







Sora作为AGI世界模型?关于文本到视频生成的完整调查
论文名称:Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
摘要
文本到视频生成标志着生成式人工智能领域的一个重要前沿,整合了文本到图像合成、视频字幕和文本引导编辑方面的进展。本调查对文本到视频技术的发展进行了批判性审视,重点关注从传统生成模型到尖端Sora模型的转变,突出了在可扩展性和泛化性方面的发展。我们的分析与先前的研究有所不同,深入探讨了这些模型的技术框架和演进路径。此外,我们深入探讨了实际应用,并解决了伦理和技术挑战,例如无法执行多实体处理、理解因果关系学习、理解物理交互、感知物体缩放和比例以及对抗物体幻觉,这也是生成模型中长期存在的问题。我们全面讨论了将文本到视频生成模型作为人类辅助工具和世界模型的话题,以及揭示模型的缺陷并总结未来改进方向,主要集中在训练数据集和评估指标(自动和以人为中心)上。本调查旨在面向新手和经验丰富的研究人员,旨在催生文本到视频生成领域的进一步创新和讨论,为更可靠和实用的生成式人工智能技术铺平道路。
目录
- 引言 3
- 核心技术 4
- 骨干架构 4
- 语言解释器 5
- 生成建模 6
- 非扩散方法 6
- 扩散模型 6
- 文本引导视频生成 8
- 文本到图像 8
- 文本到视频 8
- 早期尝试 9
- 基于扩散的方法 11
- 颠覆者:Sora 12
- 文本引导视频编辑 13
- 评估指标 14
- 视觉质量 14
- 文本-视觉理解 16
- 人类感知 16
- 产品原型和潜在应用 16
- 技术限制和伦理关切 19
- 技术限制 19
- 伦理关切 22
- 讨论 23
- 人类辅助大型文本到视频生成模型 23
- 元宇宙建模 24
- 空间计算 24
- 可扩展的文本到视频生成模型作为世界模拟器? 24
- 世界模型的构想 25
- 通过AGI对世界建模 25
- 文本到视频生成模型的缺陷 26
- 文本-视频配对数据集的狭窄宇宙 26
- 生成评估中的鸿沟 26
- 文本到视频生成的未来方向 27
- 平衡数据扩展和类别选择 27
- 超越量化的评估指标 27
- 以人为中心的评估系统 28
- 人类辅助大型文本到视频生成模型 23
- 结论 28
参考文献 29
A 附录 36
引言
2024年2月15日,OpenAI推出了一款新的基础模型,可以根据用户的文本提示生成视频。这款名为Sora的模型,被人们称为ChatGPT的视频版本,主要受到营销[36, 134]、教育[14]和电影制作[127]等行业的关注,因为它促进了高质量内容创作的民主化,而这通常需要大量资源。
OpenAI声称,由于在大规模文本-视频配对数据集上进行训练,Sora具有令人印象深刻的接近真实世界的生成能力。这包括创造生动的角色、模拟流畅的动作、描绘情感以及详细提供显著对象和背景。
鉴于这些断言,我们对文本到视频生成模型如何从技术角度发展感兴趣。为此,我们对文本到视频生成模型的研究进行了全面回顾,并推断它们遵循的一定机制的一般框架。因此,该调查主要收集了IEEE Xplorer和ACM Library的会议和期刊论文,例如IEEE CVPR、ECCV、NIPS、ICML和ACM Multimedia,以及一些来自arXiv的最新研究。收集的大部分论文涵盖了近年来的研究,其中一些作品可以追溯到十年前,以简化领域背景的讨论。因此,我们使用关键词如文本到视频、生成式人工智能、视觉解释、物体检测等,采用雪球抽样技术收集了不少于140篇文章。
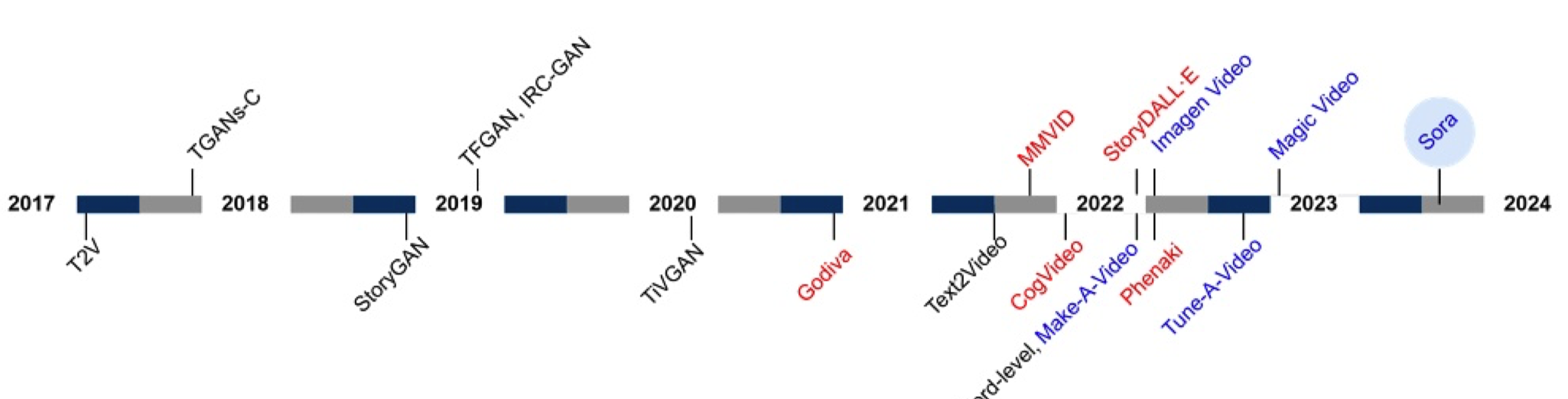
图1. 从2017年下半年到2024年上半年,文本条件视频生成模型的演变。GAN、自回归和扩散架构以颜色区分。
基于这一技术总结,我们探讨了支持对文本到视频生成研究的全面理解的各种相关方面。这使我们的工作与先前关于类似主题的调查[118, 162]有所不同,因为我们在这一生成模型的表面之外迈出了一步。此外,我们还补充了关于文本到文本[154]、文本到图像[155]、文本到3D[73]和文本到语音[157]的生成模型的现有调查工作。通过这种构想,我们希望我们的工作可以成为文本到视频生成领域新研究人员的易于理解的学习基础。此外,鉴于我们的多方面讨论,我们希望引发这些模型的潜在改进,使其对最终用户更加可靠和可信赖。我们调查文章的另一个重要目标是为任何对探索文本到视频方法感兴趣的人提供简明的教训,并进一步突出该领域的几个研究前景。我们期望我们的受众能够轻松理解这一充满活力领域内的障碍和潜力。
为了全面调查文本到视频生成模型,我们首先简要介绍其视觉建模和语言解释的核心技术,包括基本原理和骨干(§ 2)。然后,我们开始按时间顺序探索文本到视频生成模型,从它们如何源自文本到图像生成模型到最近尝试扩展视频生成模型的Sora(§ 3)。此外,我们探讨了另一个旨在使用用户的文本提示编辑视频的文本到视频任务领域(§ 4)。请注意,对于每个探索,我们提供了模型用于生成或编辑视频的一般框架概述。我们还简要介绍了文本到视频生成模型常用的评估指标(§ 5)。为了与从业者互动,我们还展示了文本到视频生成技术可能在行业中发挥重要作用的几个实际应用(§ 6)。尽管文本到视频生成模型具有独特性,但我们列出了可能阻碍潜在用户完全信任模型的限制和关切(§ 7)。最后,我们在围绕文本到视频生成模型如何引发社会思考以及未来研究如何通过改进模型性能来改善这一问题的讨论中结束我们的调查(§ 8)。
核心技术
文本到视频生成模型由两个主要组件组成,即视觉生成器和语言解释器。然而,为了生成视觉上引人注目且全面的内容,模型需要建立在强大的视觉处理器骨干架构之上。在本节中,我们简要介绍了视觉生成器架构的显著示例,以及其选择的骨干和语言解释器。
骨干架构
ConvNet. ConvNet最初于1998年在LeNet-5 [69]模型中首次构思,旨在解决参数爆炸、平移不变性和多层感知器模型的空间理解问题[2]。其背后的主要思想是通过逐渐在图像上卷积滤波器来提取视觉特征。滤波器本身的应用使ConvNet能够以更少的参数成本更深入地检查视觉信息[93]。因此,LeNet-5之后越来越多的研究转向了ConvNet,如AlexNet [67]、VGG [116]、GoogleNet [125]和ResNet [47]。尽管最初用于视觉分类任务,ConvNet也广泛用于视觉生成任务[145]。一般来说,生成模型中应用了两种类型的ConvNet架构:U形和倒U形架构。U形架构将视觉输入压缩为潜在表示,对潜在空间进行处理,然后将潜在表示扩展为视觉输出。与此同时,倒U形架构将低维输入扩展为视觉表示,对该表示进行处理,然后将处理后的视觉表示压缩为低维输出。U形架构的一个著名示例是U-Net [108],通常用于自动编码器网络。另一方面,GAN [38]是倒U形架构的一个著名示例。
ViT. 尽管 ConvNet 在计算机视觉领域取得了成功,但仍存在其架构和工作原理带来的固有局限性。ConvNet 的一些缺陷包括归纳偏差和在较低层未能学习全局特征。幸运的是,视觉变换器(ViT)[33]能够处理这些限制,因为它具有更少的线性层和自注意力机制[41]。ViT的工作原理与 NLP 变换器完全相同,前者将图像分成小块,类似于将文本分解为标记。这些块与位置嵌入连接,以锚定原始结构中每个块的空间位置。嵌入的块然后被归一化并输入到一个多头自注意力层中。在这里,自注意力机制使ViT能够同时处理所有块。自注意力还允许从一个整体视觉输入中进行上下文挖掘,因为它允许每个像素同时关注所有其他像素。此外,多层此类注意力使ViT能够让每个像素同时关注不同的较低级别视觉表示,增加了在一个单一块内学习的广度。鉴于这些特点,ViT可以作为一个可扩展且强大的特征提取器。
语言解释器
