







CHASE - SQL:文本到 SQL 中的多路径推理和偏好优化候选选择
论文:https://arxiv.org/abs/2410.01943
摘要
在应对文本到SQL(Text-to-SQL)任务中大型语言模型(LLM)性能方面的挑战时,我们推出了CHASE - SQL,这是一个采用创新策略的新框架,它在多智能体建模中利用测试时计算来改进候选SQL语句的生成和选择。CHASE - SQL利用大语言模型的内在知识,通过不同的大语言模型生成器来生成多样化且高质量的SQL候选语句,具体方法如下:(1)采用分治法,在一次大语言模型调用中将复杂查询分解为易于处理的子查询;(2)基于查询执行计划进行思维链推理,反映数据库引擎在执行过程中采取的步骤;(3)采用独特的实例感知合成示例生成技术,为测试问题提供特定的小样本演示。为了确定最佳候选语句,使用一个选择智能体通过与经过微调的二元候选选择大语言模型进行成对比较来对候选语句进行排序。事实证明,这种选择方法比其他方法更稳健。所提出的生成器 - 选择器框架不仅提高了SQL查询的质量和多样性,而且优于以往的方法。总体而言,我们提出的CHASE - SQL在著名的BIRD文本到SQL数据集基准测试集和开发集上分别实现了73.0%和73.01%的最先进执行准确率,使CHASE - SQL在排行榜上名列前茅(在论文提交时)。
1 引言
文本转SQL(Text-to-SQL)作为人类语言和机器可读的结构化查询语言之间的桥梁,在许多应用场景中至关重要,它能将自然语言问题转换为可执行的SQL命令(安德鲁索普洛斯等人(Androutsopoulos et al.),1995年;李和贾加迪什(Li & Jagadish),2014年;李等人(Li et al.),2024c;余等人(Yu et al.),2018年;?)。通过让用户无需具备SQL专业知识就能与复杂的数据库系统进行交互,文本转SQL使用户能够提取有价值的见解、进行高效的数据探索、做出明智的决策、生成数据驱动的报告,并为机器学习挖掘更好的特征(陈等人(Chen et al.),2023年;佩雷斯 - 梅尔卡多等人(Pérez - Mercado et al.),2023年;波雷扎和拉菲伊(Pourreza & Rafiei),2024a;波雷扎等人(Pourreza et al.),2024年;孙等人(Sun et al.),2023年;王等人(Wang et al.),2019年;谢等人(Xie et al.),2023年)。此外,文本转SQL系统在通过复杂推理实现数据分析自动化以及驱动对话式代理方面发挥着关键作用,使其应用范围超越了传统的数据检索(孙等人(Sun et al.),2023年;谢等人(Xie et al.),2023年)。随着数据持续呈指数级增长,在无需大量SQL知识的情况下高效查询数据库的能力对于广泛的应用变得越来越重要。
文本到SQL转换可被视为代码生成的一种特殊形式,其上下文信息可能包括数据库模式、元数据以及数据值。在更广泛的代码生成领域,利用大语言模型(LLMs)生成大量不同的候选代码并选择最佳代码已被证明是有效的(陈等人,2021年;李等人,2022年;倪等人,2023年)。然而,目前尚不清楚哪些因素能使候选代码生成机制和最佳代码选择机制达到最佳效果。一种简单而有效的方法是使用零样本/少样本提示或开放式提示生成候选代码,然后利用自一致性原则(王等人,2022年)选择最佳选项,即根据候选代码的执行输出对其进行聚类。多项研究表明,这种方法取得了不错的效果(李等人,2024年;马马里等人,2024年;塔莱伊等人,2024年;王等人,2023年)。然而,单一的提示设计可能无法充分挖掘大语言模型在文本到SQL转换方面的知识,自一致性方法也并非总是有效。事实上,如表1所示,一致性最高的答案并不总是正确答案,其上限性能 14 % {14}\% 14% 高于通过自一致性方法获得的性能。这一显著差距表明,通过实施更有效的选择方法从候选查询中识别最佳答案,仍有很大的改进空间。
