







LLMs遇上SQL:用自然语言处理革新数据查询 利用提示工程、SQL代理等等
文章目录
参考资料:Senthil E LLMs Meet SQL: Revolutionizing Data Querying with Natural Language Processing

引言:
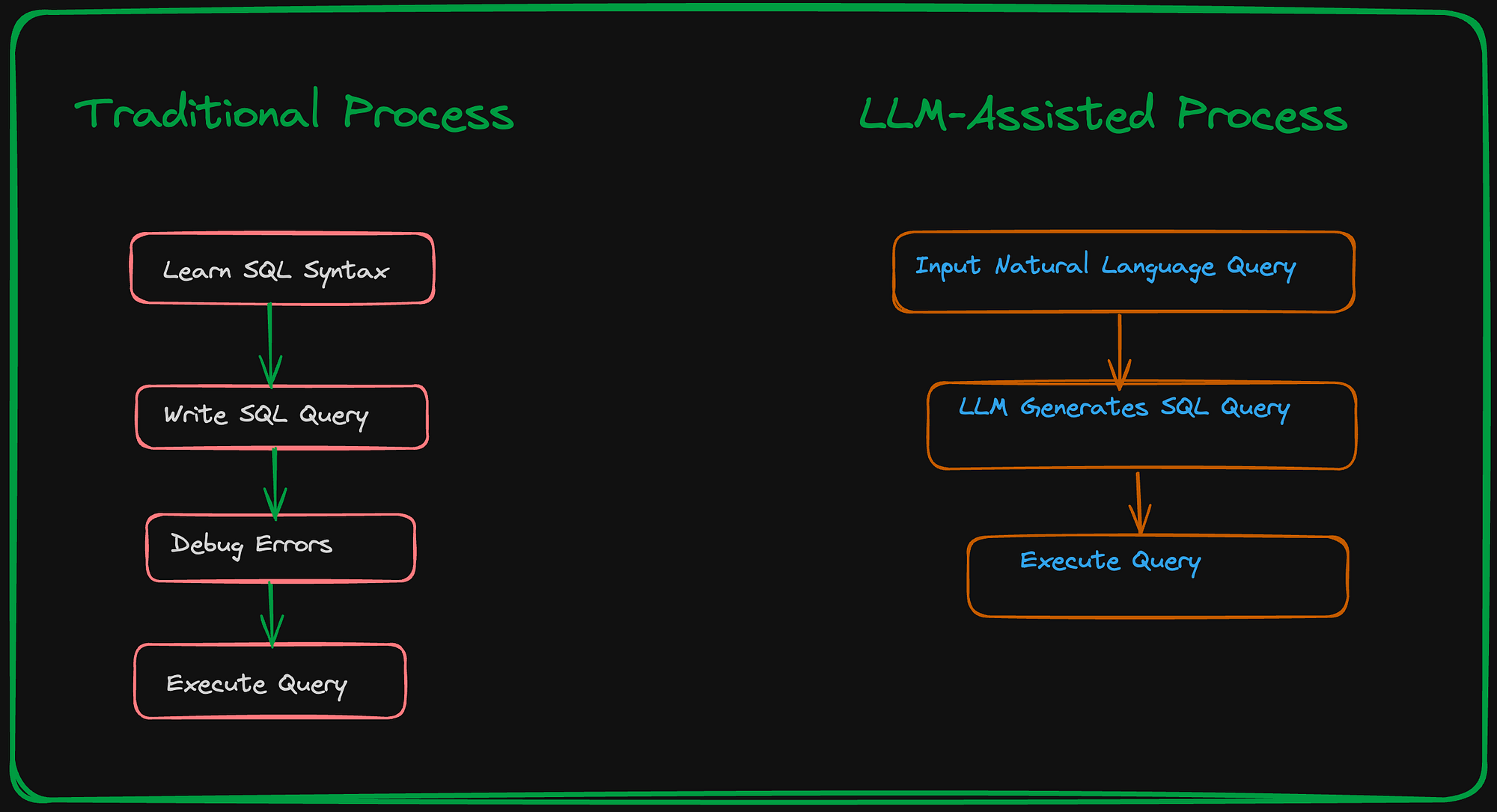
欢迎来到将大型语言模型(LLMs)与结构化数据(如表格和SQL数据库)相结合的令人兴奋的世界!想象一下拥有一个超级聪明的助手,可以用它们自己的语言与数据库交流,让我们轻松获取所需的信息。这不仅仅是问问题和获取答案,而是创建感觉像魔术一样的工具。
在本文中,我们将深入探讨这些强大的模型如何以多种方式简化我们的生活。我们将探索它们如何通过理解我们的问题来编写数据库查询,帮助我们构建了解数据库信息的聊天机器人,并让我们设置自定义仪表板以查看我们最关心的信息。但这还不是全部——当我们将LLMs的智慧与结构化数据的有序世界相结合时,我们还将发现更多令人惊奇的事情。所以,准备好解锁新的可能性,让与数据的互动变得轻松愉快吧!
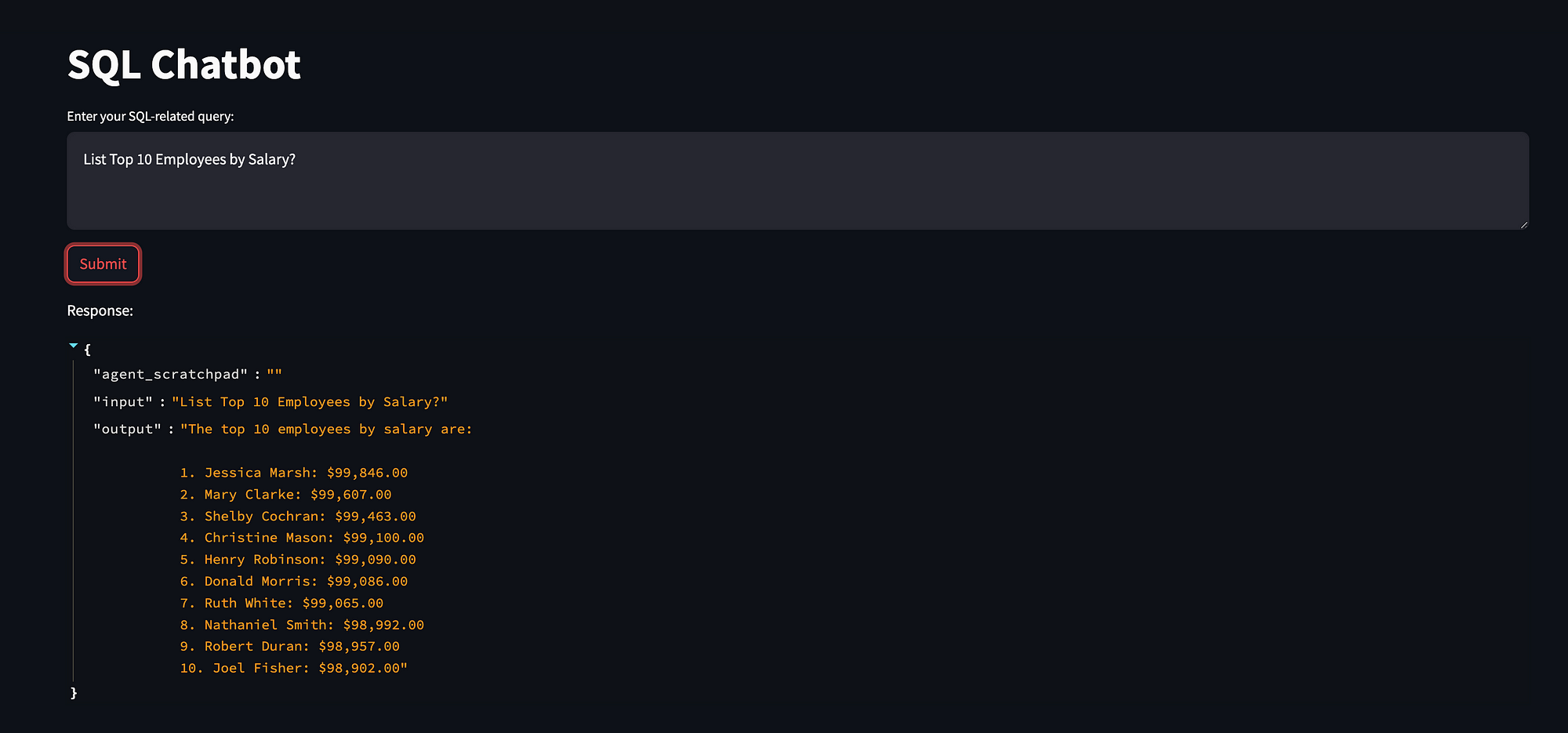
像这样的简单查询
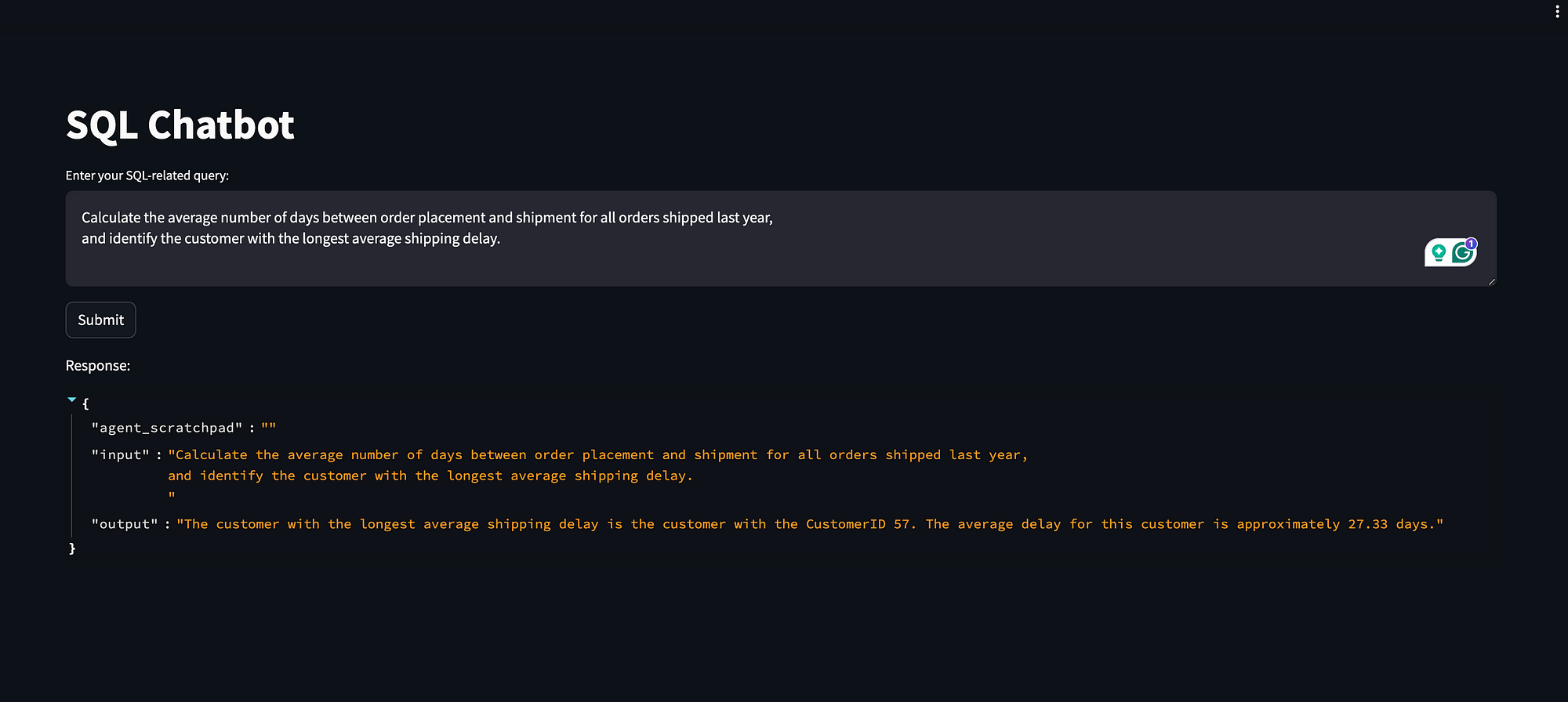
或者像这样的复杂查询
让我们开始吧。
第一部分:选择SQL数据库,创建模式并加载数据
第二部分:代理和SQL代理
第三部分:使用提示工程
第四部分:SQL查询验证
第五部分:数据库中的非描述性或特定语言的表和字段名称
第六部分:挑战
第七部分:文本到可视化
第八部分:使用Ollama进行文本到SQL
第九部分:文本到SQL评估
第十部分:使用Llamaindex进行文本到SQL
第十一部分:使用SQL数据集微调LLM
第十二部分:Pandas AI
第十三部分:一些相关论文
第1部分:选择SQL数据库,创建模式并加载数据
SQL及其在数据管理中的作用:
- SQL代表结构化查询语言,就像您与数据库交流的魔法词汇,告诉它们要存储、查找或更改哪些数据。
- 它非常重要,因为几乎每个应用程序都使用数据库,而SQL是管理所有这些数据的首选语言。
选择正确的数据库:
- 将PostgreSQL、MySQL和SQLAlchemy视为数据的不同类型的工具箱。
- MySQL在这里被选择,因为它易于使用、快速,并适用于各种项目规模。它就像您可靠的厨房刀具,适用于许多任务。
- PostgreSQL实际上是众人喜爱的数据库,因为它具有强大的功能,但在本指南中,我们将使用MySQL来保持简单。
- 如果您直接从Jupyter笔记本工作,并且想要更简单的东西,那么SQLAlchemy就是您的好朋友。它允许您使用Python代码与数据库交流,无需费力气。
这就是为什么MySQL是这个项目的选择——简单、快速,并且适用于从周末爱好到完整业务需求的所有情况!
为了我们的项目目的,我们将创建一个销售订单模式:
模式:
在关系数据库中,模式就像一个蓝图,定义了数据的结构和组织方式。它包括有关表、关系和数据类型的详细信息,为高效地存储和检索数据做好准备。
SalesOrder模式旨在捕捉和反映销售交易的复杂性。它旨在存储从客户信息和库存状态到详细的销售订单和供应商数据的所有内容。
该模式包括七个关键表:
- **Customer:**跟踪客户详细信息、购买历史和联系信息。
- **Employee:**记录员工信息,包括他们的角色、联系方式和薪水。
- **InventoryLog:**监控库存变化,提供有关库存水平和动态的见解。
- **LineItem:**详细说明销售订单中的每个项目,包括价格和数量。
- **Product:**记录产品、描述、价格和库存数量。
- **SalesOrder:**作为模式的核心,该表记录销售交易,包括日期、状态和付款详细信息。
- **Supplier:**包含供应产品的供应商的数据,对于管理供应链至关重要。
CREATE DATABASE SalesOrderSchema;
USE SalesOrderSchema;
CREATE TABLE Customer (
CustomerID INT AUTO_INCREMENT PRIMARY KEY,
FirstName VARCHAR(100),
LastName VARCHAR(100),
Email VARCHAR(255),
Phone VARCHAR(20),
BillingAddress TEXT,
ShippingAddress TEXT,
CustomerSince DATE,
IsActive BOOLEAN
);
CREATE TABLE SalesOrder (
SalesOrderID INT AUTO_INCREMENT PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
RequiredDate DATE,
ShippedDate DATE,
Status VARCHAR(50),
Comments TEXT,
PaymentMethod VARCHAR(50),
IsPaid BOOLEAN,
FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID)
);
CREATE TABLE Product (
ProductID INT AUTO_INCREMENT PRIMARY KEY,
ProductName VARCHAR(255),
Description TEXT,
UnitPrice DECIMAL(10, 2),
StockQuantity INT,
ReorderLevel INT,
Discontinued BOOLEAN
);
CREATE TABLE LineItem (
LineItemID INT AUTO_INCREMENT PRIMARY KEY,
SalesOrderID INT,
ProductID INT,
Quantity INT,
UnitPrice DECIMAL(10, 2),
Discount DECIMAL(10, 2),
TotalPrice DECIMAL(10, 2),
FOREIGN KEY (SalesOrderID) REFERENCES SalesOrder(SalesOrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);
CREATE TABLE Employee (
EmployeeID INT AUTO_INCREMENT PRIMARY KEY,
FirstName VARCHAR(100),
LastName VARCHAR(100),
Email VARCHAR(255),
Phone VARCHAR(20),
HireDate DATE,
Position VARCHAR(100),
Salary DECIMAL(10, 2)
);
CREATE TABLE Supplier (
SupplierID INT AUTO_INCREMENT PRIMARY KEY,
CompanyName VARCHAR(255),
ContactName VARCHAR(100),
ContactTitle VARCHAR(50),
Address TEXT,
Phone VARCHAR(20),
Email VARCHAR(255)
);
CREATE TABLE InventoryLog (
LogID INT AUTO_INCREMENT PRIMARY KEY,
ProductID INT,
ChangeDate DATE,
QuantityChange INT,
Notes TEXT,
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);
SELECT TABLE_NAME, COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_DEFAULT, CHARACTER_MAXIMUM_LENGTH
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'SalesOrderSchema'
ORDER BY TABLE_NAME, ORDINAL_POSITION;
CREATE DATABASE SalesOrderSchema;
USE SalesOrderSchema;
CREATE TABLE Customer (
CustomerID INT AUTO_INCREMENT PRIMARY KEY,
FirstName VARCHAR(100),
LastName VARCHAR(100),
Email VARCHAR(255),
Phone VARCHAR(20),
BillingAddress TEXT,
ShippingAddress TEXT,
CustomerSince DATE,
IsActive BOOLEAN
);
CREATE TABLE SalesOrder (
SalesOrderID INT AUTO_INCREMENT PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
RequiredDate DATE,
ShippedDate DATE,
Status VARCHAR(50),
Comments TEXT,
PaymentMethod VARCHAR(50),
IsPaid BOOLEAN,
FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID)
);
CREATE TABLE Product (
ProductID INT AUTO_INCREMENT PRIMARY KEY,
ProductName VARCHAR(255),
Description TEXT,
UnitPrice DECIMAL(10, 2),
StockQuantity INT,
ReorderLevel INT,
Discontinued BOOLEAN
);
CREATE TABLE LineItem (
LineItemID INT AUTO_INCREMENT PRIMARY KEY,
SalesOrderID INT,
ProductID INT,
Quantity INT,
UnitPrice DECIMAL(10, 2),
Discount DECIMAL(10, 2),
TotalPrice DECIMAL(10, 2),
FOREIGN KEY (SalesOrderID) REFERENCES SalesOrder(SalesOrderID),
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);
CREATE TABLE Employee (
EmployeeID INT AUTO_INCREMENT PRIMARY KEY,
FirstName VARCHAR(100),
LastName VARCHAR(100),
Email VARCHAR(255),
Phone VARCHAR(20),
HireDate DATE,
Position VARCHAR(100),
Salary DECIMAL(10, 2)
);
CREATE TABLE Supplier (
SupplierID INT AUTO_INCREMENT PRIMARY KEY,
CompanyName VARCHAR(255),
ContactName VARCHAR(100),
ContactTitle VARCHAR(50),
Address TEXT,
Phone VARCHAR(20),
Email VARCHAR(255)
);
CREATE TABLE InventoryLog (
LogID INT AUTO_INCREMENT PRIMARY KEY,
ProductID INT,
ChangeDate DATE,
QuantityChange INT,
Notes TEXT,
FOREIGN KEY (ProductID) REFERENCES Product(ProductID)
);
加载数据:
要为Customer、Employee和Product等表生成和加载数据,可以执行以下操作:
通过pip安装Faker。
使用Faker为每个表的字段创建数据,考虑到特定需求(例如姓名、地址、产品详情)。
编写Python脚本,将这些虚假数据插入MySQL数据库,利用
mysql-connector-python或SQLAlchemy等库进行数据库交互。
此脚本对于为测试或开发目的填充数据库中的示例数据非常有用。
**导入必要的库:**脚本使用mysql.connector连接到MySQL数据库,并使用Faker生成虚假数据。
**初始化Faker:**设置Faker以创建逼真但虚假的数据,如姓名、电子邮件、电话号码、地址和日期。
**连接到MySQL数据库:**它建立与名为SalesOrderSchema的本地主机上的MySQL数据库的连接。用户是root,您应该将“Your MySQL Password”替换为实际密码。
**创建游标对象:**使用游标通过Python执行SQL命令。
**生成并插入数据:**对于每个100次迭代,它为一个客户生成虚假数据,包括名字、姓氏、电子邮件、电话号码、地址、成为客户的日期以及他们是否是活跃客户。如果生成的电话号码超过20个字符,则将其截断以确保适应数据库列。将账单地址和送货地址设置为相同的生成地址。然后,使用SQL INSERT语句将这些数据插入数据库的Customer表中。提交事务:在插入所有数据之后,使用conn.commit()将更改保存到数据库中。关闭游标和连接:最后,通过关闭游标和与数据库的连接进行清理。
#将数据加载到客户表的代码
#Customer表
import mysql.connector
from faker import Faker
# 初始化Faker
fake = Faker()
# 连接到MySQL
conn = mysql.connector.connect(
host="localhost",
user="root",
password="Your MySQL Password",
database="SalesOrderSchema"
)
cursor = conn.cursor()
# 生成并插入数据
for _ in range(100): # 假设我们要生成100条记录
first_name = fake.first_name()
last_name = fake.last_name()
email = fake.email()
phone = fake.phone_number()
if len(phone) > 20: # 假设'Phone'列为VARCHAR(20)
phone = phone[:20] # 截断电话号码以适应列
address = fake.address()
customer_since = fake.date_between(start_date='-5y', end_date='today')
is_active = fake.boolean()
# 插入客户数据
cursor.execute("""
INSERT INTO Customer (FirstName, LastName, Email, Phone, BillingAddress, ShippingAddress, CustomerSince, IsActive)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""", (first_name, last_name, email, phone, address, address, customer_since, is_active))
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
员工表:使用Faker填充
#Employee表
import mysql.connector
from faker import Faker
# 初始化Faker
fake = Faker()
# 连接到MySQL
conn = mysql.connector.connect(
host="localhost",
user="root",
password="Your MySQL Password",
database="SalesOrderSchema"
)
cursor = conn.cursor()
# 生成并插入1000条员工记录
for _ in range(1000):
first_name = fake.first_name()
last_name = fake.last_name()
email = fake.email()
phone = fake.phone_number()
if len(phone) > 20: # 如果需要,截断电话号码
phone = phone[:20]
hire_date = fake.date_between(start_date='-5y', end_date='today')
position = fake.job()
salary = round(fake.random_number(digits=5), 2) # 生成一个5位数的工资
# 插入员工数据
cursor.execute("""
INSERT INTO Employee (FirstName, LastName, Email, Phone, HireDate, Position, Salary)
VALUES (%s, %s, %s, %s, %s, %s, %s)
""", (first_name, last_name, email, phone, hire_date, position, salary))
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
print("成功插入1000条员工记录。")
#Product表
import mysql.connector
from faker import Faker
import random
# 初始化Faker
fake = Faker()
# 连接到MySQL
conn = mysql.connector.connect(
host="localhost",
user="root",
password="Your MySQL Password",
database="SalesOrderSchema"
)
cursor = conn.cursor()
# 生成并插入数据到Product表
for _ in range(1000): # 生成1000条产品记录
product_name = fake.word().capitalize() + " " + fake.word().capitalize()
description = fake.sentence(nb_words=10)
unit_price = round(random.uniform(10, 500), 2) # 10到500之间的随机价格
stock_quantity = random.randint(10, 1000) # 10到1000之间的随机库存数量
reorder_level = random.randint(5, 50) # 5到50之间的随机重新订购级别
discontinued = random.choice([0, 1]) # 在0(false)和1(true)之间随机选择
# 插入产品数据
cursor.execute("""
INSERT INTO Product (ProductName, Description, UnitPrice, StockQuantity, ReorderLevel, Discontinued)
VALUES (%s, %s, %s, %s, %s, %s)
""", (product_name, description, unit_price, stock_quantity, reorder_level, discontinued))
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
print("成功插入产品。")
#Supplier表
import mysql.connector
from faker import Faker
import random
# 初始化Faker
fake = Faker()
# 连接到MySQL
conn = mysql.connector.connect(
host="localhost",
user="root",
password="Your MySQL Password",
database="SalesOrderSchema"
)
cursor = conn.cursor()
# 生成并插入数据到Supplier表
for _ in range(1000): # 假设要插入1000条记录
company_name = fake.company()
contact_name = fake.name()
contact_title = fake.job()
# 确保ContactTitle不超过列的最大长度,例如VARCHAR(50)
contact_title = contact_title[:50] if len(contact_title) > 50 else contact_title
address = fake.address().replace('\n', ', ') # 将换行符替换为逗号以用于地址
phone = fake.phone_number()
# 确保电话不超过列的最大长度,例如VARCHAR(20)
phone = phone[:20] if len(phone) > 20 else phone
email = fake.email()
# 插入供应商数据
cursor.execute("""
INSERT INTO Supplier (CompanyName, ContactName, ContactTitle, Address, Phone, Email)
VALUES (%s, %s, %s, %s, %s, %s)
""", (company_name, contact_name, contact_title, address, phone, email))
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
print("成功插入供应商。")
#Sales Order表
import mysql.connector
from faker import Faker
from datetime import timedelta
import random
fake = Faker()
conn = mysql.connector.connect(
host="localhost",
user="root",
password="Your MySQL Password",
database="SalesOrderSchema"
)
cursor = conn.cursor(buffered=True)
# 获取客户ID
cursor.execute("SELECT CustomerID FROM Customer")
customer_ids = [id[0] for id in cursor.fetchall()]
# 插入数据到SalesOrder
for _ in range(1000): # 假设我们要生成1000个销售订单
customer_id = random.choice(customer_ids)
order_date = fake.date_between(start_date='-2y', end_date='today')
required_date = order_date + timedelta(days=random.randint(1, 30))
shipped_date = order_date + timedelta(days=random.randint(1, 30)) if random.choice([True, False]) else None
status = random.choice(['Pending', 'Completed', 'Shipped'])
is_paid = random.choice([True, False])
cursor.execute("""
INSERT INTO SalesOrder (CustomerID, OrderDate, RequiredDate, ShippedDate, Status, IsPaid)
VALUES (%s, %s, %s, %s, %s, %s)
""", (customer_id, order_date, required_date, shipped_date, status, is_paid))
conn.commit()
#Sales Order Line Item表
# 获取产品ID
cursor.execute("SELECT ProductID FROM Product")
product_ids = [id[0] for id in cursor.fetchall()]
# 获取销售订单ID
cursor.execute("SELECT SalesOrderID FROM SalesOrder")
sales_order_ids = [id[0] for id in cursor.fetchall()]
# 插入数据到LineItem
for _ in range(5000): # 假设每个订单有多个行项目
sales_order_id = random.choice(sales_order_ids)
product_id = random.choice(product_ids)
quantity = random.randint(1, 10)
unit_price = round(random.uniform(10, 100), 2) # 假设您有此信息或从Product表中获取
total_price = quantity * unit_price
cursor.execute("""
INSERT INTO LineItem (SalesOrderID, ProductID, Quantity, UnitPrice, TotalPrice)
VALUES (%s, %s, %s, %s, %s)
""", (sales_order_id, product_id, quantity, unit_price, total_price))
conn.commit()
cursor.close()
conn.close()
#Inventory表
import mysql.connector
from faker import Faker
import random
# 初始化Faker
fake = Faker()
# 连接到MySQL
conn = mysql.connector.connect(
host="localhost",
user="root",
password="Your MySQL Password",
database="SalesOrderSchema"
)
cursor = conn.cursor()
# 获取产品ID
cursor.execute("SELECT ProductID FROM Product")
product_ids = [row[0] for row in cursor.fetchall()]
# 假设要插入1000条库存日志记录
for _ in range(1000):
product_id = random.choice(product_ids) # 随机选择一个产品ID
change_date = fake.date_between(start_date="-1y", end_date="today")
quantity_change = random.randint(-100, 100) # 假设库存可以增加或减少
notes = "Inventory " + ("increased" if quantity_change > 0 else "decreased")
# 插入库存日志数据
cursor.execute("""
INSERT INTO InventoryLog (ProductID, ChangeDate, QuantityChange, Notes)
VALUES (%s, %s, %s, %s)
""", (product_id, change_date, quantity_change, notes))
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
print("成功插入库存日志。")
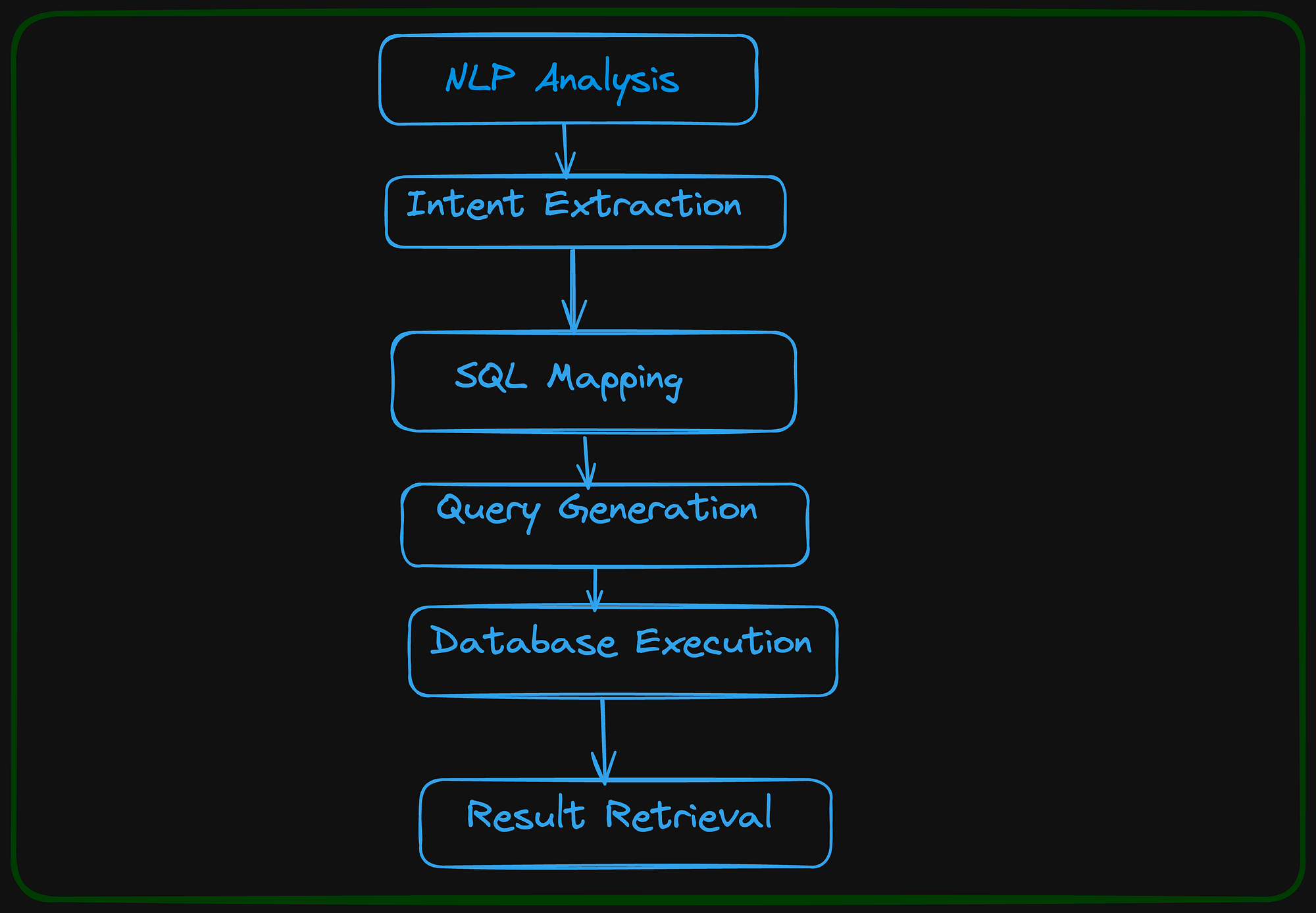
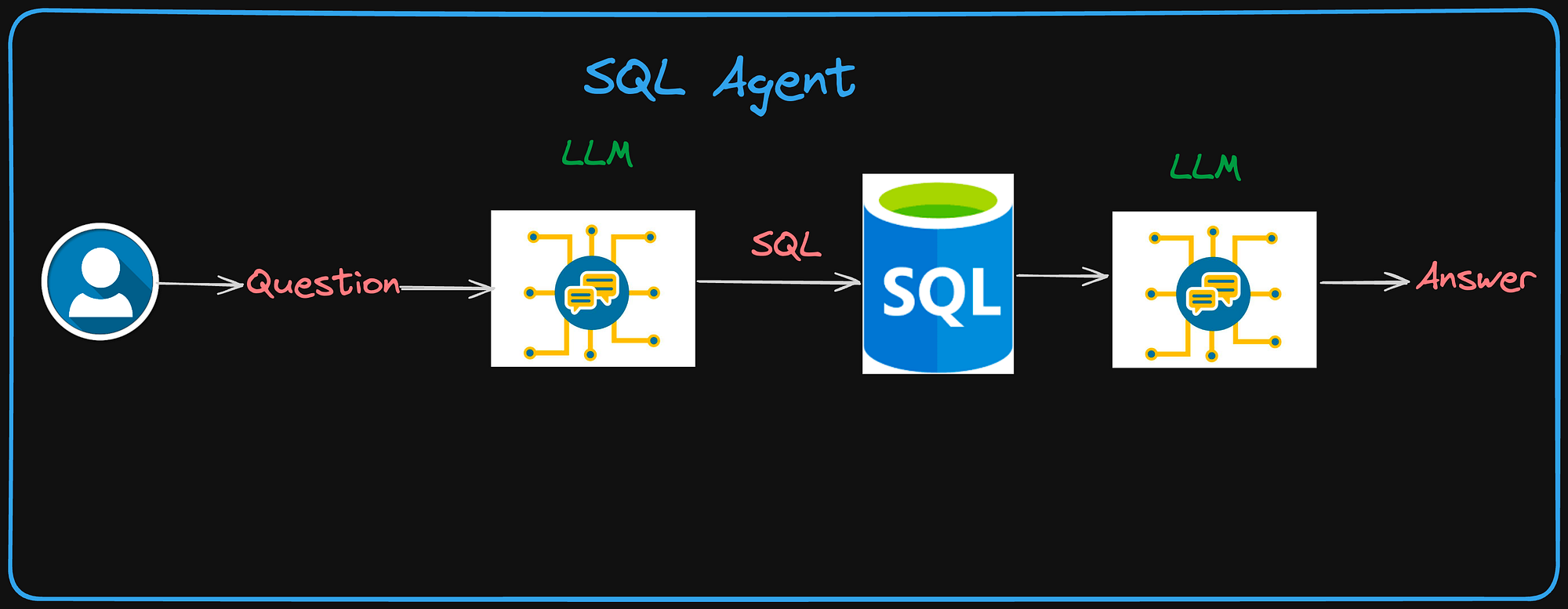
文本到 SQL 流程 👆
第2部分:代理 & SQL 代理:
让我们首先使用 SQL 代理创建文本到 SQL。
什么是 AI 代理?
定义: AI 代理是一种计算机程序,旨在通过模拟人类智能的某些方面来执行任务。它可以在没有持续人类指导的情况下做出决策,与环境交互或解决问题。
**能力:**决策:AI 代理可以评估情况并根据它们拥有的数据或编程规则做出选择。
**问题解决:**它们能够在复杂情景中导航,以实现特定目标或找到问题的解决方案。
**学习:**一些 AI 代理能够从数据或过去的经验中学习,随着时间的推移提高其性能。这通常被称为机器学习。
AI 代理的类型:
**简单反射代理:**根据预定义规则对当前情况或环境做出反应,而不考虑过去或未来。
**基于模型的反射代理:**考虑世界的当前状态及其如何响应行动的变化,从而实现更明智的决策过程。
**基于目标的代理:**通过考虑未来行动及其结果来实现特定目标。
**基于效用的代理:**根据效用函数评估其行动的成功,旨在最大化其满意度或利益。
**学习代理:**通过从环境和过去行动中学习来提高其性能并适应新情况。
应用:
**虚拟助手:**如 Siri 或 Alexa,可以为个人执行任务或提供服务。
**自主车辆:**无需人类干预即可导航和操作的汽车或无人机。
**推荐系统:**像 Netflix 或 Amazon 使用的那些,根据您的偏好推荐产品或电影。
**医疗保健:**AI 代理可以协助诊断疾病,预测患者结果或个性化治疗计划。
优势:
**效率:**它们可以自动化并在许多情况下比人类更快,更准确地执行任务。
**可用性:**AI 代理全天候可用,提供连续服务,无需休息或睡眠。
**个性化:**能够根据个人偏好定制体验、推荐和互动。
挑战:
伦理和隐私问题:需要谨慎决定 AI 代理如何使用和共享数据。
依赖性:过度依赖 AI 代理可能影响人类技能和就业。
开发和维护的复杂性:创建和更新 AI 代理需要重大的专业知识和资源。
SQL 代理:
能力:
**自然语言查询:**允许用户通过自然语言与数据库交互,使非技术用户能够在不了解 SQL 语法的情况下提取信息更加容易。
**AI 辅助数据库交互:**通过 AI 增强数据库交互,实现更复杂的查询、数据分析和通过对话界面提取见解。
**与语言模型集成:**将 AI 语言模型与 SQL 数据库结合,促进从自然语言输入自动生成 SQL 查询并为用户解释结果。
组件:
**语言模型:**预先训练的 AI 模型,能够理解和生成类似人类的文本。
**查询生成:**将自然语言请求转换为 SQL 查询的机制。
**结果解释:**将 SQL 查询结果转换回人类可读的格式或摘要。
应用:
**数据探索:**为没有深入技术知识的用户提供更直观的数据探索和分析。
**商业智能:**通过对话界面促进报告和见解的生成。
**自动化:**简化用户与数据库之间的交互,自动化查询生成和数据检索过程。
让我们看看如何使用 SQL 代理并进行文本到 SQL 转换。
脚本如下。
import os
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain_community.utilities import SQLDatabase
from langchain_community.agent_toolkits import create_sql_agent
# 在此设置您的 OpenAI API 密钥
os.environ["OPENAI_API_KEY"] = "Your OpenAI API Key"
# 直接使用数据库连接详细信息
host = "localhost"
user = "root"
password = "Your MySQL Password"
database = "SalesOrderSchema"
# 设置数据库连接
db_uri = f"mysql+mysqlconnector://{user}:{password}@{host}/{database}"
db = SQLDatabase.from_uri(db_uri)
llm = ChatOpenAI(model="gpt-4", temperature=0)
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
# Streamlit 应用布局
st.title('SQL Chatbot')
# 用户输入
user_query = st.text_area("输入与 SQL 相关的查询:", "List Top 10 Employees by Salary?")
if st.button('提交'):
# 尝试:
# 处理用户输入
#response = agent_executor.invoke(user_query)
#response = agent_executor.invoke({"query": user_query})
#if st.button('提交'):
try:
# 处理用户输入
response = agent_executor.invoke({
"agent_scratchpad": "", # 假设如果未使用,则需要为空字符串
"input": user_query # 从 "query" 更改为 "input"
})
st.write("响应:")
st.json(response) # 如果是 JSON,则使用 st.json 进行漂亮打印响应
except Exception as e:
st.error(f"发生错误:{e}")
#st.write("响应:")
#st.write(response)
#except Exception as e:
#st.error(f"发生错误:{e}")
关于脚本:
**导入库和模块:**脚本从 langchain_openai 和 langchain_community 中导入必要的库,如 os、streamlit(作为 st)和特定模块,用于创建和管理 SQL 聊天机器人。
**设置 OpenAI API 密钥:**它使用您的 OpenAI API 密钥设置环境变量 OPENAI_API_KEY,这对于访问 OpenAI 的语言模型是必要的。
**数据库连接详细信息:**脚本定义了用于连接到 MySQL 数据库的主机、用户、密码和数据库名称等数据库连接详细信息的变量。
**设置数据库连接:**使用提供的凭据创建到指定 MySQL 数据库的连接,并构建一个 SQLDatabase 对象。
**初始化语言模型和 SQL 代理:**它从 OpenAI 的 GPT-4 初始化语言模型,并创建一个 SQL 代理。该代理可以解释与 SQL 相关的查询,并使用自然语言处理与数据库交互。