CLIP 文本嵌入. 视觉生成任务的主要原则是将文本与视觉配对。为了降低学习成本,许多视觉生成模型采用现成的图像-文本配对模型,如 CLIP [101]。CLIP 使用对比学习技术进行了预训练,该技术最小化了图像和文本嵌入之间的余弦相似度。在零样本预测期间,CLIP 将找到与图像输入嵌入具有最高内积的类别。最后,CLIP 返回一个由将类别与特定模板匹配而形成的标题。由于 CLIP 基本上是在一个检索任务上工作,它最大化了文本和图像之间的语义匹配。对于这种机制,CLIP 文本嵌入的优势在于它能够深入学习与配对图像语义最兼容的标题的语义。鉴于这种性能,视觉生成模型采用了 CLIP 文本嵌入以从其语义理解性能中受益。
LLM. 除了 CLIP,许多视觉生成模型还经常使用独立的大型语言模型(LLMs)。大多数现代 LLMs 都是从变换器模型部署的,因此有三种类型的 LLM 架构被整合到视觉生成模型中。第一种架构是仅利用变换器的编码器部分的 LLM。BERT [30]是其中一个著名的模型。BERT 架构设计得每个标记都可以关注所有前面和后面的标记。尽管 BERT 的注意力机制是双向的,但它配备了随机输入标记掩码,以允许模型进行训练。这一基本原理使得 BERT 成为一个强大的文本嵌入,并可以附加到各种下游任务。第二种架构是仅利用变换器的解码器部分的 LLM。GPT [102]是其中一个著名的模型。与 BERT 不同,GPT 中的注意力是单向的,每个标记只能关注前面的标记。因此,GPT 被训练为自回归地预测下一个标记,直到达到句子结束(EOS)标记。因此,GPT 本质上是一个生成模型。尽管使用 BERT 也可以生成文本,但结果将不如 GPT,因为 BERT 本质上是训练来解除隐藏标记掩码的。第三种架构是同时利用变换器的编码器和解码器的 LLM。T5 [103]是其中一个著名的模型。T5 几乎完全继承了原始变换器架构。T5 模型最初是为文本到文本转换而设计的,类似于机器翻译机制。尽管存在架构上的差异,所有 LLM 都具有相同的内在能力,即理解文本中的上下文。因此,雇用 LLM 和 CLIP 文本嵌入进行视觉生成任务之间的区别在于文本是否应该被编码得更深层次或更广泛的上下文。
生成建模
-
非扩散方法. 尽管当前的视觉生成领域主要由扩散模型主导,但在扩散模型被发明之前,存在几个著名的模型。这些模型包括 VAE、自回归模型和 GAN。
VAE. 如第2.1节所述,变分自动编码器(VAE)[64]具有编码和解码阶段的 U 形架构。VAE 的关键工作原理是通过估计后验分布,使用可比较的已知函数生成潜在表示,类似于从电影标题中估计流派。从技术角度来看,VAE 被训练以最小化后验分布与可比较已知函数之间的 KL 散度,通过优化证据下界(ELBO)项。
自回归模型. 顾名思义,自回归模型通过逐像素生成图像[25]。PixelCNN [131]是视觉领域中的一个例子。该模型的关键原则是所有生成的像素都是每次生成的条件分布的联合分布的元素。与 NLP 领域的姊妹模型一样,自回归模型可以生成质量令人印象深刻的视觉输出,但代价是推理时间。VAE 和自回归模型都具有一个相似的特点,即都试图使用特定参数来近似样本的密度函数。
GAN. 为了缓解 VAE 和自回归模型中的分布约束,开发了 GAN,其主要目标是简单地生成良好的合成样本,而不受基础真实分布的限制。GAN 具有倒 U 形架构,包括生成和鉴别阶段。GAN 的关键原则是从随机分布中对随机噪声进行采样,并用其生成视觉输出。GAN 在生成器和鉴别器之间遵循博弈论,生成器试图用一个假样本愚弄鉴别器。同时,鉴别器的任务是区分真实和假样本。尽管直观上,生成器和鉴别器有相互冲突的目标,但在实践中,生成器被训练以最大化鉴别器在其鉴别任务中出错的可能性,使两者都参与了一个最大-最大博弈。由于 GAN 的性质是无需分布(减少了需要在两个分布之间找到中间点的必要性),该模型可以生成比自回归模型更生动的视觉输出。然而,GAN 尚未完全克服其模式崩溃问题,即生成器只能生成有限多样性的新样本,这是由于 GAN 训练中的不稳定性导致的。此外,由于 GAN 不依赖于任何形式的分布来估计基础真实分布,衡量生成质量是一个非平凡的任务。尽管这些模型存在局限性,但它们在视觉生成任务中的表现相对快速,因为它们只需要一次采样过程来生成视觉输出。
-
扩散模型. 扩散模型,也被称为去噪扩散概率模型(DDPM)[51],旨在解决 GAN 中的模式崩溃和 VAE 生成质量低的问题。从架构上看,扩散模型可以被视为多步 VAE,因为它与 VAE 具有相似的架构,但需要更多的采样过程来执行生成。理论上,扩散与 GAN 类似,因为它不试图近似基础真实数据分布。
DDPM 和 DDIM. 扩散模型背后的直觉相当简单。如果一个模型可以将微小的噪声 𝛽𝑡 逐步添加到视觉输入 x0 直到它变成完全的噪声 xT(正向过程),那么反向过程也是可能的(逆向过程)。正向过程的结果噪声需要具有高斯分布 N(0, I ),因为它使得逆向过程能够生成任何类型的视觉输出。请注意,这两个过程都是马尔可夫的。因此,当前生成结果仅取决于直接前一代的生成,就像自回归模型一样。在正向过程中,因为模型只需要生成高斯噪声,所以仅仅添加小的高斯噪声就足够了,而无需任何可学习的参数。因此,正向过程的输出可以是所有先前正向过程的累积分布。这最终意味着正向过程可以通过单一步骤完成,直接从输入图像中创建噪声。
在这里, α t = 1 − β t \alpha_t=1-\beta_t αt=1−βt, α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t=\prod_{i=1}^t \alpha_i αˉt=∏i=1tαi。然而,在反向过程中无法应用相同的原理,因为所需视觉输出的真实分布是未知的。因此,反向过程只能用可学习参数来近似输出分布。
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)=\mathcal{N}\left(\mathbf{x}_{t-1} ; \mu_\theta\left(\mathbf{x}_t, t\right), \Sigma_\theta\left(\mathbf{x}_t, t\right)\right) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
尽管这种近似听起来类似于 VAE 中所做的工作,但在真实数据分布方面两者有所不同。VAE 中目标数据的分布是完全未知的,而在扩散模型的反向过程中,目标数据 p θ ( x t − 1 ∣ x t ) p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right) pθ(xt−1∣xt) 可以被建模为高斯分布,因为在正向过程中,由于每一步添加的噪声微不足道,噪声添加函数 q ( x t − 1 ∣ x t ) q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right) q(xt−1∣xt) 是高斯的。因此,与 VAE 中所做的最小化后验分布和高斯函数之间的 KL 散度不同,反向过程的目标函数只需要最小化两个高斯分布之间的 KL 散度,使其更简单和更稳定地训练。
D K L ( p ∥ q ) = β t 2 2 σ t 2 α t ( 1 − α ˉ t ) ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 D_{K L}(p \| q)=\frac{\beta_t^2}{2 \sigma_t^2 \alpha_t\left(1-\bar{\alpha}_t\right)}\left\|\boldsymbol{\epsilon}_t-\boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}_t, t\right)\right\|^2 DKL(p∥q)=2σt2αt(1−αˉt)βt2 ϵt−ϵθ(αˉtx0+1−αˉtϵt,t) 2
进一步简化为以下损失函数。
