









将线性模型用于 多分类问题
优点、 缺点和参数
线性模型的主要参数是正则化参数,在回归模型中叫作 alpha,
在 LinearSVC 和 LogisticRegression 中叫作 C。 alpha 值较大或 C 值较小,说明模型比较简单。
特别是对于回归模型而言,调节这些参数非常重要。通常在对数尺度上对 C 和 alpha 进行搜索。
还需要确定用的是 L1 正则化还是 L2 正则化。
如果你假定只有几个特征是真正重要的,那么你应该用
L1 正则化,否则应默认使用 L2 正则化。
如果模型的可解释性很重要的话,使用 L1 也会有帮助。由于 L1 只用到几个特征,所以更容易解释哪些特征对模型是重要的,以及这些
特征的作用。
线性模型的训练速度非常快,预测速度也很快。这种模型可以推广到非常大的数据集,对
稀疏数据也很有效。
如果你的数据包含数十万甚至上百万个样本,你可能需要研究如何使
用 LogisticRegression 和 Ridge 模型的 solver=‘sag’ 选项,在处理大型数据时,这一选项
比默认值要更快。其他选项还有 SGDClassifier 类和 SGDRegressor 类,它们对本节介绍的
线性模型实现了可扩展性更强的版本
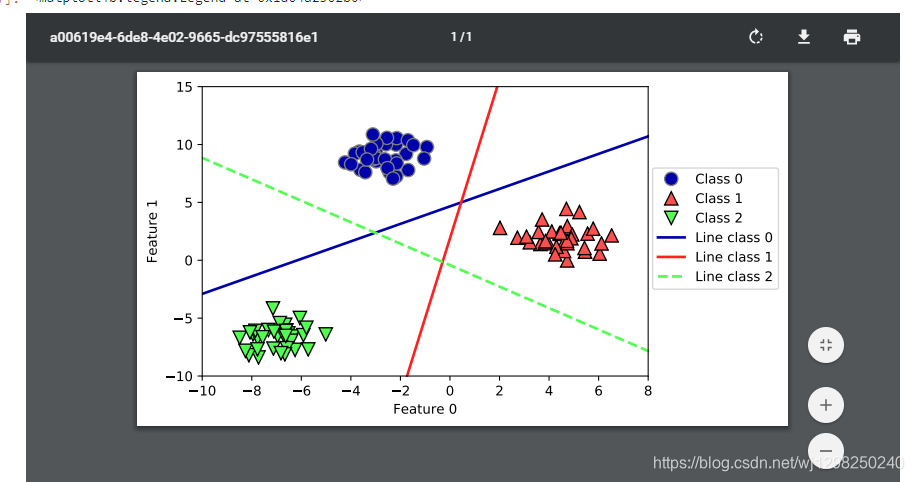
# 我们将这 3 个二类分类器给出的直线可视化
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_,
mglearn.cm3.colors):
plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)
plt.ylim(-10, 15)
plt.xlim(-10, 8)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(['Class 0', 'Class 1', 'Class 2', 'Line class 0', 'Line class 1',
'Line class 2'], loc=(1.01, 0.3))
# 你可以看到,训练集中所有属于类别 0 的点都在与类别 0 对应的直线上方,这说明它们位
# 于这个二类分类器属于“类别 0”的那一侧。属于类别 0 的点位于与类别 2 对应的直线上
# 方,这说明它们被类别 2 的二类分类器划为“其余”。属于类别 0 的点位于与类别 1 对应
# 的直线左侧,这说明类别 1 的二元分类器将它们划为“其余”。因此,这一区域的所有点
# 都会被最终分类器划为类别 0(类别 0 的分类器的分类置信方程的结果大于 0,其他两个
# 类别对应的结果都小于 0)。
# 但图像中间的三角形区域属于哪一个类别呢, 3 个二类分类器都将这一区域内的点划为
# “其余”。这里的点应该划归到哪一个类别呢?答案是分类方程结果最大的那个类别,即最
# 接近的那条线对应的类别
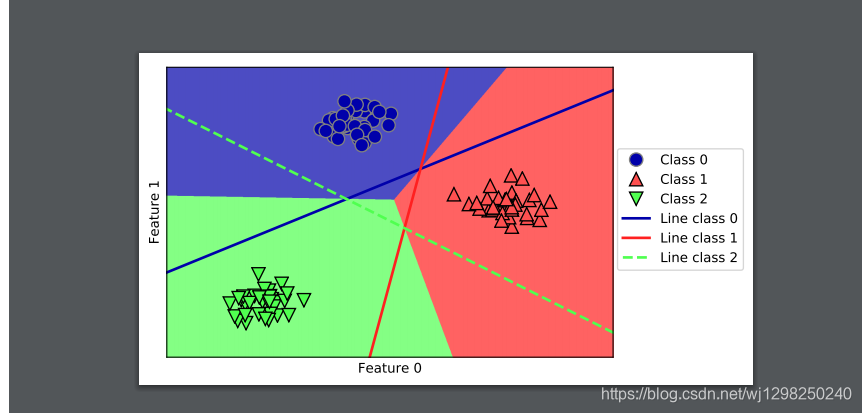
# 下面的例子(图 2-21)给出了二维空间中所有区域的预测结果
mglearn.plots.plot_2d_classification(linear_svm, X, fill=True, alpha=.7)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_,
mglearn.cm3.colors):
plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)
plt.legend(['Class 0', 'Class 1', 'Class 2', 'Line class 0', 'Line class 1',
'Line class 2'], loc=(1.01, 0.3))
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
# 7. 优点、 缺点和参数
# 线性模型的主要参数是正则化参数,在回归模型中叫作 alpha,在 LinearSVC 和 LogisticRegression 中叫作 C。 alpha 值较大或 C 值较小,说明模型比较简单。特别是对于回归模型
# 而言,调节这些参数非常重要。通常在对数尺度上对 C 和 alpha 进行搜索。你还需要确定
# 的是用 L1 正则化还是 L2 正则化。如果你假定只有几个特征是真正重要的,那么你应该用
# L1 正则化,否则应默认使用 L2 正则化。如果模型的可解释性很重要的话,使用 L1 也会
# 有帮助。由于 L1 只用到几个特征,所以更容易解释哪些特征对模型是重要的,以及这些
# 特征的作用。
# 线性模型的训练速度非常快,预测速度也很快。这种模型可以推广到非常大的数据集,对
# 稀疏数据也很有效。如果你的数据包含数十万甚至上百万个样本,你可能需要研究如何使
# 用 LogisticRegression 和 Ridge 模型的 solver='sag' 选项,在处理大型数据时,这一选项
# 比默认值要更快。其他选项还有 SGDClassifier 类和 SGDRegressor 类,它们对本节介绍的
# 线性模型实现了可扩展性更强的版本














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