Streamlit 应用界面:
- 设置一个简单的网络界面标题为“SQL 聊天机器人”。
为用户提供一个文本区域,让他们输入与 SQL 相关的查询。
包括一个提交按钮,供用户执行他们的查询。 - 点击提交按钮后,应用程序尝试使用 SQL 代理处理用户的查询。
它以 JSON 格式在 Streamlit 界面中格式化和显示 SQL 代理的响应。 - 如果在处理过程中发生错误,它会显示一个错误消息。
错误处理:脚本包含一个 try-except 块,用于捕获并显示在查询处理或响应生成阶段可能发生的错误。
如何运行 Streamlit Python 脚本:
安装 Streamlit:
如果您尚未安装 Streamlit,请打开终端
(或 Windows 中的命令提示符/PowerShell)并运行以下命令:
pip install streamlit
保存您的脚本:确保您的 Streamlit 脚本(例如 app.py)
保存在计算机上已知的目录中。
打开终端:导航到保存有您的 Streamlit 脚本的目录。
您可以使用 cd 命令,后跟目录路径来完成这一步。例如:
cd path/to/your/script
运行 Streamlit 脚本:在终端中执行以下命令
来运行您的 Streamlit 脚本:
streamlit run app.py
如果文件名不同,请用您的 Streamlit 脚本文件名替换 app.py。
访问网络界面:运行命令后,Streamlit 将启动服务器,并为您提供一个本地 URL,通常类似于 http://localhost:8501。
在 Web 浏览器中打开此 URL,以查看您的 Streamlit 应用程序。
与应用程序交互:使用 Web 界面与您的 Streamlit 应用程序交互。
您可以输入内容、按按钮,并实时查看脚本的输出。
停止 Streamlit 服务器:完成后,您可以在运行服务器的终端中按 Ctrl+C 停止 Streamlit 服务器。
这些步骤将使您能够运行和与任何 Streamlit 脚本交互,轻松将您的 Python 脚本转换为交互式 Web 应用程序。
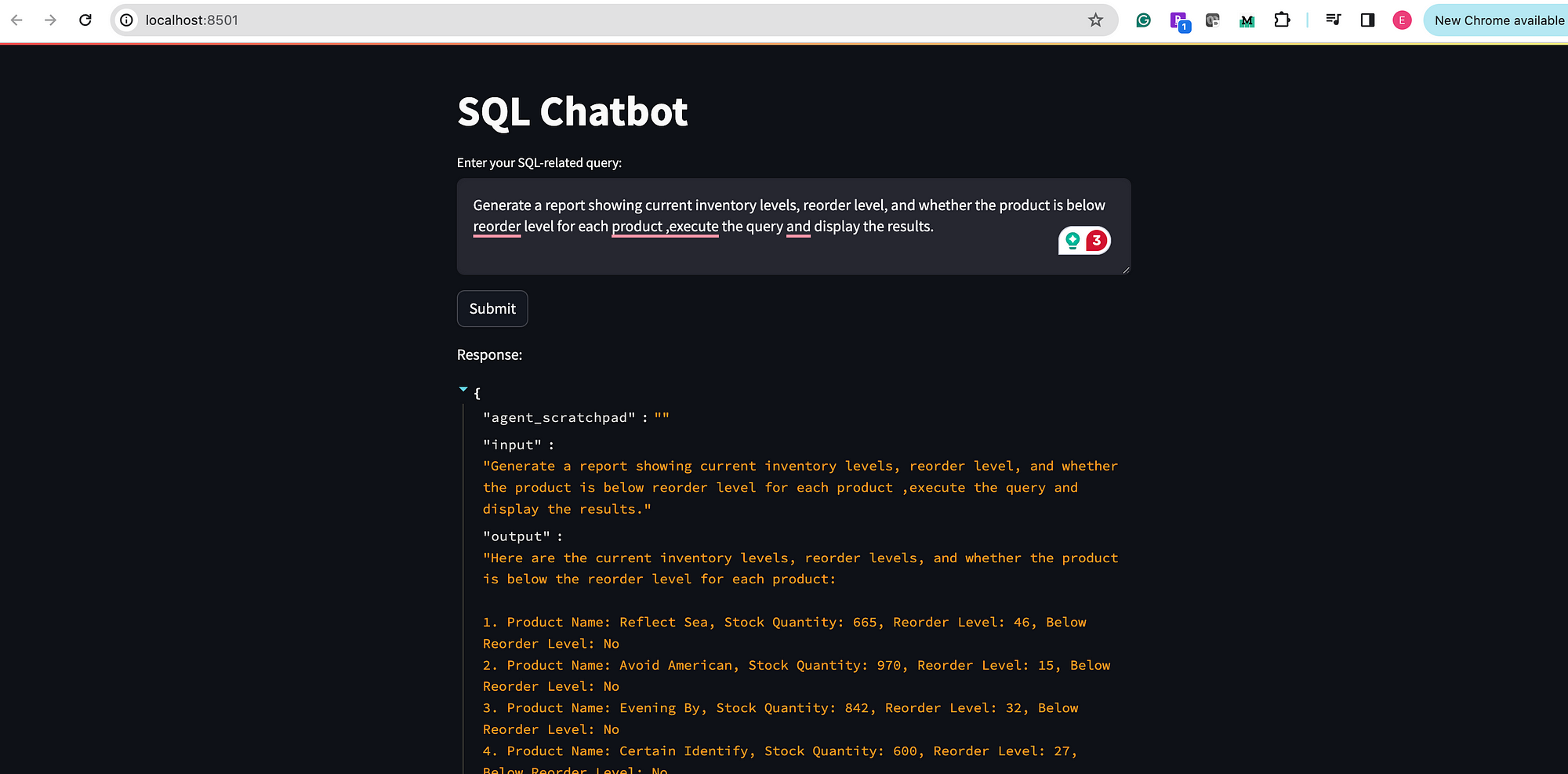
查询:1
生成一个报告,显示每种产品的当前库存水平、重新订购水平以及产品是否低于重新订购水平,执行查询并显示结果。
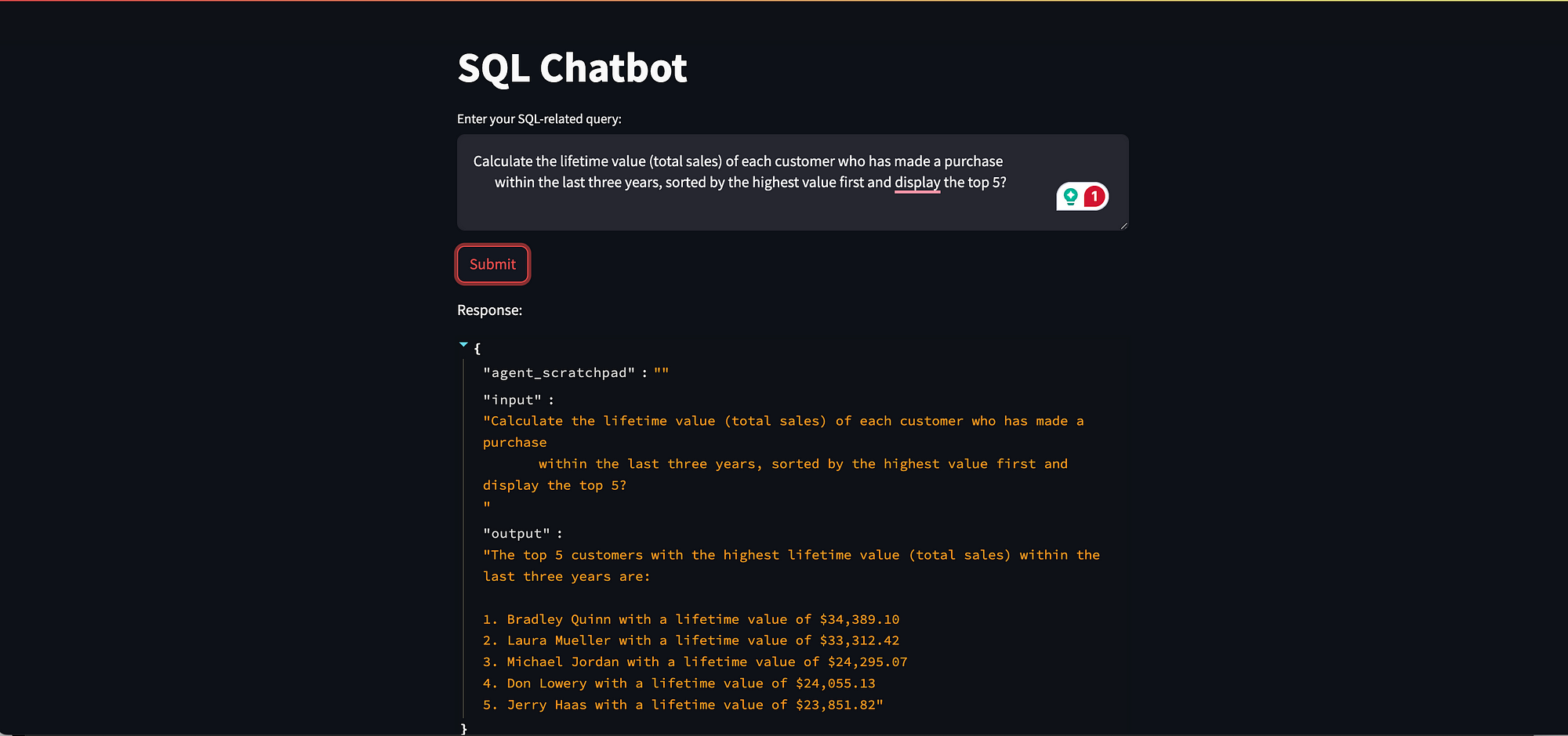
查询:2
计算过去三年内进行过购买的每位客户的生命周期价值(总销售额),按最高价值排序并显示前 5 位?
第3部分:使用提示工程:
提示工程涉及以指导模型生成所需输出为目标,精心设计输入。这在文本转SQL任务中特别有用,其中目标是将自然语言查询转换为精确的SQL语句。
工作原理:
示例作为指导: 在提示中包含自然语言查询的示例以及它们正确的SQL翻译,实质上为模型提供了一个要遵循的模板。这种方法使用了少样本学习的原则,模型利用提供的示例来理解和推广手头的任务。
上下文信息: 添加关于数据库架构的信息,如表名和关系,可以帮助模型生成更准确的SQL查询。这种上下文背景有助于模型将自然语言术语映射到数据库中相应的实体。
任务描述: 以清晰的任务描述开头的提示(例如,“将以下自然语言查询转换为SQL:”)表明了模型预期的任务,为其在指定任务上表现更好做好了准备。
示例提示:
我是一个SQL助手,旨在将自然语言查询转换为SQL。
给定一个包含Customer、Employee、InventoryLog、LineItem、Product、SalesOrder和Supplier表的销售数据库架构,这里有一些示例:
- 自然语言查询:“显示所有价格高于100美元的产品。”
- SQL翻译:SELECT * FROM Product WHERE price > 100;
- 自然语言查询:“列出顾客ID为123在2023年下的所有订单。”
- SQL翻译:SELECT * FROM SalesOrder WHERE CustomerID = 123 AND YEAR(OrderDate) = 2023;
翻译以下查询:
“查找2024年3月每种产品的总销售额。”
例如:系统提示将是
给定以下数据库架构,生成与用户请求相对应的SQL查询。
表及其相关字段:
- Product(ProductID,ProductName)
- LineItem(ProductID,TotalPrice)
- SalesOrder(SalesOrderID,OrderDate)
用户对去年每种产品的总销售额感兴趣。查询应返回每种产品的名称以及该时期所有销售总价的总和。确保查询仅考虑与去年销售订单相关联的那些行项目。
参考示例SQL模板:
“SELECT [columns] FROM [table] JOIN [other_table] ON [condition] WHERE
[condition] GROUP BY [column];”
在查询结构中,为了可读性和保持SQL最佳实践,请适当使用表别名。
用户提示:
“显示去年每种产品的总销售额。”
LLM生成以下输出:
SELECT
P.ProductName,
SUM(L.TotalPrice) AS TotalSales
FROM
Product P
JOIN LineItem L ON P.ProductID = L.ProductID
JOIN SalesOrder S ON L.SalesOrderID = S.SalesOrderID
WHERE
YEAR(S.OrderDate) = YEAR(CURDATE()) - 1
GROUP BY
P.ProductName;