L t simple = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] L_t^{\text {simple }}=\mathbb{E}_{t \sim[1, T], \mathbf{x}_0, \boldsymbol{\epsilon}_t}\left[\left\|\boldsymbol{\epsilon}_t-\boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}_t, t\right)\right\|^2\right] Ltsimple =Et∼[1,T],x0,ϵt[ ϵt−ϵθ(αˉtx0+1−αˉtϵt,t) 2]
然而,扩散模型也存在局限性,特别是在生成过程缓慢,因为模型在训练过程中需要多次采样步骤。幸运的是,去噪扩散隐式模型(DDIM)[119] 解决了这一缺点,试图通过允许确定性和跳跃采样来推广 DDPM,使用非马尔可夫假设。
无分类器引导。 普通的 DDPM 或 DDIM 无法灵活控制视觉输出的类型。因此,这些普通模型可以与引导相结合,仅针对某一类来引导采样过程。最早的方法是简单地将模型 ϵ θ ( x t , t ) \epsilon_\theta\left(\mathbf{x}_t, t\right) ϵθ(xt,t) 与一个预训练的分类器 ϵ θ ( x t , t , y ) \epsilon_\theta\left(\mathbf{x}_t, t, y\right) ϵθ(xt,t,y) 耦合,该分类器涵盖大量类别[31]。使用这个分类器,类别引导是通过分类器的梯度来近似的。最终,由于这种近似,可以在没有预训练分类器的情况下获得引导,因为引导将与反向过程的神经网络一起训练[52]。此外,大约 10 % 10\% 10% 的训练时间将用于使用空类进行训练 ϵ θ ( x t , t ) = ϵ θ ( x t , t , y = ∅ ) \epsilon_\theta\left(\mathbf{x}_t, t\right)=\epsilon_\theta\left(\mathbf{x}_t, t, y=\varnothing\right) ϵθ(xt,t)=ϵθ(xt,t,y=∅)。
潜在 DDPM。 为了处理高分辨率的视觉输入,直接将其输入 DDPM 将在反向过程中产生可克服的时间成本。因此,今天视觉生成模型中最流行的选择是提前将图像缩小为更小的潜在表示,使用自动编码器。然后,DDPM 只需要处理更小尺寸的潜在表示。这种技术被称为潜在 DDPM [107]。
文本引导视频生成
视频生成模型源自图像生成模型,因为视频本质上是遵循某种时间一致性规则的图像序列。在本节中,首先我们简要介绍了文本到图像生成模型如何演变为文本到视频生成模型。我们进一步讨论了每种特定架构模型的基本框架,如基于 GAN、基于自回归和基于扩散的模型。
文本到图像
从简单的文本到图像生成技术到能够从文本描述中产生复杂逼真图像的最新模型的创造之旅是令人着迷的。最初,文本到图像的创建依赖于基于规则的方法,将文本提示与预定义数据库中的视觉元素相匹配[106]。这进一步发展为更复杂的特征提取和匹配方法,利用语义映射和基本神经网络[158]。接着,GAN 的引入,特别是条件 GAN(cGAN)[87],显著提高了图像的逼真度,因为它帮助模型专注于特定的文本元素,以生成更相关的图像。随着在 AttnGAN [146] 中看到的注意力机制的引入,GAN 在文本到图像生成性能上的提升进一步增强。不久之后,这些生成模型采用 ViT,以从其令人印象深刻的视觉生成质量和可扩展性中受益。OpenAI 的 DALL·E [104] 是其中一个广为人知的例子。然而,大多数今天的文本到图像生成模型(DALL·E 2、DALL·E 3 和 Imagen)利用扩散模型,因为其在创建视觉详细和逼真输出方面的性能胜过 GAN [31]。这一进展突显了人工智能研究的快速进步及其在生成引人入胜的输出方面的应用,每一步都标志着图像生成技术的技术复杂性和对口头描述的微妙解释的显著飞跃。
文本到视频
文本到视频生成是条件视频生成的一个子集,它扩展了文本到图像生成的能力[120]。这种生成的主要概念是直接从书面描述中生成动态且具有丰富背景的视频。最初,这个领域依赖于简单的方法,比如将静态图像和基于单词的动画串联起来,其中算法将文本与预先存在的视频剪辑或序列配对[105]。然而,这些早期尝试往往导致有限且有时不连贯的输出。更先进的机器学习和深度学习技术的引入带来了重大进步。
在过去的七年里,文本到视频生成模型主要由 GAN、自回归和扩散模型主导。我们在附录中编制了十六个代表性的文本到视频模型,见表 A1。这些模型的演变如图 1 所示。从 2017 年底到 2022 年第三季度,基于 GAN 的模型很受欢迎。许多这些模型还集成了循环模型,如 RNN 和 LSTM [53],以有效处理时间动态。尽管基于 GAN 的模型很受欢迎,但研究界开始将注意力转向在生成模型中使用自回归架构。这种改变的原因是由于 GAN 在生成具有清晰图像质量的视频帧方面存在局限性 [46, 140]。此外,发现一些模型在帧间生成单调的视觉内容 [140]。因此,自回归模型于 2021 年上半年进入视频生成社区,并存在了大约一年半的时间。尽管具有强大的时间一致性,自回归模型仍然不足以生成高质量的视频帧。除了其无法生成生动的视觉内容外,其衰退的部分原因是其在全面将文本指令转化为视频帧方面的局限性 [54]。到 2022 年下半年,研究人员还开始探索将扩散模型作为文本到视频生成模型的主要架构的利用。
扩散模型现在负责从文本描述中生成动态和具有上下文准确性的视频内容。结合使用大规模数据集进行学习,它们生成的视频不仅视觉上令人惊叹,而且在整个叙事中保持了连贯性。文本到视频生成模型的每一次进步都显著加深了我们对文本叙述与视觉叙事之间错综复杂关系的理解,突显了人工智能能力从文本中打造引人入胜视频叙事的快速演进。
早期尝试
基于规则的模型。 从计算机视觉、自然语言处理和生成模型中整合技术的初期努力。早期模型主要使用基于模板和基于规则的系统,通过将书面描述与现有图像或视频库中的视觉元素相关联,根据预定义规则进行组装来创建视频内容。这种方法对于结构化和特定领域的应用(如体育总结和天气预报)是有效的。然而,它缺乏生成新颖内容的灵活性。此外,还有一种依赖检索系统的模型。这种模型搜索与文本描述相匹配的数据库中的视频片段。然而,与基于模板和基于规则的模型类似,这种模型的局限性仍在于无法生成新颖内容,因为它严重依赖数据库的镜头和元数据准确性 [144]。
基于 GAN 的模型。 GAN [38] 已经在无引导视频生成任务中得到应用。以产生逼真图像而闻名的 GAN 与语言模型结合,将用户指令以文本提示的形式纳入其中。这种文本-视觉协作标志着更复杂的文本到视频生成技术的重要一步。
图 2. 基于 GAN 的文本到视频生成模型框架。
图2展示了将 GAN 作为生成器的文本到视频生成模型的一般框架。首先,文本指令被输入到带有两个目标的循环单元 RNN 中,这两个目标分别是将文本编码为潜在向量 Z,以及在帧之间创建这些向量的有意义序列。潜在向量进入生成器 G 以生成图像。为了确保这个图像与文本指令匹配,生成器的输出被发送到鉴别器 Df,用于区分这个输出和训练数据集中的真实图像。一些模型,如 TiVGAN [62],会用另一帧的图像替换特定帧的真实图像,以迫使鉴别器认可视觉输出的时间传播信号。此外,基于 GAN 的视频生成模型还使用额外的鉴别器 Dv,其任务是区分生成的帧序列和真实的帧序列。这个鉴别器的输入是生成器生成的带有正确帧顺序的连接图像。此外,每次生成新图像(除第一帧外)时都会执行这种区分。其他整合了两个鉴别器的模型包括 TFGAN [10]、StoryGAN [74]、TGANs-C [94] 和 IRC-GAN [29]。除了多鉴别器,还可以通过轻微修改使用单个鉴别器生成视频,方法是插入一个融合特征,将文本特征与图像特征混合,而不仅仅是简单地将它们连接在一起 [72]。另一个可行的选择是在生成潜在表示时解耦背景和显著对象的语义。在这里,显著对象的表示通过基于文本指令的生成运动滤波权重得到进一步增强 [75]。
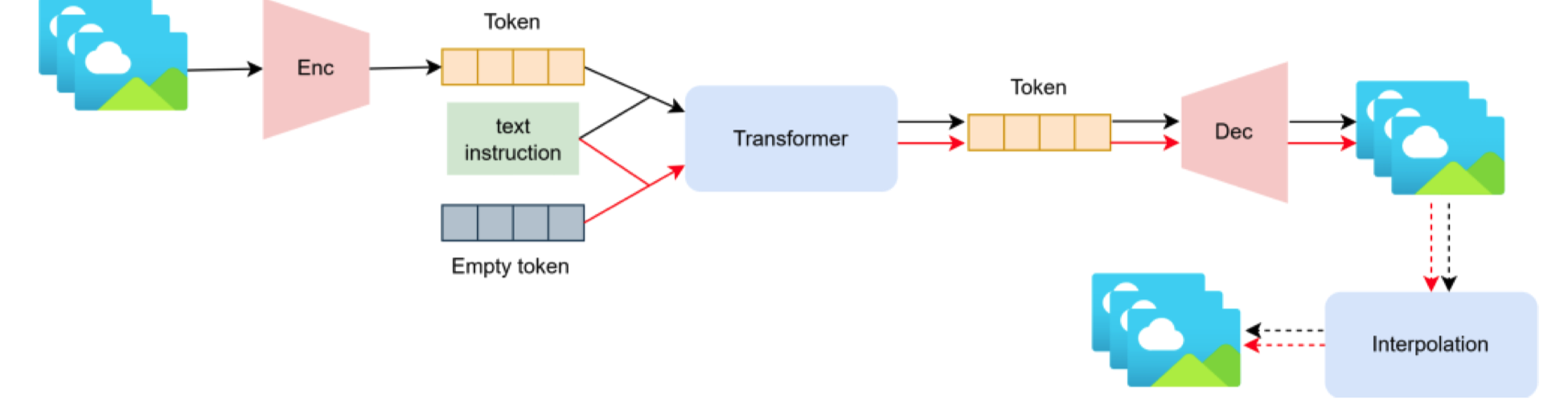
