







目录
9.1.read、readline和readlines方法读取文件
9.1.4 使用write和writelines方法写入文件
10.3 改变文件指针的位置。seek()方法用于移动文件指针到指定位置,以便后续的读取或写入操作可以从该位置开始。
11.1.3 使用read_json和to_json读取和存储json文件
11.2.1使用pandas的read——excel读取excel文件
11.2.2使用pandas的read_excel读取excel文件
11.2.3使用pandas的to_excel写入excel文件
11.2.5 pandas的ExcelWriter方法同时写入多个sheet
1.课前准备:
(1)python可视化免费软件(官网:Project Jupyter | Home):
Jupyter Notebook (anaconda)
(2) 会动的脑袋瓜子
(3)本篇阅读完有啥不理解的可以在评论区留言哈。
2.数据编辑操作是什么
Pandas可视化是指使用Pandas库进行数据可视化处理,帮助分析者更直观地展示和理解数据。

3.库包
| 代码行 | 解释 |
|---|---|
import pandas as pd |
导入Pandas库,并将其命名为pd。Pandas是一个强大的数据分析库,提供了数据结构和数据分析工具,用于处理和操作结构化数据。 |
import matplotlib as mpl |
导入Matplotlib库,并将其命名为mpl。Matplotlib是一个用于绘制图表和可视化数据的库,提供了各种绘图功能和样式选项。 |
import matplotlib.pyplot as plt |
导入Matplotlib库中的pyplot模块,并将其命名为plt。pyplot是Matplotlib的一个子模块,提供了类似于MATLAB的绘图接口,方便进行简单的图表绘制。 |
mpl.rcParams["font.sans-serif"] = ["SimHei"] |
设置Matplotlib的字体参数,将字体设置为"SimHei"。"SimHei"是一种中文字体,用于解决中文显示问题。通过设置字体为"SimHei",可以确保在图表中正确显示中文字符。 |
4.折线图
案例1:
使用matplotlib库绘制了一条折线图,x轴为[1, 2, 3, 4, 5],y轴为[1, 6, 5, 19, 10]。最后通过plt.show()显示该图形。
plt.plot([1, 2, 3, 4, 5], [1, 6, 5, 19, 10])
plt.show()
案例2:
创建一个DataFrame
计算'year'列的累积和,并将结果存储在'cumsum0'列中
使用matplotlib的pyplot模块绘制'cumsum0'列的折线图,kind="line" 表示绘制折线图,linestyle="-." 表示线的样式为点划线,marker="s" 表示数据点的样式为正方形,color="#ff0000" 表示线的颜色为红色,linewidth=1 表示线的宽度为1,alpha=0.8 表示透明度为0.8,markersize=6 表示数据点的大小为6
显示绘制的图形
import pandas as pd
import matplotlib.pyplot as plt
data = {
'name': ['陈五', '王四', '马三', '刘一'],
'sex': ['男', '女', '男', '男'],
'year': [2000, 2001, 2003, 2002],
'city': ['武汉', '云南', '广州', '上海']}
df = pd.DataFrame(data)
df['cumsum0'] = df['year'].cumsum()
df['cumsum0'].plot(kind="line", linestyle="-.", marker="s", color="#ff0000", linewidth=1, alpha=0.8, markersize=6)
plt.show()
5.条形图(柱状图)
案例1:
-
df['sex'].value_counts(): 这部分代码的作用是统计DataFrame中sex列(性别列)每个唯一值(即男性和女性)出现的次数。value_counts()是一个pandasSeries的方法,它会返回一个新的Series,其中的索引是原始Series中的唯一值,值是这些唯一值在原始Series中出现的次数。 -
