







用 AI 技术让 PDF 图像"说话",开启交互新模式
引言
在我们的数字时代,信息主要通过电子格式共享,PDF作为一种重要的媒介。然而,其中的数据,尤其是图像,由于格式限制往往被低效利用。本文介绍了一种开创性的方法,不仅解放了PDF中的数据,而且最大化了其利用价值。通过使用Python和先进的人工智能技术,我们将演示如何从PDF文件中提取图像,并使用像LLava和LangChain这样的复杂AI模型与其进行交互。这种创新方法为数据交互开辟了新的途径,增强了我们分析和利用PDF中封存的信息的能力。

学习目标
- 使用unstructured库从PDF中提取和分类元素。
- 设置Python环境以进行PDF数据提取和AI交互。
- 将PDF图像隔离并转换为base64格式以进行AI分析。
- 使用LLavA和LangChain等AI模型分析和与PDF图像交互。
- 将对话式AI集成到应用程序中,增强数据的实用性。
- 探索基于AI的PDF内容分析的实际应用。
从PDF中提取非结构化数据
环境设置
将PDF内容转换的第一步是准备计算环境和必要的软件工具。这个设置对于高效处理和提取PDF中的非结构化数据至关重要。
!pip install "unstructured[all-docs]" unstructured-client
安装这些软件包会为您的Python环境配备unstructured库,这是一个强大的工具,用于解剖和提取PDF文档中的各种元素。
从PDF中提取数据
提取数据的过程始于将PDF拆分为单个可管理的元素。使用unstructured库,您可以轻松地将PDF分割为不同的元素,包括文本和图像。这里关键的是unstructured.partition.pdf模块中的partition_pdf函数。
from unstructured.partition.pdf import partition_pdf
# 指定PDF文件的路径
filename = "data/gpt4all.pdf"
# 从PDF中提取元素
path = "images"
raw_pdf_elements = partition_pdf(filename=filename,
extract_images_in_pdf=True,
strategy="hi_res",
infer_table_structure=True,
extract_image_block_output_dir=path)
该函数返回PDF中存在的元素列表。每个元素可以是文本、图像或其他类型的内容。PDF中的图像存储在’image’文件夹中。
识别和提取图像
一旦我们确定了PDF中的所有元素,下一个关键步骤是隔离图像以进行进一步的交互:
images = [el for el in elements if el.category == "Image"]
这个列表现在包含了从PDF中提取的所有图像,可以进一步处理或分析。
以下是提取的图像:
在笔记本文件中显示图像的代码:
这一简单而有效的代码行从不同元素的混合中筛选出图像,为更复杂的数据处理和分析奠定了基础。
使用LLavA和LangChain进行对话式AI
设置和配置
为了与提取的图像进行交互,我们使用了先进的人工智能技术。安装langchain及其社区功能对于促进与图像的对话式AI非常重要。
请查看链接以详细了解如何设置Llava和Ollama。另外,请安装以下软件包。
!pip install langchain langchain_core langchain_community
此安装引入了将对话式人工智能功能集成到我们应用程序中所需的基本工具。
将保存的图像转换为base64:
为了使AI能够理解图像,我们将它们转换为一种AI模型可以解释的格式——base64字符串。
import base64
from io import BytesIO
from IPython.display import HTML, display
from PIL import Image
def convert_to_base64(pil_image):
"""
将PIL图像转换为Base64编码的字符串