图3. 基于自回归的文本到视频生成模型框架。黑色箭头表示训练流程,红色箭头表示推断流程。
基于自回归的模型。 自回归模型是早期尝试从文本提示生成视频的另一种常用模型。Phenaki [133]、CogVideo [54]、GODIVA [140] 和 StoryDALL-E [81] 是一些基于自回归的视频生成模型的例子。图3展示了这种生成方式的一般框架。首先,视频帧被编码为图像标记的序列。然后,这些标记连同文本标记一起输入到 transformer 块中,产生新生成的帧。在推断过程中,输入到这个 transformer 的图像标记会被替换为空图像标记或软标记。来自 transformer 块的输出标记然后被解码为 RGB 视频帧,可以进行插值以获得更精细的帧速率。不同的模型会在这个框架的不同部分进行调整以生成视频。可以在视频帧编码为图像标记序列的过程中进行修改,通过整合因果 transformer 来确保帧之间的时间连贯性(由 Phenaki 实现)。另一个选择是集成帧速率信息并实现分层生成,就像 CogVideo 所做的那样。此外,屏蔽帧标记也可以是一种强制生成 transformer 学习帧之间的时间序列信息的替代方法 [46, 133]。生成 transformer 可以以任何方式设计,例如在现有空间注意力之上加入时间注意力(由 GODIVA 实现)。
这些早期的努力,虽然受到技术和对文本-视频相互作用理解的限制,为像扩散模型这样的更先进方法的发展奠定了基础。
基于扩散的方法
最近文本到视频生成的进展是基于扩散模型的。OpenAI 的 DALL·E 为视频进行了适应,Google 的 Imagen Video [50] 是引领将文本转视频引入公众的模型。
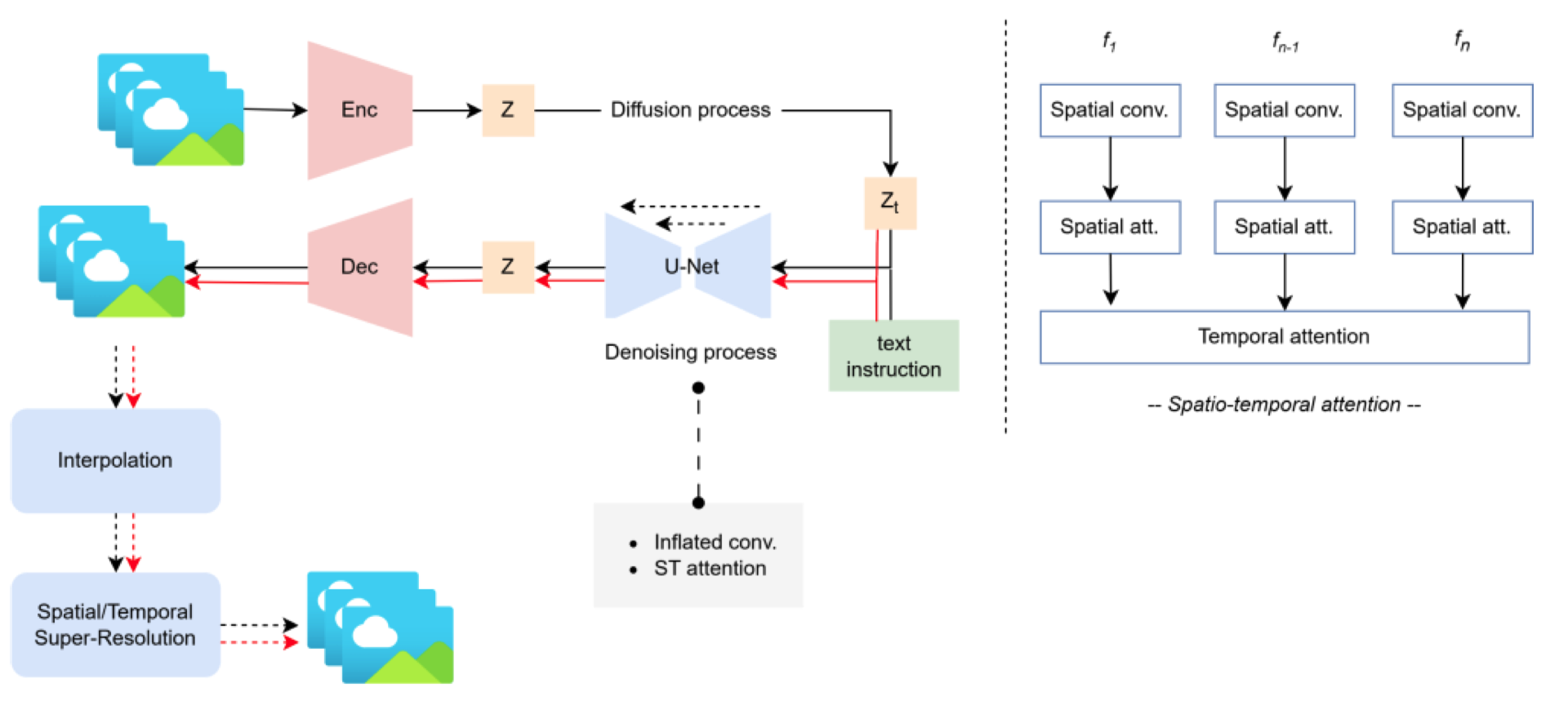
图4. 基于扩散的文本到视频生成模型框架。黑色箭头表示训练流程,红色箭头表示推断流程。右侧的图示了时空 aNention。
总体上,使用扩散模型从文本提示生成视频类似于该模型用于图像生成的方式。图4展示了从文本提示生成视频的扩散模型的一般框架。首先,视频帧被编码为潜在表示,生成过程在其中进行。在训练过程中,通过扩散(或正向)过程向潜在表示添加噪音。带有文本嵌入的噪音潜在表示被发送到执行去噪(或反向)过程的生成器。通常使用的生成器是带有跳跃连接的 U-Net,以保留从编码的潜在表示到解码的空间信息。这个 U-Net 架构是进行修改以适应视频的时间维度的地方。
尽管不同的模型实现了不同的修改,但它们通常可以分为两类,即插入时空注意力和将二维卷积层膨胀为三维。时空注意力的主要思想是独立地在每帧上执行空间操作,并在帧之间混合时间操作 [50]。此外,时间操作的执行方式也可以进行修改,例如实现定向时间注意力 [161] 或稀疏注意力 [141]。与此同时,卷积层膨胀的原则来自可分离卷积的概念 [22]。为了将二维卷积层膨胀为三维,可以用 1x3x3 的核替换 3x3 的核。此外,transformer 块需要整合额外的时间注意力以适应维度扩展。集成这种卷积膨胀的作品的例子包括 Tune-A-Video [141] 和 Make-A-Video [117]。从 U-Net 开始,生成的潜在表示被解码为 RGB 视频帧。为了在不增加生成过程的计算成本的情况下构建高帧速率和高分辨率视频,一些模型在解码过程后附加插值和空间或时间超分辨率模块 [50, 117, 161]。
改变游戏规则:Sora
我们在第3.4节讨论了几个采用扩散模型架构的文本到视频生成模型的例子。然而,大多数这些模型都使用了带有卷积层的 U-Net 骨干的潜在 DDPM。从这一发展进一步的一步是用 transformer 骨干替换基于 ConvNet 的 DDPM,以使视频生成模型更具可扩展性。这正是 Sora [96] 实现的,Sora 是 OpenAI 大视觉模型(LVMs)中视频生成模型的新成员。Sora 的核心视觉处理能力建立在扩散 transformer(DiT)[97] 的基础上。扩散 transformer 继承了与 ViT 类似的结构,稍作修改,通过将标准层归一化替换为自适应层归一化以整合条件项。其余的工作原理继承了 ViT,其中视觉输入被分块并线性投影,然后被馈送到 transformer 编码器。
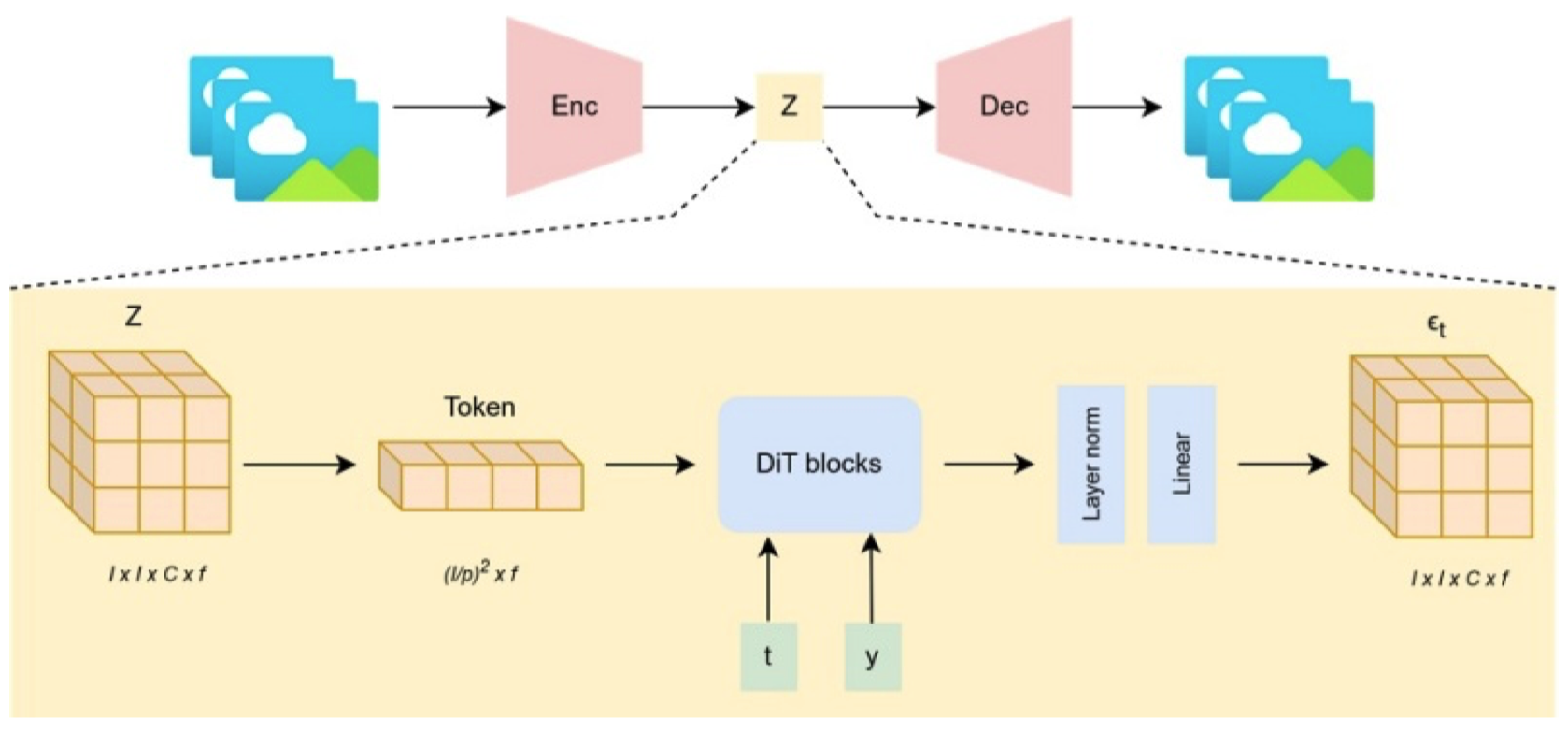
图5. Sora 模型架构示意图(近似)。
特别是对于视频生成,机制如图5所示。请注意,由于 OpenAI 没有披露 Sora 的模型架构,我们根据技术报告描述进行了近似。首先,由大小为 H x W x C 的图像序列组成的视频被编码为潜在表示 Z,将高分辨率输入压缩为低分辨率特征以节省生成过程的计算成本。具有 I x I x C 形状的 Z 被分解为每个形状为 p x p 的补丁。补丁被线性投影为长度为 (I /p)^2 x f 的向量。带有噪音的线性向量然后与其他条件一起输入到 DiT 中,例如步长 t 和文本嵌入 y。扩散过程产生一个新的潜在表示 𝜖t,其形状与 Z 相同。生成的潜在表示然后通过解码器上采样以生成视频输出。Sora 强大的视觉处理器与出色的文本生成模型 GPT-4 结合在一起。此外,Sora 遵循 DALL·E-3 [12] 中使用的重新标题策略,自动将简单用户标题转换为高度描述性的文本,以进行 DiT 编码。利用生成式语言模型使 Sora 能够更好地理解用户指令的上下文,从而使其能够创建具有令人印象深刻的文本-视觉一致性的视频。
文本引导的视频编辑
将文本和视觉模态连接起来已经实现了许多超越视觉描述或生成的进展。视觉编辑是其中一个领域,这种发展是针对这一领域的。在这里,用户可以同时输入文本和视觉输入,与模型进行交互以产生所需的视觉输出,而不是只输入文本或视觉。已经有许多研究探索了图像领域的视觉编辑,比如图像修补和图像风格转移。如今,许多视觉编辑技术通常利用直观的用户输入。在这些技术中,最常见的方法是利用分割掩模,使用像 SAM 这样的大型零样本模型 [65, 149, 150, 153]。然而,在这里,我们特别选择只利用文本作为控制输入的视频编辑模型。尽管仅使用文本进行视频领域的视觉编辑研究仍在增长,但有一些值得作为未来研究参考的技术。简言之,研究人员通常使用两种框架来执行文本到视频编辑任务。一种是整合分层神经地图的方法,另一种是同时采用 DDIM 反演和注意力注入的方法。
与分层神经地图集成。 分层神经地图(LNA)[59] 首次在 2021 年提出,旨在解决视频编辑任务中的时间不一致性问题。该技术背后的直觉是将输入视频解耦为一组分层的 2D 地图集,包括显著对象地图和背景地图,以及不透明度映射。这组 2D 地图是进行所有编辑过程的地方。利用这组地图,文本到视频编辑的框架如图 6 所示。
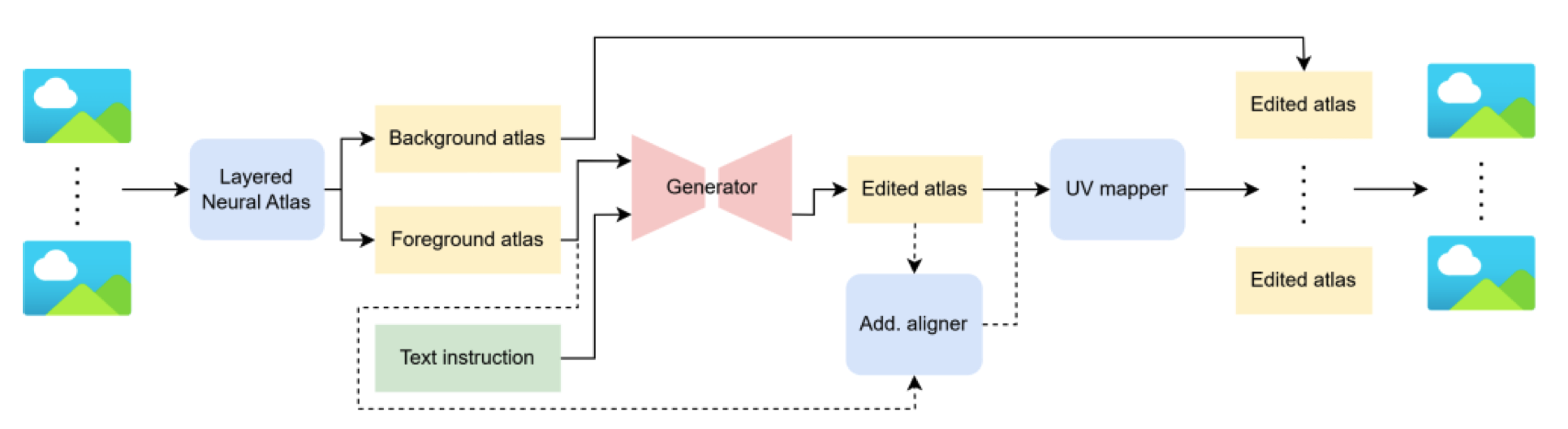
图 6. 带有分层神经地图集成的文本到视频编辑框架。
首先,视频输入的帧进入 LNA 模型,生成地图集。包含要编辑的显著对象的前景地图与文本嵌入一起输入到视频生成模型中。视频生成模型生成的编辑后的地图进入 UV 映射器,将地图与背景地图结合并渲染回帧。一些模型还集成了额外的对齐模块,将编辑后的地图锚定到原始前景地图。LNA 集成框架广泛应用于现有的视频编辑作品,如 Text2Live [11]、Text-driven video stylization [80]、StableVideo [19] 和 Shape-aware video editing [71]。LNA 在视频编辑任务中经常被选用,因为它具有语义可解释性,并且可以自动映射回原始帧。
与 DDIM 反演和注意力注入集成。 编辑视频的第二种流行方法是在帧级别上使用 DDIM 反演和注意力注入。这一框架的高层理解是将视频帧转换回其嘈杂的潜在空间,然后执行编辑过程。整体编辑过程如图 7 所示。