基于上一节概述的挑战,我们提出了新颖的方法,通过在智能体框架中利用精心设计的测试时计算来提高大语言模型(LLM)在文本到SQL(Text-to-SQL)任务中的性能。如表1中的上限所示,利用大语言模型的内在知识具有显著的改进潜力。我们提出的方法能够生成一组多样化的高质量候选响应,并应用选择机制来确定最佳答案。实现高质量且多样化的候选响应对于基于评分的选择方法的成功至关重要。低多样性会限制改进潜力,并缩小自一致性方法和基于评分方法之间的差异。虽然提高温度或重新排列提示内容等技术可以提高多样性,但它们往往会降低候选响应的质量。为了解决这个问题,我们引入了有效的候选生成器,旨在在保持高质量输出的同时提高多样性。具体来说,我们提出了三种不同的候选生成方法,每种方法都能够产生高质量的响应。第一种方法受分治法(divide-and-conquer algorithm)的启发,该算法将复杂问题分解为更小、更易于管理的部分,以处理困难的查询。第二种方法采用基于查询执行计划的思维链策略,其中推理过程反映了数据库引擎在查询执行期间采取的步骤。最后,我们引入了一种新颖的在线合成示例生成方法,该方法有助于模型更好地理解测试数据库的底层数据模式。这些方法单独使用时,可以产生高度准确的SQL输出。为了在候选响应中有效地选择最佳答案,我们引入了一个选择智能体,该智能体以分类为目标进行训练,根据候选查询之间的成对比较来分配分数。利用这个智能体,我们为所有候选响应构建一个比较矩阵,并根据最高累积分数选择最终响应。通过将这些候选生成方法与提出的评分模型相结合,我们创建了一种集成方法,该方法利用每种策略的优势来显著提高整体性能。
表1:在BIRD开发集上评估单查询生成与自一致性集成方法,以及使用Gemini 1.5 Pro进行文本到SQL转换所能达到的上限。EX代表执行准确率。
| 方法 | 提取率(EX (%)) |
| 单查询 | 63.01 |
| 自一致性 | 68.84 (+ 5.84) |
| 上限 | 82.79 (+ 19.78) |
我们对CHASE - SQL提出的方法的有效性进行了全面评估。与传统的通用思维链(Chain of Thought,CoT)提示相比,我们创新的候选生成方法表现更优,这表明它们能够引导大语言模型(LLMs)将复杂问题分解为易于处理的中间步骤。此外,所提出的选择代理明显优于传统的基于一致性的方法,有助于取得最先进的成果。具体而言,在具有挑战性的BIRD文本到SQL数据集的开发集和测试集上,CHASE - SQL的执行准确率分别达到了 73.01 % \mathbf{{73.01}\% } 73.01% 和 73.0 % \mathbf{{73.0}\% } 73.0% ,大幅超越了该基准上所有已发表和未公开的方法。
2 相关工作
早期的文本到SQL(Text-to-SQL)方法主要采用序列到序列(sequence-to-sequence)架构,使用图神经网络(Graph Neural Networks,GNNs)、循环神经网络(Recurrent Neural Networks,RNNs)、长短期记忆网络(Long Short-Term Memory,LSTM)和预训练的Transformer编码器等模型对用户查询和数据库模式进行编码(蔡等人,2021年;曹等人,2021年;黄等人,2019年)。在解码方面,这些系统采用插槽填充或自回归建模方法,从编码输入构建最终的SQL查询(崔等人,2021年;王等人,2019年)。此外,还开发了如TaBERT(尹等人,2020年)、TaPas(赫尔齐格等人,2020年)和Grappa(余等人,2020年)等表格语言模型,以有效编码表格和文本数据。然而,随着大语言模型(LLMs)的广泛使用,情况发生了变化,大语言模型凭借其卓越的性能在很大程度上取代了早期的方法(卡索吉安尼斯 - 梅马拉基斯和库特里卡,2023年;夸马尔等人,2022年)。最初,人们致力于优化这些大语言模型的提示设计(董等人,2023年;高等人,2023年;波雷扎和拉菲埃,2024a)。随后的进展引入了更复杂的方法,包括模式链接(李等人,2024b;波雷扎和拉菲埃,2024a、b;塔莱伊等人,2024年)、自我修正或自我调试(陈等人,2023年;塔莱伊等人,2024年;王等人,2023年)以及自我一致性技术(李等人,2024年;马马里等人,2024年;孙等人,2023年;塔莱伊等人,2024年),通过提出复杂的基于大语言模型的流程进一步提高了性能。
