







RAG Foundry: 增强检索增强生成(RAG)的框架
论文链接:https://arxiv.org/abs/2408.02545
英特尔实验室
摘要
实现检索增强生成(RAG)系统本质上很复杂,需要对数据、用例和复杂的设计决策有深入理解。此外,评估这些系统还面临显著挑战,必须通过多方面的方法评估检索准确性和生成质量。我们介绍RAG FOUNDRY,一个开源框架,用于增强大型语言模型在RAG用例中的应用。RAG FOUNDRY将数据创建、训练、推理和评估整合到一个单一的工作流程中,便于创建数据增强数据集,以训练和评估在RAG环境中的大型语言模型。这种整合使用户能够快速原型开发和实验多种RAG技术,轻松生成数据集并使用内部或专业知识来源训练RAG模型。我们通过将Llama-3和Phi-3模型与多种RAG配置进行增强和微调,展示了框架的有效性,展示了在三个以知识为中心的数据集上持续改进的成果。代码已作为开源发布在 https://github.com/IntelLabs/RAGFoundry。
1 引言
大型语言模型(LLMs)已成为人工智能领域的一种变革力量,展示了在广泛任务中表现出色的能力,这些任务在传统上需要人类智能(Brown et al., 2020; Kojima et al., 2022)。尽管它们的能力令人印象深刻,但LLMs本质上存在局限性。这些模型可能产生听起来合理但实际上不正确或无意义的答案,难以保证事实准确性,在其训练截止后缺乏获取最新信息的能力,并且在处理大型上下文时难以注意到相关信息(Huang et al., 2023; Liu et al., 2023)。
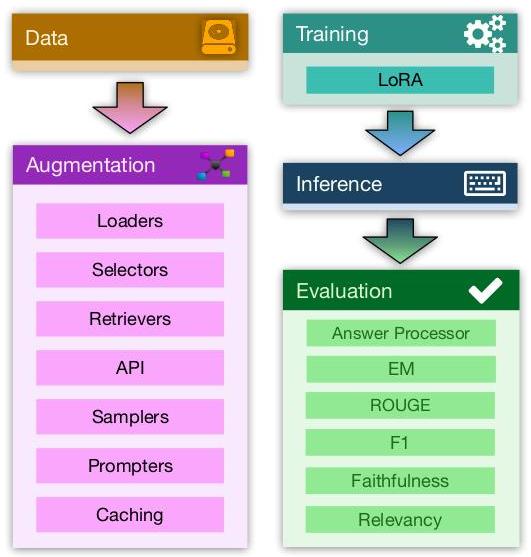
图1:RAG FOUNDRY框架的概述:数据增强模块将RAG交互持久化为专用数据集,然后用于训练、推理和评估。
检索增强生成(RAG)通过使用检索机制整合外部信息,从而提升LLMs的性能。结合利用模型知识以外的庞大知识库的检索,有效地解决了知识局限性,能够减少虚假信息,提高生成内容的相关性,提供可解释性,并且在成本效益上可能更高(Lewis et al., 2021; Mallen et al., 2022; Gao et al., 2023; Asai et al., 2023; Borgeaud et al., 2021; Peng et al., 2023; de Jong et al., 2023)。此外,近期研究表明,针对RAG微调LLMs能够实现业界领先的性能,超越较大、专有模型的表现(Yu et al., 2024b; Liu et al., 2024)。
然而,实施RAG系统本质上很复杂,需要一系列复杂的决策,这些决策会显著影响系统的性能。这个过程要求对数据和用例有透彻的理解,而解决方案往往无法很好地泛化到其他领域(Barnett et al., 2024; Bala-guer et al., 2024)。一些关键的RAG设计决策包括文本嵌入、索引参数、检索算法、查询构建和提示设计等,而这些考虑因素超出了LLM配置(Wang et al., 2024)。另一个问题是可重复性:在运行、数据集和任务之间实现一致且可比较的结果。训练数据、预处理步骤、模型配置和硬件的变化可能导致性能差异,使得研究人员和从业者在复制发现和构建先前工作的基础上面临挑战。此外,由于依赖检索准确性和生成质量的双重性质,评估RAG系统也面临挑战。这些系统需要一个复杂的评估套件,考虑到所检索信息、数据的形式化以及生成输出之间的相互作用(Chen et al., 2023; Yu et al., 2024a; Es et al., 2024)。