输入帧通过 DDIM 反演转换为相应的嘈杂潜在表示。噪声与文本指令一起输入到视频生成器中,生成编辑后的潜在表示。在这里,从前一帧向生成器注入交叉注意力是必要的,这样可以捕捉跨帧的语义交互。此外,除了特征注入,后续帧的编辑后潜在表示还会更新为当前帧的编辑后潜在表示。一些视频编辑模型还设计了特征注入和潜在表示更新,使其发生在原始视频和编辑视频之间,而不是同一视频的帧间。Pix2Video [18]、FateZero [100]、InFusion [61] 和 Zero-shot video editing [136] 模型是遵循这一框架的模型,同时集成了 DDIM 反演和注意力注入。与 LNA 集成的视频编辑框架相比,这一框架在处理新形状或 3D 结构方面性能更好,并且消除了昂贵的神经地图优化的需求。
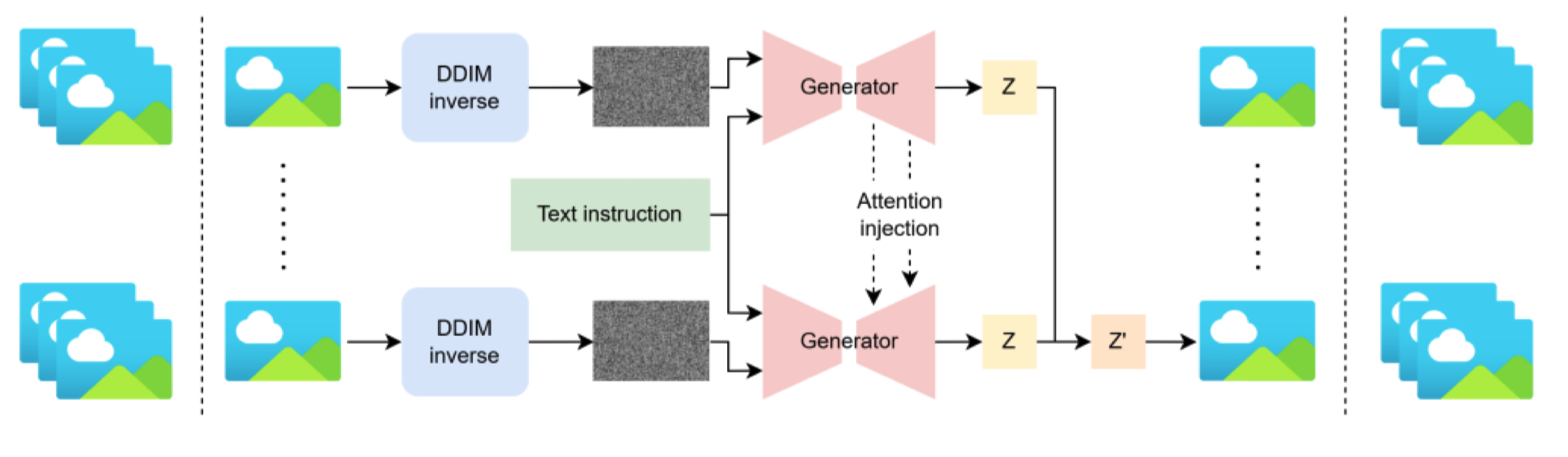
图 7. 带有 DDIM 反演和注意力注入集成的文本条件视频编辑框架。
评估指标
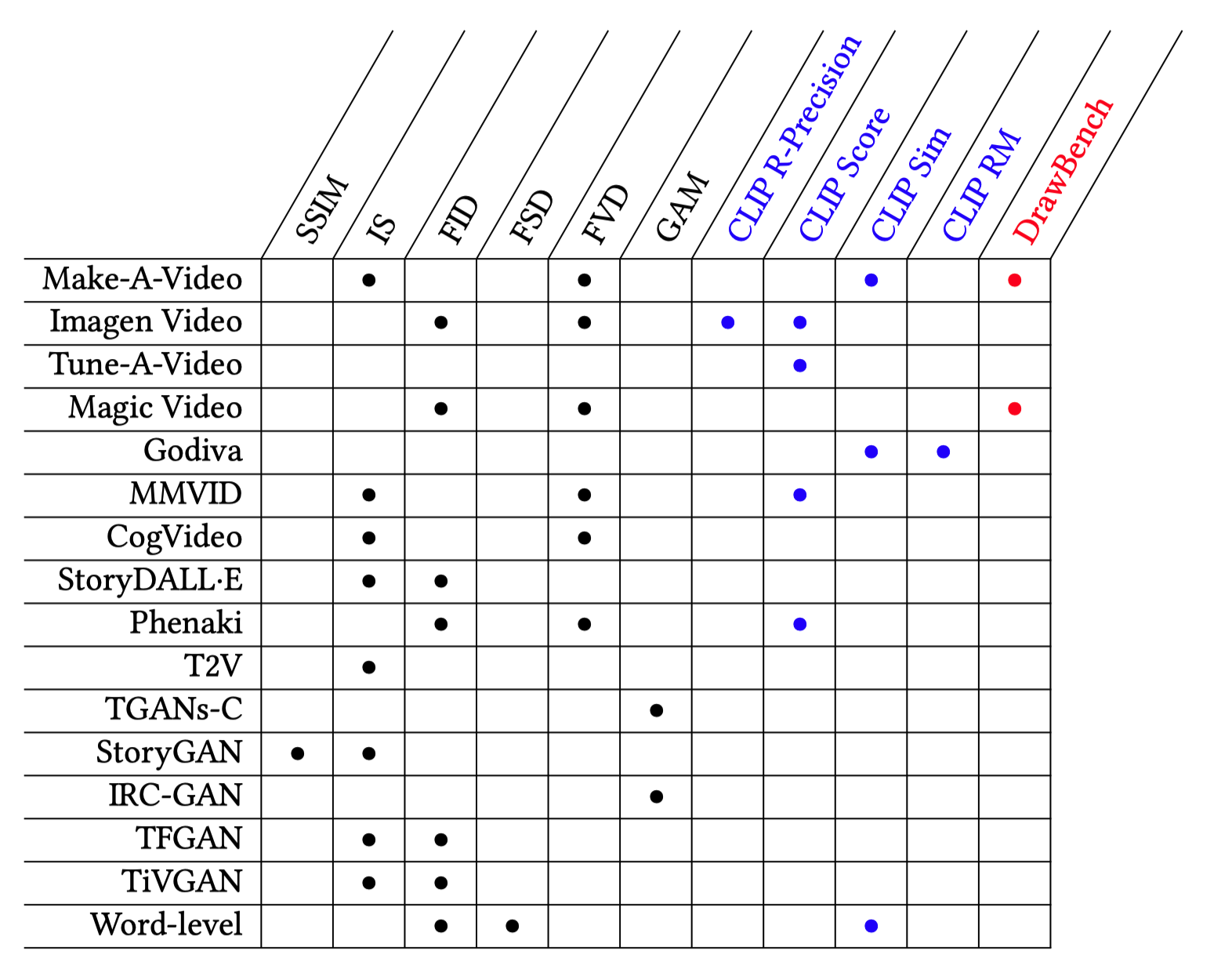
文本到视频生成模型采用评估指标来衡量其生成性能。由于这些模型涉及双模态,即文本和视觉,评估指标应该平等地评判这两种模态。实际上,这意味着需要同时衡量视觉质量和文本-视觉一致性。此外,由于视频由相互关联的图像组成,还需要一个可以探究时间维度的指标。然而,除了这些机器评估系统外,用户通常根据人类感知来评判模型输出。表 1 总结了每个代表性模型使用的评估指标。
视觉质量
结构相似性指数。 SSIM [139] 首次于 2004 年提出,其主要目标是开发一种自动视觉评估指标,了解人眼的视觉感知特征。SSIM 的基本思想是比较经过局部亮度和对比度值归一化后的像素强度的局部模式。这种归一化是为了揭示图像中物体的真实纹理。基于这一理解,SSIM 通过比较两幅图像的亮度、对比度和结构三个方面来计算它们之间的相似性。
Inception 分数。 IS [110] 分数被提出作为自动评估指标,以消除人工评估的低效性和固有偏见。评估简单地通过将所有生成的图像馈送到 Inception 网络 [125] 中,以获得条件标签分布。Inception 分数通过计算两者之间的 KL 散度来衡量生成标签分布与真实标签分布之间的差异。虽然 IS 最初是用于评估图像生成的,但也可以用于视频生成。视频的 IS 可通过取所有帧的 IS 的平均值来获得。
表 1. 视觉质量、文本-视觉一致性和人类感知评估指标(颜色编码)。
Fréchet Inception 距离。 FID [49] 提出解决 IS 偏向于使用合成样本统计而不是真实样本的限制。通过使用 Fréchet 距离来衡量地面真实样本和生成样本分布之间的差异,该距离假定这两个分布都是高斯分布。
d 2 ( ( m , C ) , ( m w , C w ) ) = ∥ m − m w ∥ 2 2 + Tr ( C + C w − 2 ( C C w ) 1 / 2 ) d^2\left((\boldsymbol{m}, \boldsymbol{C}),\left(\boldsymbol{m}_w, \boldsymbol{C}_w\right)\right)=\left\|\boldsymbol{m}-\boldsymbol{m}_w\right\|_2^2+\operatorname{Tr}\left(\boldsymbol{C}+\boldsymbol{C}_w-2\left(\boldsymbol{C} \boldsymbol{C}_w\right)^{1 / 2}\right) d2((m,C),(mw,Cw))=∥m−mw∥22+Tr(C+Cw−2(CCw)1/2)
其中 ( m , C ) (\boldsymbol{m}, \boldsymbol{C}) (m,C) 和 ( m w , C w ) \left(\boldsymbol{m}_w, \boldsymbol{C}_w\right) (mw,Cw) 分别是来自生成和地面真实数据分布的高斯均值。这两个样本的分布是从在 ImageNet [28] 数据上预训练的 Inception-v3 [126] 网络的最后池化层的输出中获得的。与 IS 类似,视频的 FID 可通过取所有帧的 FID 的平均值来获得。
Fréchet Video 距离。 FVD [130] 是 FID 的扩展,不仅考虑视觉质量,还考虑了时间一致性和样本多样性。尽管思想与 FID 几乎相似,但 FVD 从膨胀的 3D Inception-v1 网络的最终层中获取地面真实和生成数据分布的特征表示。3D Inception 网络的基础架构在 ImageNet 上进行了预训练,而模型本身则在 Kinetics [60] 数据集上进行了训练。通过最大均值差异(MMD)[40] 方法估计地面真实 p ( X ) p(X) p(X) 和生成 q ( Y ) q(Y) q(Y) 分布之间的距离,以减轻尝试近似高斯分布可能产生的大误差。
M M D 2 ( q , p ) = ∑ i ≠ j m k ( x i , x j ) m ( m − 1 ) − 2 ∑ i = 1 m ∑ j = 1 n k ( x i , y j ) m n + ∑ i ≠ j n k ( y i , y j ) n ( n − 1 ) M M D^2(q, p)=\sum_{i \neq j}^m \frac{k\left(x_i, x_j\right)}{m(m-1)}-2 \sum_{i=1}^m \sum_{j=1}^n \frac{k\left(x_i, y_j\right)}{m n}+\sum_{i \neq j}^n \frac{k\left(y_i, y_j\right)}{n(n-1)} MMD2(q,p)=i=j∑mm(m−1)k(xi,xj)−2i=1∑mj=1∑nmnk(xi,yj)+i=j∑nn(n−1)k(yi,yj)
其中 x 1 … x m x_1 \ldots x_m x1…xm 和 y 1 … y n y_1 \ldots y_n y1…yn 是从 X \mathrm{X} X 和 Y \mathrm{Y} Y 中抽取的样本, k ( ⋅ , ⋅ ) k(\cdot, \cdot) k(⋅,⋅) 是核函数。
Fréchet Story 距离。 FSD [121] 是 FID 的扩展,旨在衡量故事序列的一致性。这个指标被认为是 FID 和 FVD 之间的中间值。这是因为故事一致性和帧一致性在几个方面不同,包括决定每个指标可以处理的图像数量的时间平滑度。例如,FVD 每次评估至少需要七幅图像,而大多数文本到故事模型只生成五个故事。因此,FSD 稍微修改了 FVD 中的 3D Inception 网络,使其成为 R(2+1)D [129]。实际上,网络架构变为带有 2D 空间卷积和 1D 时间卷积的 ResNet。
生成对抗度量。 GAM [55] 是专门提出来比较两个基于 GAN 的模型的生成结果。其主要思想是让两个 GAN 模型参与一场涉及两个模型之间生成器-判别器对交换的战斗。
Text-Vision Comprehension
CLIP R-Precision. R-精度计算了从查询图像中获取匹配标题的前 R 个检索准确性。根据这一定义,CLIP R-精度 [95] 是通过向 CLIP 模型查询生成的图像并自动检查检索到的标题与真实标题的匹配程度来获得的。这个度量是衡量文本和图像模态之间相似性的最早尝试之一。
CLIP 分数. CLIP 分数 [48] 通过借鉴 CLIP 模型理解图像和文本之间关联的能力来评估标题-图像相似性。使用这个度量获得相似性分数的想法相当简单。生成的图像和文本标题分别通过 CLIP 图像嵌入和 CLIP 文本嵌入。通过评估两个嵌入之间的余弦相似性来计算分数。视频的 CLIP 分数通过取所有帧的平均值 (CLIP SIM) [140] 或最大值 [46] 来衡量。为了减小 CLIP 模型的影响并使评估度量更加领域无关,生成视频的 CLIP 分数可以通过真实视频的 CLIP 分数进行归一化 (CLIP RM) [140]。
人类感知
