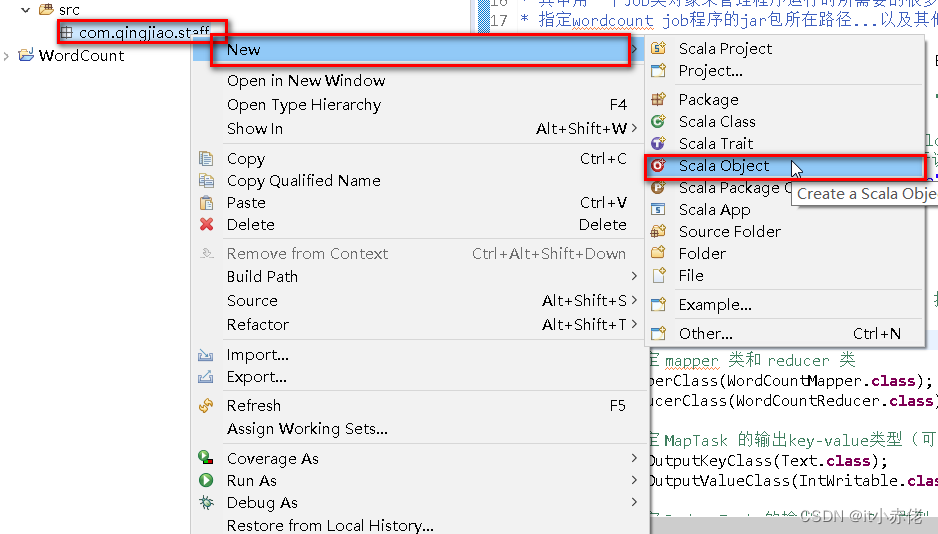
类名:Test

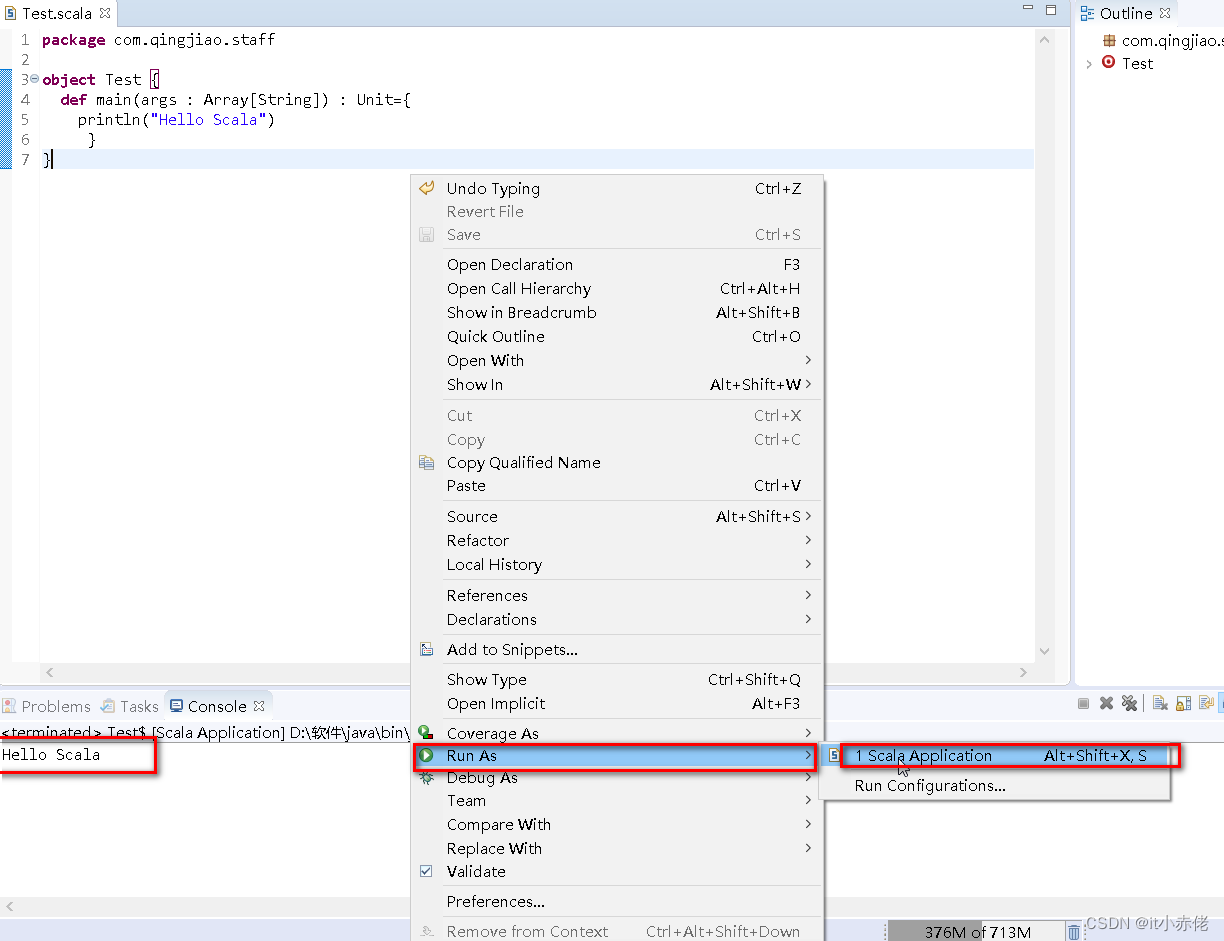
4.5 编写测试程序并运行
package com.qingjiao.staff
object Test {
def main(args : Array[String]) : Unit={
println("Hello Scala")
}
}
5 Eclipse上创建Spark项目(Wordount)
5.1 创建项目Project
自定创建数据word.txt.路径可自定义。 为方便处理,同目录下创建即可,并写入如下内容。
Shall I compare thee to a summer's day?
Thou art more lovely and more temperate:
Rough winds do shake the darling buds of May,
And summer's lease hath all too short a date;
Sometime too hot the eye of heaven shines,
And often is his gold complexion dimmed,