3 种方法
3.1 总体框架
本节概述了所提出的 CHASE - SQL(追逐 - 结构化查询语言)框架,该框架由四个主要组件组成:1) 值检索,2) 候选查询生成器,3) 查询修复器,以及 4) 选择代理。如图 1 所示。所提出的框架首先检索相关的数据库值。随后,所有上下文信息,包括检索到的值、数据库元数据和模式,都会提供给大语言模型(LLM)以生成候选查询。这些候选查询随后会经过一个修复循环,最后,使用经过训练的选择代理以两两比较的方式对所有候选查询进行比较,从而选出正确答案。以下各节将深入探讨每个组件的细节。

图 1:所提出的用于文本到结构化查询语言(Text - to - SQL)的 CHASE - SQL 框架概述,包括值检索,并使用选择代理从生成的候选查询中更好地挑选答案,同时使用修复器为输出的优化提供反馈。
3.2 值检索
数据库可能包含大量的行,而通常只有少数行与查询相关。检索相关值至关重要,因为它们可用于各种SQL子句,如“WHERE”和“HAVING”。与(塔莱伊等人,2024年)的方法类似,我们首先使用经过少样本示例提示的大语言模型(LLM)从给定问题中提取关键词。对于每个关键词,我们采用局部敏感哈希(LSH)(达塔尔等人,2004年)来检索语法上最相似的单词,并根据基于嵌入的相似度和编辑距离对它们进行重新排序。这种方法对问题中的拼写错误具有鲁棒性,并在检索过程中考虑了关键词的语义。
3.3 多路径候选生成
如表1所示,仅依赖回复之间的一致性可能会导致性能欠佳。因此,我们在生成多个回复候选时优先考虑多样性,以增加至少生成一个正确答案的可能性。在候选生成器生成的多样化回复中,我们使用一个选择代理通过两两比较候选回复来选择一个作为最终回复。为了生成多样化的回复,我们提高了下一个标记的采样温度,并打乱了提示中列和表的顺序。
思维链(Chain-of-Thought,CoT)提示法(Wei等人,2022年)已被提出,旨在通过让大语言模型(LLMs)的最终回答基于逐步的推理链,来增强其推理能力。大多数CoT提示法依赖于提示中的少量示例,以引导大语言模型逐步思考,遵循格式 M = ( q i , r i , s i ) M = \left( {{q}_{\mathrm{i}},{r}_{\mathrm{i}},{s}_{\mathrm{i}}}\right) M=(qi,ri,si) ,其中 q i {\mathrm{q}}_{\mathrm{i}} qi 是示例问题, r i {\mathrm{r}}_{\mathrm{i}} ri 是推理路径, s i {\mathrm{s}}_{\mathrm{i}} si 是 q i {\mathrm{q}}_{\mathrm{i}} qi 的真实SQL查询。我们采用了两种不同的推理方法和一种在线合成示例生成方法。如图3a所示,不同的生成器可能会产生不同的输出,这表明它们对于特定的问题和数据库是有效的。
分治思维链(Divide and Conquer CoT):分治视角意味着将复杂问题分解为较小的子问题,分别解决每个子问题,然后合并这些解决方案以获得最终答案。据此,我们提出了一种思维链提示方法,该方法首先使用伪SQL查询将给定问题分解为较小的子问题。在“攻克”步骤中,将这些子问题的解决方案进行汇总以构建最终答案。最后,对构建好的查询应用优化步骤,以去除冗余的子句和条件。这种方法在处理涉及嵌套查询的复杂场景时特别有效,例如复杂的WHERE或HAVING条件,以及需要高级数学运算的查询。在附录图17中,我们给出了一个问题及其对应的SQL查询示例,该问题使用此生成器成功解决,而本文中考虑的其他方法由于查询的复杂条件和SQL子句无法处理该场景。有关分治提示的更详细信息,请参阅附录图16。此外,算法1概述了使用单次大语言模型(LLM)调用生成最终SQL输出的此策略的详细步骤。

