







本文章拟解决问题(不是这些问题请绕路):
DataFrame中的JSON、dict、map、key:value类型的数据解析、处理。JSON、dict、map、key:value格式的数据被通过pandas读取后变成了str或者是object等类型。DataFrame中的字典类型数据解析成新的DataFrame对象。DataFrame中的字典类型数据解析成新的DataFrame对象,并与之前的DataFrame合并成一个DataFrame对象。- 对
DataFrame中的list格式的列进行炸裂,一行变成多行,列表中的列元素被拆开成单独的一行。 - 使用
explode()函数对DataFrame进行炸裂。
一、需求
数据库中有一张传感器的数据表,如下图所示:其中的 data 字段中的数据是列表(数组),列表(数组)里面的元素是 JSON、或者说是 key:value 、 map 格式,现在是需要将 key:value 解析出来。
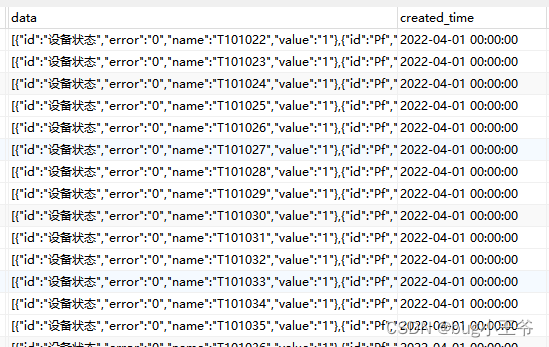
下面是表中前几条数据:表头——id, data, create_time
id data created_time
1 [{"id":"设备状态","error":"0","name":"T101022","value":"1"},{"id":"Pf","error":"0","value":"0.943000"},{"id":"Fr","error":"0","value":"50.029999"},{"id":"Pfa","error":"0","value":"0.936000"},{"id":"Pfb","error":"0","value":"0.945000"},{"id":"Pfc","error":"0","value":"0.956000"},{"id":"EPI","error":"0","value":"2867518.750000"},{"id":"EPE","error":"0","value":"572.519958"},{"id":"EQL","error":"0","value":"965824.437500"},{"id":"EQC","error":"0","value":"13.120000"},{"id":"Ua","error":"0","value":"239.500000"},{"id":"Ub","error":"0","value":"241.000000"},{"id":"Uc","error":"0","value":"240.400009"},{"id":"Ia","error":"0","value":"421.200012"},{"id":"Ib","error":"0","value":"388.200012"},{"id":"Ic","error":"0","value":"423.000000"},{"id":"Uab","error":"0","value":"416.100037"},{"id":"Ubc","error":"0","value":"416.900024"},{"id":"Uca","error":"0","value":"415.600006"},{"id":"P","error":"0","value":"279.000000"},{"id":"Pa","error":"0","value":"94.200005"},{"id":"Pb","error":"0","value":"88.199997"},{"id":"Pc","error":"0","value":"96.599998"},{"id":"Q","error":"0","value":"80.400002"},{"id":"Qa","error":"0","value":"30.599998"},{"id":"Qb","error":"0","value":"24.600000"},{"id":"Qc","error":"0","value":"23.400000"},{"id":"Sa","error":"0","value":"100.799995"},{"id":"Sb","error":"0","value":"93.599998"},{"id":"Sc","error":"0","value":"103.200005"},{"id":"S","error":"0","value":"297.600006"}] 2022-04-01 00:00:00