.plot(kind='bar', color='y'): 这部分代码的作用是将上一步得到的Series(即性别分布次数)绘制成柱状图。kind='bar'指定了要绘制的图形类型为柱状图,color='y'指定了柱状图的颜色为黄色。
df['sex'].value_counts().plot(kind='bar',color='y')
案例2:
-
设置了Matplotlib的默认无衬线字体为“黑体”
-
这行代码解决了在图表中负号'-'显示为方块的问题。
-
df['sex'].value_counts(): 这部分代码的作用是统计DataFrame中sex列(性别列)每个唯一值(例如男性和女性)出现的次数。value_counts()会返回一个Series对象,其中的索引是sex列中的唯一值,值是这些唯一值在sex列中出现的次数。plot(kind='barh', color='r'): 这部分代码的作用绘制成横向的柱状图(horizontal bar chart)。kind='barh'指定了要绘制的图形类型为横向柱状图,color='r'指定了柱状图的颜色为红色。 -
设置正标题及行列标题
-
显示图形
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df['sex'].value_counts().plot(kind='barh', color='r')
plt.title('性别分布')
plt.xlabel('数量')
plt.ylabel('性别')
plt.show()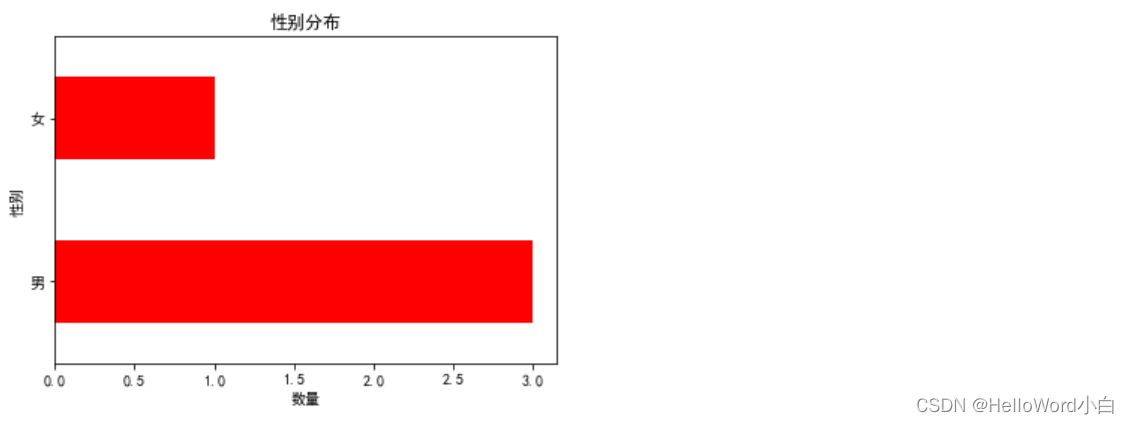
6.直方图和密度图
6.1直方图:
案例1:
- 代码使用numpy的
random.normal函数生成了80个从标准正态分布(均值为0,标准差为1)中抽取的随机数。然后,使用pandas的Series对象来封装这些随机数。 np.random.normal(size=80):生成一个大小为80的数组,数组中的元素是从标准正态分布中随机抽取的。pd.Series(...):将生成的数组转换为pandas的Series对象。sl.hist(bins=20, grid=False, color='c')使用pandas的hist方法绘制Series对象sl的直方图。bins=20:指定直方图中的数据分箱数量为20。也就是说,数据会被分成20个区间,然后统计每个区间内的数据点数量。grid=False:这个参数实际上在pandas的hist方法中并不存在。
sl=pd.Series(np.random.normal(size=80))
sl.hist(bins=20,grid=False,color='c') 
案例2:
您创建了一个名为df1的pandas DataFrame,其中包含三列数据:
plt.rcParams['axes.unicode_minus'] = False,这是为了解决在绘制图形时负号显示为方块的问题。'N1'列包含从标准正态分布中随机抽取的30个数值。'N2'列包含从形状参数为1的伽马分布中随机抽取的30个数值。'N3'列包含从泊松分布(此处参数未明确给出,默认为1)中随机抽取的30个数值。-
df1.hist(bins=20, grid=False, color='c'):这将为每个数值列('N1', 'N2', 'N3')绘制一个直方图,并将它们放在同一个图形窗口中。bins=20指定了每个直方图中的数据分箱数量为20,grid=False表示不显示网格线,color='c'设置了直方图的颜色为青色。 -
df1.plot(kind="hist", bins=20, grid=True):这也是绘制直方图的方法,但是与第一种方法不同,df.plot()方法提供了更灵活的绘图选项。kind="hist"表示要绘制的是直方图,bins=20和grid=True的含义与前面相同。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['axes.unicode_minus'] = False
df1 = pd.DataFrame({'N1': np.random.normal(size=30),
'N2': np.random.gamma(1,size=30),
'N3': np.random.poisson(size=30)})
df1.hist(bins=20, grid=False, color='c')
df1.plot(kind="hist",bins=20,grid=True) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