我们介绍RAG FOUNDRY,一个开源Python框架,用于开发复杂的检索增强LLMs以满足RAG用例的需求。该库支持研究人员和从业者在增强RAG用例中LLMs能力的微妙任务方面展开合作。它高度可定制,便于在RAG的所有方面(包括数据选择、聚合和过滤、检索、文本处理、文档排序、少量生成、使用模板的提示设计、微调、推理和评估)进行快速原型开发和实验。为了满足研究人员的特定需求,我们设计了该框架,作为一个端到端的实验环境。该库的主干由四个独立的模块组成:数据创建、训练、推理和评估。每个模块都被封装,并由配置文件控制,确保一个模块的输出和下一个模块的输入之间的兼容性。这种模块化方法允许每个步骤独立实验,从而生产多个输出并同时执行众多实验。可以对生成的输出以及数据中的任何特征(包括检索、排序和推理)进行评估。
为说明该框架的实用性,我们进行了涉及检索、微调、思维链(CoT)推理(Wu et al., 2023)和负干扰文档技术(Zhang et al., 2024)的实验。我们使用三种知识密集的问答任务,用多种增强方法比较了两种广泛接受的基础模型,展示了RAG FOUNDRY的有效性。
2 相关工作
与RAG不同方面(即推理、训练和评估)相关的开源工具很多。LlamaIndex (Liu, 2022)、LangChain (Chase, 2022)和Haystack (Pietsch et al., 2019)是著名的RAG管道构建库;然而,它们并不专注于评估,且训练能力相对欠缺。
Hoshi et al. (2023) 提出了一个开发基于RAG的LLMs的框架;尽管我们的处理可能在包含自定义单个步骤方面相似,但他们并未引入任何形式的训练。Khattab et al. (2023, 2022) 提出了一种不同的方法,将LLM提示表示为编程语言,以便进行优化和编译;这是一种相当独特且通用的方法,可能对RAG有益,但由于引入的抽象,复杂度较高。Saad-Falcon et al. (2024) 更侧重于评估方面,通过创建合成数据并训练一个LLM评审来评估RAG系统。Hsia et al. (2024) 研究了检索对RAG性能的影响;我们的RAG Foundry库是通用的,能够在RAG的所有方面进行实验:检索、文本处理、提示设计、模型选择、推理和评估。
最近,Jin et al. (2024) 提出的工作提供了一个RAG构建框架,包括一些RAG实现和数据集;我们关注于可扩展性,让用户定义自定义管道和自定义组件。Rau et al. (2024) 提出了一个框架,分享与我们相似的通过配置进行可扩展的设计原则;他们的库强加了特定的工作流程结构(检索器、排序器、LLM),而我们的库则更加通用,并不强加任何特定范例。
3 RAG Foundry
RAG FOUNDRY框架便于快速原型开发和与多种RAG设置和配置的实验。该库由四个模块组成:数据集创建、训练、
name: my_pipeline
cache: true
steps:
- _target_: dataset_loaders.loaders.HFLoader
inputs: main
dataset_config:
path: "Tevatron/wikipedia-trivia"
split: train
- _target_: dataset_loaders.loaders.LocalLoader inputs: fewshot-data
filename: prepared-fewshot-data.jsonl
- _target_: global_steps.sampling.ShuffleSelect inputs: main
shuffle: 42
limit: 10000
- _target_: $\hookrightarrow$ local_steps.retrievers.HaystackRetriever inputs: main
pipeline_path: configs/qdrant.yaml query_key: query