2 [{"id":"设备状态","error":"0","name":"T101023","value":"1"},{"id":"Pf","error":"0","value":"-0.004000"},{"id":"Fr","error":"0","value":"50.020000"},{"id":"Pfa","error":"0","value":"0.139000"},{"id":"Pfb","error":"0","value":"-0.299000"},{"id":"Pfc","error":"0","value":"0.187000"},{"id":"EPI","error":"0","value":"599556.000000"},{"id":"EPE","error":"0","value":"1714.469971"},{"id":"EQL","error":"0","value":"165549.343750"},{"id":"EQC","error":"0","value":"297128.687500"},{"id":"Ua","error":"0","value":"239.000000"},{"id":"Ub","error":"0","value":"240.800003"},{"id":"Uc","error":"0","value":"240.000000"},{"id":"Ia","error":"0","value":"48.720001"},{"id":"Ib","error":"0","value":"86.400002"},{"id":"Ic","error":"0","value":"96.479996"},{"id":"Uab","error":"0","value":"415.499969"},{"id":"Ubc","error":"0","value":"416.300018"},{"id":"Uca","error":"0","value":"414.799988"},{"id":"P","error":"0","value":"-0.240000"},{"id":"Pa","error":"0","value":"1.600000"},{"id":"Pb","error":"0","value":"-6.160000"},{"id":"Pc","error":"0","value":"4.320000"},{"id":"Q","error":"0","value":"-52.480003"},{"id":"Qa","error":"0","value":"-11.200000"},{"id":"Qb","error":"0","value":"-19.199999"},{"id":"Qc","error":"0","value":"-22.080000"},{"id":"Sa","error":"0","value":"11.599999"},{"id":"Sb","error":"0","value":"20.799999"},{"id":"Sc","error":"0","value":"23.120001"},{"id":"S","error":"0","value":"55.520000"}] 2022-04-01 00:00:00
3 [{"id":"设备状态","error":"0","name":"T101024","value":"1"},{"id":"Pf","error":"0","value":"-0.004000"},{"id":"Fr","error":"0","value":"50.029999"},{"id":"Pfa","error":"0","value":"0.211000"},{"id":"Pfb","error":"0","value":"-0.120000"},{"id":"Pfc","error":"0","value":"-0.114000"},{"id":"EPI","error":"0","value":"93052.085938"},{"id":"EPE","error":"0","value":"1660.539917"},{"id":"EQL","error":"0","value":"75957.359375"},{"id":"EQC","error":"0","value":"348346.218750"},{"id":"Ua","error":"0","value":"239.100006"},{"id":"Ub","error":"0","value":"240.800003"},{"id":"Uc","error":"0","value":"240.100006"},{"id":"Ia","error":"0","value":"77.839996"},{"id":"Ib","error":"0","value":"59.599998"},{"id":"Ic","error":"0","value":"89.680008"},{"id":"Uab","error":"0","value":"415.600006"},{"id":"Ubc","error":"0","value":"416.499969"},{"id":"Uca","error":"0","value":"414.900024"},{"id":"P","error":"0","value":"-0.160000"},{"id":"Pa","error":"0","value":"3.920000"},{"id":"Pb","error":"0","value