选择特定方言提示-Langchain
from langchain.chains.sql_database.prompt import SQL_PROMPTS
list(SQL_PROMPTS)
['crate',
'duckdb',
'googlesql',
'mssql',
'mysql',
'mariadb',
'oracle',
'postgresql',
'sqlite',
'clickhouse',
'prestodb']
由于我们使用MySQL,那么操作如下
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature="0")
chain = create_sql_query_chain(llm, db)
chain.get_prompts()[0].pretty_print()
提示将是
您是一个MySQL专家。给定一个输入问题,首先创建一个语法正确的MySQL查询以检索答案,然后执行查询并返回输入问题的答案。
- 使用LIMIT子句查询最多5个结果,除非用户指定不同数量。
- 永远不要从表中查询所有列。只选择回答问题所需的列。
- 将每个列名用反引号(`)括起来,以防由于保留关键字或特殊字符而导致的语法错误。
- 注意列名及其各自的表。
- 如果问题涉及“今天”,请使用CURDATE()表示当前日期。
结构化您的响应如下:
问题:[用户的问题]
MySQL查询:[您生成的SQL查询]
结果:[SQL查询的结果,如果有的话]
答案:[基于查询结果的最终答案]
只在SalesOrder架构中使用以下表:Customer、Employee、InventoryLog、LineItem、Product、SalesOrder、Supplier。这里是这些表的一些示例数据供您参考:[包括示例数据]。
问题:[用户输入]
要获取表名、它们的模式以及每个表的一些行的示例,请使用以下内容:
from langchain_community.utilities import SQLDatabase
# 根据您的MySQL调整连接URI
db = SQLDatabase.from_uri("mysql+mysqlconnector://'user_id':'password'@localhost/SalesOrderSchema")
# 打印SQL方言(现在应该反映MySQL)
print(db.dialect)
# 打印您的MySQL数据库中可用的表名
print(db.get_usable_table_names())
# 运行一个示例查询 - 根据您的架构调整表名
# 这是一个示例;将“Artist”替换为您架构中的实际表名,如“Customer”
db.run("SELECT * FROM Customer LIMIT 10;")
mysql
['Customer', 'Employee', 'InventoryLog', 'LineItem', 'Product', 'SalesOrder', 'Supplier']
"[(1, 'Sandra', 'Cruz', 'rhonda24@example.net', '511-949-6987x21174', '18018 Kyle Streets Apt. 606\\nShaneville, AZ 85788', '18018 Kyle Streets Apt. 606\\nShaneville, AZ 85788', datetime.date(2023, 5, 2), 0), (2, 'Robert', 'Williams', 'traciewall@example.net', '944-649-2491x60774', '926 Mitchell Pass Apt. 342\\nBrianside, SC 83374', '926 Mitchell Pass Apt. 342\\nBrianside, SC 83374', datetime.date(2020, 9, 1), 0), (3, 'John', 'Greene', 'travis92@example.org', '279.334.1551', '36019 Bill Manors Apt. 219\\nDominiquefort, AK 55904', '36019 Bill Manors Apt. 219\\nDominiquefort, AK 55904', datetime.date(2021, 3, 15), 0), (4, 'Steven', 'Riley', 'greennathaniel@example.org', '+1-700-682-7696x189', '76545 Hebert Crossing Suite 235\\nForbesbury, MH 14227', '76545 Hebert Crossing Suite 235\\nForbesbury, MH 14227', datetime.date(2022, 12, 5), 0), (5, 'Christina', 'Blake', 'christopher87@example.net', '584.263.4429', '8342 Shelly Fork\\nWest Chasemouth, CT 81799', '8342 Shelly Fork\\nWest Chasemouth, CT 81799', datetime.date(2019, 11, 12), 0), (6, 'Michael', 'Stevenson', 'lynnwilliams@example.org', '328-637-4320x7025', '7503 Mallory Mountains Apt. 199\\nMeganport, MI 81064', '7503 Mallory Mountains Apt. 199\\nMeganport, MI 81064', datetime.date(2024, 1, 1), 1), (7, 'Anna', 'Kramer', 'steven23@example.org', '+1-202-719-6886x844', '295 Mcgee Fort\\nManningberg, PR 93309', '295 Mcgee Fort\\nManningberg, PR 93309', datetime.date(2022, 3, 6), 1), (8, 'Michael', 'Sullivan', 'bbailey@example.com', '988.368.5033', '772 Bruce Motorway Suite 583\\nPowellbury, MH 42611', '772 Bruce Motorway Suite 583\\nPowellbury, MH 42611', datetime.date(2019, 3, 23), 1), (9, 'Kevin', 'Moody', 'yoderjennifer@example.org', '3425196543', '371 Lee Lake\\nNew Michaelport, CT 99382', '371 Lee Lake\\nNew Michaelport, CT 99382', datetime.date(2023, 12, 3), 1), (10, 'Jeremy', 'Mejia', 'spencersteven@example.org', '449.324.7097', '90137 Harris Garden\\nMatthewville, IA 39321', '90137 Harris Garden\\nMatthewville, IA 39321', datetime.date(2019, 5, 20), 1)]"
context = db.get_context()
print(list(context))
print(context["table_info"])
输出:
['table_info', 'table_names']
CREATE TABLE `Customer` (
`CustomerID` INTEGER NOT NULL AUTO_INCREMENT,
`FirstName` VARCHAR(100),
`LastName` VARCHAR(100),
`Email` VARCHAR(255),
`Phone` VARCHAR(20),
`BillingAddress` TEXT,
`ShippingAddress` TEXT,
`CustomerSince` DATE,
`IsActive` TINYINT(1),
PRIMARY KEY (`CustomerID`)
)DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci
/*
3 rows from Customer table:
CustomerID FirstName LastName Email Phone BillingAddress ShippingAddress CustomerSince IsActive
1 Sandra Cruz rhonda24@example.net 511-949-6987x21174 18018 Kyle Streets Apt. 606
Shaneville, AZ 85788 18018 Kyle Streets Apt. 606
Shaneville, AZ 85788 2023-05-02 0
2 Robert Williams traciewall@example.net 944-649-2491x60774 926 Mitchell Pass Apt. 342
Brianside, SC 83374 926 Mitchell Pass Apt. 342
Brianside, SC 83374 2020-09-01 0
3 John Greene travis92@example.org 279.334.1551 36019 Bill Manors Apt. 219
Dominiquefort, AK 55904 36019 Bill Manors Apt. 219
Dominiquefort, AK 55904 2021-03-15 0
*/
CREATE TABLE `Employee` (
`EmployeeID` INTEGER NOT NULL AUTO_INCREMENT,
`FirstName` VARCHAR(100),
`LastName` VARCHAR(100),
`Email` VARCHAR(255),
`Phone` VARCHAR(20),
`HireDate` DATE,
`Position` VARCHAR(100),
`Salary` DECIMAL(10, 2),
PRIMARY KEY (`EmployeeID`)
)DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci
/*
3 rows from Employee table:
EmployeeID FirstName LastName Email Phone HireDate Position Salary
1 Danny Morales catherine08@example.com 001-240-574-6687x625 2021-06-16 Medical technical officer 36293.00
2 William Spencer sthompson@example.com (845)940-2095x693 2023-08-22 English as a foreign language teacher 51775.00
3 Brian Stark hughesmelissa@example.com 780.299.1965x06374 2023-02-24 Pharmacologist 11963.00
*/
CREATE TABLE `InventoryLog` (
`LogID` INTEGER NOT NULL AUTO_INCREMENT,
`ProductID` INTEGER,
`ChangeDate` DATE,
`QuantityChange` INTEGER,
`Notes` TEXT,
PRIMARY KEY (`LogID`),
CONSTRAINT inventorylog_ibfk_1 FOREIGN KEY(`ProductID`) REFERENCES `Product` (`ProductID`)
)DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci
/*
3 rows from InventoryLog table:
LogID ProductID ChangeDate QuantityChange Notes
1 301 2023-09-08 84 Inventory increased
2 524 2023-08-09 -84 Inventory decreased
3 183 2023-04-17 -51 Inventory decreased
*/
CREATE TABLE `LineItem` (
`LineItemID` INTEGER NOT NULL AUTO_INCREMENT,
`SalesOrderID` INTEGER,
`ProductID` INTEGER,
`Quantity` INTEGER,
`UnitPrice` DECIMAL(10, 2),
`Discount` DECIMAL(10, 2),
`TotalPrice` DECIMAL(10, 2),
PRIMARY KEY (`LineItemID`),
CONSTRAINT lineitem_ibfk_1 FOREIGN KEY(`SalesOrderID`) REFERENCES `SalesOrder` (`SalesOrderID`),
CONSTRAINT lineitem_ibfk_2 FOREIGN KEY(`ProductID`) REFERENCES `Product` (`ProductID`)
)DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci
/*
3 rows from LineItem table:
LineItemID SalesOrderID ProductID Quantity UnitPrice Discount TotalPrice
1 280 290 3 84.59 None 253.77
2 94 249 6 88.70 None 532.20
3 965 247 1 43.44 None 43.44
*/
CREATE TABLE `Product` (
`ProductID` INTEGER NOT NULL AUTO_INCREMENT,
`ProductName` VARCHAR(255),
`Description` TEXT,
`UnitPrice` DECIMAL(10, 2),
`StockQuantity` INTEGER,
`ReorderLevel` INTEGER,
`Discontinued` TINYINT(1),
PRIMARY KEY (`ProductID`)
)DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci
/*
3 rows from Product table:
ProductID ProductName Description UnitPrice StockQuantity ReorderLevel Discontinued
1 Reflect Sea Factor country center price pretty foreign theory paper fact machine two. 191.19 665 46 1
2 Avoid American Skill environmental start set bring must job early per weight difficult someone. 402.14 970 15 1
3 Evening By Whether high bill though each president another its. 12.81 842 32 1
*/
CREATE TABLE `SalesOrder` (
`SalesOrderID` INTEGER NOT NULL AUTO_INCREMENT,
`CustomerID` INTEGER,
`OrderDate` DATE,
`RequiredDate` DATE,
`ShippedDate` DATE,
`Status` VARCHAR(50),
`Comments` TEXT,
`PaymentMethod` VARCHAR(50),
`IsPaid` TINYINT(1),
PRIMARY KEY (`SalesOrderID`),
CONSTRAINT salesorder_ibfk_1 FOREIGN KEY(`CustomerID`) REFERENCES `Customer` (`CustomerID`)
)DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci
/*
3 rows from SalesOrder table:
SalesOrderID CustomerID OrderDate RequiredDate ShippedDate Status Comments PaymentMethod IsPaid
1 12 2022-11-05 2022-12-02 2022-11-25 Pending None None 0
2 56 2022-02-22 2022-03-08 2022-03-17 Completed None None 1
3 63 2023-03-20 2023-03-27 None Shipped None None 0
*/
CREATE TABLE `Supplier` (
`SupplierID` INTEGER NOT NULL AUTO_INCREMENT,
`CompanyName` VARCHAR(255),
`ContactName` VARCHAR(100),
`ContactTitle` VARCHAR(50),
`Address` TEXT,
`Phone` VARCHAR(20),
`Email` VARCHAR(255),
PRIMARY KEY (`SupplierID`)
)DEFAULT CHARSET=utf8mb4 ENGINE=InnoDB COLLATE utf8mb4_0900_ai_ci
/*
3 rows from Supplier table:
SupplierID CompanyName ContactName ContactTitle Address Phone Email
29 Hogan-Anderson Sierra Carey Mining engineer 246 Johnny Fords Apt. 858, Williamsport, AK 96920 232.945.6443 rodney04@example.com
30 Nixon, Woods and Pearson Lawrence Phillips Aid worker USS Osborn, FPO AE 24294 001-462-571-0185x478 jessica29@example.org
31 Bruce and Sons Sonya Wilson Insurance risk surveyor 983 Howard Radial, Eileenfurt, MN 70941 +1-245-792-2848x851 brianbrown@example.com
*/
我们可以使用上述内容更新我们的提示或传递所有内容。Chatgpt4上下文大小为128K,一切正常。
带上下文的提示 = chain.get_prompts()[0].partial(table_info=context["table_info"])
print(prompt_with_context.pretty_repr()[:1500])
有关提示的更多详细信息,请查看
如何为文本到SQL提示LLMs:零样本、单领域和跨领域设置研究