查询计划思维链(Query Plan CoT):查询(执行)计划是数据库引擎为访问或修改SQL命令所描述的数据而遵循的一系列步骤。当执行SQL查询时,数据库管理系统的查询优化器会将SQL文本转换为数据库引擎可以执行的查询计划。该计划概述了如何访问表、如何进行表连接以及对数据执行的具体操作(以附录图19为例)。受数据库引擎执行SQL查询的逐步过程的启发,我们提出了一种推理策略来构建最终的SQL输出。可以使用“EXPLAIN”命令获取任何给定SQL查询的查询计划,该命令会详细分解执行步骤。然而,这种输出通常以大语言模型(LLM)难以解释的格式呈现(例如在SQLite中)。为了解决这个问题,我们将“EXPLAIN”命令的输出转换为更符合大语言模型预训练数据的人类可读文本格式。查询计划的人类可读版本包括三个关键步骤:(1)识别并定位与问题相关的表;(2)在表之间执行计数、过滤或匹配等操作;(3)通过选择合适的列来返回最终结果。这种推理方法补充了分治思维链策略。虽然分治方法更适合分解复杂问题,但当问题需要对问题的不同部分与数据库模式之间的关系进行更多推理时,查询计划方法表现出色。它系统地解释了要扫描哪些表、如何匹配列以及如何应用过滤器。附录图20展示了一个仅通过这种方法正确回答问题的示例。附录图18提供了用于此推理策略的提示。
在线合成示例生成:使用 M M M 个示例进行少样本上下文学习在各种相关任务中已显示出有前景的结果(普尔雷扎(Pourreza)和拉菲伊(Rafiei),2024a)。除了有助于明确任务并展示推导输出的逐步过程外,使用相关表格和列构建的示例还可以帮助模型理解底层数据模式。基于这一见解,我们提出了一种用于文本到SQL的合成示例生成策略——给定用户问题 Q u {Q}_{u} Qu 、目标数据库 D D D 和选定的列 t i {t}_{i} ti (使用类似于(塔莱伊(Talaei)等人, 2024 ) ) {2024})) 2024)) )的列选择方法。

算法2概述了具有两个大语言模型(LLM)生成步骤的在线合成示例生成方法。第一步侧重于根据指南 R f {R}_{f} Rf 中描述的常见SQL特性生成说明性示例。这些SQL特性包括相等和不相等谓词、单表和多表连接(JOIN)、嵌套连接(JOIN)、排序(ORDER BY)和限制(LIMIT)、分组(GROUP BY)和筛选(HAVING)以及各种聚合函数。这些都是广泛应用的SQL子句和函数——生成的示例SQL查询包含这些特性,遵循BIRD SQL特性分布(附录图23a)。第二步侧重于生成突出对底层数据模式正确解释的示例——要求模型 θ \theta θ 使用 t i {t}_{i} ti 生成与 R t {R}_{t} Rt 中概述的示例类似的示例。附录A.10提供了用于示例生成的提示。
虽然一个相关示例(例如展示一个涉及多个表的嵌套JOIN查询)对于需要复杂JOIN查询的问题可能会有帮助,但过度使用它也可能会误导大语言模型(LLM)(例如,当一个简单的单表查询就足够时)。这一点以及自然语言查询 q i {q}_{i} qi 固有的歧义性(我们根据相关性选取示例),使得示例选择颇具挑战性。因此,我们针对每个 q i {q}_{i} qi 在线生成示例并将其注入到提示中。我们要求大语言模型生成许多输入 - 输出对用于上下文学习。针对 q i {q}_{i} qi 的最终合成示例集包含使用 R f {R}_{f} Rf 和 R t {R}_{t} Rt 生成的示例。这确保了示例集在SQL特性/子句以及相关表/列的选择上都具有多样性。示例集的多样性有助于避免输出过度拟合某些模式(例如,如果展示的大多是JOIN示例,模型就总是编写带有JOIN的SQL语句)。观察发现,将各种SQL特性的示例以及有无列过滤的数据库表示例混合起来,总体上能产生更好的生成质量(请参阅附录表8)。