And every fair from fair sometime declines,
By chance, or nature's changing course untrimmed:
But thy eternal summer shall not fade,
Nor lose possession of that fair thou ow'st;
Nor shall Death brag thou wand'rest in his shade,
When in eternal lines to time thou grow'st.
So long as men can breathe, or eyes can see,
So long lives this, and this gives life to thee.
5.2 配置Scala工程版本库
同上。选择2.11.11
5.3 导包
将spark文件jars目录的jar包导入即可。
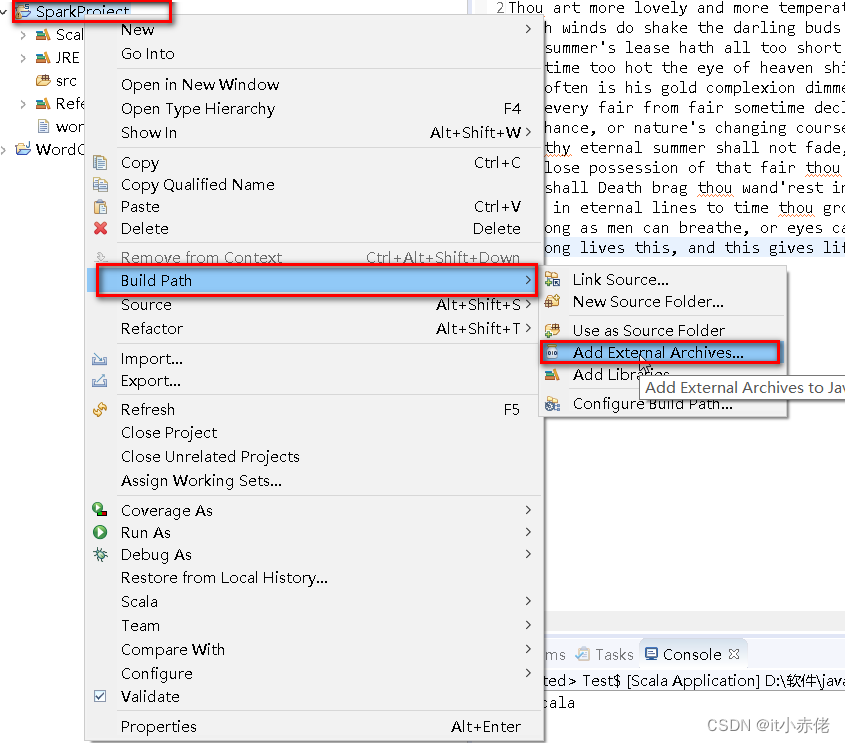
选择全部jar包
导入成功。
5.4 创建包和类
创建com.qingjiao.staff和类WordCount。创建方法同上,创建结果如下。
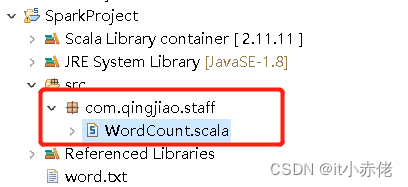