docs_key: positive_passages
- _target_: global_steps.sampling.FewShot inputs: main
input_dataset: fewshot-data k: 3
output_key: fewshot_examples
- _target_: local_steps.prompter.TextPrompter inputs: main prompt_file: prompts/basic.txt output_key: my_prompt mapping: question: query context: positive_passages fewshot: fewshot_examples answer: answers
- _target_: global_steps.output.OutputData inputs: main
file_name: TQA_train_processed.jsonl
列表 1:一个数据集创建配置示例。该示例包含数据加载、混洗、采样、检索、少量示例收集、提示构建和保存步骤、推理和评估。下面,我们扩展每个模块并提供运行它们的示例配置。
3.1 数据创建与处理
处理模块通过持久化 RAG 交互来促进上下文增强数据集的创建,这对于 RAG 导向的训练和推理至关重要(Berchansky et al., 2024; Liu et al., 2024; Yu et al., 2024b)。这些交互包括数据集加载、列归一化、数据聚合、信息检索、基于模板的提示创建和各种其他形式的预处理。处理过的数据可以保存为一致的、与模型无关的格式,连同所有相关的元数据,确保不同模型和实验之间的兼容性和可重复性。
处理模块由一个包含多个步骤的抽象管道组成,每个步骤由实现特定数据处理功能的 Python 类定义。这些步骤分为两类:
-
全局步骤:可以作用于整个数据集,因此在聚合、分组、示例过滤、连接操作等操作中非常有用。
-
局部步骤:针对单个示例操作,适用于检索、文本处理和字段操作等任务。
模块化设计允许构建灵活且高效的数据处理流程,满足 RAG 导向的训练和推理需求。步骤可以分为以下非排他性类别:
-
加载器:从 Hugging Face 1 {}^{1} 1 中心或本地源加载数据集。
-
选择器:过滤示例、混洗数据集和选择子数据集。
-
检索器:从外部数据库、工具、库和管道集成信息。
-
采样器:从任何数据集中收集随机示例或特征,以编制少量示例或负示例。
-
提示生成器:使用自定义模板和关键字映射格式化提示。
处理模块支持通过全局数据集共享同时处理多个数据集。此功能允许管道的每个步骤访问任何已加载的数据集,增加灵活性并允许复杂的处理程序。此外,该模块包括步骤缓存,可以本地缓存每个管道步骤。这提高了计算效率,并便于轻松重现结果。
3.1.1 示例:增强问答数据集
为了展示处理模块的有效性,我们展示如何通过检索管道获取外部信息来丰富问答数据集,准备少量示例并使用提示模板将所有内容结合在一起。列表 1 演示了如何使用 YAML 配置定义此类处理管道。文件的主要结构是一个步骤列表,每个步骤由一个指向步骤实现的 target 定义。每个步骤都有输入,这是一个名称或要操作的数据集名称列表。步骤中的其他键与特定步骤逻辑相关。
列表 1 中的前两个步骤从 Hugging Face 中心和本地路径加载数据集。第三步从主数据集中混洗并选择 10 k {10}\mathrm{k} 10k 个示例。第四步运行一个基于 Haystack 的(Pietsch et al., 2019)检索管道,使用加载数据集中的问题作为查询来检索相关段落,并将其存储在 docs_key 中。我们注意到,可以在检索步骤中使用不同的检索过程或框架(Liu, 2022; Chase, 2022; Lin et al., 2021)。第五步从辅助数据集中选择 3 个少量示例,紧随其后的是一个提示生成步骤,该步骤加载提示模板并根据定义的映射字典替换所有给定的信息。最后,数据集被保存到本地路径。