DrawBench. DrawBench 是与谷歌的 Imagen [109] 模型一起提出的,后者成为了一个多维文本到图像生成基准。这样一个基准背后的动机是克服 COCO [77] 的有限视觉推理能力和社会偏见,就像另一个评估基准 PaintSkills [21] 的设计一样。DrawBench 中有十一个评估类别,包括颜色、计数、空间定位、冲突互动、长描述、拼写错误、罕见词汇、引用词汇以及来自 DALL·E、Reddit 和 DALL·E-2 初步评估 [82] 的复杂提示,总共编制了 200 个提示。然而,还有另一个主要被我们审查的模型广泛使用的人工人类评估度量。这个度量包含如表 2 所示的组件。
产品原型和潜在应用
随着文本到视频生成研究的进展,许多企业家利用这项技术开发了解决现实问题的人工智能产品 [114]。视频内容生成是利用文本到视频生成模型的重要应用之一。将任何文本转换为视频内容的想法有助于提高生产效率,因为它可以降低内容创作的成本,特别是视频内容,通常需要大量时间。一般来说,根据目标市场,市场上推广的文本到视频生成产品分为两类,面向专业人士和艺术家。
表 2. 人类评估方面。
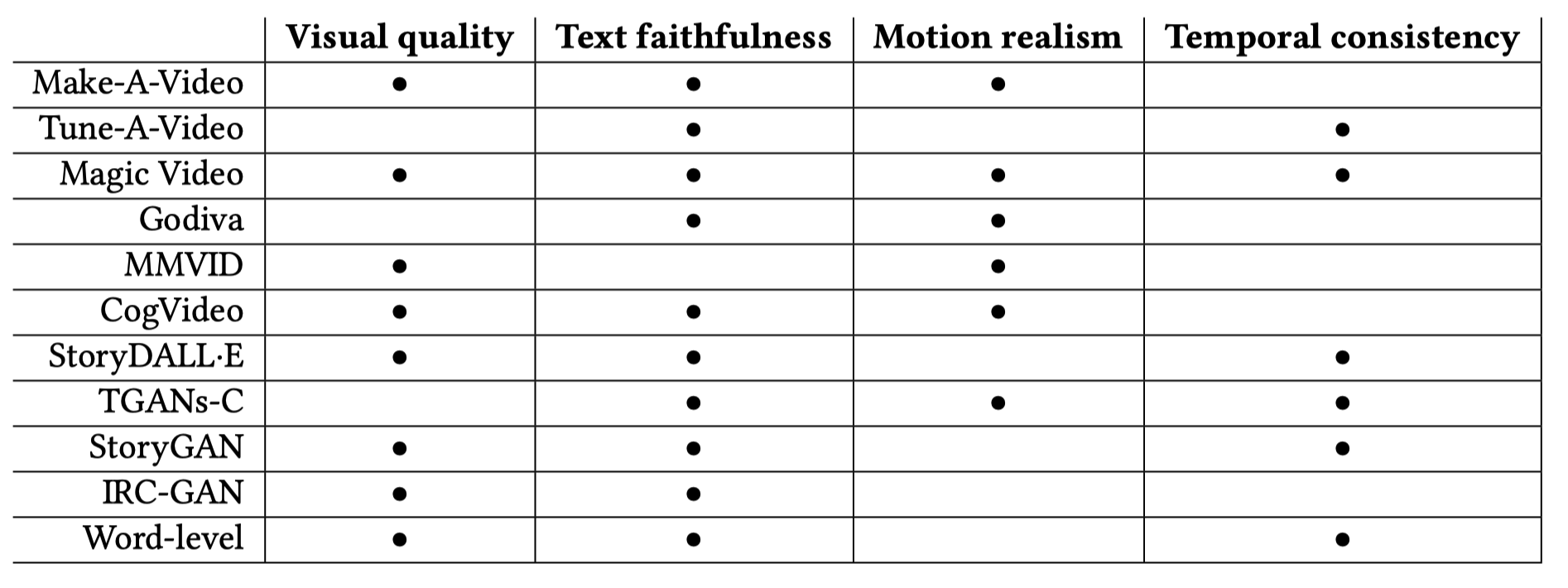
面向专业人士的产品. 针对专业行业的文本条件视频生成应用主要提供员工招聘和培训、商业演示、新闻广播、产品商业广告和营销 [99] 以及社交媒体内容的视频生成。DeepBrain AI2、Veed IO3、Lumen54、Synthesia5、InVideo AI6、GliaCloud7、Synthesys8、Pictory9 和 Fliki10 是视频生成应用的一些例子。使用这些应用,用户可以将他们的文本或 ChatGPT 生成的文本输入到视频生成器中。此外,用户可以简单地上传 .pdf 或 .ppt 文件,甚至可以直接提供托管所需转换为视频的文章的 URL。其中一些应用的另一个高级功能是用户可以生成能够模拟输入文本生成的脚本的真实人类化身。这些化身还可以使用全球 50 多种语言进行讲话。然而,许多视频生成应用只提供现成的化身,不能公平地代表世界上所有的种族。用户可以创建自定义化身,但通常需要额外费用。然而,许多大型企业已经在他们的业务中使用了这些多功能产品。例如,DeepBrain AI 产品已被用于创建 MBN 新闻广播 [4]、仁荷大学 AI 教授 [6] 和尹锡烈总统的 AI 总统竞选 [5]。此外,Synthesia 的产品也已集成到许多应用中,如 Antisel 的员工入职流程 [124]。
面向艺术家的产品. 除了商业专业人士,文本到视频生成应用也面向艺术家或其他创意产业的专业人士。这个行业的用户通常需要用于动画或电影制作的视频生成器。与面向商业专业人士的视频生成器类似,用户可以在这里输入文本提示以生成创意视频。此外,用户可以输入他们的图像、绘画或音乐,以帮助视频生成结果更具艺术感。针对创意产业的应用旨在执行艺术任务。
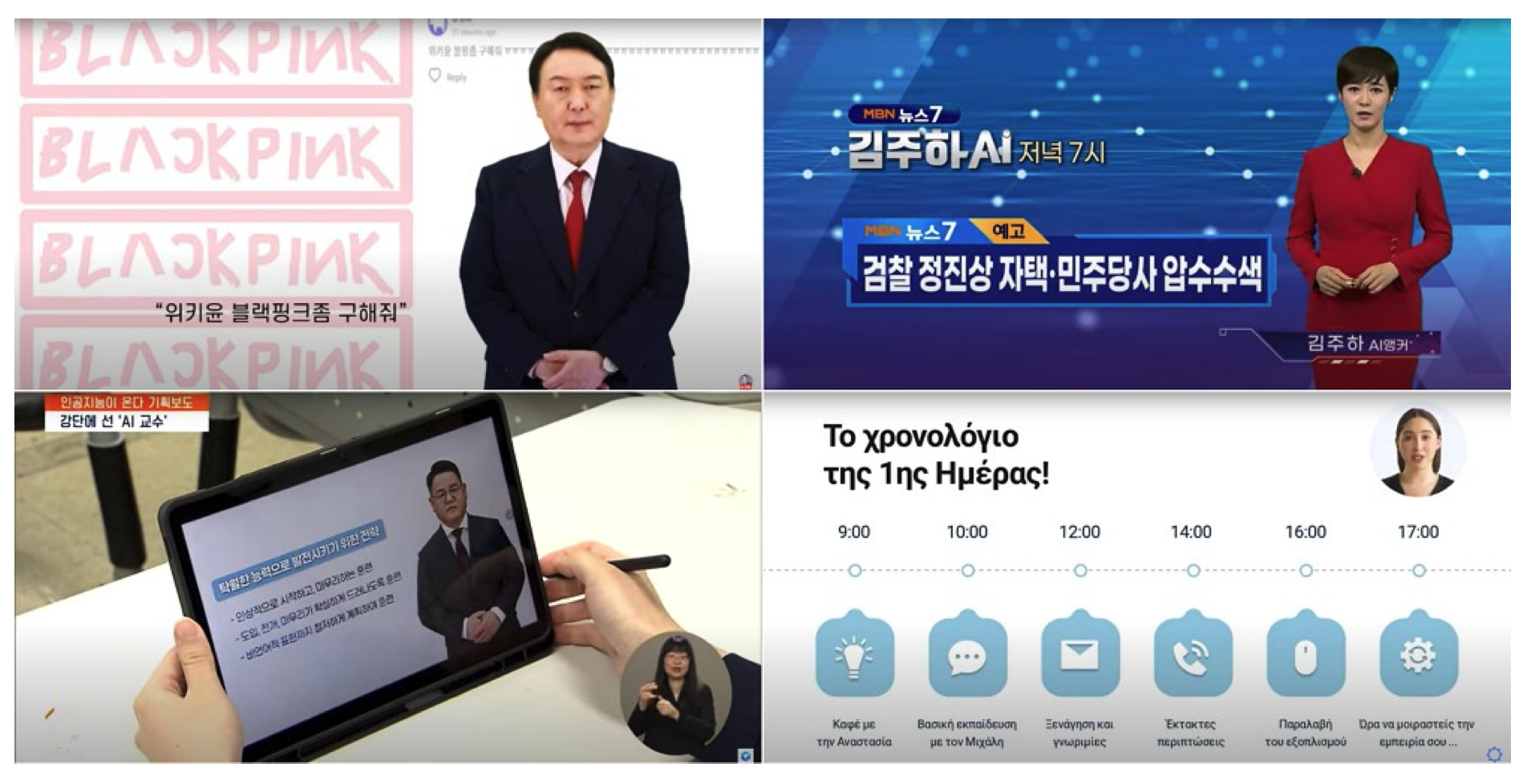
图 8. 专业市场文本到视频生成应用的使用案例。总统竞选 (左上)、新闻广播 (右上)、AI 教授 (左下) 和员工入职 (右下)。
研究用原型. 除了上述的商业产品,还有一些原型是针对人工智能研究人员进行实验当前文本到视频生成模型的发展。Make-A-Video、Stable Diffusion Video 和 Deforum Stable Diffusion15 是其中的几个。用户可以自由地使用文本提示生成视频,并检查这些模型在不同输入设置组合下的表现。这些平台帮助研究人员识别当前模型发展中的潜在缺陷,并可能设计出更好的模型架构或训练技术,以推动文本到视频生成研究的进展。
教育用原型. 值得注意的是,文本到视频技术能够显著改变教育方法,提供丰富的策略来丰富教学和学习体验。视频已经被广泛讨论和应用于教育 [92],因为它能够提高学生的动机 [1] 和自主学习 [68]。此外,从文字教学向视频教学的转变可以通过可视化抽象概念(例如科学教育中的电流流动可视化)为学生提供深刻理解。因此,在教育中实施文本到视频技术有潜力通过将讲座笔记转换为视频格式极大地增强教师的效果。视频辅助教育有几个优势,包括学生能够更详细地解释复杂思想,并达到比传统方法更高水平的学习。
技术限制和伦理问题
技术限制
尽管文本到视频生成模型取得了许多进展,但从视频生成结果中可以看出存在一些限制,即使在像 Sora 这样的大型视频生成模型中也是如此。
多实体处理. 这类生成模型在创建存在多个外观相似实体的场景时通常表现不佳。失败案例包括突然的实体克隆、多个实体稀释以及实体收缩为无法识别的形式(图 10)。处理这种类型场景的能力在目标检测任务中也一直是一个长期存在的问题。特别是在使用边界框来检测对象时,这种情况尤为突出,因为它包含一个非极大值抑制算法来优化检测结果。
因果关系学习. 文本到视频生成模型的一个重大失败是它们无法有效理解动态场景。这些模型尚未能够预测事件发生时的反应。失败案例包括无法理解交互对象之间的文本关系、无法跟随动作协调以及忽视因果关系排序(图 11)。
物理交互. 视频作为解释抽象概念或太复杂以用文本解释的指导的首选媒介之一的原因之一是视频可以正确模拟物理世界中的抽象概念。然而,由文本到视频生成模型生成的合成视频在模拟适当的物理交互方面存在局限。这些缺点包括忽视模拟基本物理定律、无法进行基础和把握、以及在显示对象的物理状态时存在时间上的不一致性(图 12)。
尺度和比例理解。 物体的尺度和比例是场景理解中的另两个重要方面。同样,在视频生成任务中,它们也是至关重要的因素。与此同时,即使在像 Sora 这样的大型视觉模型中,正确处理这些元素仍然具有挑战性。图 13 展示了 Sora 在处理物体缩放和比例时的一些失败案例。我们注意到,这些错误主要发生在使用复杂的摄像机运动(如旋转或从地面高度变化)生成场景时。由于视频基本上是一系列图像帧,我们推测缩放失败是由于帧之间的过渡不连贯造成的,这是由于解释非线性视角变化的困难。然而,这可能是由于提示不足或运动数据多样性不足而导致的。例如,图 13 中用于生成左右视频屏幕的文本提示仅为“2056 年展示尼日利亚拉各斯人民的美丽家庭视频。用手机摄像头拍摄。”和“美丽的、下雪的东京城市熙熙攘攘。摄像机穿过熙熙攘攘的城市街道,跟随几个人享受美丽的雪天气,并在附近的摊位购物。美丽的樱花花瓣随风飘扬,与雪花一起飞舞。”。请注意,没有一个文本提示描述应该如何创建摄像机角度。

图 10. 当存在多个外观相似的实体时,视频生成模型通常会出现幻觉,如克隆实体(顶部),退化为不可识别的形式(中部),或融合成单个实体 [141](底部)。受影响的实体在黄色框中。
物体幻觉。 我们将新物体突然出现或消失于生成的视频屏幕中称为幻觉。像 Sora 这样的大型文本到视觉模型仍然受到这一限制的影响。图 14 展示了一些由幻觉引起的失败案例。例如,第一个视频场景从同一高度的市场转变为不同高度的城市景观。第二个视频场景展示了人行道的消失。第三个视频场景展示了一条新路径突破茂密树木的突然出现。此外,最后一个视频场景说明了公交车在被树木遮挡时消失的情况。从这些案例中,我们推断幻觉发生在物体遭受严重遮挡时。此外,基于运动的帧插值可能促使视频场景创建一个看似不合逻辑的物体。就像新的路径出现在树木间一样,因为骑自行车的人将自行车转向新路径出现的方向。与此同时,在真实的视频镜头中,骑自行车的人可能会立即将自行车转向正确的轨道。这种情况类似于物体跟踪任务中的限制,其中估计非线性物体运动(如突然改变方向)仍然具有挑战性 [123]。

图 11. Sora 在理解因果关系方面的缺陷示例;玻璃破裂前液体泄漏(顶部),蜡烛火焰方向不一致且尽管被吹动仍保持静止(中部),画布上颜色刷子的颜色不随画布上颜色变化而改变(底部)。受影响的实体在黄色框中。

图 12. Sora 在物理和交互理解方面的示例限制包括未理解液体必须流向较低地面(顶部),球不能穿过固体环(中部),塑料椅不是由黏土制成的(底部)。受影响的实体在黄色框中。

图 13. Sora 中物体缩放和比例失败案例;一帧中矮小的人群和正常尺寸的男性(左侧),一帧中正常尺寸的行人和巨大尺寸的夫妇(右侧)。受影响的实体在黄色框中。
伦理关切