少样本示例:
以下是一些示例:
examples = [
{"input": "List all customers.", "query": "SELECT * FROM Customer;"},
{"input": "Find all orders placed by customer with ID 1.",
"query": "SELECT * FROM SalesOrder WHERE CustomerID = 1;"},
{"input": "List all products currently in stock.",
"query": "SELECT * FROM Product WHERE StockQuantity > 0;"},
{"input": "Find the supplier for product with ID 10.",
"query": "SELECT s.CompanyName FROM Supplier s JOIN Product p ON
s.SupplierID = p.SupplierID WHERE p.ProductID = 10;"},
{"input": "List the sales orders that have not been shipped yet.",
"query": "SELECT * FROM SalesOrder WHERE Status = 'Pending';"},
{"input": "How many employees work in the sales department?",
"query": "SELECT COUNT(*) FROM Employee WHERE Position LIKE '%sales%';"},
{"input": "List the top 5 most sold products.",
"query": "SELECT ProductID, SUM(Quantity) AS TotalQuantity FROM LineItem
GROUP BY ProductID ORDER BY TotalQuantity DESC LIMIT 5;"},
{"input": "Find the total sales amount for orders completed this year.",
"query": "SELECT SUM(TotalPrice) FROM SalesOrder WHERE YEAR(OrderDate) = YEAR(CURDATE()) AND Status = 'Completed';"},
{"input": "List all suppliers from 'New York'.",
"query": "SELECT * FROM Supplier WHERE Address LIKE '%New York%';"},
{"input": "How many products are low on stock (below reorder level)?",
"query": "SELECT COUNT(*) FROM Product WHERE StockQuantity < ReorderLevel;"},
{"input": "List all orders made by customer named 'John Doe'.",
"query": "SELECT so.* FROM SalesOrder so JOIN Customer c ON so.CustomerID = c.CustomerID WHERE c.FirstName = 'John' AND c.LastName = 'Doe';"},
{"input": "Show inventory logs for product with ID 20.",
"query": "SELECT * FROM InventoryLog WHERE ProductID = 20;"},
]
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate.from_template("用户输入:{input}\nSQL查询:{query}")
prompt = FewShotPromptTemplate(
examples=examples[:15],
example_prompt=example_prompt,
prefix="您是一个MySQL专家。给定一个输入问题,创建一个语法正确的MySQL查询来运行。除非另有说明,不要返回超过{top_k}行。\n\n这是相关表信息:{table_info}\n\n以下是一些问题及其相应SQL查询的示例。",
suffix="用户输入:{input}\nSQL查询:",
input_variables=["input", "top_k", "table_info"],
)
table_info = """
- Customer(CustomerID INT,FirstName VARCHAR(100),LastName VARCHAR(100),Email VARCHAR(255),Phone VARCHAR(20),BillingAddress TEXT,ShippingAddress TEXT,CustomerSince DATE,IsActive TINYINT)
- Employee(EmployeeID INT,FirstName VARCHAR(100),LastName VARCHAR(100),Email VARCHAR(255),Phone VARCHAR(20),HireDate DATE,Position VARCHAR(100),Salary DECIMAL)
- InventoryLog(LogID INT,ProductID INT,ChangeDate DATE,QuantityChange INT,Notes TEXT)
- LineItem(LineItemID INT,SalesOrderID INT,ProductID INT,Quantity INT,UnitPrice DECIMAL,Discount DECIMAL,TotalPrice DECIMAL)
- Product(ProductID INT,ProductName VARCHAR(255),Description TEXT,UnitPrice DECIMAL,StockQuantity INT,ReorderLevel INT,Discontinued TINYINT)
- SalesOrder(SalesOrderID INT,CustomerID INT,OrderDate DATE,RequiredDate DATE,ShippedDate DATE,Status VARCHAR(50),Comments TEXT,PaymentMethod VARCHAR(50),IsPaid TINYINT)
- Supplier(SupplierID INT,CompanyName VARCHAR(255),ContactName VARCHAR(100),ContactTitle VARCHAR(50),Address TEXT,Phone VARCHAR(20),Email VARCHAR(255))
"""
# 示例用法
input_example = "列出当前库存中的所有产品。"
top_k = 10
formatted_prompt = prompt.format(input=input_example, top_k=top_k, table_info=table_info)
print(formatted_prompt)
```
```python
您是一位MySQL专家。给定一个输入问题,创建一个语法正确的MySQL查询以运行。除非另有规定,不要返回超过10行。
以下是相关表格信息:
- Customer(CustomerID INT,FirstName VARCHAR(100),LastName VARCHAR(100),Email VARCHAR(255),Phone VARCHAR(20),BillingAddress TEXT,ShippingAddress TEXT,CustomerSince DATE,IsActive TINYINT)
- Employee(EmployeeID INT,FirstName VARCHAR(100),LastName VARCHAR(100),Email VARCHAR(255),Phone VARCHAR(20),HireDate DATE,Position VARCHAR(100),Salary DECIMAL)
- InventoryLog(LogID INT,ProductID INT,ChangeDate DATE,QuantityChange INT,Notes TEXT)
- LineItem(LineItemID INT,SalesOrderID INT,ProductID INT,Quantity INT,UnitPrice DECIMAL,Discount DECIMAL,TotalPrice DECIMAL)
- Product(ProductID INT,ProductName VARCHAR(255),Description TEXT,UnitPrice DECIMAL,StockQuantity INT,ReorderLevel INT,Discontinued TINYINT)
- SalesOrder(SalesOrderID INT,CustomerID INT,OrderDate DATE,RequiredDate DATE,ShippedDate DATE,Status VARCHAR(50),Comments TEXT,PaymentMethod VARCHAR(50),IsPaid TINYINT)
- Supplier(SupplierID INT,CompanyName VARCHAR(255),ContactName VARCHAR(100),ContactTitle VARCHAR(50),Address TEXT,Phone VARCHAR(20),Email VARCHAR(255))
以下是一些问题及其相应的SQL查询示例。
用户输入:列出所有客户。
SQL查询:SELECT * FROM Customer;
用户输入:查找ID为1的客户下的所有订单。
SQL查询:SELECT * FROM SalesOrder WHERE CustomerID = 1;
用户输入:列出当前库存中的所有产品。
SQL查询:SELECT * FROM Product WHERE StockQuantity > 0;
用户输入:查找ID为10的产品的供应商。
SQL查询:SELECT s.CompanyName FROM Supplier s JOIN Product p ON s.SupplierID = p.SupplierID WHERE p.ProductID = 10;
用户输入:列出尚未发货的销售订单。
SQL查询:SELECT * FROM SalesOrder WHERE Status = 'Pending';
用户输入:销售部门有多少员工?
SQL查询:SELECT COUNT(*) FROM Employee WHERE Position LIKE '%sales%';
用户输入:列出销量最高的前5个产品。
SQL查询:SELECT ProductID, SUM(Quantity) AS TotalQuantity FROM LineItem GROUP BY ProductID ORDER BY TotalQuantity DESC LIMIT 5;
用户输入:找出今年完成的订单的总销售额。
SQL查询:SELECT SUM(TotalPrice) FROM SalesOrder WHERE YEAR(OrderDate) = YEAR(CURDATE()) AND Status = 'Completed';
用户输入:列出所有来自“纽约”的供应商。
SQL查询:SELECT * FROM Supplier WHERE Address LIKE '%New York%';
用户输入:库存低于再订购水平的产品有多少?
SQL查询:SELECT COUNT(*) FROM Product WHERE StockQuantity < ReorderLevel;
用户输入:列出名为“John Doe”的客户的所有订单。
SQL查询:SELECT so.* FROM SalesOrder so JOIN Customer c ON so.CustomerID = c.CustomerID WHERE c.FirstName = 'John' AND c.LastName = 'Doe';
用户输入:显示ID为20的产品的库存日志。
SQL查询:SELECT * FROM InventoryLog WHERE ProductID = 20;
用户输入:列出当前库存中的所有产品。
SQL查询:SELECT * FROM Product WHERE StockQuantity > 0;

动态Few Shot示例:
想象一下,您有一个大工具箱,但您只想拿出最适合当前工作的工具。SemanticSimilarityExampleSelector 做了类似的事情。它查看您的问题,并从集合中挑选出最相似的示例,以帮助模型理解您的问题。
#pip install faiss-cpu
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
FAISS,
k=5,
input_keys=["input"],
)
example_selector.select_examples({"input": "列出所有客户?"})
输出:
[{'input': '列出所有客户。', 'query': 'SELECT * FROM Customer;'},
{'input': "列出名为'John Doe'的客户的所有订单。",
'query': "SELECT so.* FROM SalesOrder so JOIN Customer c ON so.CustomerID = c.CustomerID WHERE c.FirstName = 'John' AND c.LastName = 'Doe';"},
{'input': '列出当前库存中的所有产品。',
'query': 'SELECT * FROM Product WHERE StockQuantity > 0;'},
{'input': '查找ID为1的客户下的所有订单。',
'query': 'SELECT * FROM SalesOrder WHERE CustomerID = 1;'},
{'input': "列出所有来自'纽约'的供应商。",
'query': "SELECT * FROM Supplier WHERE Address LIKE '%New York%';"}]
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="您是一位MySQL专家。给定一个输入问题,创建一个语法正确的MySQL查询以运行。除非另有规定,不要返回超过{top_k}行。\n\n以下是相关表格信息:{table_info}\n\n以下是一些问题及其相应的SQL查询示例。",
suffix="用户输入: {input}\nSQL查询: ",
input_variables=["input", "top_k", "table_info"],
)
# 使用调整后的参数创建SQL查询链
chain = create_sql_query_chain(llm, db, prompt)
# 使用与您的数据库相关的问题调用链
chain.invoke({"question": "当前库存中有多少产品?"})
输出:
'SELECT COUNT(*) FROM Product WHERE StockQuantity > 0;

增强大型语言模型的Few-shot文本到SQL 能力:关于提示设计策略的研究。
如何为LLMs提供文本到SQL提示: 零样本、单领域和跨领域设置的研究要点。
ChatGPT的全面评估: 零样本文本到SQL能力
探索思维链 风格提示用于文本到SQL