3.4 查询修复器
在某些情况下,大语言模型(LLMs)可能会生成语法错误的查询。这些查询显然需要修正,因为它们无法提供正确答案。为了解决这个问题,我们采用了基于大语言模型的查询修复器,该修复器利用自我反思(Shinn等人,2024)方法。修复器会对之前生成的查询进行反思,利用语法错误细节或空结果集等反馈来指导修正过程。我们会持续采用这种迭代修复方法,直至达到指定的尝试次数, β \beta β (本文中设定为三次)。附录图21展示了此查询修复步骤所使用的提示词。
3.5 选择代理
通过三种不同的生成SQL查询的方法,我们可以为任何给定的问题生成一组候选查询。此步骤的关键挑战在于从这组候选查询中选择正确的SQL查询。一种简单的方法是通过执行候选查询来衡量它们之间的一致性,根据执行结果对它们进行分组,并从最大的组中选择一个查询作为最可能正确的答案。然而,这将假设最一致的答案总是最好的答案,但实际情况并非总是如此。相反,我们提出了一种更精细的选择策略,即算法3,它依赖于一个选择代理。给定一组候选SQL查询 C = { c 1 , c 2 , … , c n } C = \left\{ {{c}_{1},{c}_{2},\ldots ,{c}_{n}}\right\} C={c1,c2,…,cn} ,通过找到由选择模型赋予最高分数的候选查询来选择最终响应。该模型 θ p {\theta }_{p} θp 可以接收 k k k 个候选查询,并根据每个查询回答给定问题的准确程度对它们进行排序。具体来说,我们将最终响应的选择公式化为: c f = arg max c ∈ C ( ∑ i = 1 ( n k ) θ p ( c i 1 , … , c i k ∣ Q u , H u , D ) ) , (1) {c}_{f} = \arg \mathop{\max }\limits_{{c \in C}}\left( {\mathop{\sum }\limits_{{i = 1}}^{\left( \begin{array}{l} n \\ k \end{array}\right) }{\theta }_{p}\left( {{c}_{{i}_{1}},\ldots ,{c}_{{i}_{k}} \mid {Q}_{u},{H}_{u}, D}\right) }\right) , \tag{1} cf=argc∈Cmax i=1∑(nk)θp(ci1,…,cik∣Qu,Hu,D) ,(1) 其中 Q u {Q}_{u} Qu 指用户的问题, H u {H}_{u} Hu 是提供的提示, D D D 是提出问题所依据的目标数据库。在公式 1 中,我们将 k k k 个候选对象传递给选择模型进行排序, k k k 的取值范围在 1 到 n n n 之间。在 k = 1 k = 1 k=1 的极端情况下,模型无法对候选对象进行比较,这使得模型的评估过程变得复杂。随着 k k k 的增加,比较更多的候选对象会让模型面临更大的挑战,因为它需要同时考虑不同的方面。因此,我们设置 k = 2 k = 2 k=2 并训练一个具有分类目标的模型,以便每次仅比较两个候选对象。
在拥有一组高质量且多样化的候选对象后,最直接的解决方案是使用现成的大语言模型(LLM)进行两两选择。然而,对Gemini - 1.5 - pro(双子座1.5专业版)的实验表明,在未进行微调的情况下使用大语言模型,二元分类准确率仅为 58.01 % {58.01}\% 58.01% 。这主要是因为候选对象彼此非常相似,需要一个经过微调的模型来学习其中的细微差别并做出更准确的决策。为了训练选择代理,我们首先在训练集(文本到SQL基准测试集)上生成候选SQL查询,并根据它们的执行结果将其分组。