评估文本到视频生成模型的优缺点,特别是 Sora,变得至关重要,考虑到其具有开创性的影响。这种能够从文本描述中生成逼真的一分钟视频的模型代表了人工智能驱动内容创作的重大进步,为创造力、教育和沟通开启了巨大潜力。另一方面,它也带来了一些缺点,引发了重要的伦理和社会关切。
滥用。 从视觉生成人工智能生成的超逼真视频可能被滥用,用于制作在关键事件(如选举)中传播误导信息的情感操纵内容。通过展示政治家在不存在的场景中的虚假视频,传播虚假信息的威胁 [37, 85] 极大地扭曲了公众舆论。此外,这样的模型可能生成威胁个人隐私和安全的虚假内容 [86]。可以通过实施各种保障措施来缓解这些问题,如强大的深度伪造检测系统、及时的输入分类器,或简单地禁止某些话题。这些选项还应与遵循版权规则相结合,可以通过水印 [151] 或深度隐藏 [152] 等措施来实施,这些措施可以秘密附加用户的唯一识别模式。然而,这些措施取决于观众辨别和理解其重要性的能力。脆弱群体,特别是老年人或数字素养有限的人,可能会忽视这些标记,突显了年龄和能力歧视的问题。
公平性。 公平性已成为当今生成模型中长期存在的挑战。刻板印象是当今任何基础模型中最常见的问题,包括视觉。例如,像 Stable Diffusion 和 DALL·E 这样的视觉生成模型被发现放大了性别和种族的偏见 [128]。尽管许多研究人员试图揭示一些公开可用的基础模型中的偏见问题,但问题仍然存在。也许其中一个原因是公平性问题在现实世界中仍然存在。因此,可以预期类似的问题也会传播到视频生成模型中。

图 14. Sora 中的幻觉案例包括突然的场景变化(第一行),由于遮挡导致物体消失(第二行和第四行),以及新物体的出现(第三行)。受影响的实体在黄色框中。
透明度。 尽管像深度伪造检测这样的纠正措施似乎是政策制定者最常选择的方式,但可以通过预防性措施来防止应用生成式人工智能模型的不当行为。迫使模型变得更加透明可以是其中的一种选择。例如,通过利用可解释的人工智能系统,可以揭示用户指令是如何转化为输出视频的基础“路径” [44]。然而,实施这一措施的大规模过程可能充满挑战 [43]。主要原因主要是出于战略目的,因为披露商业生成产品的基础机制可能导致同一市场中的商业参与者之间潜在的竞争风险。
讨论
人类辅助大型文本到视频生成模型
在人工通用智能(AGI)不断发展的格局中,Sora 代表了使文本到视频生成更加以人为中心的一种变革性方法。Sora 采取的一个明显方法是将 GPT-4 与提示细化相结合,使 Sora 能够以类似于人类理解的方式解释用户的指令。有了这种能力,这种文本到视频生成模型提供了更加用户友好和直观的体验,展示了其以人为中心的特性。这种在生成式人工智能领域的显著进步 [156] 不仅将彻底改变视频生成社区,还将影响到内容生成的各个领域。连接现实世界和虚拟世界可能成为从 Sora 中获益最多的领域之一。
-
元宇宙建模。 具备理解和模拟物理世界的能力,合理地假设 Sora 的后代模型在 3D 渲染和 3D 虚拟环境构建方面表现出色是可以的。因此,它可以促进元宇宙的发展,提供更加动态、个性化、沉浸式的用户体验。元宇宙被构想为一个集体虚拟共享空间,融合了数字和增强现实的多个方面,包括社交网络、在线游戏、增强现实(AR)和虚拟现实(VR)[70]。元宇宙依靠持续创造和扩展其虚拟环境和体验而蓬勃发展。Sora 的后代模型有望通过快速生成可以填充这些虚拟世界的 3D 内容来为此做出贡献;因此,构建 3D 对象和 3D 世界是繁琐且资源密集的。这可能包括从环境背景和动画纹理到复杂叙事序列的一切,从而丰富元宇宙内容景观的多样性和动态性。此外,快速构建虚拟 3D 对象的潜力可能会开辟新的可能性,使未来曾被认为不可能的事情成为现实。Sora 的进步表明了在物理物品建模之后创建数字孪生体的潜力。这些物品的其他属性,如声音和触觉反馈(触觉),可能会得到增强,除了一系列图像,以实现 AGI 世界模型的逼真复制。
-
空间计算。 如前一段所述,关键特征也可以释放元宇宙的潜力,通过研究虚拟实体与人类用户之间的互动。构建的 3D 环境可以用作评估在现实世界中难以进行的活动的测试场所。一些其他用户研究可能会引发伦理问题(例如种族主义或黑暗模式[138])和技术限制(例如部署可移动的 100 米高建筑[27])。例如,关于在城市中放置巨大物品收集反馈的用户研究可能会从由 Sora 驱动的虚拟世界中受益。因此,与其花费大量时间和财力来建造这些物品,Sora 可以作为一种辅助技术,帮助研究人员在模拟或原型制作阶段了解用户反馈,从而避免改变真实世界配置而干扰人们的日常生活。另一方面,目前在混合现实(MR)中进行用户活动存在技术限制,例如数字叠加在物理世界中的不精确放置。这些限制可能会对用户体验产生负面影响,并在研究过程中扭曲用户感知。利用未来一代的 Sora 模型,研究人员可以在虚拟环境中模拟增强现实(即虚拟现实),以分析用户行为及其对 3D 用户界面的反应,前提是现代虚拟现实头显可以提供高质量视频和无缝体验。
作为世界模拟器的可扩展文本到视频生成模型?
随着前一节所述的令人印象深刻的进展,可以理解为什么 OpenAI 将 Sora 称为一种能够理解并因此模拟物理世界的 AI 模型。这一说法确实划定了 Sora 与像 DALL·E 这样的现有文本到图像模型之间的界限,后者旨在通过视觉方式表达文本概念。而后者则是为了真实地建模或模拟物理世界而开发的。然而,要将 Sora 标记为世界模型,首先要理解一个类似 Sora 的 AGI 要承担这种身份需要什么。
- 世界模型的概念。 世界建模的概念已经存在了四十多年。它最初源自纯科学,如物理学、数学和经济学。一般来说,世界建模的过程相当启发式,因为模型制作者通常缺乏一个全面的计划或理论来支撑他们的思考,就像在没有食谱的情况下烘烤蛋糕需要经历几次试验和错误[13]。由于这一点,模型制作者只能依赖现有作品或与其构想密切相关的可用信息来近似于他们心中构想的世界[39]。总的来说,世界建模的主要组成部分包括理论、隐喻、类比、政策、经验数据、程式化事实和数学概念和技术(图 15),这些必须包含在建模的“食谱”中[13]。将这些方面总结为实践,今天的世界模型似乎由三种能力表示,即视觉、记忆和控制器,Ha 和 Schmidhuber 将其分别展示为 VAE、RNN 和控制器[45]。这样的概念适用于任何形式,因为视觉、记忆和控制器可能分别指数据、架构和目标函数(图 15)。
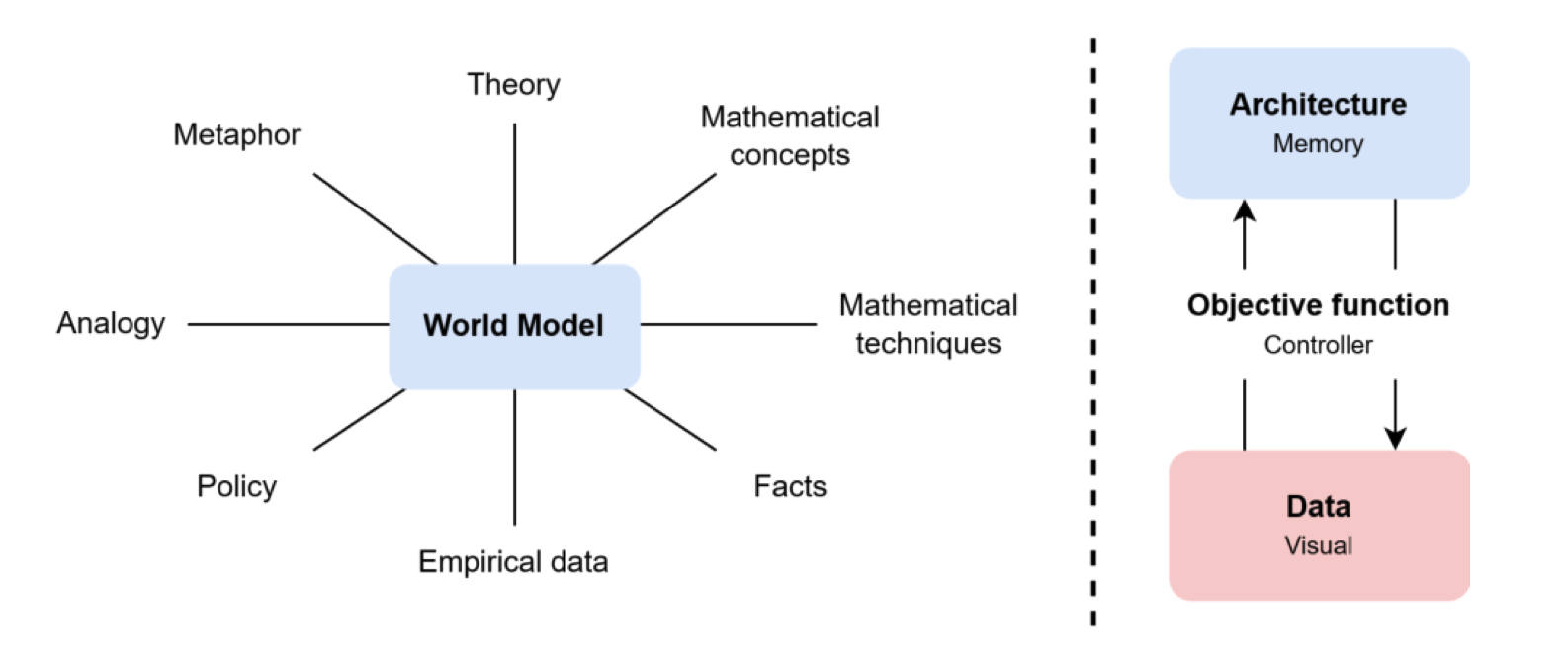
图 15. 从 Boumans [13] 调整的世界模型元素(左)和从 Ha 和 Schmidhuber [45] 调整的人工智能世界模型方面(右)。
- 通过 AGI 建模世界。 人工通用智能(AGI)作为人工智能领域快速发展中的一项革命性前沿旨在实现在各种任务和领域上与人类智能相媲美或超越的认知表现,超越了人工狭窄智能(ANI)系统的能力[83]。其目标是构建能够完成人类能够完成的任何智力工作的机器,包括理解、学习和灵活自主地应用信息。与针对专门任务定制的人工智能应用(如图像识别、下棋或语言翻译)不同,AGI 的目标是将这些各种技能结合到一个单一系统中,展示出通用智能。对智能基本原理的更深入理解的追求激发了这种全方位的人工智能研究和发展方法,为可能完全改变我们与技术的互动方式、处理具有挑战性的问题以及理解人类思维如何运作打开了大门。鉴于这些规格,AGI 确实有资格拥有世界模型的称号。然而,根据我们在前几节中的讨论,我们可以推断出 AGI 模型是纯数学的,没有考虑手动控制在“真实”世界中固有存在的内在方面。例如,像 ChatGPT 这样的 LLM 完全建立在执行纯矩阵操作的变压器上。这反映了研究人员在 1990 年代尝试通过自然语言处理来模拟世界时,他们认识到在语言中将实体和属性连接起来作为基本本体论的困难[15]。尽管如此,科学家们不断前行,努力实现在一个完全适合用户理解的模型中建模广阔宇宙的梦想。有了这些属性,研究人员一直在创新各种方法,让模型看到真实世界环境。通过游戏进行代理建模[76]、虚拟体验[142]和与人类反馈结合的强化学习[23]是挖掘真实世界经验的方法之一。
