






首先我们随机生成一批数据文件;

可以看到我们总共生成了500万条数,均匀分到20个文件中,全部数据大约220M。
现在,我们用python中标准的文件读取方式读入数据,测试结果如下:

读入仅仅只需3秒。
我们接着重复读10次:

耗时31.6秒,大约是单遍读取时间的10倍。
接着我们用tensorflow的dataset试试看,测试结果如下:
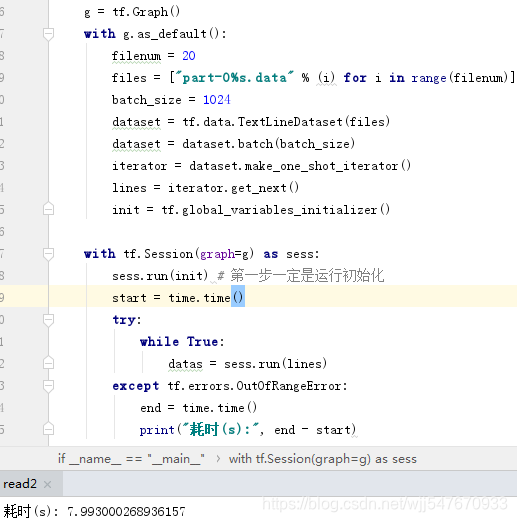
可以看到耗时8秒。
下面让epoch为10再看看dataset的耗时:

耗时80秒,刚好是单个epoch的10倍。
下面加入shuffle且让epoch为10再看看dataset的耗时:

耗时122秒,可以发现shuffle会增加大约一半的耗时。至此,我们可以断定,在我们测试这种场景下dataset性能实在不怎么样。














 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