Gemini提供的图片
需要记住的关键点:
理解模式: 熟悉数据库结构,了解表格、它们之间的关系以及每列的数据类型。
清晰的用户提示: 鼓励用户在查询中提供清晰和具体的细节。例如,不要问“给我销售数字”,而应该问“上个季度产品X的总销售额是多少?”
设计系统提示: 设计系统提示,指导LLM如何解释用户问题并构建SQL查询。这可以包括指定SQL方言、输出格式以及日期范围或特定字段等任何约束。
处理多个表格: 处理复杂模式时,包括关于连接表格和管理它们之间关系的说明。例如,如果用户想了解销售情况,您可能需要连接Sales、Customers和Products表格。
融入示例: 包括几个自然语言查询转换为SQL查询的示例。这为LLM提供了一个遵循的模式。
测试和迭代: 使用各种查询测试您的提示,以确保它们生成正确的SQL语句。根据这些测试准备好根据需要调整您的提示。
用户提示: "每种产品去年贡献了多少销售额?"
系统提示: "要回答这个问题,连接Product和SalesOrder表格,过滤出去年的订单,并对每种产品的销售额求和。"
示例SQL: "SELECT Product.ProductName, SUM(SalesOrder.TotalSales)
FROM Product JOIN SalesOrder ON Product.ProductID = SalesOrder.ProductID
WHERE YEAR(SalesOrder.OrderDate) = YEAR(CURDATE()) - 1 GROUP BY Product.
ProductName;"
用户提示: "按销售额排名前5位的客户。"
系统提示: "通过连接Customer和SalesOrder表格,按客户分组并按销售总额排序,确定销售额最高的客户。"
示例SQL: "SELECT Customer.FirstName, Customer.LastName,
SUM(SalesOrder.TotalSales) AS TotalSales FROM Customer JOIN SalesOrder
ON Customer.CustomerID = SalesOrder.CustomerID GROUP BY Customer.CustomerID
ORDER BY TotalSales DESC LIMIT 5;"
用户提示: "上个月每个产品类别的平均销售额是多少?"
系统提示: "通过连接Product、SalesOrder,可能还有Category表格,计算平均销售额,按类别分组。"
示例SQL: "假设您有一个Category表格,查询可能如下所示:'SELECT Category.Name, AVG(SalesOrder.TotalSales) FROM SalesOrder
JOIN Product ON SalesOrder.ProductID = Product.ProductID JOIN Category ON
Product.CategoryID = Category.CategoryID WHERE MONTH(SalesOrder.OrderDate) =
MONTH(CURRENT_DATE - INTERVAL 1 MONTH) GROUP BY Category.Name;'"
如何生成动态提示:
1. 分析用户提示: 确定用户问题的意图和所需数据。
2. 选择相关表格: 根据意图,确定数据库中需要的表格和字段。
3. 生成系统提示: 使用模板或预定义模式创建系统提示,指导LLM生成正确的SQL查询。这可能涉及指定任务、涉及的表格以及应使用的任何特定SQL语法或函数。
# 定义用户意图与数据库模式元素之间的映射
intent_to_tables = {
"去年的总销售额": {
"tables": ["SalesOrder", "LineItem", "Product"],
"fields": ["ProductName", "SUM(TotalPrice)"],
"conditions": ["YEAR(OrderDate) = YEAR(CURDATE()) - 1"]
}
# 在此添加更多意图和相应的模式元素
}
def generate_system_prompt(user_prompt):
# 分析用户提示以确定意图
# 为简单起见,假设意图直接提供
intent = user_prompt # 实际情况下,使用NLP技术确定意图
# 根据意图检索相关表格、字段和条件
schema_info = intent_to_tables.get(intent, {})
# 生成系统提示
system_prompt = f"生成一个SQL查询以计算{intent}。"
system_prompt += f"使用表格:{', '.join(schema_info.get('tables', []))}。"
system_prompt += f"选择字段:{', '.join(schema_info.get('fields', []))}。"
system_prompt += f"在条件下:{', '.join(schema_info.get('conditions', []))}。"
return system_prompt
# 示例用法
user_prompt = "去年的总销售额"
system_prompt = generate_system_prompt(user_prompt)
print(system_prompt)
生成一个SQL查询以计算去年的总销售额。使用表格:SalesOrder, LineItem, Product。选择字段:ProductName, SUM(TotalPrice)。在条件下:YEAR(OrderDate) = YEAR(CURDATE()) - 1。
一套全面的系统提示:
system = """
Given the database schema below, generate a MySQL query based on the user's question. Ensure to consider totals from line items, inclusive date ranges, and correct data aggregation for summarization. Remember to handle joins, groupings, and orderings effectively.
Database schema:
- Customer (CustomerID, FirstName, LastName, Email, Phone, BillingAddress, ShippingAddress, CustomerSince, IsActive)
- Employee (EmployeeID, FirstName, LastName, Email, Phone, HireDate, Position, Salary)
- InventoryLog (LogID, ProductID, ChangeDate, QuantityChange, Notes)
- LineItem (LineItemID, SalesOrderID, ProductID, Quantity, UnitPrice, Discount, TotalPrice)
- Product (ProductID, ProductName, Description, UnitPrice, StockQuantity, ReorderLevel, Discontinued)
- SalesOrder (SalesOrderID, CustomerID, OrderDate, RequiredDate, ShippedDate, Status, Comments, PaymentMethod, IsPaid)
- Supplier (SupplierID, CompanyName, ContactName, ContactTitle, Address, Phone, Email)
Guidelines for SQL query generation:
1. **Ensure Efficiency and Performance**: Opt for JOINs over subqueries where possible, use indexes effectively, and mention any specific performance considerations to keep in mind.
2. **Adapt to Specific Analytical Needs**: Tailor WHERE clauses, JOIN operations, and aggregate functions to precisely meet the analytical question being asked.
3. **Complexity and Variations**: Include a range from simple to complex queries, illustrating different SQL functionalities such as aggregate functions, string manipulation, and conditional logic.
4. **Handling Specific Cases**: Provide clear instructions on managing NULL values, ensuring date ranges are inclusive, and handling special data integrity issues or edge cases.
5. **Explanation and Rationale**: After each generated query, briefly explain why this query structure was chosen and how it addresses the analytical need, enhancing understanding and ensuring alignment with requirements.
-- 1. Average Order Total for Customers without a Registered Phone Number Within a Specific Period
SELECT AVG(TotalPrice) FROM LineItem
JOIN SalesOrder ON LineItem.SalesOrderID = SalesOrder.SalesOrderID
JOIN Customer ON SalesOrder.CustomerID = Customer.CustomerID
WHERE Customer.Phone IS NULL AND SalesOrder.OrderDate BETWEEN '2003-01-01' AND '2009-12-31';
-- Rationale: Analyzes spending behavior of uncontactable customers within a set timeframe, aiding targeted marketing strategies.
-- 2. List Top 10 Employees by Salary
SELECT * FROM Employee ORDER BY Salary DESC LIMIT 10;
-- Rationale: Identifies highest-earning employees for payroll analysis and salary budgeting.
-- 3. Find the Total Quantity of Each Product Sold Last Month
SELECT Product.ProductName, SUM(LineItem.Quantity) AS TotalQuantitySold
FROM Product
JOIN LineItem ON Product.ProductID = LineItem.ProductID
JOIN SalesOrder ON LineItem.SalesOrderID = SalesOrder.SalesOrderID
WHERE SalesOrder.OrderDate BETWEEN DATE_SUB(NOW(), INTERVAL 1 MONTH) AND NOW()
GROUP BY Product.ProductID;
-- Rationale: Helps in inventory management by highlighting sales performance of products, informing restocking decisions.
-- 4. Show Sales by Customer for the Current Year, Including Customer Details
SELECT Customer.FirstName, Customer.LastName, SUM(LineItem.TotalPrice) AS TotalSales
FROM Customer
JOIN SalesOrder ON Customer.CustomerID = SalesOrder.CustomerID
JOIN LineItem ON SalesOrder.SalesOrderID = LineItem.SalesOrderID
WHERE YEAR(SalesOrder.OrderDate) = YEAR(CURDATE())
GROUP BY Customer.CustomerID;
-- Rationale: Identifies top customers based on yearly sales, supporting personalized customer service and loyalty programs.
-- 5. Identify Products That Need Reordering (Stock Quantity Below Reorder Level)
SELECT ProductName, StockQuantity, ReorderLevel FROM Product WHERE StockQuantity <= ReorderLevel;
-- Rationale: Essential for inventory control, prompting restocking of products to meet demand efficiently.
-- 6. Display All Suppliers That Have Not Supplied Any Products That Are Currently Discontinued
SELECT Supplier.CompanyName FROM Supplier
LEFT JOIN Product ON Supplier.SupplierID = Product.SupplierID
WHERE Product.Discontinued = 0
GROUP BY Supplier.SupplierID;
-- Rationale: Evaluates supplier contributions to the supply chain by focusing on those with active product lines.
Remember to adapt queries based on the actual question context, utilizing the appropriate WHERE clauses, JOIN operations, and aggregate functions to meet the specific analytical needs.
Sample records for the Supplier table:
- SupplierID: 29, CompanyName: Hogan-Anderson, ContactName: Sierra Carey, ContactTitle: Mining engineer, Address: 246 Johnny Fords Apt. 858, Williamsport, AK 96920, Phone: 232.945.6443, Email: rodney04@example.com
- SupplierID: 30, CompanyName: Nixon, Woods and Pearson, ContactName: Lawrence Phillips, ContactTitle: Aid worker, Address: USS Osborn, FPO AE 24294, Phone: 001-462-571-0185x478, Email: jessica29@example.org
Sample records for the Product table:
- ProductID: 1, ProductName: Reflect Sea, Description: Factor country center price pretty foreign theory paper fact machine two., UnitPrice: 191.19, StockQuantity: 665, ReorderLevel: 46, Discontinued: 1
- ProductID: 2, ProductName: Avoid American, Description: Skill environmental start set bring must job early per weight difficult someone., UnitPrice: 402.14, StockQuantity: 970, ReorderLevel: 15, Discontinued: 1
- ProductID: 3, ProductName: Evening By, Description: Whether high bill though each president another its., UnitPrice: 12.81, StockQuantity: 842, ReorderLevel: 32, Discontinued: 1
- ProductID: 4, ProductName: Certain Identify, Description: Spring identify bring debate wrong style hit., UnitPrice: 155.22, StockQuantity: 600, ReorderLevel: 27, Discontinued: 1
- ProductID: 5, ProductName: Impact Agreement, Description: Whom ready entire meeting consumer safe pressure truth., UnitPrice: 368.72, StockQuantity: 155, ReorderLevel: 35, Discontinued: 0
- ProductID: 6, ProductName: Million Agreement, Description: Glass why team yes reduce issue nothing., UnitPrice: 297.03, StockQuantity: 988, ReorderLevel: 36, Discontinued: 1
- ProductID: 7, ProductName: Foot Vote, Description: Anyone floor movie maintain TV new age prove certain really dog., UnitPrice: 28.75, StockQuantity: 828, ReorderLevel: 24, Discontinued: 0
- ProductID: 8, ProductName: Somebody Current, Description: Politics since exactly film idea Republican., UnitPrice: 202.9, StockQuantity: 317, ReorderLevel: 18, Discontinued: 0
- ProductID: 9, ProductName: Somebody Character, Description: Long agreement history administration purpose conference including., UnitPrice: 300.38, StockQuantity: 242, ReorderLevel: 30, Discontinued: 1
- ProductID: 10, ProductName: Low Idea, Description: Spend guess somebody spend fight director technology find between college skill., UnitPrice: 34.68, StockQuantity: 65, ReorderLevel: 27, Discontinued: 0
Use the above schema and sample records to generate syntactically correct SQL queries. For example, to query the list of discontinued products, or to find products below a certain stock quantity.
Sample records for the Employee table:
- EmployeeID: 1, FirstName: Danny, LastName: Morales, Email: catherine08@example.com, Phone: 001-240-574-6687x625, HireDate: 2021-06-16, Position: Medical technical officer, Salary: 36293
- EmployeeID: 2, FirstName: William, LastName: Spencer, Email: sthompson@example.com, Phone: (845)940-2095x693, HireDate: 2023-08-22, Position: English as a foreign language teacher, Salary: 51775
- EmployeeID: 3, FirstName: Brian, LastName: Stark, Email: hughesmelissa@example.com, Phone: 780.299.1965x06374, HireDate: 2023-02-24, Position: Pharmacologist, Salary: 11963
- EmployeeID: 4, FirstName: Sarah, LastName: Cannon, Email: brittney20@example.com, Phone: 512.717.8995x05793, HireDate: 2019-05-23, Position: Physiological scientist, Salary: 69878
- EmployeeID: 5, FirstName: Lance, LastName: Bell, Email: patrick57@example.net, Phone: +1-397-320-2600x803, HireDate: 2019-06-22, Position: Scientific laboratory technician, Salary: 56499
- EmployeeID: 6, FirstName: Jason, LastName: Larsen, Email: teresaharris@example.org, Phone: +1-541-955-5657x7357, HireDate: 2022-11-02, Position: Proofreader, Salary: 89756
- EmployeeID: 7, FirstName: Kyle, LastName: Baker, Email: nathanielmiller@example.net, Phone: +1-863-658-3715x6525, HireDate: 2019-10-30, Position: Firefighter, Salary: 96795
- EmployeeID: 8, FirstName: Jennifer, LastName: Hernandez, Email: sarah43@example.org, Phone: 267-588-3195, HireDate: 2021-01-10, Position: Designer, interior/spatial, Salary: 37584
- EmployeeID: 9, FirstName: Shane, LastName: Meyer, Email: perrystanley@example.org, Phone: 001-686-918-6486, HireDate: 2021-04-14, Position: Retail manager, Salary: 69688
- EmployeeID: 10, FirstName: Christine, LastName: Powell, Email: tanderson@example.org, Phone: 427.468.2131, HireDate: 2019-05-11, Position: Sports administrator, Salary: 39962
Use the above schema and sample records to generate syntactically correct SQL queries. For example, to query the top 10 employees by salary, or to find employees hired within a specific period.
Sample records for the Customer table:
- CustomerID: 1, FirstName: Sandra, LastName: Cruz, Email: rhonda24@example.net, Phone: 511-949-6987x21174, BillingAddress: "18018 Kyle Streets Apt. 606, Shaneville, AZ 85788", ShippingAddress: "18018 Kyle Streets Apt. 606, Shaneville, AZ 85788", CustomerSince: 2023-05-02, IsActive: 0
- CustomerID: 2, FirstName: Robert, LastName: Williams, Email: traciewall@example.net, Phone: 944-649-2491x60774, BillingAddress: "926 Mitchell Pass Apt. 342, Brianside, SC 83374", ShippingAddress: "926 Mitchell Pass Apt. 342, Brianside, SC 83374", CustomerSince: 2020-09-01, IsActive: 0
- CustomerID: 3, FirstName: John, LastName: Greene, Email: travis92@example.org, Phone: 279.334.1551, BillingAddress: "36019 Bill Manors Apt. 219, Dominiquefort, AK 55904", ShippingAddress: "36019 Bill Manors Apt. 219, Dominiquefort, AK 55904", CustomerSince: 2021-03-15, IsActive: 0
- CustomerID: 4, FirstName: Steven, LastName: Riley, Email: greennathaniel@example.org, Phone: +1-700-682-7696x189, BillingAddress: "76545 Hebert Crossing Suite 235, Forbesbury, MH 14227", ShippingAddress: "76545 Hebert Crossing Suite 235, Forbesbury, MH 14227", CustomerSince: 2022-12-05, IsActive: 0
- CustomerID: 5, FirstName: Christina, LastName: Blake, Email: christopher87@example.net, Phone: 584.263.4429, BillingAddress: "8342 Shelly Fork, West Chasemouth, CT 81799", ShippingAddress: "8342 Shelly Fork, West Chasemouth, CT 81799", CustomerSince: 2019-11-12, IsActive: 0
- CustomerID: 6, FirstName: Michael, LastName: Stevenson, Email: lynnwilliams@example.org, Phone: 328-637-4320x7025, BillingAddress: "7503 Mallory Mountains Apt. 199, Meganport, MI 81064", ShippingAddress: "7503 Mallory Mountains Apt. 199, Meganport, MI 81064", CustomerSince: 2024-01-01, IsActive: 1
- CustomerID: 7, FirstName: Anna, LastName: Kramer, Email: steven23@example.org, Phone: +1-202-719-6886x844, BillingAddress: "295 Mcgee Fort, Manningberg, PR 93309", ShippingAddress: "295 Mcgee Fort, Manningberg, PR 93309", CustomerSince: 2022-03-06, IsActive: 1
- CustomerID: 8, FirstName: Michael, LastName: Sullivan, Email: bbailey@example.com, Phone: 988.368.5033, BillingAddress: "772 Bruce Motorway Suite 583, Powellbury, MH 42611", ShippingAddress: "772 Bruce Motorway Suite 583, Powellbury, MH 42611", CustomerSince: 2019-03-23, IsActive: 1
- CustomerID: 9, FirstName: Kevin, LastName: Moody, Email: yoderjennifer@example.org, Phone: 3425196543, BillingAddress: "371 Lee Lake, New Michaelport, CT 99382", ShippingAddress: "371 Lee Lake, New Michaelport, CT 99382", CustomerSince: 2023-12-03, IsActive: 1
- CustomerID: 10, FirstName: Jeremy, LastName: Mejia, Email: spencersteven@example.org, Phone: 449.324.7097, BillingAddress: "90137 Harris Garden, Matthewville, IA 39321", ShippingAddress: "90137 Harris Garden, Matthewville, IA 39321", CustomerSince: 2019-05-20, IsActive: 1
These sample records provide a clear representation of the data structure for customers within the database schema. Use these details to assist in generating queries that involve customer information, such as filtering active customers, summarizing sales by customer, or identifying long-term customers.
Sample records for the InventoryLog table:
- LogID: 1, ProductID: 301, ChangeDate: 2023-09-08, QuantityChange: 84, Notes: Inventory increased
- LogID: 2, ProductID: 524, ChangeDate: 2023-08-09, QuantityChange: -84, Notes: Inventory decreased
- LogID: 3, ProductID: 183, ChangeDate: 2023-04-17, QuantityChange: -51, Notes: Inventory decreased
- LogID: 4, ProductID: 390, ChangeDate: 2023-02-27, QuantityChange: 80, Notes: Inventory increased
- LogID: 5, ProductID: 737, ChangeDate: 2023-11-15, QuantityChange: 24, Notes: Inventory increased
- LogID: 6, ProductID: 848, ChangeDate: 2023-11-22, QuantityChange: 69, Notes: Inventory increased
- LogID: 7, ProductID: 534, ChangeDate: 2023-06-06, QuantityChange: -61, Notes: Inventory decreased
- LogID: 8, ProductID: 662, ChangeDate: 2024-01-16, QuantityChange: 70, Notes: Inventory increased
- LogID: 9, ProductID: 969, ChangeDate: 2024-01-07, QuantityChange: -25, Notes: Inventory decreased
- LogID: 10, ProductID: 640, ChangeDate: 2023-08-08, QuantityChange: -13, Notes: Inventory decreased
These sample records provide insights into the inventory adjustments for different products within the database schema. Utilize these details to assist in generating queries that track inventory changes, analyze stock levels, or evaluate inventory management efficiency.
Sample records for the LineItem table:
- LineItemID: 1, SalesOrderID: 280, ProductID: 290, Quantity: 3, UnitPrice: 84.59, Discount: NULL, TotalPrice: 253.77
- LineItemID: 2, SalesOrderID: 94, ProductID: 249, Quantity: 6, UnitPrice: 88.7, Discount: NULL, TotalPrice: 532.2
- LineItemID: 3, SalesOrderID: 965, ProductID: 247, Quantity: 1, UnitPrice: 43.44, Discount: NULL, TotalPrice: 43.44
- LineItemID: 4, SalesOrderID: 173, ProductID: 16, Quantity: 10, UnitPrice: 26.3, Discount: NULL, TotalPrice: 263
- LineItemID: 5, SalesOrderID: 596, ProductID: 191, Quantity: 9, UnitPrice: 59.44, Discount: NULL, TotalPrice: 534.96
- LineItemID: 6, SalesOrderID: 596, ProductID: 308, Quantity: 8, UnitPrice: 33.11, Discount: NULL, TotalPrice: 264.88
- LineItemID: 7, SalesOrderID: 960, ProductID: 758, Quantity: 5, UnitPrice: 64.47, Discount: NULL, TotalPrice: 322.35
- LineItemID: 8, SalesOrderID: 148, ProductID: 288, Quantity: 5, UnitPrice: 65.21, Discount: NULL, TotalPrice: 326.05
- LineItemID: 9, SalesOrderID: 974, ProductID: 706, Quantity: 3, UnitPrice: 59.86, Discount: NULL, TotalPrice: 179.58
- LineItemID: 10, SalesOrderID: 298, ProductID: 998, Quantity: 2, UnitPrice: 75.79, Discount: NULL, TotalPrice: 151.58
These sample records illustrate various line items associated with sales orders in the database. These details help in constructing queries to analyze sales performance, product popularity, pricing strategies, and overall sales revenue.
Sample records for the SalesOrder table:
- SalesOrderID: 1, CustomerID: 12, OrderDate: 2022-11-05, RequiredDate: 2022-12-02, ShippedDate: 2022-11-25, Status: Pending, Comments: NULL, PaymentMethod: NULL, IsPaid: 0
- SalesOrderID: 2, CustomerID: 56, OrderDate: 2022-02-22, RequiredDate: 2022-03-08, ShippedDate: 2022-03-17, Status: Completed, Comments: NULL, PaymentMethod: NULL, IsPaid: 1
- SalesOrderID: 3, CustomerID: 63, OrderDate: 2023-03-20, RequiredDate: 2023-03-27, ShippedDate: NULL, Status: Shipped, Comments: NULL, PaymentMethod: NULL, IsPaid: 0
- SalesOrderID: 4, CustomerID: 21, OrderDate: 2023-04-29, RequiredDate: 2023-05-26, ShippedDate: 2023-05-14, Status: Pending, Comments: NULL, PaymentMethod: NULL, IsPaid: 1
- SalesOrderID: 5, CustomerID: 16, OrderDate: 2022-11-05, RequiredDate: 2022-11-30, ShippedDate: NULL, Status: Shipped, Comments: NULL, PaymentMethod: NULL, IsPaid: 1
- SalesOrderID: 6, CustomerID: 46, OrderDate: 2023-10-06, RequiredDate: 2023-10-27, ShippedDate: NULL, Status: Shipped, Comments: NULL, PaymentMethod: NULL, IsPaid: 1
- SalesOrderID: 7, CustomerID: 47, OrderDate: 2023-02-08, RequiredDate: 2023-02-25, ShippedDate: 2023-03-03, Status: Shipped, Comments: NULL, PaymentMethod: NULL, IsPaid: 1
- SalesOrderID: 8, CustomerID: 70, OrderDate: 2022-07-29, RequiredDate: 2022-08-18, ShippedDate: 2022-08-10, Status: Pending, Comments: NULL, PaymentMethod: NULL, IsPaid: 0
- SalesOrderID: 9, CustomerID: 14, OrderDate: 2022-03-29, RequiredDate: 2022-04-15, ShippedDate: 2022-04-17, Status: Completed, Comments: NULL, PaymentMethod: NULL, IsPaid: 0
- SalesOrderID: 10, CustomerID: 31, OrderDate: 2024-01-12, RequiredDate: 2024-01-31, ShippedDate: 2024-02-07, Status: Pending, Comments: NULL, PaymentMethod: NULL, IsPaid: 0
These sample records provide insights into sales order management within the database, including order status, shipping details, payment methods, and customer IDs. This information is crucial for analyzing sales processes, order fulfillment rates, customer engagement, and payment transactions.
"""
数据库模式概述:详细列出了SalesOrder数据库模式的结构,列出了表格及其用途。
SQL查询生成指南:提供了创建高效准确的SQL查询的原则,涵盖了JOINs、WHERE子句和聚合函数。
处理特定情况:管理NULL值的指导以及确保日期范围是包容性的说明。
每个表格的示例记录:提供了来自Supplier、Product、Employee、Customer、InventoryLog、LineItem和SalesOrder表的示例,以说明存储的数据类型。
适应指南:鼓励根据特定的分析需求定制查询,提供常见查询及其原理的示例。
第4部分:SQL查询验证:
查询验证:
要求LLM通过在系统提示中添加验证规则来验证生成的查询。
仔细检查用户的{dialect}查询,查找常见错误,包括:
- 在NULL值中使用NOT IN
- 在应该使用UNION ALL时使用UNION
- 在排他性范围中使用BETWEEN
- 谓词中的数据类型不匹配
- 适当引用标识符
- 对函数使用正确数量的参数
- 强制转换为正确的数据类型
- 对JOIN使用正确的列
如果存在以上任何错误,请重新编写查询。如果没有错误,只需重现原始查询。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
system = """根据下面的数据库模式,根据用户的问题生成一个MySQL查询。记得根据需要从行项目计算总数,并确保除非另有说明,否则所有日期范围都是包容性的。正确地聚合数据以进行汇总,例如计算订单总额的平均值。
- Customer (CustomerID INT, FirstName VARCHAR(100), LastName VARCHAR(100), Email VARCHAR(255), Phone VARCHAR(20), BillingAddress TEXT, ShippingAddress TEXT, CustomerSince DATE, IsActive TINYINT)
- Employee (EmployeeID INT, FirstName VARCHAR(100), LastName VARCHAR(100), Email VARCHAR(255), Phone VARCHAR(20), HireDate DATE, Position VARCHAR(100), Salary DECIMAL)
- InventoryLog (LogID INT, ProductID INT, ChangeDate DATE, QuantityChange INT, Notes TEXT)
- LineItem (LineItemID INT, SalesOrderID INT, ProductID INT, Quantity INT, UnitPrice DECIMAL, Discount DECIMAL, TotalPrice DECIMAL)
- Product (ProductID INT, ProductName VARCHAR(255), Description TEXT, UnitPrice DECIMAL, StockQuantity INT, ReorderLevel INT, Discontinued TINYINT)
- SalesOrder (SalesOrderID INT, CustomerID INT, OrderDate DATE, RequiredDate DATE, ShippedDate DATE, Status VARCHAR(50), Comments TEXT, PaymentMethod VARCHAR(50), IsPaid TINYINT)
- Supplier (SupplierID INT, CompanyName VARCHAR(255), ContactName VARCHAR(100), ContactTitle VARCHAR(50), Address TEXT, Phone VARCHAR(20), Email VARCHAR(255))
示例任务:计算没有注册电话号码的客户在特定时期内下订单的平均总价。
示例查询:"SELECT AVG(sum_li.TotalPrice) FROM SalesOrder JOIN (SELECT SalesOrderID, SUM(TotalPrice) AS TotalPrice FROM LineItem GROUP BY SalesOrderID) sum_li ON SalesOrder.SalesOrderID = sum_li.SalesOrderID JOIN Customer ON SalesOrder.CustomerID = Customer.CustomerID WHERE Customer.Phone IS NULL AND SalesOrder.OrderDate BETWEEN '2003-01-01' AND '2009-12-31';"
仔细检查用户的{dialect}查询,查找常见错误,包括:
- 在NULL值中使用NOT IN
- 在应该使用UNION ALL时使用UNION
- 在排他性范围中使用BETWEEN
- 谓词中的数据类型不匹配
- 适当引用标识符
- 对函数使用正确数量的参数
- 强制转换为正确的数据类型
- 对JOIN使用正确的列
如果存在以上任何错误,请重新编写查询。如果没有错误,只需重现原始查询。
仅输出最终的SQL查询。不要包含文本,请仅输出SQL查询"""
prompt = ChatPromptTemplate.from_messages(
[("system", system), ("human", "{query}")]
).partial(dialect=db.dialect)
validation_chain = prompt | llm | StrOutputParser()
full_chain = {"query": chain} | validation_chain

