







目录
4.1.2 判断索引是否包含在Index对象中---in()
4.1.4 计算索引的差集difference()、交集intersection()和并集union()
4.4 重新索引:不修改索引对象;重新引用时,如果某个索引值不存在就引入缺失值
1.课前准备:
(1)python可视化免费软件(官网:Project Jupyter | Home):
Jupyter Notebook (anaconda)
(2) 会动的脑袋瓜子
(3)本篇阅读完有啥不理解的可以在评论区留言哈。
2.数据编辑操作是什么
数据最常用的操作就是增、删、改、查。DataFrame作为一种二维数据表结构,同样能够像数据库一样,非常方便地实现“增删改查”操作。
其编辑要点就是:先选取,然后操作
3.增删改查操作
3.1增加元素
案例1:
新建一个DataFrame对象
data={
'name':['陈五','王四','刘一','马三'],
'sex':['男','女','女','男'],
'year':[2000,2001,2003,2002],
'city':['武汉','云南','广州','上海']
}
df2 = DataFrame(data,index=['a', 'b', 'c','d'])
df2
创建一个新的列'age',其值等于2023减去'year'列的值
df2['age']= 2024-df2['year']
df2
案例2:
使用insert方法来插入新的列,在第3列位置插入了一个新的列'Score',其值全部为80。
df2.insert(3,"Score",80)
df2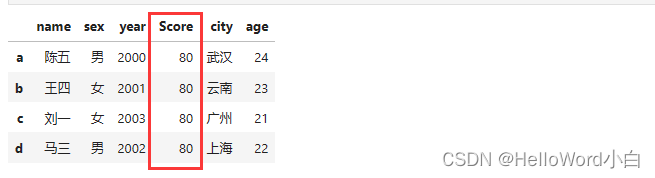
案例3:
在df2中插入一个新的行,其索引为'z',值为['张三', '男', '2000', '80', '重庆', '23']
df2.loc['z'] = ['张三', '男', '2000', '80', '重庆', '23']
df2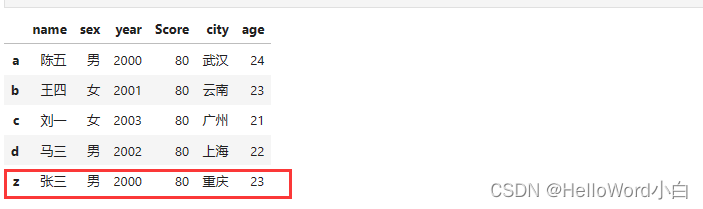
3.2修改元素
案例1:
使用iloc方法来插入新的行,在df2的第5行位置插入了一个新的行,其值为['张三', '男', '2000', '80', '北京', '20']。
df2.iloc[4] = ['张三', '男', '2000', '80', '北京', '20']
df2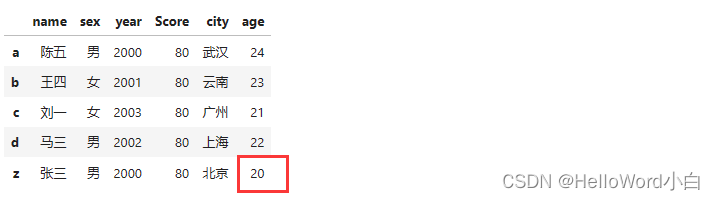
案例2:
df2中第2行的'sex'列的值修改为'男'
df2["sex"][1] = "男"
df2
3.3删除元素
案例1:
删除df2中的'score'列,del关键字是Python中的一个内置关键字,用于从内存中删除对象
del df2["Score"]
df2
案例2:
删除df2中的'age'列,pop()函数在Pandas中用于删除DataFrame中的指定列,并将其返回为一个Series
df2.pop("age")
df2
案例3:
删除d行.
drop(): 这是DataFrame对象的一个方法,用于删除指定的行或列。
"d": 这是要删除的行的标签或索引。在这个例子中,它表示要删除名为"d"的行。
axis=0: 这个参数指定了删除操作的方向。当axis=0时,表示沿着行方向进行删除操作。
inplace=True: 这个参数指定了是否在原始DataFrame上进行修改。如果设置为True,则直接在原始DataFrame上进行删除操作,而不会返回一个新的DataFrame对象。
df2. drop("d", axis=0, inplace=True)
df2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2378
2378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