对于至少有一个簇包含正确查询而其他簇包含错误查询的情况,我们以元组 ( Q u , C i , C j , D i j , y i j ) \left( {{Q}_{u},{C}_{i},{C}_{j},{D}_{ij},{y}_{ij}}\right) (Qu,Ci,Cj,Dij,yij) 的形式创建训练示例,其中 Q u {Q}_{u} Qu 是用户的问题, C i {C}_{i} Ci 和 C j {C}_{j} Cj 是正在比较的两个候选查询, D i j {D}_{ij} Dij 是两个候选查询所使用的数据库模式, y i j ∈ 0 , 1 {y}_{ij} \in 0,1 yij∈0,1 是指示 C i {C}_{i} Ci 或 C j {C}_{j} Cj 是否为正确查询的标签。为了避免训练过程中的顺序偏差,我们随机打乱每对中正确和错误查询的顺序。由于同时存在正确和错误候选对象的情况数量有限,对于不存在正确候选对象的实例,我们在提示中加入真实的SQL查询作为提示,以引导模型生成正确的候选对象。

4 实验
4.1 数据集和模型
我们在两个广泛认可的跨领域数据集上评估了所提出的CHASE - SQL框架的性能:BIRD(李等人,2024c)和Spider(余等人,2018)。BIRD包含来自95个大型数据库的超过12751个独特的问题 - SQL对,涵盖37个以上的专业领域,这些数据库的设计类似于现实场景,具有杂乱的数据行和复杂的模式。Spider包含来自200个数据库的10181个问题和5693个独特的复杂SQL查询,涵盖138个领域。与BIRD类似,Spider数据集也被划分为不重叠的训练集、开发集和测试集。对于这两个数据集,我们使用执行准确率(EX),即各自排行榜的官方指标,作为比较不同方法的主要评估指标。模型及其超参数的详细信息见附录A.2节。
4.2 BIRD结果
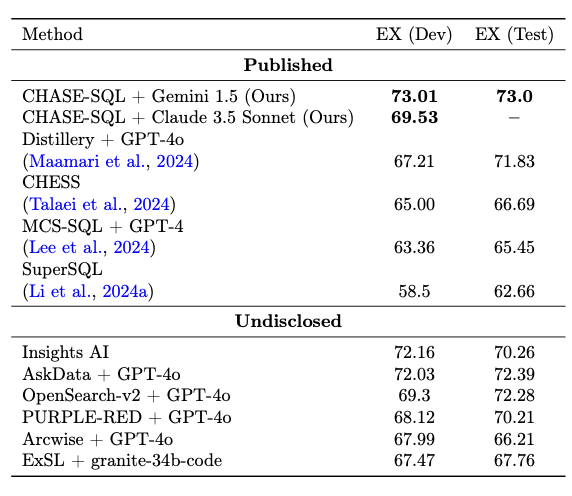
我们展示了所提出的CHASE - SQL框架在BIRD开发集上使用Claude - 3.5 - sonnet和Gemini 1.5 pro,以及在BIRD测试集上使用Gemini 1.5 pro的端到端文本转SQL性能。我们将其与已发表的方法(有可用代码库和/或论文的方法)和未公开的方法进行了比较。为了与Gemini 1.5 pro进行公平比较,Claude - 3.5 - sonnet设置中的所有大语言模型(LLM)调用(选择模型除外)均使用Claude - 3.5 - sonnet进行(重用之前训练的选择模型)。如表2所示,使用Gemini 1.5 pro的CHASE - SQL在BIRD开发集上的准确率达到73.01%,在BIRD保留测试集上达到73.0%,超越了所有先前的工作,创造了新的最优性能。
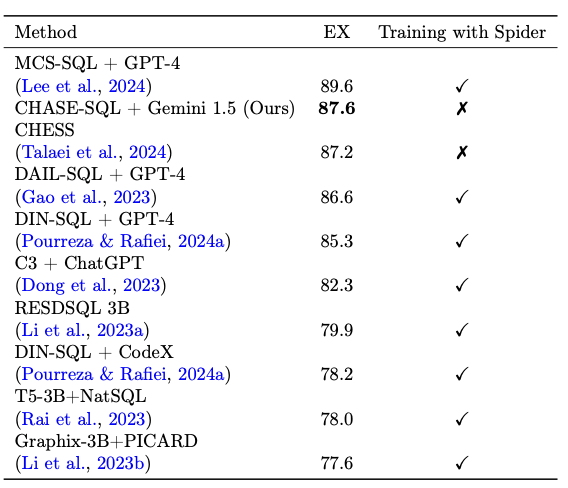
表2:不同文本转SQL方法的性能比较 表3:不同文本转SQL方法的性能比较
在BIRD基准测试上的方法。
蜘蛛(Spider)测试集上的方法。
4.3 蜘蛛数据集(Spider)测试结果
我们通过在蜘蛛数据集(Spider)的测试集上以端到端的方式评估所提出的CHASE - SQL(追逐 - 结构化查询语言),来评估其泛化能力,过程中不修改提示中的小样本示例,也不训练新的选择模型,即不使用目标分布中的任何数据。这种方法使我们能够与训练分布数据进行对比,测试CHASE - SQL在不同的未见查询和数据库分布上的性能。表3显示,CHASE - SQL在蜘蛛数据集(Spider)测试集上的执行准确率达到了 87.6 % {87.6}\% 87.6% ,在针对蜘蛛数据集(Spider)进行了特定训练或提示优化的方法中排名第二。这凸显了CHASE - SQL强大的泛化能力,以及它为来自截然不同分布且具有独特挑战的未见样本生成高质量文本到结构化查询语言(Text - to - SQL)的潜力。
4.4 生成器和选择器性能
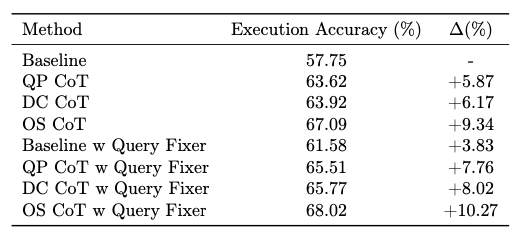