:param pil_image: PIL图像
:return: 调整大小后的Base64字符串
"""
buffered = BytesIO()
pil_image.save(buffered, format="JPEG") # 如果需要,可以更改格式
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
return img_str
def plt_img_base64(img_base64):
"""
将Base64编码的字符串显示为图像
:param img_base64: Base64字符串
"""
# 创建一个带有Base64字符串作为源的HTML img标签
image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'
# 通过渲染HTML来显示图像
display(HTML(image_html))
file_path = "./images/figure2.jpg"
pil_image = Image.open(file_path)
image_b64 = convert_to_base64(pil_image)
使用Llava和Ollama通过langchain分析图像
LLaVa是一个开源的聊天机器人,通过在GPT生成的多模态指令跟随数据上进行LlamA/Vicuna的微调来训练。它是基于Transformer架构的自回归语言模型。换句话说,它是针对聊天/指令进行微调的多模态版本的LLMs。
将转换为适当格式(base64字符串)的图像可以作为LLavA的上下文,提供描述或其他相关信息。
from langchain_community.llms import Ollama
llm = Ollama(model="llava:7b")
# 使用LLavA解释图像
llm_with_image_context = llm.bind(images=[image_b64])
response = llm_with_image_context.invoke("解释图像")
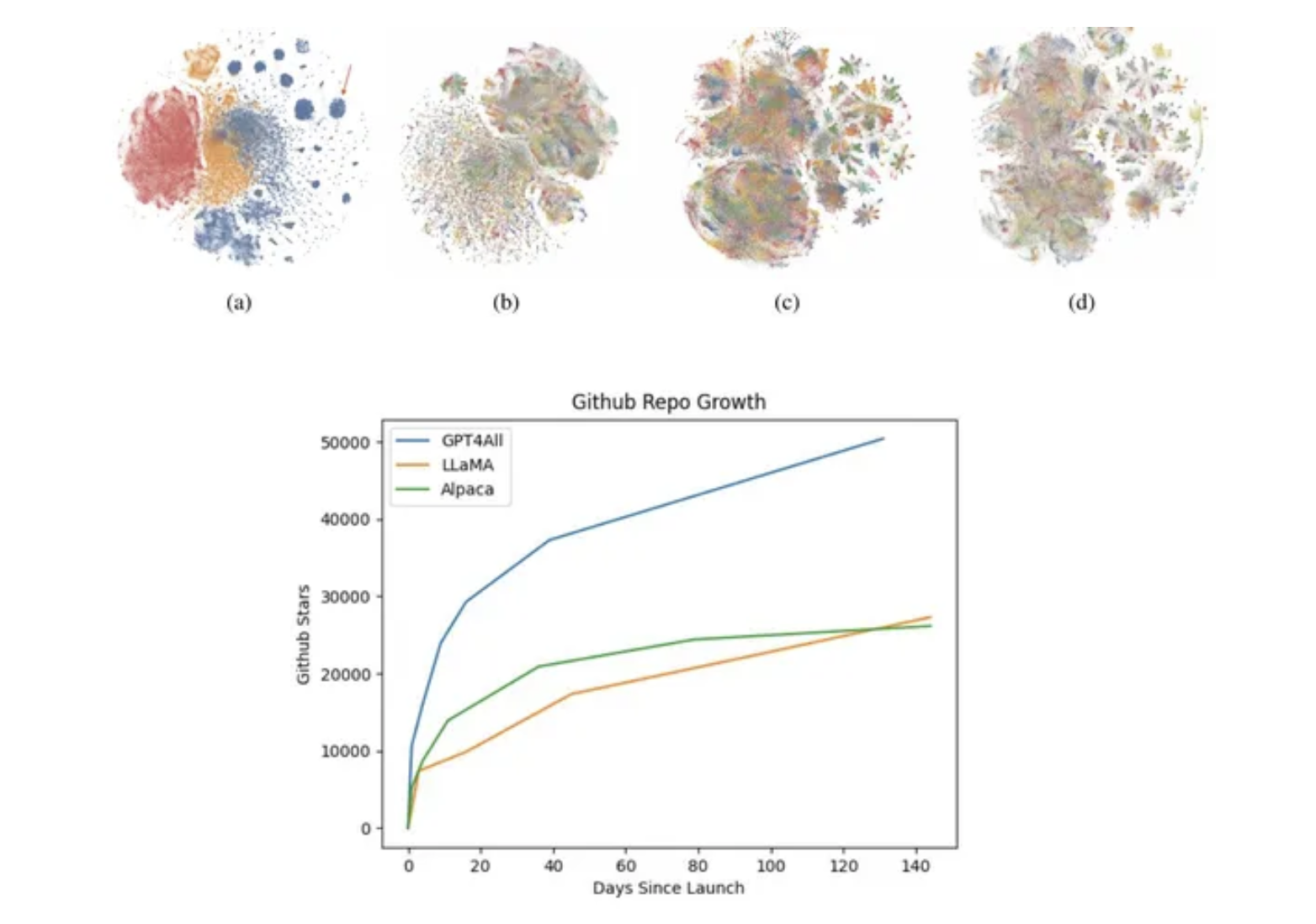
输出:
“该图显示了GitHub存储库随时间的增长情况。图中包含三条线,分别代表不同类型的存储库:
- Lama:这条线代表一个名为“Lama”的单个存储库,从给定的时间段开始,逐渐增长到接近5,00。
- Alpaca:与Lama存储库类似,这条线也代表一个名为“Alpaca”的单个存储库。它从0开始增长得更快,到该时期结束时达到大约75,00。
- 所有存储库(平均):这条线代表GitHub上所有存储库的平均增长率。它显示随时间逐渐增加的存储库数量,与其他两条线相比变化较小。
图上标有从数据开始到结束的时间戳,但没有明确标注。垂直轴表示存储库数量,水平轴表示时间。
此外,图像上还有一些注释:
- “GitHub存储库增长”表明该图说明了GitHub上存储库的增长情况。
- “Lama,Alpaca,所有存储库(平均)”标签指示每条线代表哪个存储库集合。
- “100s”,“1k”,“10k”,“100k”和“1M”是标记在图上的里程碑,表示特定时间点的存储库数量。
图像中看不到GitHub的源代码,但在讨论此图时,这可能是一个重要的方面。所显示的增长趋势表明在这个平台上,新存储库的创建或贡献数量随时间增加。”
此集成使模型能够“看到”图像并提供有关图像内容的见解、描述或回答相关问题。
结论
从PDF中提取图像,然后利用AI与这些图像进行交互,为数据分析、内容管理和自动化处理打开了许多可能性。这里描述的技术利用了强大的库和AI模型来有效处理和解释非结构化数据。
主要要点
-
高效提取:该无结构化库提供了一种无缝的方法,可以提取和分类PDF文档中的不同元素。
-
高级人工智能交互:将图像转换为适当的格式,并使用LLavA等模型,可以实现与文档内容的复杂人工智能驱动交互。
-
广泛应用:这些功能适用于各个领域,从自动化文档处理到基于人工智能的内容分析。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











