









N-BEATS
在这个笔记本中,我们展示了如何使用darts来使用N-BEATS。如果您是darts的新手,我们建议您首先跟随快速入门笔记本。
N-BEATS是一种最先进的模型,展示了在时间序列预测的背景下纯DL架构的潜力。它在M3和M4竞赛中优于成熟的统计方法。有关该模型的更多详细信息,请参见:https://arxiv.org/pdf/1905.10437.pdf。
# 导入fix_pythonpath_if_working_locally函数
from utils import fix_pythonpath_if_working_locally
# 调用fix_pythonpath_if_working_locally函数,用于修复本地Python路径
fix_pythonpath_if_working_locally()
# 在Jupyter Notebook中使用matplotlib绘图时,需要使用%matplotlib inline命令
%matplotlib inline
# 导入所需的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入darts库中的相关模块和函数
from darts import TimeSeries, concatenate
from darts.utils.callbacks import TFMProgressBar
from darts.models import NBEATSModel
from darts.dataprocessing.transformers import Scaler, MissingValuesFiller
from darts.metrics import mape, r2_score
from darts.datasets import EnergyDataset
from darts import concatenate
# 忽略警告信息
import warnings
warnings.filterwarnings("ignore")
# 禁用日志输出
import logging
logging.disable(logging.CRITICAL)
# 定义一个函数,用于生成torch模型的参数
def generate_torch_kwargs():
# 在CPU上运行torch模型,并且除了训练阶段,禁用所有模型阶段的进度条
return {
"pl_trainer_kwargs": {
"accelerator": "cpu",
"callbacks": [TFMProgressBar(enable_train_bar_only=True)],
}
}
def display_forecast(pred_series, ts_transformed, forecast_type, start_date=None):
plt.figure(figsize=(8, 5))
if start_date:
ts_transformed = ts_transformed.drop_before(start_date)
ts_transformed.univariate_component(0).plot(label="actual")
pred_series.plot(label=("historic " + forecast_type + " forecasts"))
plt.title(
"R2: {}".format(r2_score(ts_transformed.univariate_component(0), pred_series))
)
plt.legend()
每日能源发电示例
我们在一家溪流发电厂的日常能源生成数据集上对NBEATS进行测试,因为该数据集展示了不同级别的季节性。
# 创建一个EnergyDataset对象,并调用load方法加载数据集
df = EnergyDataset().load()
# 将加载的数据集转换为Pandas DataFrame格式
df = df.pd_dataframe()
# 使用DataFrame中的某一列数据绘制折线图
df["generation hydro run-of-river and poundage"].plot()
# 设置折线图的标题
plt.title("Hourly generation hydro run-of-river and poundage")
Text(0.5, 1.0, 'Hourly generation hydro run-of-river and poundage')
为了简化事情,我们使用每日发电量,并使用“MissingValuesFiller”填充数据中存在的缺失值。
# 对原始数据进行按日期分组,并计算每天的平均值
df_day_avg = df.groupby(df.index.astype(str).str.split(" ").str[0]).mean().reset_index()
# 创建MissingValuesFiller对象
filler = MissingValuesFiller()
# 创建Scaler对象
scaler = Scaler()
# 将数据转换为TimeSeries对象,并填充缺失值
series = filler.transform(
TimeSeries.from_dataframe(
df_day_avg, "time", ["generation hydro run-of-river and poundage"]
)
).astype(np.float32)
# 将数据划分为训练集和验证集
train, val = series.split_after(pd.Timestamp("20170901"))
# 对训练集进行缩放
train_scaled = scaler.fit_transform(train)