model:
_target_: ragfoundry.models.hf.HFTrain
model_name_or_path:
,→ "microsoft/Phi-3-mini-128k-instruct"
load_in_8bit: true
lora:
peft_type: "LORA"
r: 16
target_modules: ["qkv_proj"]
completion_start: "<|assistant|>"
train: gradient_accumulation_steps: 4
learning_rate: 2e-05
lr_scheduler_type: "cosine"
num_train_epochs: 1
optim: "paged_adamw_8bit"
instruction: prompts/prompt_instructions/qa.txt
data_file: TQA_train_processed.jsonl
3.2 训练
我们提供一个训练模块,以微调给定由先前处理模块创建的数据集的模型。训练模块依赖于成熟的训练框架 T R L 2 {\mathrm{{TRL}}}^{2} TRL2 提供高级和高效的训练技术,例如 LoRA (Hu 等, 2021)。列表 2 中展示了一个训练配置的示例。
model:
-_target_: ragfoundry.models.hf.HFInference
model_name_or_path: $\hookrightarrow$ "microsoft/Phi-3-mini-128k-instruct"
load_in_8bit: true
instruction: prompts/prompt_instructions/qa.txt
lora_path: /path/to/adapter
generation:
do_sample: false
max_new_tokens: 50
return_full_text: false
data_file: my-processed-data.jsnol
generated_file: model-predictions.jsonl
列表 3: 推理配置的示例。除了模型和生成选项外,还可以定义系统提示。
3.3 推理
推理模块生成给定由处理模块创建的处理数据集的预测。推理在概念上与评估步骤分开,因为它比评估更计算密集。此外,可以在单个准备好的推理结果文件上运行多个评估。列表 3 中展示了给定数据集生成预测的示例配置。
3.4 评估
框架的目标是增强 RAG 的 LLM。评估模块允许用户运行多个指标集合来评估 RAG 技术和调整过程。评估模块加载推理模块的输出并运行可配置的指标列表。指标是在库中实现的类。这些类可以是包裹其他评估库的简单包装,也可以由用户实现。可以在单个示例上运行局部指标,例如精确匹配(EM),而全局指标则在整个数据集上运行,例如召回(用于基于分类的指标)。指标可以使用数据集中的任何字段和元数据,而不仅仅是输入-输出对。库中实现的一些指标包括:Hugging Face 评估库的包装器,EM,F1,分类指标,BERTScore (Zhang 等, 2019),语义相似度以及 DeepEval 的包装器 3 {}^{3} 3 (用于使用
answer_processor:
_target_: ragfoundry.processing.RegexAnswer capture_pattern: "回答: ${\left( . * \right) }^{n}$ stopping_pattern:
metrics:
- _target_: ragfoundry.evaluation.HFEvaluate metric_names: ["rouge"]
- _target_: ragfoundry.evaluation.EM
- _target_: ragfoundry.evaluation.F1
- _target_: ragfoundry.evaluation.BERTScore model: "microsoft/deberta-large-mnli"
- _target_: ragfoundry.evaluation.Faithfulness
- _target_: ragfoundry.evaluation.Relevancy embeddings: "BAAI/bge-small-en-v1.5"
results_file: my-evaluation.yaml
generated_file: model-prediction.jsonl
data_file: my-processed-data.jsonl
清单 4:评估配置示例;它包含一个答案处理器,以及要运行的指标列表,带有可选参数。
RAGAS 指标(Es 等,2024)。评估完成后,结果文件将写入磁盘,包含本地和全球指标的结果。
此外,评估模块使用一个称为答案处理器的处理步骤,它可以实现自定义逻辑,并服务于多种目的,包括清理和对齐输出;例如,通过使用正则表达式,可以孤立答案,删除停用词,进行连锁思维推理,定义停止标准,处理引用和归属,以及进行任何其他形式的处理,以满足特定评估的需要。
请参见清单 4 以获取配置示例;它包含一个从输出中提取答案的答案处理器,以及要运行的指标列表。
4 实验:RAG 调优
为了说明 RAG FOUNDRY 库的使用及其有效性,我们对 LLM 的几种可能的 RAG 改进进行了实验,并在三个知识密集型任务上评估结果。
4.1 RAG 增强技术
我们探索了几种 RAG 增强技术,并使用 RAG FOUNDRY 轻松实现和评估其效益。作为初步步骤,我们评估未修改的模型;我们将基准设置为通过运行未修改的模型并且不使用任何外部知识来定义的配置。我们定义一个 RAG 设置,该设置以一致的提示模板格式引入相关性最高的文档,并使用系统指令和引导模型使用检索到的上下文、解释步骤、引用相关部分并生成最终答案的连锁思维方案。作为补充,我们探索微调配方。我们在 RAG 设置中微调模型,并将其标记为 RAG-sft。为了补充连锁思维,我们实施了一种微调配方,称为 CoT-sft,引用自(Zhang et al., 2024),在提示中使用金标准文档和纯干扰文档,根据概率确定,并与 CoT 提示结合使用。所有提示模板均包含在附录 A.1 中。
4.2 数据集
我们在 TriviaQA(Joshi 等,2017)、PubmedQA(Jin 等,2019)和 ASQA(Stelmakh 等,2022)上评估我们的模型,这些数据集是知识密集型问答数据集,可以从外部来源中受益。TriviaQA 和 PubmedQA 数据集包含相关上下文;对于 ASQA,检索是通过使用密集检索器在维基百科语料库上完成的 4 {}^{4} 4 。数据集的来源和大小包含在附录 A.2 中。
4.3 模型
我们尝试两种代表性模型:Llama- 3 5 {3}^{5} 35 (Touvron 等,2023;AI@Meta,2024)和 Phi- 3 6 {3}^{6} 36 (Abdin 等,2024),因为它们代表了强大的能力并且是 RAG 用例部署的理想候选模型。
4.4 评估