":"-1.680000"},{"id":"Pc","error":"0","value":"-2.400000"},{"id":"Q","error":"0","value":"-52.399998"},{"id":"Qa","error":"0","value":"-17.760000"},{"id":"Qb","error":"0","value":"-13.839999"},{"id":"Qc","error":"0","value":"-20.799999"},{"id":"Sa","error":"0","value":"18.559999"},{"id":"Sb","error":"0","value":"14.320001"},{"id":"Sc","error":"0","value":"21.440001"},{"id":"S","error":"0","value":"54.320000"}] 2022-04-01 00:00:00
二、操作步骤
1.从数据库中读入数据
source = pd.read_sql(sql="""
SELECT
id,
`data`,
created_time
FROM
table_name
""", con=con)
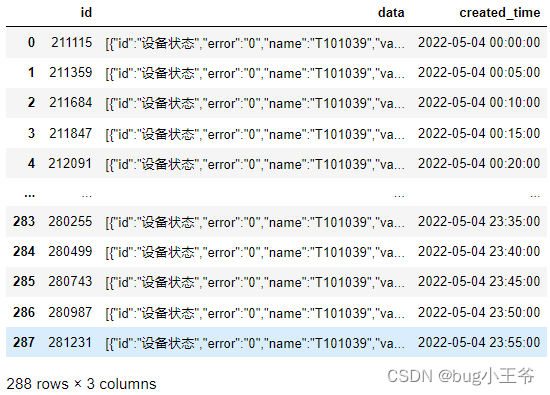
读入的原始数据如图:
2.将数据炸裂:将JSON列表拆分,一个JSON对象占一行
1). 具体的代码过程:
踩坑:因为pandas读入数据,将 JSON列表 格式当做 object,所以在数据炸裂前需要先将数据格式改成 list。
# 将 data 列的数据类型 object 转成 str,并将原始数据中的 '['、']'删除
source['data'] = source['data'].str.replace('[', '')
source['data'] = source['data'].str.replace(']', '')
# 将 JSON列表 中的JSON对象之间使用 ‘#’隔开
source['data'] = source['data'].str.replace('},{', '}#{')
# 使用 lambda 表达式,按照 ‘#’ 切割str, 就能得到数据格式为 list 的列表
source['data'] = source['data'].apply(lambda x: x.split('#'))
# 使用 explode() 函数对列表进行炸裂,一行变多行
data = source.explode('data')
data
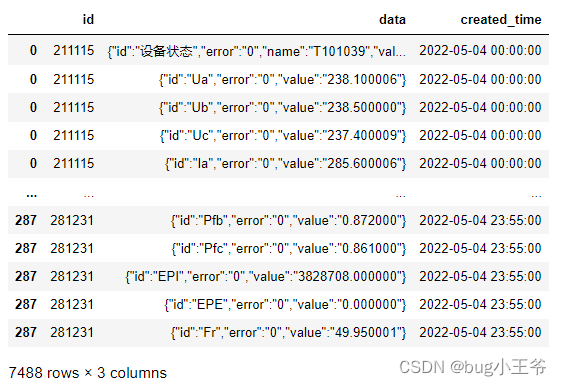
2). 数据炸裂结果,如下图所示:数据规模 从 288 * 3 变成 7488 * 3,原始数据中的JSON列表已经被拆成一个一个的JSON对象。
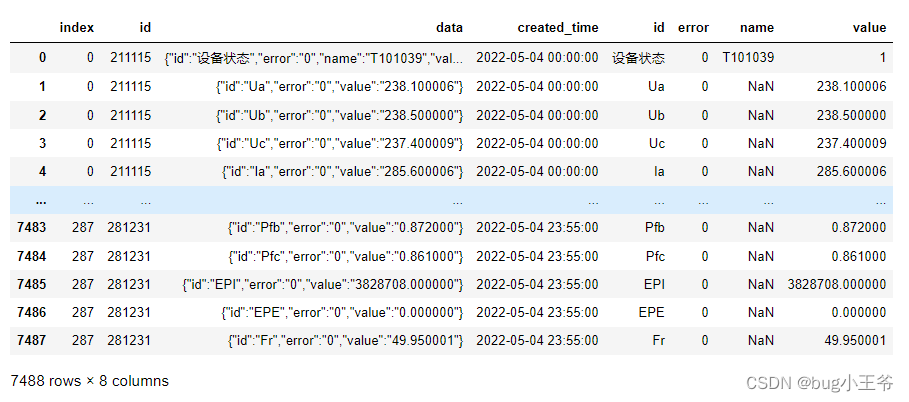
3). 处理 DataFrame 中的 JSON、dict、map、key:value 对象:将 字典中的数据 key 作为列名, value为每一行的解析结果保留,如下图所示:
具体的代码为:
# 重新设置 DataFrame 的 index
data = data.reset_index()
# 将 JSON 所在列转成 list 类型
list_tmp = data['data'].values.tolist()
tmp = []
# 遍历 JSON 所在的列,将每一个 str 对象转成 JSON(因为现在,JSON的格式默认为 str)
for index in range(len(list_tmp)):
tmp.append(json.loads(list_tmp[index]))
# list 转成 新的 DataFrame 对象
list_to_dict = pd.DataFrame(tmp)
#将两个 DataFrame 对象 合并
result = pd.concat([data,list_to_dict],axis=1)
result.to_excel(r'C:\Users\Dell\Desktop\字典结果.xlsx')
result
4). 验证数据是否解析有误,如下图所示,为写出Excel表的结果:
总结
- 使用
explode()行数对DataFrame进行炸裂,需要保证炸裂的目标列的格式是list - 小技巧:如果
DataFrame的某一列本该是list,但是被当做object、str等类型时,可以将该列当做转成str后,在列表元素之间 使用特殊符号(该符号不能在列表中出现过,不然切割时会污染原始数据)来进行隔开,然后使用split对该列进行切割,即可将该列转变成list格式了。 - DataFrame中的JSON解析:将字段Key作为列名,value作为列值生成多列。















 2490
2490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









