







目录
5.1.1获取前两个索引对应的行,即行索引为 '一' 和 '二' 的行
1.课前准备:
(1)python可视化免费软件(官网:Project Jupyter | Home):
Jupyter Notebook (anaconda)
(2) 会动的脑袋瓜子
(3)本篇阅读完有啥不理解的可以在评论区留言哈。
2.数据编辑操作是什么
层级索引是Pandas库中用于表示高维数据的一种索引方式,它允许在一个轴上拥有多个(两个以上)索引级别。
在数据分析中,层级索引的使用可以带来以下好处:
- 多维度数据管理:层级索引使用户能够以低维度的形式处理高维度数据,这在处理复杂的数据集时非常有用。
- 更灵活的索引操作:通过层级索引,可以实现更加灵活的数据操作,如根据特定层级进行数据的选取、重排和汇总统计等。
- 方便的数据重塑:使用层级索引,可以方便地进行数据的堆叠(stack)和展开(unstack),以及设置索引(set_index)和重置索引(reset_index)等操作,这些操作对于数据整理和分析至关重要。
- 提高数据可读性:层级索引有助于提高数据的可读性和理解性,尤其是在处理具有多个分类变量的数据集时。
- 简化复杂查询:当数据集中存在多层次的分类信息时,层级索引可以简化复杂查询的操作,使得数据筛选更加直观和高效。
3.创建层级索引:轴上有多个索引
3.1创建Series的层级索引
首先创建一个Series对象
s1=Series(["xiaowang","1班","xiaoli","二班"],index=[[1,2,3,3],["姓名","班级","姓名","班级"]])
s1
其次建立层次化索引(hierarchical index),由两个级别的索引组成。
第一个级别是数字 [1, 2, 3, 3],表示每个数据值对应的行号。第二个级别是字符串 ["姓名", "班级", "姓名", "班级"],表示每个数据值对应的列名。
s1.index
3.2 创建DataFrame的层级索引
3.2.1隐式构造层级索引
首先,我们需要导入pandas库,然后创建一个numpy数组data1,接着使用这个数组和指定的列名、索引来创建一个DataFrame df1。
from_arrays:这个方法通过接受一个数组列表作为输入,其中每个数组代表 MultiIndex 的一个层级。这些数组按照提供的顺序被组合成多级索引。
data1 = np.array([["小张", "男", 20], ["小王", "女", 19], ["小杨", "男", 19], ["小李", "男", 21]])
df1 = DataFrame(data1, columns=["姓名", "性别", "年龄"],
index=pd.MultiIndex.from_arrays([[1, 1, 2, 2], ["班长", "学委", "班长", "学委"]]))
df1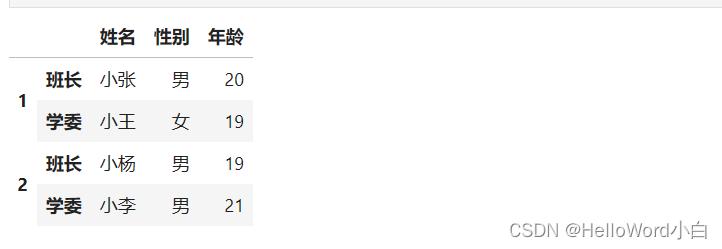
或者:
from_product:此方法用于根据提供的可迭代对象集合之间的笛卡尔积来创建 MultiIndex。也就是说,它会生成所有可能的组合,适用于需要交叉迭代多个集合来创建索引的场景。
import numpy as np
import pandas as pd
from pandas import DataFrame
data1 = np.array([["小张", "男", 20], ["小王", "女", 19], ["小杨", "男", 19], ["小李", "男", 21]])
df1 = DataFrame(data1, columns=["姓名", "q性别", "年龄"],
index=pd.MultiIndex.from_tuples([[1, 1, 2, 2], ["班长", "学委", "班长", "学委"]]))
df13.2.2 显示构造 pd.MultiIndex
首先,创建一个 Pandas Series
from pandas import Series,DataFrame
import numpy as np
import pandas as pd
s1=Series(["小王","一班","小李","二班"],index=[[1,1,2,2],["姓名","班级","姓名","班级"]])
s1
3.3层级索引对象元素操作
3.3.1Series的元素操作
首先创建一个对象
s1=Series(["小王","一班","小李","二班"],index=[[1,1,2,2],["姓名","班级","姓名","班级"]])
s1
slice(1, 3) 创建一个从 1 到 3 的切片,不包括 3,对应于第一级索引
s1.iloc[0:3] #自动索引 左闭右开
相关例子:
s1.iloc[1:1] 
s1.iloc[1:2] 
3.3.2 DataFrame的元素操作
首先创建一个对象
from pandas import Series,DataFrame
import numpy as np
data1=np.array([["小张","男",20],["小王","女",19],["小杨","男",19],["小李","男",21]])
df=DataFrame(data1,columns=["姓名","性别","年龄"],
index=[["一班","一班","二班","二班 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