第5部分:数据库中非描述性或特定语言的表格和字段名称:
对于具有非描述性或特定语言的表格和字段名称的数据库,创建一个全面的映射或字典,将这些技术标识符翻译为更易理解的术语将非常有帮助。这种映射可以作为用户的自然语言查询和实际数据库模式之间的桥梁,使LLM能够生成准确的SQL查询。
创建翻译映射: 开发一个全面的映射,将技术标识符(表格名称、字段名称)翻译为更易理解或英文术语。这有助于连接用户的自然语言查询和实际数据库模式之间的差距。
将映射整合到LLM输入中: 直接将这种映射整合到系统提示中,或用它预处理用户查询,使LLM更容易理解并生成正确的SQL查询。
使用自定义数据调整LLM: 考虑在包括技术标识符及其翻译的示例上微调LLM,以提高其直接处理此类情况的能力。
使用带注释的示例: 在提示中或作为训练数据的一部分,包括使用技术标识符的自然语言问题及其相应的SQL查询的示例,为LLM提供上下文。
# 技术标识符到易理解术语的示例映射
mapping = {
"kunnr": "customer",
"lifnr": "vendor",
# 根据需要添加更多映射
}
def translate_query(user_query, mapping):
for technical_term, common_term in mapping.items():
user_query = user_query.replace(common_term, technical_term)
return user_query
# 示例用法
user_query = "Show sales for vendor last year"
translated_query = translate_query(user_query, mapping)
# 现在translated_query可以传递给LLM生成SQL查询
第6部分:大规模企业挑战
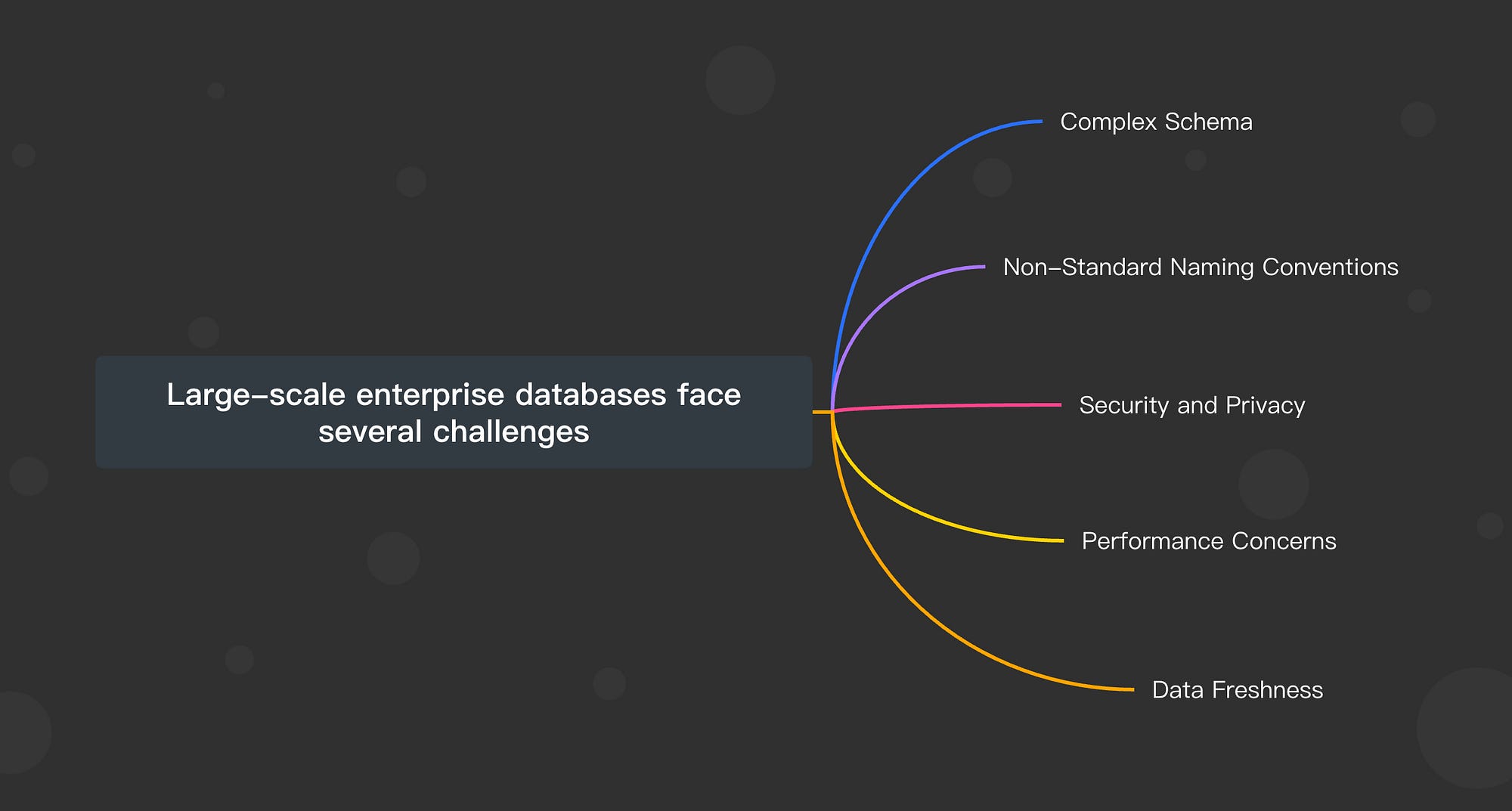
大规模企业数据库面临几个挑战:
复杂的模式: 企业通常具有复杂的数据库模式,拥有数百个表格和关系,使得LLM在没有广泛领域知识的情况下难以生成准确的SQL查询。
非标准命名约定: 如前所述,数据库可能使用非直观的命名约定或不同语言,需要映射或额外上下文来有效生成查询。
安全和隐私: 在真实数据库上直接执行生成的SQL查询可能存在安全风险,包括潜在的数据暴露或注入攻击。
性能问题: 在大型数据库上生成和执行SQL查询可能会消耗大量资源,影响数据库性能。
数据新鲜度: 企业需要实时数据,但LLM可能生成不考虑最新数据更新的查询,导致过时的见解。
第7部分:文本到可视化:
Gemini提供的图片
利用LLM设计文本到可视化工具包括:
理解用户查询: 解析自然语言输入以辨别用户意图和他们想要可视化的数据。
映射到数据库查询: 将解析的意图转换为SQL查询,以从数据库中获取相关数据。
选择可视化类型: 基于查询结果和用户意图,选择适当的可视化类型(条形图、折线图、饼图)。
生成可视化: 使用Python中的数据可视化库(例如Matplotlib、Plotly)创建查询数据的可视化表示。
与LLM整合: 利用LLM来优化查询理解,建议可视化类型,并通过反馈循环改进用户交互。
用户界面设计: 创建一个用户友好的界面,允许轻松输入文本查询并有效显示可视化效果。
伪代码:
from your_llm_library import LLM # 假设LLM库
import matplotlib.pyplot as plt
import pandas as pd
sql_connector # 假设连接和执行SQL查询的模块
# 初始化LLM
llm = LLM(api_key="your_api_key")
def query_database(sql_query):
# 连接到数据库并执行SQL查询
# 将结果作为DataFrame返回
connection = sql_connector.connect(host="your_host", database="your_db", user="your_user", password="your_password")
return pd.read_sql(sql_query, connection)
def generate_visualization(data, visualization_type):
# 根据类型和数据生成可视化
if visualization_type == "bar":
data.plot(kind="bar")
plt.show()
# 根据需要添加更多可视化类型
def text_to_sql(text_input):
# 使用LLM将文本输入转换为SQL查询
sql_query = llm.generate_sql_query(text_input)
return sql_query
def text_to_visualization(text_input):
# 将文本输入转换为SQL查询
sql_query = text_to_sql(text_input)
# 查询数据库
data = query_database(sql_query)
# 根据数据或用户输入确定可视化类型
visualization_type = "bar" # 这可以动态确定
# 生成可视化
generate_visualization(data, visualization_type)
# 示例用法
text_input = "Show total sales per product last year"
text_to_visualization(text_input)
这段伪代码概述了将用户的自然语言输入转换为 SQL 查询,从数据库中获取数据,并基于获取的数据生成可视化的步骤。实际实现将取决于您使用的 LLM 库、数据库设置以及您喜欢的 Python 数据可视化库。
这是一个概念验证代码,您可以在此基础上不断改进。
from langchain_community.utilities import SQLDatabase
# 调整 MySQL 的连接 URI
db = SQLDatabase.from_uri("mysql+mysqlconnector://'your user id':'your password@localhost/SalesOrderSchema")
import pandas as pd
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import pandas as pd
# 假设 'db' 是您从 langchain_community.utilities 中获得的 SQLDatabase 实例
# 并且 execute_query 是执行 SQL 并返回 pandas DataFrame 的函数
# 使用 GPT-4 初始化 LLM
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 使用 LLM 和您的数据库配置创建 SQL 查询链
chain = create_sql_query_chain(llm, db)
# 为基于模式生成 SQL 查询的系统消息定义
system = """
给定下面的数据库模式,根据用户的问题生成一个 MySQL 查询。记得根据需要计算行项目的总数,并确保所有日期范围是包容性的,除非另有说明。正确地对数据进行汇总,如平均订单总额。
- Customer (CustomerID INT, FirstName VARCHAR(100), LastName VARCHAR(100), Email VARCHAR(255), Phone VARCHAR(20), BillingAddress TEXT, ShippingAddress TEXT, CustomerSince DATE, IsActive TINYINT)
- Employee (EmployeeID INT, FirstName VARCHAR(100), LastName VARCHAR(100), Email VARCHAR(255), Phone VARCHAR(20), HireDate DATE, Position VARCHAR(100), Salary DECIMAL)
- InventoryLog (LogID INT, ProductID INT, ChangeDate DATE, QuantityChange INT, Notes TEXT)
- LineItem (LineItemID INT, SalesOrderID INT, ProductID INT, Quantity INT, UnitPrice DECIMAL, Discount DECIMAL, TotalPrice DECIMAL)
- Product (ProductID INT, ProductName VARCHAR(255), Description TEXT, UnitPrice DECIMAL, StockQuantity INT, ReorderLevel INT, Discontinued TINYINT)
- SalesOrder (SalesOrderID INT, CustomerID INT, OrderDate DATE, RequiredDate DATE, ShippedDate DATE, Status VARCHAR(50), Comments TEXT, PaymentMethod VARCHAR(50), IsPaid TINYINT)
- Supplier (SupplierID INT, CompanyName VARCHAR(255), ContactName VARCHAR(100), ContactTitle VARCHAR(50), Address TEXT, Phone VARCHAR(20), Email VARCHAR(255))
"""
prompt = ChatPromptTemplate.from_messages(
[("system", system)]
).partial(dialect=db.dialect)
# 假设 'execute_query' 是执行生成的 SQL 查询并返回 DataFrame 的函数
def execute_query(sql_query):
# 执行 SQL 查询并返回 pandas DataFrame 的实现
pass
# 使用链基于自然语言输入生成 SQL 查询
query_input = "Show me the total sales for each product last year"
query_response = chain.invoke({"question": query_input})
# 执行生成的 SQL 查询
#df = execute_query(query_response)
query_results = db.run(query_response)
import pandas as pd
from decimal import Decimal
# 用于演示的虚拟数据;用实际的 query_results 替换这部分
#query_results_str = "[('Reflect Sea', Decimal('25.31')), ('Avoid American', Decimal('514.63'))]"
query_results_str = query_results
query_results_str = query_results_str.replace("Decimal('", "").replace("')", "")
# 尝试安全地将字符串评估为元组列表
try:
query_results_evaluated = eval(query_results_str, {'Decimal': Decimal})
except Exception as e:
print(f"评估过程中出错: {e}")
query_results_evaluated = []
# 将 Decimal 转换为 float 并准备 DataFrame
query_results_converted = [(name, float(total)) if isinstance(total, Decimal) else (name, total) for name, total in query_results_evaluated]
# 创建 DataFrame
df = pd.DataFrame(query_results_converted, columns=['ProductName', 'TotalSales'])
df_json = df.to_json(orient='split', index=False)
# 继续您的工作流程...
# 为生成 Matplotlib 可视化代码准备提示模板
# 为生成 Matplotlib 可视化代码准备提示模板
prompt_template = ChatPromptTemplate.from_template(
"给定以下数据,使用 Matplotlib 生成 Python 代码,创建最能展示数据见解的适当可视化。决定最适合显示数据的图表类型(如柱状图、饼图、折线图)。提供简要解释为何选择这种可视化类型。这是数据:{data}"
)
# 使用 GPT-4 初始化模型
model = ChatOpenAI(model="gpt-4")
# 初始化输出解析器以提取字符串响应
output_parser = StrOutputParser()
# 创建链:提示 + 模型 + 输出解析器
visualization_chain = prompt_template | model | output_parser
# 使用 DataFrame JSON 作为输入调用链
visualization_code = visualization_chain.invoke({"data": df_json})
# 打印生成的代码以供审查
#print(visualization_code)
mixed_text = visualization_code
code_start = mixed_text.find("python") + len("python")
code_end = mixed_text.find("```", code_start)
generated_code = mixed_text[code_start:code_end].strip()
#print(generated_code)
exec(generated_code)
输出 — 如果启用所有打印语句,您可以看到输出。
SELECT `Product`.`ProductName`, SUM(`LineItem`.`TotalPrice`) AS `TotalSales`
FROM `Product`
JOIN `LineItem` ON `Product`.`ProductID` = `LineItem`.`ProductID`
JOIN `SalesOrder` ON `LineItem`.`SalesOrderID` = `SalesOrder`.`SalesOrderID`
WHERE YEAR(`SalesOrder`.`OrderDate`) = YEAR(CURDATE()) - 1
GROUP BY `Product`.`ProductName`
LIMIT 5;
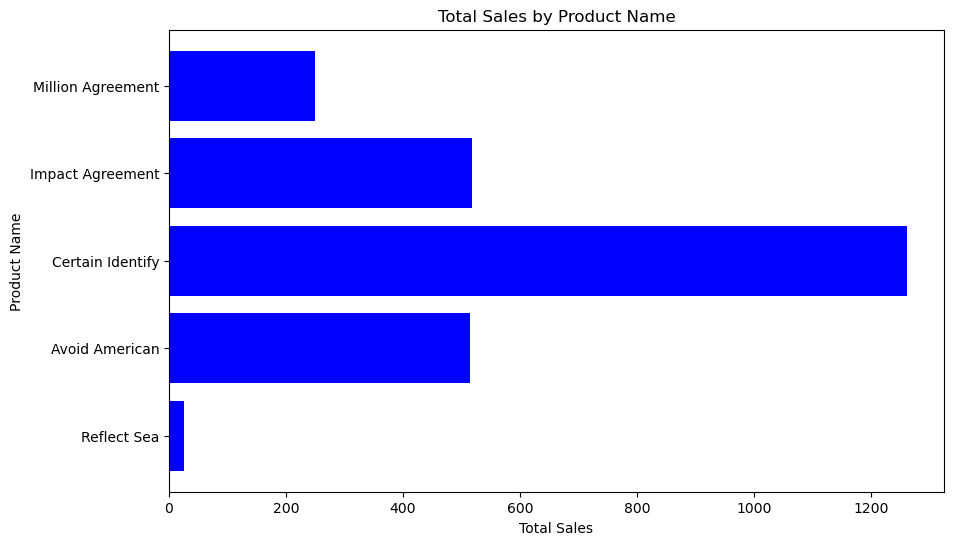
[('Reflect Sea', Decimal('25.31')), ('Avoid American', Decimal('514.63')), ('Certain Identify', Decimal('1260.98')), ('Impact Agreement', Decimal('518.32')), ('Million Agreement', Decimal('250.02'))]
提供的数据可以用柱状图表示。柱状图适合比较不同产品名称的总销售额。以下是使用 Matplotlib 可视化这些数据的 Python 代码:
import matplotlib.pyplot as plt
import pandas as pd
# 数据
data_dict = {"columns":["ProductName","TotalSales"],"data":[["Reflect Sea",25.31],["Avoid American",514.63],["Certain Identify",1260.98],["Impact Agreement",518.32],["Million Agreement",250.02]]}
# 将数据转换为 pandas DataFrame
df = pd.DataFrame(data_dict['data'], columns=data_dict['columns'])
# 创建柱状图
plt.figure(figsize=(10,6))
plt.barh(df['ProductName'], df['TotalSales'], color='blue')
plt.xlabel('总销售额')
plt.ylabel('产品名称')
plt.title('按产品名称的总销售额')
plt.show()
此代码首先将数据转换为 pandas DataFrame,这样更容易操作和绘制。然后创建一个水平柱状图,y 轴为 ‘ProductName’ 列,x 轴为 ‘TotalSales’ 列。为了更清晰,将图的大小设置为 10x6,并添加标签和标题以提供上下文。条的颜色设置为蓝色,但您可以根据喜好更改颜色。
import matplotlib.pyplot as plt
import pandas as pd
# 数据
data_dict = {"columns":["ProductName","TotalSales"],"data":[["Reflect Sea",25.31],["Avoid American",514.63],["Certain Identify",1260.98],["Impact Agreement",518.32],["Million Agreement",250.02]]}
# 将数据转换为 pandas DataFrame
df = pd.DataFrame(data_dict['data'], columns=data_dict['columns'])
# 创建柱状图
plt.figure(figsize=(10,6))
plt.barh(df['ProductName'], df['TotalSales'], color='blue')
plt.xlabel('总销售额')
plt.ylabel('产品名称')
plt.title('按产品名称的总销售额')
plt.show()
代码概览:
初始化 LLM: 使用 GPT-4,设置一个准备处理输入的实例。
创建 SQL 查询链: 将 LLM 与您的数据库结合,旨在将自然语言问题转换为 SQL 查询。
定义系统消息: 提供有关数据库模式的上下文,以帮助生成准确的 SQL 查询。
生成 SQL 查询: 将用户的自然语言输入(“Show me the total sales for each product last year”)转换为可执行的 SQL 查询。
执行 SQL 查询: 运行生成的查询以从数据库中获取所需数据。
准备数据进行可视化: 将查询结果转换为适合可视化的格式。
生成可视化代码: 生成用于创建可视化(例如使用 Matplotlib)的 Python 代码,展示数据见解。
执行可视化代码: 运行生成的 Python 代码以生成可视化。
第8部分-使用 Ollama 进行文本到 SQL:
您还可以使用 Ollama 将模型下载到您自己的计算机上并尝试。在使用以下命令之前,请在您的计算机上安装 Ollama。
https://ollama.com/
我尝试了 Google Gemma 模型。
!ollama pull gemma
!ollama run gemma
v_sys="""
You are the MySQL expert and you are going to generate MySQL queries on the user question.
Given the database schema below, generate a MySQL query based on the user's question. Ensure to consider totals from line items, inclusive date ranges, and correct data aggregation for summarization. Remember to handle joins, groupings, and orderings effectively.
Database schema:
- Customer (CustomerID, FirstName, LastName, Email, Phone, BillingAddress, ShippingAddress, CustomerSince, IsActive)
- Employee (EmployeeID, FirstName, LastName, Email, Phone, HireDate, Position, Salary)
- InventoryLog (LogID, ProductID, ChangeDate, QuantityChange, Notes)
- LineItem (LineItemID, SalesOrderID, ProductID, Quantity, UnitPrice, Discount, TotalPrice)
- Product (ProductID, ProductName, Description, UnitPrice, StockQuantity, ReorderLevel, Discontinued)
- SalesOrder (SalesOrderID, CustomerID, OrderDate, RequiredDate, ShippedDate, Status, Comments, PaymentMethod, IsPaid)
- Supplier (SupplierID, CompanyName, ContactName, ContactTitle, Address, Phone, Email)
SQL查询生成指南:
1. **确保效率和性能**:尽可能使用JOIN而非子查询,有效使用索引,并提及需要考虑的任何特定性能问题。
2. **适应特定分析需求**:调整WHERE子句、JOIN操作和聚合函数,精确满足所提出的分析问题。
3. **复杂性和变化**:包括从简单到复杂的查询范围,展示不同的SQL功能,如聚合函数、字符串操作和条件逻辑。
4. **处理特定情况**:清晰说明如何处理NULL值,确保日期范围是包容的,并处理特殊数据完整性问题或边缘情况。
5. **解释和理由**:在生成的每个查询之后,简要解释选择该查询结构的原因以及它如何满足分析需求,增强理解并确保与要求一致。"""
import ollama
r = ollama.generate(
model='gemma',
system= v_sys,
prompt="""List Top 10 Employees by Salary?"""
)
print(r['response'])
## List Top 10 Employees by Salary
SELECT * FROM Employee ORDER BY Salary DESC LIMIT 10;
**Rationale:**
This query selects all employees and sorts them in descending order based on their salaries. The `ORDER BY` clause specifies the sorting criteria, and the `LIMIT 10` clause restricts the results to the top 10 employees.
**Notes:**
* This query assumes that the `Salary` column in the `Employee` table contains
numeric values representing salaries.
* The query does not filter employees based on any specific criteria. To
restrict the results to a specific group of employees, you can add additional conditions to the `WHERE` clause.
**Additional Considerations:**
* Index on the `Salary` column to improve query performance.
* Handle NULL values in the `Salary` column appropriately.
他们还为文本到SQL提供了一些优化模型