生成器 + 修正器:为了揭示生成器的性能,我们进行了一项消融研究,以评估在应用查询修正器前后每种候选生成方法的性能。我们将所提出的生成器在生成单个候选查询方面的性能与原始的 BIRD 提示(李等人,2024c)进行了比较,该提示结合了零样本思维链推理(小岛等人,2022),作为评估提示质量的基线。表 4 所示的结果表明,与简单基线相比,所提出的方法显著提高了 SQL 生成性能,朝着生成高质量候选并保持多样性的目标迈进。在候选生成器中,在线合成数据生成方法取得了令人印象深刻的 68.02 % {68.02}\% 68.02% 性能,证明了其通过生成高质量合成示例利用测试时计算来提高大语言模型(LLM)性能的有效性。此外,查询修正器被证明至关重要,它提高了候选池的质量,并使所有候选生成器的性能提高了近 2 % 2\% 2% 。
表4:在BIRD开发集上,与使用Gemini 1.5 pro的原始BIRD提示 + 零样本思维链(zero-shot CoT)相比,各候选生成器的单候选生成性能消融研究。选择器(Selector)是我们将选择代理应用于所有生成器生成的21个候选结果后得到的最终性能。
选择:我们对选择代理在成对比较中一个候选正确而另一个候选错误的情况下的二元选择准确性进行了分析。我们排除了两个候选都正确或都错误的情况,因为在这种情况下,由于两个候选具有相同的标签,选择不会影响结果。我们将Claude - 3.5 - sonnet和Gemini - 1.5 - pro(两者均为未微调的开箱即用模型)的性能与两个微调模型进行了比较:1)Gemma 2 9B和2)Gemini - 1.5 - flash。如表5所示,两个微调模型的准确率都高于未微调的对应模型,这表明微调对于让模型了解特定偏好的重要性。
表5:评估不同选择模型的二元选择准确性。

候选生成分析:我们分别分析了每种候选生成器方法的性能。为了更好地理解从候选池中有效选择正确SQL查询时的性能潜力,我们为BIRD开发集中的所有样本从每种生成器方法生成了七个候选SQL查询(总共21个候选查询)。我们根据观察确定候选数量,即如图2d所示,将候选池增加到20个以上并不会带来显著的性能提升。通过假设可以使用一个神谕选择模型(oracle selection model),该模型总是能从七个候选查询中选择正确的SQL查询,我们计算出每种生成器可达到的上限性能。相反,通过假设一个对抗选择模型(adversarial selection model),该模型总是选择错误的SQL查询,我们确定了下限性能。图2展示了所有三种方法的上限和下限性能,以及我们的选择代理的性能。如图所示,对于不同数量的候选查询,两种不同的思维链(Chain of Thought,CoT)方法的上限性能通常高于合成示例生成方法。然而,它们的下限性能也低于合成方法。下限准确率反映了所有候选查询都正确的情况,这减少了选择过程中的噪声,因为选择哪个候选查询并不重要,所以下限越高越好。这在选择代理的性能中很明显,当下限下降时,提高上限带来的收益会逐渐减少,导致选择代理的性能趋于平稳。此外,结合所有三种方法的上限性能达到了 82.79 % \mathbf{{82.79}\% } 82.79% ,这凸显了通过更好的候选选择方法有很大的改进空间。这表明大语言模型(Large Language Model,LLM)的参数知识已经包含了解决大多数问题所需的信息,强调了需要采用集成方法来有效提取和利用这些知识。
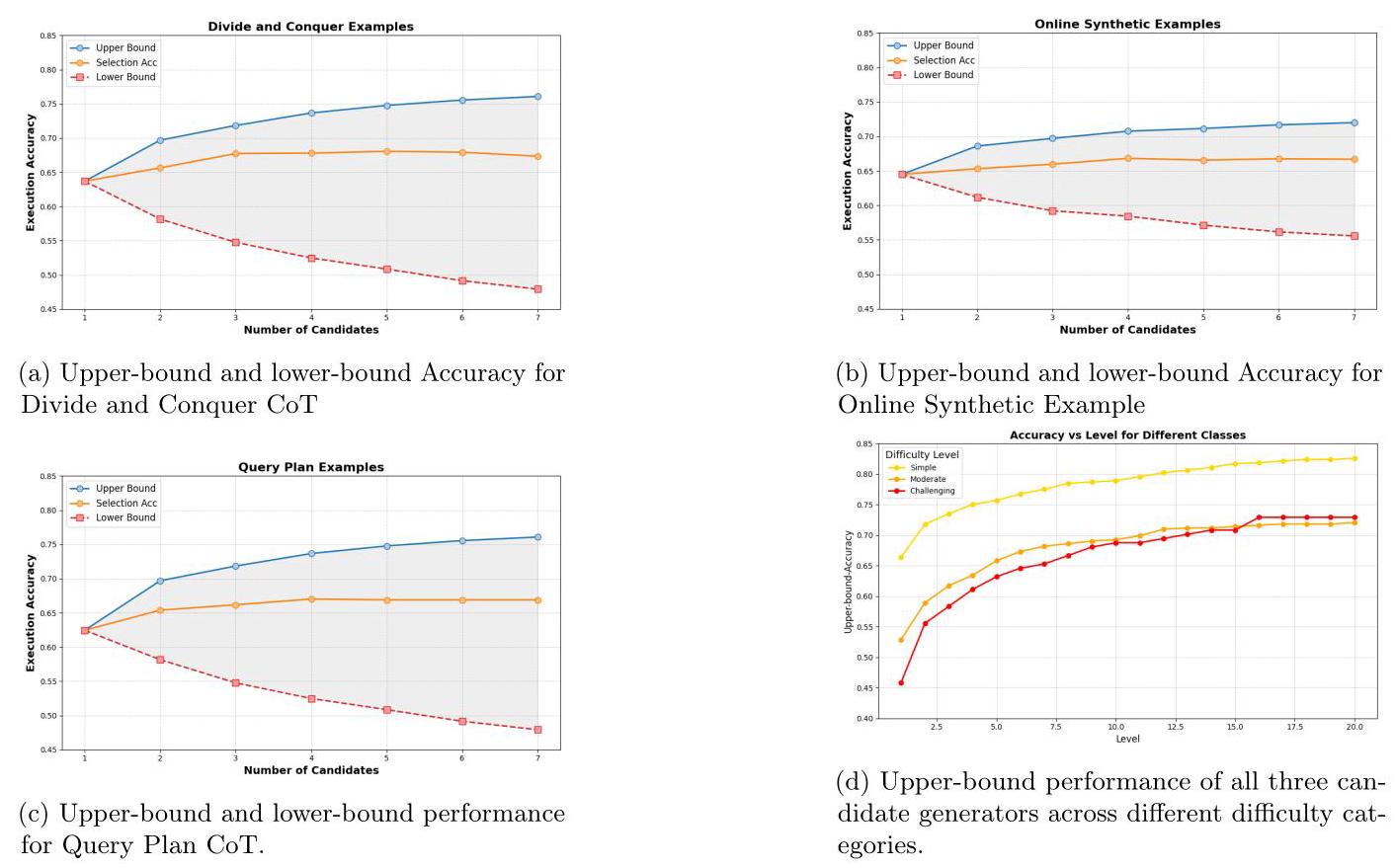
图2:不同候选生成器的上限和下限性能比较。
此外,我们通过结合来自三种候选生成方法的所有候选,对BIRD开发集的简单、中等和具有挑战性的难度级别进行上限性能评估。这些难度类别是人类专家在创建BIRD开发集时划分的。图2d显示,正如预期的那样,在所有难度级别上,上限性能随候选数量的增加而提高。然而,对于具有挑战性和中等难度的类别,其性能提升比简单类别更早达到平稳,这表明为这两个难度级别生成更多样本并不能进一步提高上限性能。