文本到视频生成模型的缺陷
尽管所有的功能都已经实现,通过人工智能模仿真实世界从未容易。社会需要权衡模型的令人印象深刻的能力,例如从用户提示中隐式学习直观物理规律[35],以及源自“离散化”高维连续输入数据的导致的模拟真实世界规范的灾难性限制。因此,我们总结了文本到视频生成模型的缺陷,即使在像 Sora 这样的可扩展生成模型中,这些缺陷可能仍然存在。
-
文本-视频配对数据集的不足。几乎所有代表性的文本生成视频模型研究都一致认为,由于缺乏大规模的文本-视频配对数据集用于训练或评估,这已成为一个共识。这可能是由于寻找确切的短视频或将其转化为全面的文本描述的困难所致。附录中的表A1列出了用于每个模型训练和评估的所有数据集。其中,MSR-VTT [144]、UCF-101 [122]、Moving MNIST [88]、Kinetics-400 [16]和Kinetics-600 [60]被认为是开发文本生成视频模型最常用的数据集。还有其他经常使用的数据集,如HD-VILA-100M [147]、LAION-400M [111]、WebVid-10M [9]、MUG [7]和KTH [112]。然而,它们仍然存在一些缺陷,这些缺陷可能会延续到我们在第7节讨论的限制中。首先,这些数据集中有一半是以人为中心的,更糟糕的是,它们强调人类行为。请注意,人类行为与活动或事件不同,因为它往往围绕着单独的行为展开 [3]。数据集的另一半包括非人类行为记录的动作,如动物、车辆、自然、科学,甚至来自动画的虚构镜头。虽然这减轻了以人类为中心的限制,但这些数据集的限制来自于生成字幕或描述的机制。它们通常依赖于传统的语言处理方法,如跳跃思想向量、视觉-文本检索以及从本地描述符生成字幕,将视觉和文本内容视为词袋 [24]。除了自动生成字幕,一些数据集还采用手动生成字幕,要么借助人类注释者的帮助,要么通过从音频语音或元数据中获取现成的文本描述。这种方法可能更灵活,可以容纳视觉理解的更复杂方面,如推理和关系。然而,除了其劳动密集特征外,这种方法可能存在一些源自人类感知本质的潜在偏见。特别是在Sora中,OpenAI隐藏了收集训练数据的来源和技术,尽管这在确定Sora的有效性方面起着关键作用。事实上,这样的决定可能源自公司的专有政策。然而,仍然令人深思的是,看看纪录片、电影和长镜头拍摄的数据是否包含在训练Sora中。
-
生成评估中的Ckasm。我们在第5节讨论了通常用于评估视频生成模型结果的指标。其中,视觉质量指标在我们在第3节审查的视频生成模型示例中被大多数引用。统计数据显示,几乎一半的研究忽略了生成视频与文本提示匹配程度的评估。这可能意味着,尽管视觉生成模型已将其他模态整合到生成过程中,但视觉质量仍然成为评估的(也许是唯一的)黄金标准。事实上,另一半的研究也整合了文本-视觉相关性的评估指标。然而,几乎所有这些模型都使用基于CLIP的评估指标。虽然这样的指标可能是当前文本-视觉一致性的黄金标准,但CLIP模型本身在理解文本提示的上下文以及如何将其转化为视觉内容方面存在缺陷。例如,发现CLIP的行为类似于词袋,它无法理解文本提示中的关系推理的含义,并将其转化为图像 [148]。当文本提示以任何方式排列时,CLIP始终检索与提示中相似的图像,就好像单词被正确排序一样。这可能意味着,CLIP的强项仍然局限于仅理解每个单词,而无法进一步参考文本的连贯性。因此,依赖于CLIP模型进行评估的文本-视觉生成模型可能会受到严重偏向于单词元素检索而不是文本内容连贯性的评分。这种缺陷部分地可以解释为什么即使在像Sora这样的视觉基础模型中,我们在第7节讨论的这些限制仍然存在。
文本生成视频的未来方向
尽管大型文本生成视频模型取得了令人称赞的成功,但上述限制并非微不足道,可能会引发用户社区的抑制。因此,研究界面临着艰巨的任务,以确保可扩展的文本生成视频模型确实足够可靠,堪称世界模型。在这里,我们列出一些建议,这些建议源自我们对模型限制的先前讨论(图16)。
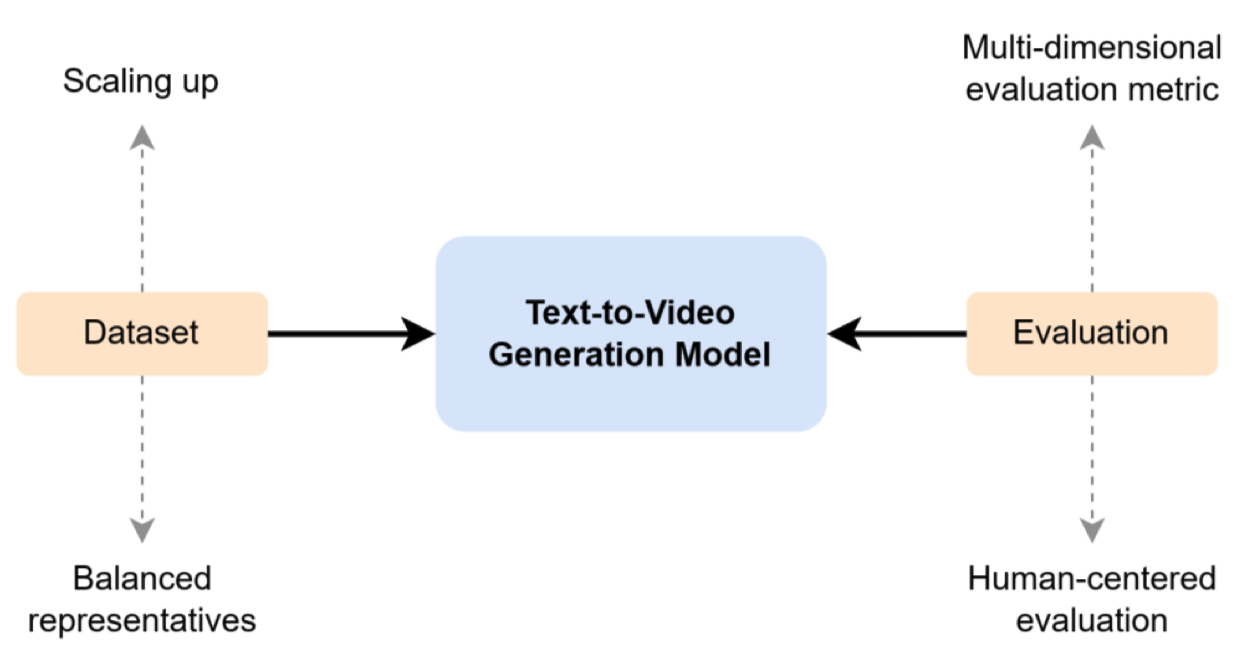
图16. 文本生成视频模型未来研究方向的插图,以数据集和评估系统为锚点。向上的虚线箭头表示泛化和自动性的增加。向下的虚线箭头表示在内容代表性和用户适应性的细粒度审查上平衡进展。
-
平衡数据扩展和类别选择。从我们的讨论中可以推断,简单地扩展文本生成视频模型并不能保证该模型能够实现接近真实世界的性能。从无法计量的数据中学习可能有助于模型识别大量真实世界术语。然而,这并不一定意味着模型也学会了超越这些数据的知识。此外,视频生成中的一些限制可能源自预训练数据的选择。因此,仔细学习预训练数据中的元素分布可能是增加这种生成模型性能的重要选择之一。
-
超越量化的评估指标。尽管一个生成输出的评估系统可能非常复杂,但一个合适的指标仍然是必要的,以决定生成模型是否符合建模者的目标。因此,文本生成视频模型的未来研究也可能同样强调开发用于文本-图像理解的评估系统的必要性,以补充视觉质量指标。开始这项工作的一种方式可能是借鉴像ChatGPT这样的LLM在评分聊天机器人输出方面经历过的情况。作为AGI中的前辈,ChatGPT已经被整合到数百个下游应用程序中,评估ChatGPT生成的文本质量仍然是研究社区的热门话题。研究人员正在积极寻找替代方法来评估生成的文本,而不依赖于基准数据。这可能包括通过各种模拟人类思维行为的机制来探索文本本身的内容,或借助更强大的语言模型的能力。研究人员为评估LLM生成的单个文本输出质量所付出的巨大努力,表明了文本生成视频模型的研究,即单个文本提示可以有数百种解释方式,因此生成的视频质量必须从多维度的角度进行评估,如推理、因果效应和空间关系。特别是,仅依赖于文本-图像检索机制可能不足以判断用户的文本提示是否在生成的视频输出中被忠实且合乎逻辑地呈现。
-
以人为中心的评估系统。实现文本生成视频AGI世界建模梦想的一大步可能会将我们引向人类参与的重要性,就像我们在第8.2节中讨论的那样。与主要在改进视频生成质量(即“到视频”部分)上的当代评估系统不同,评估模型如何理解人类提示可能会进一步赋予用户对视频生成过程的充分控制(例如,通过微调其提示的措辞)。最重要的是,将用户体验纳入文本生成视频模型的人类评估框架可能是朝着实现更加以人为中心方法的关键进步。请注意,这种方法与简单评估文本忠实性不同。虽然文本忠实性 [117, 141] 以及视觉质量 [54, 117] 只涵盖了用户与生成内容的交互和满意度的更广泛范围,但以人为中心的评估直接衡量生成的视频是否符合用户的期望。用户中心度指标的一个示例方法可能是评估生成的视频与用户在构思阶段设定的目标之间的匹配程度。在实践中,这可能涉及要求用户评价视频如何准确地反映了其输入提示中所暗示或明确陈述的意图和细微差别。通过这种测量,文本生成视频模型的输出可以从更广泛的角度进行评估(例如,成功描绘意图、情感以及用户提示中隐含或明确陈述的细节),而不仅仅是确保视频中的命名实体、动作和描述的场景准确且忠实地呈现。
结论
我们的调查从数据驱动模型演变到像 Sora 这样的大规模基础模型的角度深入讨论了文本到视频生成模型。我们全面审查了这些模型的核心技术、框架、评估指标、工业应用、技术限制以及伦理关切。在此基础上,我们围绕可扩展模型 Sora 对文本到视频生成模型展开了深入讨论。我们的讨论涉及多个方面,包括可扩展视频生成模型作为人类助手和世界模拟器的能力。我们还进一步审查了文本到视频生成领域研究人员关注的前两个引人注目的主题,即模型缺陷和未来改进方向,从数据和评估的角度。鉴于我们的全面讨论,我们认识到,即使存在一些缺陷,通过深入的训练和架构工程,可扩展的文本到视频生成模型 Sora 主要是可以实现的。Sora 不仅具有泛化能力,还能创造出极其延时的视频(长达一分钟),这是一个值得注意的进步,将该模型与以往的文本到视频生成工作区分开来。然而,为什么扩展并非万能之策,以及如何解决 Sora 在视觉生成任务中的当代问题,仍然是视觉生成研究社区中的一个蓝海。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