# 对验证集进行缩放
val_scaled = scaler.transform(val)
# 对整个数据集进行缩放
series_scaled = scaler.transform(series)
# 绘制训练集和验证集的折线图
train_scaled.plot(label="training")
val_scaled.plot(label="val")
# 设置图表标题
plt.title("Daily generation hydro run-of-river and poundage")
Text(0.5, 1.0, 'Daily generation hydro run-of-river and poundage')
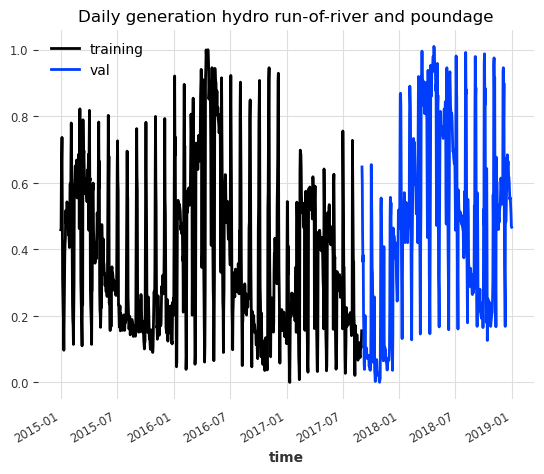
我们将数据分成训练集和验证集。通常情况下,我们需要使用额外的测试集来验证模型在未见过的数据上的表现,但是在这个例子中我们将跳过这一步。
通用架构
N-BEATS是一种单变量模型架构,提供两种配置:一种是通用的,另一种是可解释的。通用架构尽可能少地使用先前的知识,没有特征工程,没有缩放,也没有可能被认为是时间序列特定的内部架构组件。
首先,我们使用一个具有N-BEATS通用架构的模型。
# 定义模型名称为 "nbeats_run"
model_name = "nbeats_run"
# 创建 NBEATSModel 对象,并设置相关参数
model_nbeats = NBEATSModel(
input_chunk_length=30, # 输入序列的长度为30
output_chunk_length=7, # 输出序列的长度为7
generic_architecture=True, # 使用通用的 N-BEATS 架构
num_stacks=10, # 堆叠的块数为10
num_blocks=1, # 每个堆叠中的块数为1
num_layers=4, # 每个块中的层数为4
layer_widths=512, # 每个层的宽度为512
n_epochs=100, # 训练的总轮数为100
nr_epochs_val_period=1, # 每隔1轮进行一次验证
batch_size=800, # 批量大小为800
random_state=42, # 随机种子为42
model_name=model_name, # 模型名称为之前定义的 "nbeats_run"
save_checkpoints=True, # 保存训练过程中的检查点
force_reset=True, # 强制重置模型
**generate_torch_kwargs(), # 使用 generate_torch_kwargs() 函数生成的其他参数
)
# 使用N-BEATS模型对训练数据进行拟合
model_nbeats.fit(train_scaled, val_series=val_scaled)
Training: 0it [00:00, ?it/s]
NBEATSModel(generic_architecture=True, num_stacks=10, num_blocks=1, num_layers=4, layer_widths=512, expansion_coefficient_dim=5, trend_polynomial_degree=2, dropout=0.0, activation=ReLU, input_chunk_length=30, output_chunk_length=7, n_epochs=100, nr_epochs_val_period=1, batch_size=800, random_state=42, model_name=nbeats_run, save_checkpoints=True, force_reset=True, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2b3d98fd0>]})
让我们从在验证集上表现最佳的检查点中加载模型。
# 从checkpoint中加载NBEATS模型
model_nbeats = NBEATSModel.load_from_checkpoint(model_name=model_name, best=True)
让我们来看看模型在不断扩大的训练窗口下以及预测期为7的情况下会产生的历史预测。
# 对于给定的时间序列数据,使用N-BEATS模型进行历史预测
# series_scaled是经过缩放的时间序列数据
# start参数指定预测的起始时间点,这里使用val.start_time()作为起始时间点
# forecast_horizon参数指定预测的时间跨度,这里设置为7天
# stride参数指定预测的时间间隔,这里设置为7天,即每隔7天进行一次预测
# last_points_only参数指定是否只返回最后一个时间点的预测结果,这里设置为False,即返回所有时间点的预测结果
# retrain参数指定是否重新训练模型,这里设置为False,即不重新训练模型
# verbose参数指定是否打印详细信息,这里设置为True,即打印详细信息
pred_series = model_nbeats.historical_forecasts(
series_scaled,
start=val.start_time(),
forecast_horizon=7,
stride=7,
last_points_only=False,
retrain=False,
verbose=True,
)
# 将预测结果连接起来,得到完整的预测序列
pred_series = concatenate(pred_series)
0%| | 0/69 [00:00<?, ?it/s]
# 定义一个函数display_forecast,用于显示预测结果
# 参数pred_series表示预测结果序列
# 参数series_scaled表示原始序列
# 参数"7 day"表示预测的时间范围为7天
# 参数start_date表示预测的起始日期为val.start_time()
display_forecast(