图2展示了一个维恩图,展示了三种生成方法的性能:查询计划(Query Plan)、分治法(Divide and Conquer)和使用合成示例法。相交区域内的数字表示多种方法至少生成了一个正确候选的实例。该图直观地突出了每种方法的独特贡献,这表明有必要使用这三种生成器。此外,在图3b中,我们比较了每种SQL生成方法生成的、而其他生成器未生成的正确查询的数量。在具有挑战性的问题上,分治法的表现优于其他方法,而查询计划方法在中等难度的查询上表现出色。为了进一步分析生成器在不同领域以及不同列数和表数情况下的性能,我们比较了每个数据库生成的正确查询的数量,如附录图4所示。如图所示,两种思维链(CoT)方法在各个数据库中的表现总体相似,而在线合成示例生成方法显著增加了多样性,从而在不同数据库中总体上产生了更多的正确答案。
选择代理分析:我们通过比较选择代理的文本到SQL执行准确率与自一致性方法(使用多数投票)(Wang等人,2022年)、神谕模型(上限)和对抗模型(下限)来评估查询选择性能。为了进行评估,我们使用两种不同的采样温度(0.5和1.8)从每个候选生成方法中生成10个样本。如表6所示,结果表明选择代理明显优于自一致性方法,领先幅度约为6%。正如预期的那样,提高采样温度会提高上限,但也会降低下限。与两种思维链(CoT)方法相比,这种影响在合成数据生成方法中更为明显,主要是因为大语言模型(LLMs)在生成最终SQL查询之前会先生成推理步骤,这有助于减轻高温采样引入的随机性。随着温度升高,自一致性方法的性能通常会下降,因为随着更多随机查询的出现,多数集群会变小。然而,所提出的经过训练的选择代理受温度缩放的影响较小,在两种情况下,甚至通过更多样化的样本池提高了其性能。
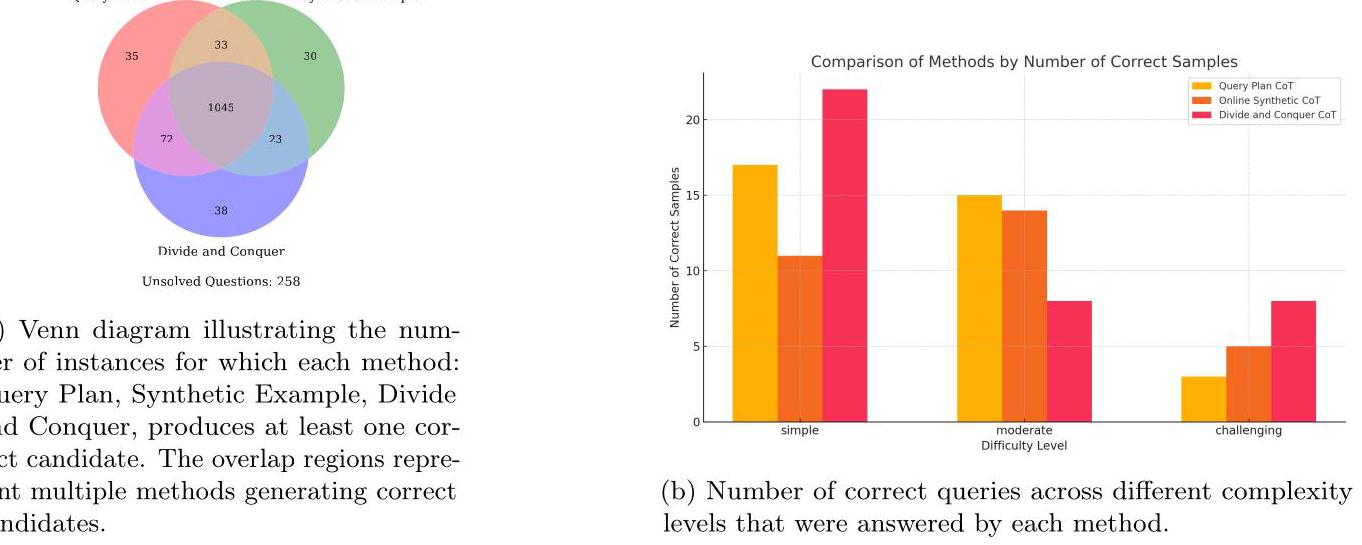
图3:SQL生成方法的比较:维恩图展示了独特的和重叠的正确答案(左)以及不同复杂度水平下的性能(右)。
表6:在BIRD开发集上,候选生成器生成的候选对象采用不同挑选方法在两种不同温度下的性能比较。QP指查询计划思维链(query plan COT),DC指分治思维链(divide and conquer COT),OS是在线合成示例生成方法。

4.5 消融研究
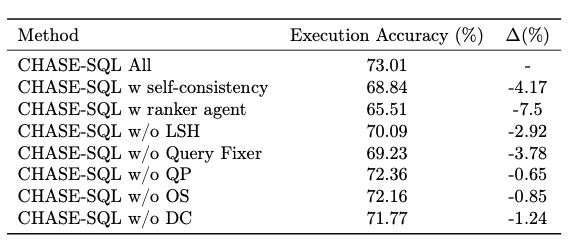
在前面的章节中,我们评估了选择代理和每种候选生成方法的重要性。接下来,我们将重点分析CHASE - SQL其余组件的作用:用于值检索的局部敏感哈希(LSH,Locality - Sensitive Hashing)、查询修复器以及三种推理策略(QP、OS和DC)。表7展示了CHASE - SQL在去掉每个步骤后的性能,凸显了它们在实现更高质量性能方面的重要性。结果表明了每个组件的贡献,去掉LSH、查询修复器或任何候选生成器都会导致执行准确率下降,这进一步验证了CHASE - SQL这些组件的重要性。此外,该表还将我们的二元选择代理的性能与另外两种选择方法进行了比较:自一致性方法(Wang等人,2022)和排序代理。排序代理在单个提示中接收我们的三个候选生成器生成的所有候选,并对它们进行比较,然后为每个候选生成一个排名。对于排序代理,我们选择排名最低的查询作为最佳答案。二元选择代理的表现明显优于自一致性方法和排序代理,证明了所提出方法的有效性。
5 结论
我们引入了一个新颖的智能体框架CHASE - SQL,以利用测试时计算来生成多样化、高质量的SQL查询,并准确选择正确的查询。我们提出了多种思维链提示方法和一种在线合成示例生成技术,以及一种基于成对比较对候选查询进行评分的查询选择机制。我们的框架CHASE - SQL在著名的公共文本到SQL排行榜(在提交时)上创造了新的最优成绩,证明了测试时计算在生成多样化查询和选择最准确响应方面的有效性。CHASE - SQL解决了查询多样性和选择优化等关键问题,为应对现实世界文本到SQL挑战中遇到的复杂推理任务的进一步改进铺平了道路。
表7:移除查询修复器、用于值检索的局部敏感哈希(LSH)和推理策略(即QP、OS和DC)后,CHASE - SQL性能的消融研究。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