代码如下:
package com.qingjiao.staff
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf,SparkContext}
object WordCount {
def main(args:Array[String]):Unit={
//创建配置信息类,并设置应用程序名称(setAppName)
val conf:SparkConf = new SparkConf()
.setAppName("wordcount")
.setMaster("local[2]")
// 创建Spark的上下文对象,也是提交任务到集群的入口类
val sc:SparkContext = new SparkContext(conf)
//读取本地测试数据,这里数据路径为自己系统上数据实际路径
val lines:RDD[String] = sc.textFile("./word.txt")
//使用RDD方式处理数据
//按空格切分数据
val words:RDD[String] = lines.flatMap(_.split(" "))
//将获取到的单词计为1,即<key,value>=><word,1>
val tup:RDD[(String,Int)] = words.map((_,1))
//按照key(单词)进行分组求出value的和
val reduced:RDD[(String,Int)] = tup.reduceByKey(_+_)
//true表示正序排序,false表示倒序排序
val res:RDD[(String,Int)] = reduced.sortBy(_._2, false)
//控制台打印
println(res.collect.toBuffer)
//文件保存路径,可自定义
res.saveAsTextFile("./outfile")
//程序结束
sc.stop()
}
}
5.5 运行程序
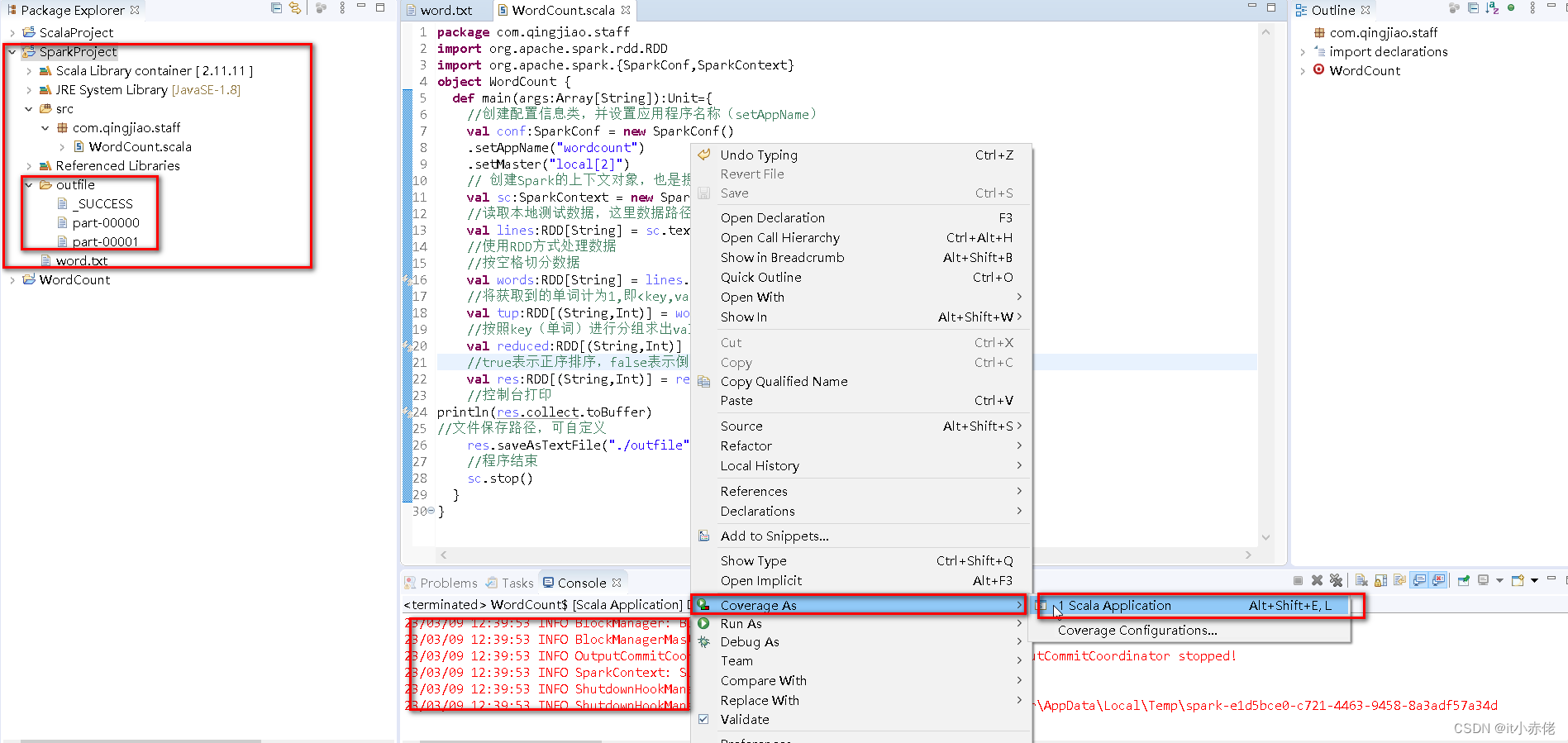
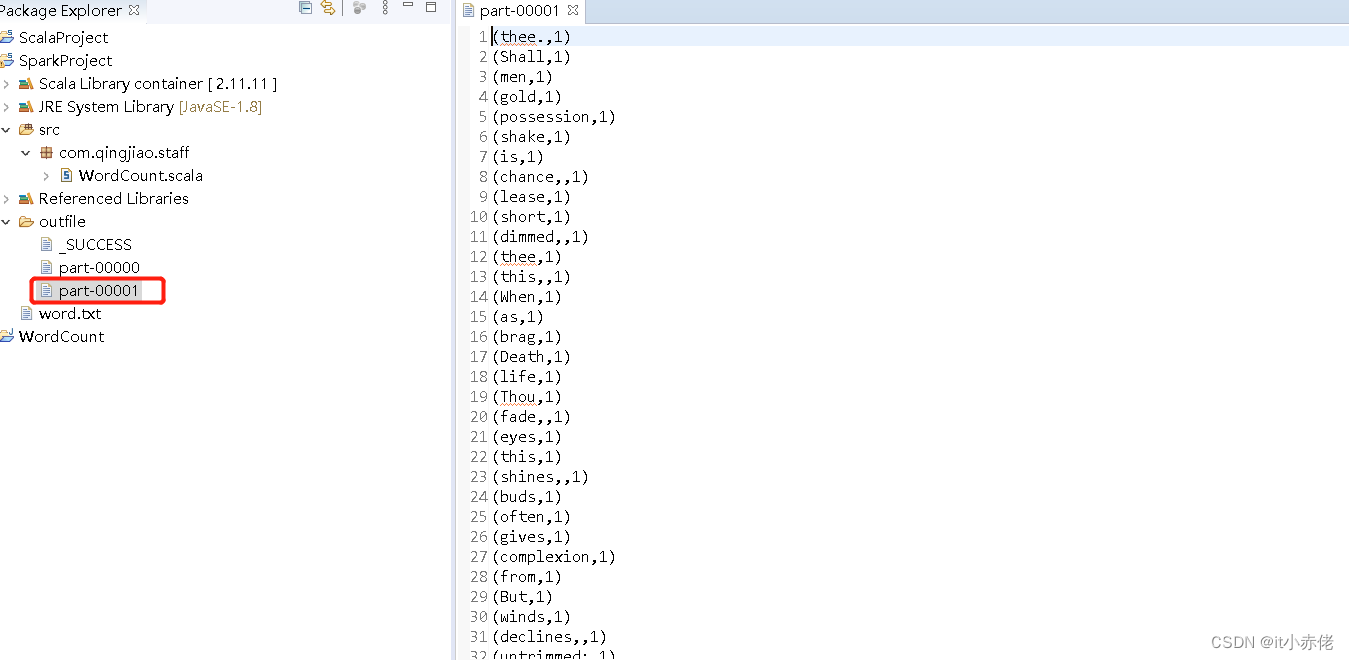
5.6 查看运行结果
6 打jar包
6.1 修改配置
上述程序是在自己系统中以本地模式进行测试使用的,要想放在集群上运行,我们可以将写好的程序打包,上传至集群,使用spark-submit方式进行提交。
提交时,需要注意运行模式和数据路径,如下图:
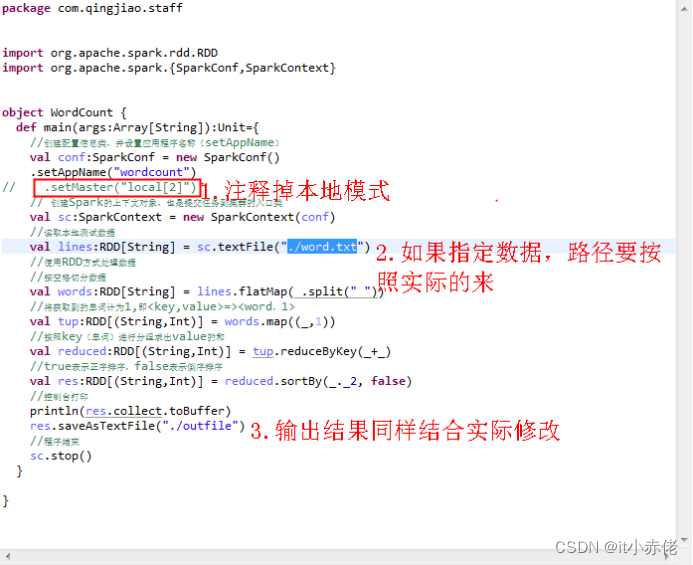
6.2 Export