pred_series,
series_scaled,
"7 day",
start_date=val.start_time(),
)
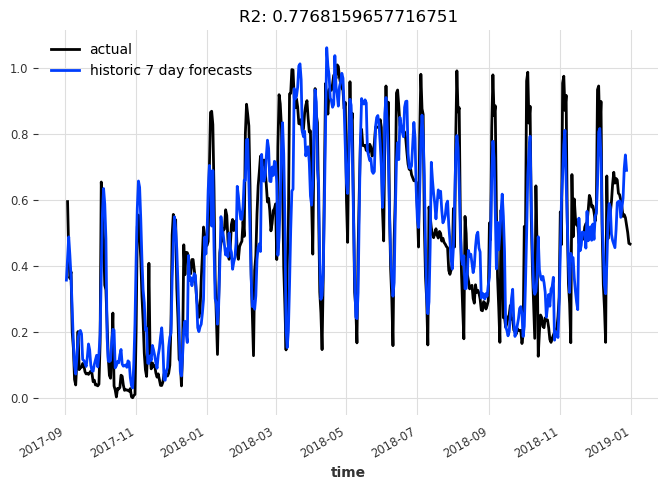
可解释模型
N-BEATS提供了一个可解释的架构,由两个堆栈组成:一个趋势堆栈和一个季节性堆栈。该架构的设计如下:
- 在将输入馈送到季节性堆栈之前,趋势组件将从输入中删除
- 趋势和季节性的部分预测可作为单独的可解释输出。
# 创建一个变量model_name,赋值为"nbeats_interpretable_run"
model_name = "nbeats_interpretable_run"
# 创建一个NBEATSModel对象,传入以下参数进行初始化
# input_chunk_length:输入序列的长度为30
# output_chunk_length:输出序列的长度为7
# generic_architecture:使用非通用架构
# num_blocks:堆叠的块数为3
# num_layers:每个块中的层数为4
# layer_widths:每个层的宽度为512
# n_epochs:训练的总轮数为100
# nr_epochs_val_period:每隔1轮进行一次验证
# batch_size:每个批次的样本数为800
# random_state:随机数生成器的种子为42
# model_name:模型的名称为model_name
# save_checkpoints:保存检查点
# force_reset:强制重置模型
# **generate_torch_kwargs():使用generate_torch_kwargs()函数生成的其他参数
model_nbeats = NBEATSModel(
input_chunk_length=30,
output_chunk_length=7,
generic_architecture=False,
num_blocks=3,
num_layers=4,
layer_widths=512,
n_epochs=100,
nr_epochs_val_period=1,
batch_size=800,
random_state=42,
model_name=model_name,
save_checkpoints=True,
force_reset=True,
**generate_torch_kwargs(),
)
# 使用N-BEATS模型拟合训练数据和验证数据
model_nbeats.fit(series=train_scaled, val_series=val_scaled)
Training: 0it [00:00, ?it/s]
NBEATSModel(generic_architecture=False, num_stacks=30, num_blocks=3, num_layers=4, layer_widths=512, expansion_coefficient_dim=5, trend_polynomial_degree=2, dropout=0.0, activation=ReLU, input_chunk_length=30, output_chunk_length=7, n_epochs=100, nr_epochs_val_period=1, batch_size=800, random_state=42, model_name=nbeats_interpretable_run, save_checkpoints=True, force_reset=True, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2b3fc0790>]})
# 从checkpoint中加载NBEATS模型
model_nbeats = NBEATSModel.load_from_checkpoint(model_name=model_name, best=True)
让我们看看模型在不断扩大的训练窗口下,以及预测的时间范围为7的情况下会产生哪些历史预测。
# 使用N-BEATS模型进行历史预测
# 参数说明:
# - model_nbeats: N-BEATS模型
# - series_scaled: 缩放后的时间序列数据
# - start: 预测开始时间
# - forecast_horizon: 预测的时间范围
# - stride: 步长,用于控制预测的频率
# - last_points_only: 是否只返回最后一个时间点的预测结果
# - retrain: 是否重新训练模型
# - verbose: 是否打印详细信息
pred_series = model_nbeats.historical_forecasts(
series_scaled,
start=val_scaled.start_time(),
forecast_horizon=7,
stride=7,
last_points_only=False,
retrain=False,
verbose=True,
)
# 将预测结果连接起来
pred_series = concatenate(pred_series)
0%| | 0/69 [00:00<?, ?it/s]
# 调用display_forecast函数,显示预测结果
display_forecast(pred_series, series_scaled, "7 day", start_date=val_scaled.start_time())
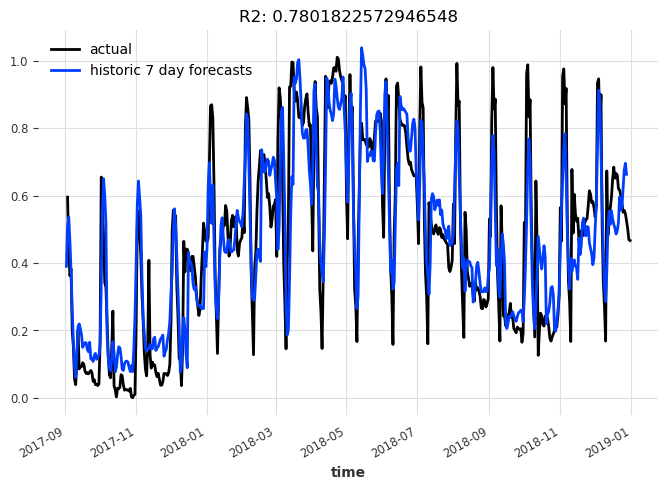



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