第9部分-文本到SQL评估:

- Bird-用于大规模数据库的大型台架的文本到SQL
BIRD-bench
BIRD-benchbird-bench.github.io
https://bird-bench.github.io/
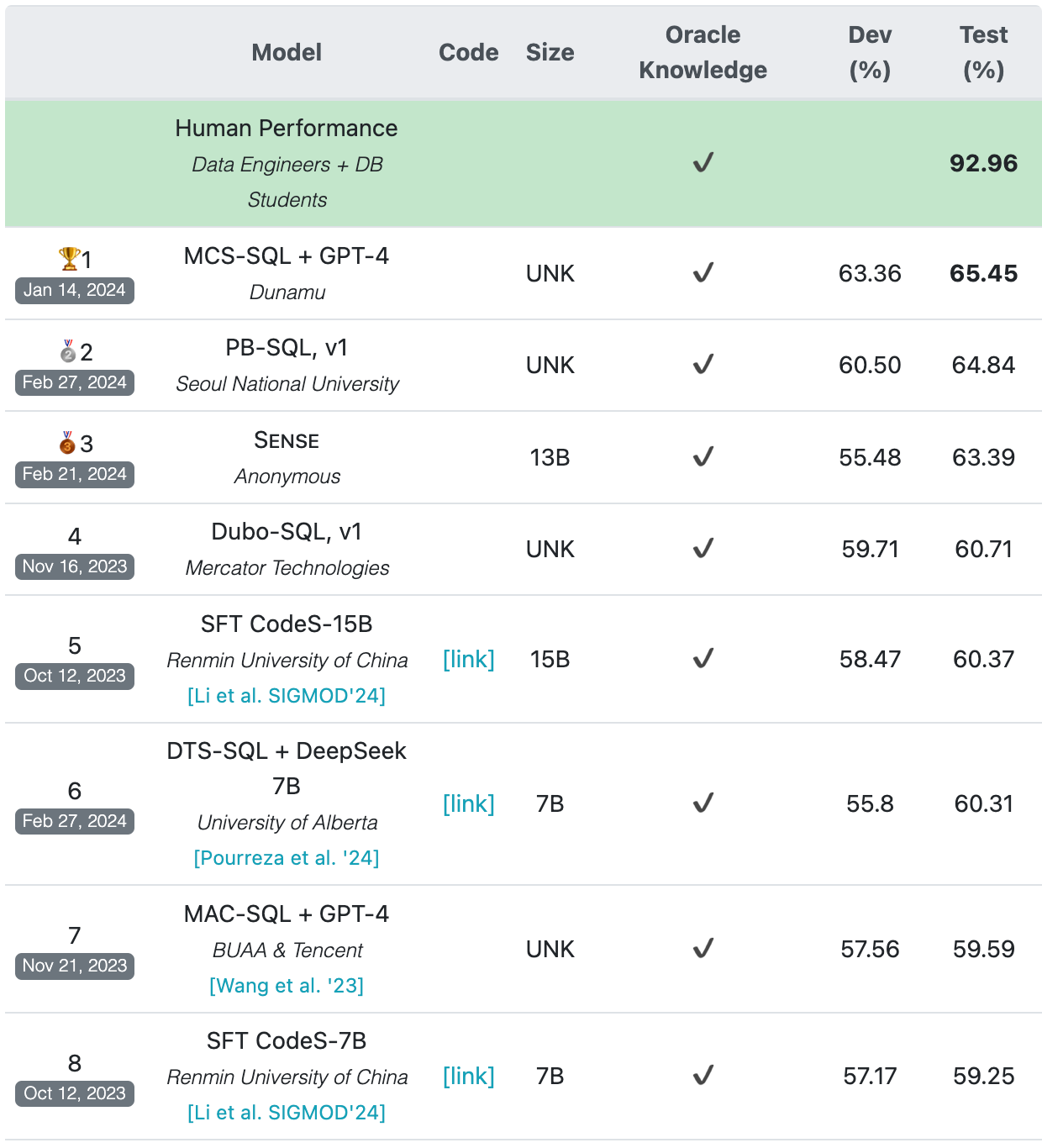
- Spider 1.0 — 耶鲁语义解析和文本到SQL挑战
yale-lily.github.io
- WikiSQL
GitHub - salesforce/WikiSQL: 用于开发自然语言接口的大型注释语义解析语料库
github.com
- Defog- SQL 评估
GitHub - defog-ai/sql-eval: 评估LLM生成输出的准确性
他们的评估方法:
我们的测试程序包括以下步骤。对于每个问题/查询对:
我们生成一个SQL查询(可能来自LLM)。
我们在各自的数据库上运行“gold”查询和生成的查询,以获得具有结果的2个数据框。
我们使用“精确”和“子集”匹配比较这两个数据框。TODO 添加博客文章链接。
我们记录这些数据以及其他感兴趣的指标(例如使用的标记、延迟)并汇总结果以供报告。
第10部分-使用Llamaindex进行文本到SQL。
让我们看看如何使用Llamaindex进行文本到SQL。

图片来源:Llamaindex 文档
让我们在同一个数据库上工作
- MySQL数据库。
- 销售订单模式。
- 之前创建的7个表。
- 安装所有必需的库。
!pip install mysql-connector-python SQLAlchemy pandas
%pip install llama-index-embeddings-openai
!pip install llama-index-llms-openai # 这是假设的;如果不同,请替换为正确的库名称。
!pip install pyvis networkx
- 提供 OpenAi 密钥:
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
- 连接到 MySQL 数据库:
from sqlalchemy import create_engine
# MySQL 的 SQLAlchemy 连接字符串
database_url = "mysql+mysqlconnector://"Your userID":"Password"@localhost/SalesOrderSchema"
# 创建引擎
mysql_engine = create_engine(database_url)
**从 SQLAlchemy 导入 create_engine:**这一行从 SQLAlchemy 库中导入 create_engine 函数,用于创建与数据库的连接引擎。
**定义数据库 URL:**database_url 是一个字符串,指定了连接到 MySQL 数据库的连接详细信息。它包括数据库适配器(mysql+mysqlconnector)、用户名(root)、密码(‘Your Password’)、主机(localhost)和数据库名称(SalesOrderSchema)。
这个 URL 的格式是:方言+驱动程序://用户名:密码@主机/数据库。
**创建引擎:**mysql_engine = create_engine(database_url) 使用 create_engine 函数创建了一个 SQLAlchemy 引擎。这个引擎是一个管理与数据库连接的对象,使用 database_url 中提供的连接详细信息。引擎负责在需要连接时连接到数据库,但不会在创建时建立连接。
**目的和用法:**create_engine 创建的引擎是 SQLAlchemy SQL 表达语言和 ORM(对象关系映射)功能的核心组件。它可用于执行原始 SQL 查询、使用 ORM 与数据库交互等。
这种设置允许您使用 SQLAlchemy 强大灵活的工具进行数据库操作,抽象了直接访问数据库的许多复杂性。
4. 表信息:
table_infos = [
{"table_name": "Customer", "table_summary": "包含客户信息,包括联系方式和地址。"},
{"table_name": "Employee", "table_summary": "包含员工记录,他们的职位和薪水信息。"},
{"table_name": "InventoryLog", "table_summary": "跟踪库存变化,包括产品数量和相关备注。"},
{"table_name": "LineItem", "table_summary": "详细说明销售订单中的每个项目,包括定价和数量。"},
{"table_name": "Product", "table_summary": "列出可用产品,包括描述、价格和库存水平。"},
{"table_name": "SalesOrder", "table_summary": "记录客户订单,包括订单日期、送货信息和付款状态。"},
{"table_name": "Supplier", "table_summary": "存储有关供应商的信息,包括公司和联系方式。"}
]
**字典列表:**table_infos 是一个列表,是一个有序且可更改的集合。列表中的每个项都是一个代表数据库中表的字典。
**字典结构:**列表中的每个字典有两个键:table_name 和 table_summary。table_name 是一个字符串,保存数据库中表的名称。这是 SQL 查询中用于标识表的方式。
table_summary 是一个字符串,提供了关于表包含或代表的简要描述。这个摘要为表在数据库中的角色提供了背景,对于文档、代码可读性或为可能使用这些描述来更好地理解数据库模式的系统提供见解都是有帮助的。
**目的:**这种结构旨在以结构化格式提供关于数据库中表的元数据。它可用于文档目的,以帮助生成动态查询,或与需要数据库模式描述的系统进行交互。
**示例用例:**如果您正在使用将自然语言查询转换为 SQL 查询的系统(如前面讨论的文本到 SQL 功能),table_infos 可以为系统提供有关每个表的必要上下文。例如,知道 Customer 表包含客户信息,包括联系方式和地址,可能有助于系统在用户要求客户联系信息时生成更准确的查询。
**可扩展性:**这种方法很容易扩展。如果数据库模式发生变化(例如,添加新表或更改现有表的目的),您只需更新 table_infos 列表以反映这些变化。
5. 对象索引 + 检索器以存储表模式:
从 llama_index.core.objects 导入 (
SQLTableNodeMapping,
ObjectIndex,
SQLTableSchema,
)
从 llama_index.core 导入 SQLDatabase, VectorStoreIndex
sql_database = SQLDatabase(engine=mysql_engine)
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [
SQLTableSchema(table_name=t['table_name'], context_str=t['table_summary'])
for t in table_infos
]
obj_index = ObjectIndex.from_objects(
table_schema_objs,
table_node_mapping,
VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
导入语句: 代码首先从 llama_index.core 包中导入各种类,包括 SQLTableNodeMapping、ObjectIndex、SQLTableSchema、SQLDatabase 和 VectorStoreIndex。每个类在为 LlamaIndex 框架内部创建数据库架构的索引表示时发挥作用。
**创建 SQLDatabase 实例:**sql_database = SQLDatabase(engine=mysql_engine) 使用之前定义的 mysql_engine 创建了一个 SQLDatabase 实例。这个 SQLDatabase 对象旨在提供一个接口,用于在 LlamaIndex 系统内与 MySQL 数据库进行交互,抽象了直接的 SQL 操作。
**初始化表节点映射:**table_node_mapping = SQLTableNodeMapping(sql_database) 初始化了一个负责在数据库表的逻辑结构(作为节点)和由 sql_database 表示的物理数据库之间进行映射的对象。这种映射对于需要理解数据库架构的操作至关重要,比如从自然语言输入生成 SQL 查询。
**创建表模式对象:**列表推导式 [SQLTableSchema(table_name=t[‘table_name’], context_str=t[‘table_summary’]) for t in table_infos] 遍历了您定义的 table_infos 列表。对于每个条目,它创建了一个 SQLTableSchema 实例,表示数据库中一个表的架构,包括其名称和上下文摘要。这构成了在 LlamaIndex 系统内理解和与每个表交互的基础。
**创建对象索引:**obj_index = ObjectIndex.from_objects(table_schema_objs, table_node_mapping, VectorStoreIndex,) 创建了数据库架构的索引表示。它使用表模式对象(table_schema_objs)、表节点映射(table_node_mapping)和向量存储索引(VectorStoreIndex)来促进基于相似性或相关性的高效检索和查询数据库架构信息。
**初始化检索器:**obj_retriever = obj_index.as_retriever(similarity_top_k=3) 从对象索引初始化了一个检索器。此检索器配置为根据给定查询获取最相关的前 k 个(此处为 3 个)表模式对象。这种功能可能用于动态识别在将自然语言查询转换为 SQL 时应考虑哪些表,基于查询与表的上下文摘要的相似性。
6. SQLDatabase 对象连接到上述表 + SQLRetriever:
from llama_index.core.retrievers import SQLRetriever
from typing import List
from llama_index.core.query_pipeline import FnComponent
sql_retriever = SQLRetriever(sql_database)
def get_table_context_str(table_schema_objs: List[SQLTableSchema]):
"""获取表上下文字符串。"""
context_strs = []
for table_schema_obj in table_schema_objs:
table_info = sql_database.get_single_table_info(
table_schema_obj.table_name
)
if table_schema_obj.context_str:
table_opt_context = " 表描述如下:"
table_opt_context += table_schema_obj.context_str
table_info += table_opt_context
context_strs.append(table_info)
return "\n\n".join(context_strs)
table_parser_component = FnComponent(fn=get_table_context_str)
**SQLRetriever 初始化:**sql_retriever = SQLRetriever(sql_database) 使用先前初始化的 sql_database 对象创建了一个 SQLRetriever 实例。这表明 sql_retriever 能够执行数据库检索,可能利用了 sql_database 封装的架构信息。
**定义获取表上下文字符串的函数:**get_table_context_str 是一个函数,接受一个 SQLTableSchema 对象列表(table_schema_objs),为每个表生成一个上下文字符串。这个上下文字符串可能用于提供关于每个表的额外信息,有助于生成或理解从自然语言输入派生的 SQL 查询。在函数内部,它遍历 table_schema_objs,为每个表模式对象(table_schema_obj)从 sql_database 获取额外的表信息。如果 table_schema_obj 包含 context_str(表的摘要或描述),则将其附加到表信息中,增强了对每个表提供的详细信息。
生成的字符串被收集到 context_strs 列表中,然后使用双换行符(\n\n)作为分隔符连接成一个字符串,使最终输出更易于阅读或进一步处理。
**创建表解析器组件:**table_parser_component = FnComponent(fn=get_table_context_str) 将 get_table_context_str 函数包装在 FnComponent 中,使其成为可以集成到查询处理管道中的组件。在 LlamaIndex 的上下文中,此组件可用于动态生成与给定自然语言查询相关的带有上下文丰富描述的表,支持将该查询转换为准确的 SQL 语句。
7. 文本转 SQL 提示:
from llama_index.core.prompts.default_prompts import DEFAULT_TEXT_TO_SQL_PROMPT
from llama_index.core import PromptTemplate
from llama_index.core.query_pipeline import FnComponent
from llama_index.core.llms import ChatResponse
def parse_response_to_sql(response: ChatResponse) -> str:
"""解析响应为 SQL。"""
response = response.message.content
sql_query_start = response.find("SQLQuery:")
if sql_query_start != -1:
response = response[sql_query_start:]
# TODO: 在 Python 3.9+ 后移至 removeprefix
if response.startswith("SQLQuery:"):
response = response[len("SQLQuery:") :]
sql_result_start = response.find("SQLResult:")
if sql_result_start != -1:
response = response[:sql_result_start]
return response.strip().strip("```").strip()
sql_parser_component = FnComponent(fn=parse_response_to_sql)
text2sql_prompt = DEFAULT_TEXT_TO_SQL_PROMPT.partial_format(
dialect=mysql_engine.dialect.name
)
print(text2sql_prompt.template)
**解析模型响应:**parse_response_to_sql 是一个函数,接受来自聊天或语言模型的响应(封装在 ChatResponse 对象中),并从中提取一个 SQL 查询。这是必要的,因为模型的响应可能包含除了 SQL 查询之外的附加信息或格式化。它搜索响应以找到特定标记(SQLQuery: 和 SQLResult:),以隔离文本中的 SQL 查询部分。这种解析策略暗示着期望语言模型的响应遵循结构化格式,其中清晰地划分了 SQL 查询及其结果。
**创建 SQL 解析器组件:**sql_parser_component = FnComponent(fn=parse_response_to_sql) 将 parse_response_to_sql 函数包装在 FnComponent 中,使其能够集成到查询处理管道中。这种设置有助于从模型响应中自动提取 SQL 查询,然后可以针对数据库执行或进一步处理。
**设置文本转 SQL 提示:**text2sql_prompt = DEFAULT_TEXT_TO_SQL_PROMPT.partial_format(dialect=mysql_engine.dialect.name) 初始化了一个提示模板,用于从自然语言问题生成 SQL 查询。该模板根据数据库的特定 SQL 方言(在本例中为 MySQL)进行了定制,该方言由 SQLAlchemy 引擎(mysql_engine)的 dialect 属性确定。这种定制确保为语言模型生成的提示与 MySQL 支持的 SQL 语法相符,增加了生成的 SQL 查询在语法上正确且可执行的可能性。
**打印提示模板:**print(text2sql_prompt.template) 将格式化后的提示模板打印到控制台。这对于调试或了解发送给语言模型的提示很有用。
给定一个输入问题,首先创建一个符合 {dialect} 查询以运行,然后查看查询结果并返回答案。您可以按相关列对结果进行排序,以返回数据库中最有趣的示例。
永远不要查询特定表的所有列,只需根据问题询问几个相关列。
注意只使用您在架构描述中看到的列名。注意不要查询不存在的列。注意哪个列在哪个表中。在必要时使用表名限定列名。您需要使用以下格式,每行一个:
问题:这里是问题
SQLQuery:要运行的 SQL 查询
SQLResult:SQLQuery 的结果
答案:这里是最终答案
只使用下面列出的表。
{schema}
问题:{query_str}
SQLQuery:
8. 响应合成提示:
from llama_index.core.program import LLMTextCompletionProgram
from llama_index.core.bridge.pydantic import BaseModel, Field
from llama_index.llms.openai import OpenAI
response_synthesis_prompt_str = (
"给定一个输入问题,从查询结果中合成一个响应。\n"
"查询:{query_str}\n"
"SQL:{sql_query}\n"
"SQL 响应:{context_str}\n"
"响应:"
)
response_synthesis_prompt = PromptTemplate(
response_synthesis_prompt_str,
)
**创建 PromptTemplate 实例:**response_synthesis_prompt 是使用 response_synthesis_prompt_str 初始化的 PromptTemplate 实例。该对象封装了提示模板,通过填充特定的查询字符串、SQL 查询和查询结果的占位符,轻松生成动态提示。这种设置表明 response_synthesis_prompt 将用于为语言模型(如 OpenAI 的 GPT-3)生成提示,以便生成基于从数据库检索的实际数据但以人类可理解和有用的方式格式化和措辞的答案。
9. LLM:
llm = OpenAI(model="gpt-4")
10. 定义查询管道:
from llama_index.core.query_pipeline import (
QueryPipeline as QP,
Link,
InputComponent,
CustomQueryComponent,
)
qp = QP(
modules={
"input": InputComponent(),
"table_retriever": obj_retriever,
"table_output_parser": table_parser_component,
"text2sql_prompt": text2sql_prompt,
"text2sql_llm": llm,
"sql_output_parser": sql_parser_component,
"sql_retriever": sql_retriever,
"response_synthesis_prompt": response_synthesis_prompt,
"response_synthesis_llm": llm,
},
verbose=True,
)
查询管道的组件
QueryPipeline(QP):这是组织系统中数据和操作流程的主要结构。它定义了如何通过各个阶段或组件处理输入查询以生成输出。verbose=True参数表示管道应提供关于其处理阶段的详细日志或输出,这对于调试或理解管道行为很有帮助。- 模块:
modules字典中的每个键值对表示管道的一个组件:"input":一个InputComponent,可能处理查询的初始接收。"table_retriever":使用obj_retriever(之前定义的)来识别基于查询的相关数据库表。"table_output_parser":处理表检索的输出,可能格式化或进一步细化它。"text2sql_prompt":管理为将文本查询转换为 SQL 查询生成提示。"text2sql_llm":表示负责处理文本到 SQL 提示的语言模型(LLM)组件。"sql_output_parser":解析 SQL 查询的输出,提取相关信息或准备进行进一步处理。"sql_retriever":执行针对数据库的 SQL 查询并检索结果。"response_synthesis_prompt":处理为从 SQL 查询结果中合成人类可读响应而创建提示。"response_synthesis_llm":处理响应合成的语言模型组件。
管道的工作原理
- 输入处理:管道通过
input组件接收自然语言查询开始。 - 表检索:然后使用
table_retriever确定与查询相关的数据库表。 - 输出解析:
table_output_parser可能会格式化或从表检索步骤中提取有用信息以通知后续阶段。 - 提示生成和 LLM 处理:
text2sql_prompt根据输入查询和可能的表信息创建结构化提示,然后由text2sql_llm处理以生成 SQL 查询。- 在执行 SQL 查询并检索结果后(
sql_retriever),response_synthesis_prompt组件创建另一个提示,旨在合成人类可读响应。此提示由response_synthesis_llm处理,后者使用 SQL 结果和原始查询上下文生成最终答案。 - 链接:
QueryPipeline对象的设置暗示这些组件之间有定义的链接,尽管具体的链接(Link,CustomQueryComponent)在片段中没有明确显示。这些链接规定了数据和控制在组件之间的流动,确保一个组件的输出按照管道的逻辑作为下一个组件的输入。
qp.add_chain(["input", "table_retriever", "table_output_parser"])
qp.add_link("input", "text2sql_prompt", dest_key="query_str")
qp.add_link("table_output_parser", "text2sql_prompt", dest_key="schema")
qp.add_chain(
["text2sql_prompt", "text2sql_llm", "sql_output_parser", "sql_retriever"]
)
qp.add_link(
"sql_output_parser", "response_synthesis_prompt", dest_key="sql_query"
)
qp.add_link(
"sql_retriever", "response_synthesis_prompt", dest_key="context_str"
)
qp.add_link("input", "response_synthesis_prompt", dest_key="query_str")
qp.add_link("response_synthesis_prompt", "response_synthesis_llm")
11. 管道可视化:
from pyvis.network import Network
net = Network(notebook=True, cdn_resources="in_line", directed=True)
net.from_nx(qp.dag)
net.show("text2sql_dag.html")
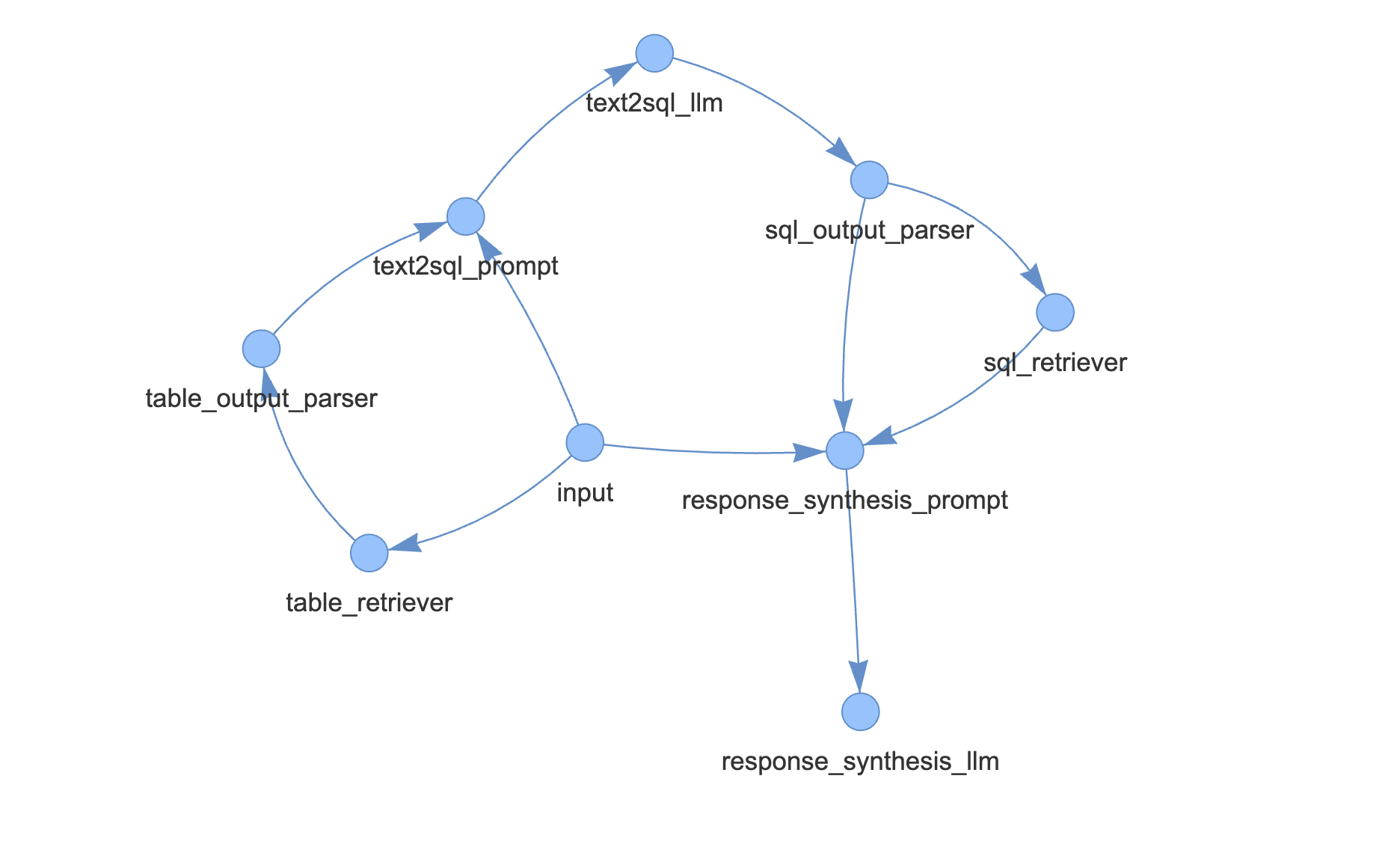
12. 执行一些查询:
查询:1
response = qp.run(
query="List Top 10 Employees by Salary?"
)
print(str(response))
> Running module input with input:
query: List Top 10 Employees by Salary?
> Running module table_retriever with input:
input: List Top 10 Employees by Salary?
> Running module table_output_parser with input:
table_schema_objs: [SQLTableSchema(table_name='Employee', context_str='Contains employee records, their positions, and salary information.'), SQLTableSchema(table_name='Customer', context_str='Holds customer information...
> Running module text2sql_prompt with input:
query_str: List Top 10 Employees by Salary?
schema: Table 'Employee' has columns: EmployeeID (INTEGER), FirstName (VARCHAR(100)), LastName (VARCHAR(100)), Email (VARCHAR(255)), Phone (VARCHAR(20)), HireDate (DATE), Position (VARCHAR(100)), Salary (DECI...
> Running module text2sql_llm with input:
messages: Given an input question, first create a syntactically correct mysql query to run, then look at the results of the query and return the answer. You can order the results by a relevant column to return ...
> Running module sql_output_parser with input:
response: assistant: SELECT EmployeeID, FirstName, LastName, Salary FROM Employee ORDER BY Salary DESC LIMIT 10
SQLResult:
EmployeeID | FirstName | LastName | Salary
1 | John | Doe | 100000
...
> Running module sql_retriever with input:
input: SELECT EmployeeID, FirstName, LastName, Salary FROM Employee ORDER BY Salary DESC LIMIT 10
> Running module response_synthesis_prompt with input:
query_str: List Top 10 Employees by Salary?
sql_query: SELECT EmployeeID, FirstName, LastName, Salary FROM Employee ORDER BY Salary DESC LIMIT 10
context_str: [NodeWithScore(node=TextNode(id_='02c6e159-d328-4bab-8911-eef1daf06bb2', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={}, text="[(959, 'Je...
> Running module response_synthesis_llm with input:
messages: Given an input question, synthesize a response from the query results.
Query: List Top 10 Employees by Salary?
SQL: SELECT EmployeeID, FirstName, LastName, Salary FROM Employee ORDER BY Salary DESC LI...
assistant: The top 10 employees by salary are:
1. Jessica Marsh with a salary of $99,846.00
2. Mary Clarke with a salary of $99,607.00
3. Shelby Cochran with a salary of $99,463.00
4. Christine Mason with a salary of $99,100.00
5. Henry Robinson with a salary of $99,090.00
6. Donald Morris with a salary of $99,086.00
7. Ruth White with a salary of $99,065.00
The remaining employees' details are not fully provided in the query response.
查询:2
response = qp.run(
query= """Calculate the average number of days between order placement and shipment for all orders shipped last year,
and identify the customer with the longest average shipping delay?""")
print(str(response))
> Running module input with input:
query: Calculate the average number of days between order placement and shipment for all orders shipped last year,
and identify the customer with the longest average shipping delay?
> Running module table_retriever with input:
input: Calculate the average number of days between order placement and shipment for all orders shipped last year,
and identify the customer with the longest average shipping delay?
> Running module table_output_parser with input:
table_schema_objs: [SQLTableSchema(table_name='SalesOrder', context_str='Records customer orders, including order dates, shipping information, and payment status.'), SQLTableSchema(table_name='Customer', context_str='Ho...
> Running module text2sql_prompt with input:
query_str: Calculate the average number of days between order placement and shipment for all orders shipped last year,
and identify the customer with the longest average shipping delay?
schema: Table 'SalesOrder' has columns: SalesOrderID (INTEGER), CustomerID (INTEGER), OrderDate (DATE), RequiredDate (DATE), ShippedDate (DATE), Status (VARCHAR(50)), Comments (TEXT), PaymentMethod (VARCHAR(5...
> Running module text2sql_llm with input:
messages: Given an input question, first create a syntactically correct mysql query to run, then look at the results of the query and return the answer. You can order the results by a relevant column to return ...
> Running module sql_output_parser with input:
response: assistant: SELECT AVG(DATEDIFF(SalesOrder.ShippedDate, SalesOrder.OrderDate)) AS AverageDays, Customer.FirstName, Customer.LastName
FROM SalesOrder
JOIN Customer ON SalesOrder.CustomerID = Customer....
> Running module sql_retriever with input:
input: SELECT AVG(DATEDIFF(SalesOrder.ShippedDate, SalesOrder.OrderDate)) AS AverageDays, Customer.FirstName, Customer.LastName
FROM SalesOrder
JOIN Customer ON SalesOrder.CustomerID = Customer.CustomerID ...
> Running module response_synthesis_prompt with input:
query_str: Calculate the average number of days between order placement and shipment for all orders shipped last year,
and identify the customer with the longest average shipping delay?
sql_query: SELECT AVG(DATEDIFF(SalesOrder.ShippedDate, SalesOrder.OrderDate)) AS AverageDays, Customer.FirstName, Customer.LastName
FROM SalesOrder
JOIN Customer ON SalesOrder.CustomerID = Customer.CustomerID ...
context_str: [NodeWithScore(node=TextNode(id_='1e988d3f-4019-451b-8b84-62144e09d15a', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={}, text="[(Decimal(...
> Running module response_synthesis_llm with input:
messages: Given an input question, synthesize a response from the query results.
Query: Calculate the average number of days between order placement and shipment for all orders shipped last year,
and identify ...
assistant: The average number of days between order placement and shipment for all orders shipped last year was 30 days. The customer with the longest average shipping delay was Jonathan Burke.
查询:3
response = qp.run(
query= """计算过去三年内曾经购买过商品的每位顾客的生命周期价值(总销售额),按最高价值降序排列,并显示前5名。""")
print(str(response))
> 运行模块输入,输入为:
query: 计算过去三年内曾经购买过商品的每位顾客的生命周期价值(总销售额),按最高价值降序排列,并显示前5名。
> 运行模块表检索器,输入为:
input: 计算过去三年内曾经购买过商品的每位顾客的生命周期价值(总销售额),按最高价值降序排列,并显示前5名。
> 运行模块表输出解析器,输入为:
table_schema_objs: [SQLTableSchema(table_name='SalesOrder', context_str='Records customer orders, including order dates, shipping information, and payment status.'), SQLTableSchema(table_name='Customer', context_str='Ho...
> 运行模块文本转SQL提示,输入为:
query_str: 计算过去三年内曾经购买过商品的每位顾客的生命周期价值(总销售额),按最高价值降序排列,并显示前5名。
schema: 表'SalesOrder'具有列:SalesOrderID(整数),CustomerID(整数),OrderDate(日期),RequiredDate(日期),ShippedDate(日期),Status(VARCHAR(50)),Comments(文本),PaymentMethod(VARCHAR(5...
> 运行模块文本到SQL LLM,输入为:
messages: 给定一个输入问题,首先创建一个语法正确的mysql查询来运行,然后查看查询结果并返回答案。您可以按相关列对结果进行排序以返回...
> 运行模块SQL输出解析器,输入为:
response: assistant: SELECT Customer.CustomerID, Customer.FirstName, Customer.LastName, SUM(LineItem.TotalPrice) as LifetimeValue
FROM Customer
JOIN SalesOrder ON Customer.CustomerID = SalesOrder.CustomerID
JOI...
> 运行模块SQL检索器,输入为:
input: SELECT Customer.CustomerID, Customer.FirstName, Customer.LastName, SUM(LineItem.TotalPrice) as LifetimeValue
FROM Customer
JOIN SalesOrder ON Customer.CustomerID = SalesOrder.CustomerID
JOIN LineItem ...
> 运行模块响应合成提示,输入为:
query_str: 计算过去三年内曾经购买过商品的每位顾客的生命周期价值(总销售额),按最高价值降序排列,并显示前5名。
sql_query: SELECT Customer.CustomerID, Customer.FirstName, Customer.LastName, SUM(LineItem.TotalPrice) as LifetimeValue
FROM Customer
JOIN SalesOrder ON Customer.CustomerID = SalesOrder.CustomerID
JOIN LineItem ...
context_str: [NodeWithScore(node=TextNode(id_='c37b8a16-0132-48d5-9425-5eba1281d7a5', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={}, text="[(61, 'Bra...
> 运行模块响应合成LLM,输入为:
messages: 给定一个输入问题,从查询结果中合成一个响应。
Query: 计算过去三年内曾经购买过商品的每位顾客的生命周期价值(总销售额),...
assistant: 过去三年内销售额最高的五位顾客的生命周期价值(总销售额)如下:
1. Bradley Quinn,总销售额为$34,389.10
2. Laura Mueller,总销售额为$33,312.42
3. Michael Jordan,总销售额为$24,295.07
4. Don Lowery,总销售额为$24,055.13
5. Jerry Haas,总销售额为$23,851.82
第11部分 — 使用 SQL 数据集对 LLM 进行微调:

图片来源:Google 博客
请查看 colab 笔记本。我已为大多数单元格提供了注释。这只是展示如何对模型进行微调的示例。
- 安装 Gemma 模型、数据处理和微调所需的 Python 库。
- 通过 Hugging Face 进行身份验证以访问模型和数据集。
- 加载经过优化以进行高效推理的 Gemma 模型。
- 为微调准备和格式化数据集。
- 配置 LoRA 以进行参数高效微调。
- 初始化和配置微调训练器。
- 执行微调过程。
- 使用经过微调的模型从自然语言提示生成 SQL 查询。

第12部分 — Pandas AI:
docs.pandas-ai.com
根据他们的文档:
PandasAI 是一个 Python 库,它使得向数据(CSV、XLSX、PostgreSQL、MySQL、BigQuery、Databrick、Snowflake 等)提出问题变得容易,可以用自然语言进行提问。它帮助您使用生成式人工智能来探索、清理和分析数据。
除了查询外,PandasAI 还提供了通过图表可视化数据、通过处理缺失值来清理数据集以及通过特征生成来提高数据质量等功能,使其成为数据科学家和分析师的综合工具。
请查看:
Pandas AI:
# 使用 poetry(推荐)
poetry add pandasai
# 使用 pip
pip install pandasai
import pandas as pd
from pandasai import SmartDataframe
# 示例 DataFrame
products_data = pd.DataFrame({
"category": ["Electronics", "Clothing", "Toys", "Electronics", "Clothing", "Toys", "Electronics", "Clothing", "Toys", "Electronics"],
"product": ["Laptop", "Jeans", "Teddy Bear", "Smartphone", "T-Shirt", "Puzzle", "Tablet", "Dress", "Board Game", "Camera"],
"price": [1200, 80, 20, 800, 25, 15, 500, 100, 30, 450],
"units_sold": [300, 1500, 800, 500, 2000, 1500, 400, 1200, 1000, 350]
})
# 实例化 LLM
from pandasai.llm import OpenAI
llm = OpenAI(api_token="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")
# 转换为 SmartDataframe
df = SmartDataframe(products_data, config={"llm": llm})
# 向 LLM 提问
df.chat('最有利可图的产品类别是什么?')
# 问题1:找出每个类别中产品的平均价格。
response = df.chat('每个类别中产品的平均价格是多少?')
print(response)
category price
0 Clothing 500.0
1 Electronics 15.0
2 Toys 1200.0
# 问题2:确定每个产品类别生成的总收入。
response = df.chat('每个产品类别生成了多少总收入?')
print(response)
category revenue
0 Clothing 500000
1 Electronics 12000
2 Toys 600000
# 问题3:比较两个类别的销售量。
response = df.chat('电子产品和玩具的销售量如何比较?')
print(response)
电子产品的销售量高于玩具的销售量。
# 问题4:查询数据集中最昂贵的产品。
response = df.chat('数据集中最昂贵的产品是什么?')
print(response)
数据集中最昂贵的产品是智能手机。
df.chat('绘制每个产品类别生成的总收入,为每个类别使用不同颜色')
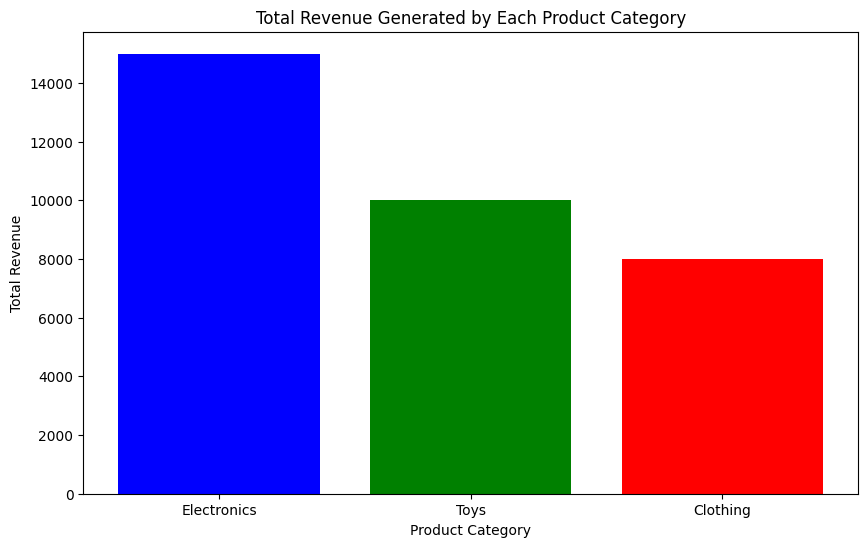

第13部分:一些相关论文:
- 1. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation (https://arxiv.org/abs/2308.15363)
- 对基于大型语言模型的文本到SQL的各种提示工程方法进行全面评估。
- 提出了 DAIL-SQL,一种在 Spider 排行榜基准上名列前茅的新解决方案。
- 探讨了使用和微调开源大型语言模型。
- 2.Evaluating the Text-to-SQL Capabilities of Large Language Models(https://arxiv.org/abs/2204.00498)
- 分析 Codex 语言模型在文本到SQL任务中的能力。
- 在 Spider 基准上展示了强大的性能,无需进行任何微调。
- 探讨了少样本示例对进一步改进的影响。
- 3.Analyzing the Effectiveness of Large Language Models on Text-to-SQL Synthesis (https://arxiv.org/html/2401.12379v1)
- 调查大型语言模型在文本到SQL合成中处理聚合等细微差别的能力。
- 强调了LLM在这一领域的优势和局限性。
- 4.Global Reasoning over Database Structures for Text-to-SQL Parsing(https://arxiv.org/abs/2004.07320)
- 引入了一种全局推理方法,以更好地捕捉数据库模式不同组件之间的关系。
- 5.RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers (https://arxiv.org/abs/1911.04942)
- 提出了一种方法,将模式编码和链接集成到文本到SQL系统中,以提高准确性。
- 6.Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing (https://arxiv.org/abs/1805.07555)
- 专注于处理跨多个数据库领域的查询。
- 7.Enhancing Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies (https://arxiv.org/abs/2305.12586)
- 探讨了用于在文本到SQL任务中提示LLM的不同设计策略。
- 调查了演示和指令格式选择如何影响结果。
- 引入了 TypeSQL,它将类型意识融入提示中,以更好地理解模式约束。
- 9.拆解问题:一种文本到SQL的问题分解方法 (https://arxiv.org/abs/2008.06750)
- 提出了一种将复杂SQL查询分解为更小、更易翻译的子查询的方法。
- 10.RAT-SQL++:面向文本到SQL解析器的关系感知模式编码和链接 (https://aclanthology.org/2020.acl-main.369.pdf)
- 借助增强的关系编码技术改进了 RAT-SQL 模型,以更好地处理复杂的SQL结构。
- 11.从对话上下文生成跨领域文本到SQL (https://arxiv.org/abs/2003.10024)
- 专注于对话环境中的文本到SQL,其中查询的领域可能在对话中发生变化。
结论:
在大型企业使用 Text2SQL 面临许多挑战,如确保数据安全、确保翻译正确以及将这项技术顺利整合到现有系统中。尽管存在这些障碍,但使数据更易访问和决策更高效的潜在好处是显著的,而且这项 Text2SQL 技术正在迅速发展。


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