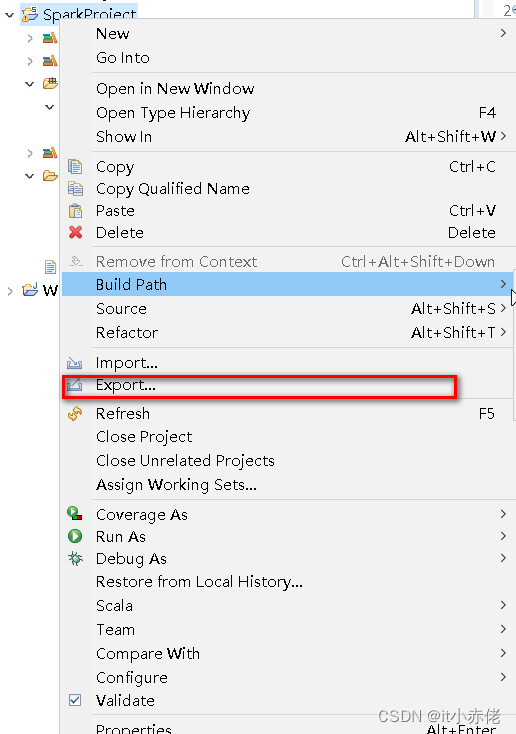
修改好代码之后,点击【想要打包的项目】(注:一定是项目),右键选择【Export】。
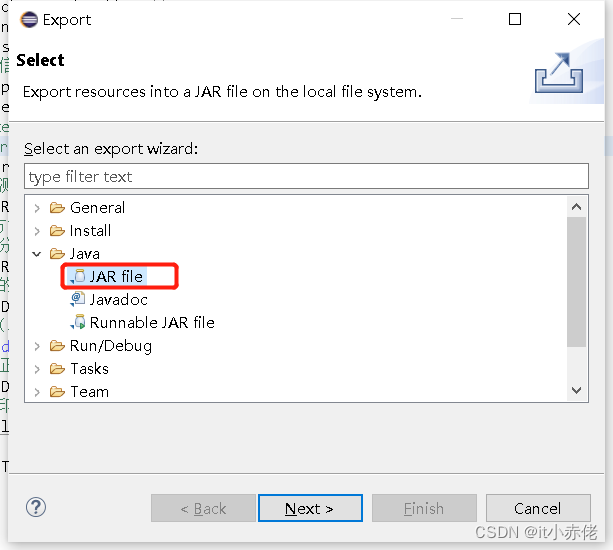
6.3 选择导出【JAR file】
6.4 选择导出路径
选择我们要导出的项目文件,自行选择生成路径。

6.5 检查jar包

6.6 提交集群
- jar包上传至hadoop伪分布式环境集群,使用命令就可以直接提交任务了。
使用spark-submit提交jar包程序,指定master为master节点,以及指定程序对应类和jar包:
spark-submit --master spark://hadoop000:7077 --class com.hongya.staff.WordCount /root/sparksql.jar参数说明:
–master: 设置主节点 URL 的参数。支持:
local: 本地机器。
spark://host:port:远程Spark单机集群。
yarn:yarn 集群
-- class 指定程序对应类















 3926
3926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