我们在 TriviaQA 上测量并报告精确匹配(EM),在 ASQA 上报告 STR-EM,在 PubmedQA 上测量准确性和 F1。此外,我们评估两个 RAGAS 指标(Es 等,2024):真实性和相关性。真实性测量生成文本与上下文之间的关系。相关性测量生成文本与查询之间的关系。这两个指标将上下文作为 LLM 评论者的输入,因此仅在 RAG 设置中相关。使用的评论者 LLM 是 GPT4-32k,版本 0613。相关性评估需要一个嵌入器 7 {}^{7} 7 。
4.5 结果
我们在 TriviaQA、ASQA 和 PubmedQA 数据集上提供了 RAG 增强技术的比较研究。结果显示在表 1 中:每个数据集的主要指标以及真实性和相关性得分(如(Es 等,2024)中所定义的)展示。对于 TriviaQA,我们观察到以下情况:检索到的上下文改善了结果,微调 RAG 设置改善了结果,基于 CoT 推理的微调(包括在金标准段落和干扰段落的组合上训练)则降低了性能。对于该数据集,最佳方法依赖于模型。在 ASQA 中,我们同样观察到每种方法均改善了基线,CoT 推理在两个模型中产生了一致的改善,以及 CoT 配置的微调,表明其表现最佳。最后,在 PubmedQA 中,我们观察到几乎所有方法都改善了基线(有一个例外);CoT 推理改善了未训练的 RAG 设置,但在微调后,RAG 方法在两个模型中似乎表现最佳。
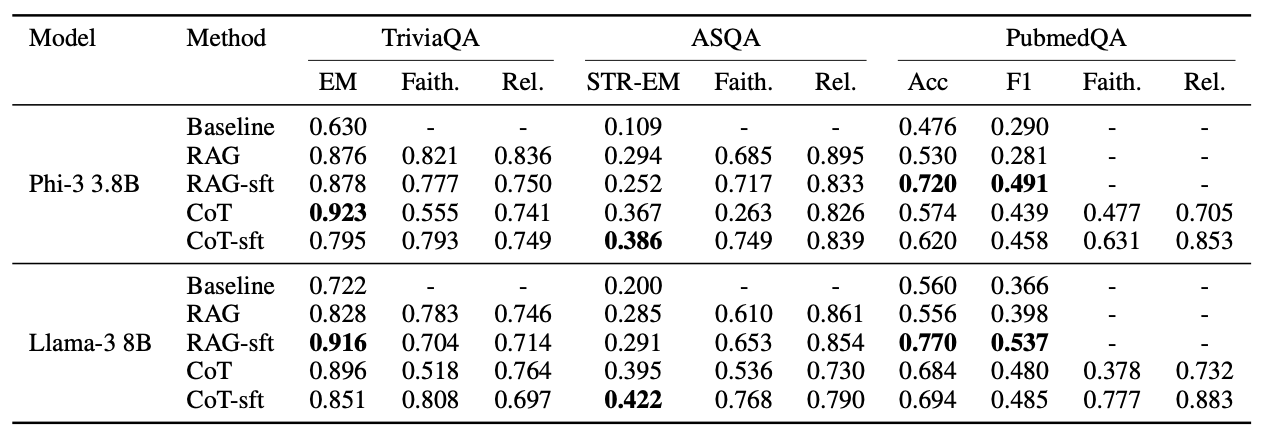
表1:基线模型和不同RAG设置的评估结果,适用于测试的三个数据集和两个模型。除了每个数据集的主要指标外,还报告了相关配置的可信度和相关性。粗体字表示每个数据集的最佳配置,基于主要指标。
检查可信度和相关性分数时,注意并非所有配置都适合被测量:这些指标需要上下文,因此对于基线方法无关。此外,在PubmedQA数据集中,答案是二元的“是/否”;只有在CoT配置中,LLMs产生的推理可以被评估。最后,可信度和相关性分数往往与主要指标不相关,也彼此无关,这可能表明它们捕捉了检索和生成结果的不同方面,并代表了性能的权衡。
结果证明了RAG技术在提高性能方面的有用性,以及需要在多样化的数据集上仔细评估RAG系统的不同方面,因为开发通用技术的工作仍在进行中。
5 结论
我们介绍了RAG FOUNDRY,这是一个专注于RAG增强LLMs任务的开源库,旨在微调LLMs以便在RAG设置中表现更好。该库旨在作为一个端到端的实验环境,使用户能够快速原型设计和实验不同的RAG技术。我们通过在三个问答数据集上评估和增强两个模型,以及展示RAG技术的好处,证明了该库的实用性,还使用了与RAG系统评估相关的多方面指标。
限制与未来计划
我们希望该库能对尽可能多的人和用例有所帮助。然而,由于时间和资源限制,我们只能在部分任务和数据集上展示其实用性。未来的工作可以扩展到其他任务的评估,以及实现其他RAG技术和评估。
尽管我们设计了库以便于通用和可定制,但可能会有特定的工作流在原样运行时会遇到困难,并可能需要一些代码更改。该库在我们自己研究项目中对多样化的数据集和任务证明了其有用性,并且扩展也是简单直接的。
最后,尽管我们尽力在库中提供详细文档,但可能会有一些关于某些功能或特定用例的细节缺失。代码库将接受建议、错误修复和拉取请求。
伦理声明
在进行研究时,我们努力遵守最高的伦理标准,包括我们工作的诚信、公平和社会效益。我们在整个研究过程中优先考虑数据隐私和安全;我们实验中使用的任何数据都是公开可用的,并且不包含任何私人信息。我们致力于透明和可重复性的原则;研究方法,包括数据预处理、模型训练和评估都有文档记录,以使他人能够重复我们的发现。代码在开放的代码库中提供。我们倡导负责任地使用LLMs和RAG增强。务必谨慎行事,并验证LLMs生成文本的准确性和可靠性。幻觉可能会产生负面影响,尽管RAG方法可以改善其中的一些方面,但仍需进行验证和检查。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











