







 本文探讨了在Hadoop中文件压缩的原因和常见压缩格式,包括Snappy、LZ4、LZO、GZIP和BZIP2的压缩比、时间成本。在Hive中,针对MapReduce的不同阶段,应选择合适的压缩方式。例如,中间结果推荐使用Snappy压缩以减少IO影响,最终输出可选择BZip2以获得高压缩比。文章还详细介绍了Hive的压缩配置参数,如hive.exec.compress.output和mapred.output.compression.codec,并提到了配置文件的区别。
本文探讨了在Hadoop中文件压缩的原因和常见压缩格式,包括Snappy、LZ4、LZO、GZIP和BZIP2的压缩比、时间成本。在Hive中,针对MapReduce的不同阶段,应选择合适的压缩方式。例如,中间结果推荐使用Snappy压缩以减少IO影响,最终输出可选择BZip2以获得高压缩比。文章还详细介绍了Hive的压缩配置参数,如hive.exec.compress.output和mapred.output.compression.codec,并提到了配置文件的区别。
概述
为什么会出现需要对文件进行压缩?
在Hadoop中,文件需要存储、传输、读取磁盘、写入磁盘等等操作,而文件的大小,直接决定了这些这些操作的速度。常见压缩方式、压缩比、压缩解压缩时间、是否可切分
原文件:1403M
Snappy 压缩:701M,压缩时间:6.4s,解压时间:19.8s,不可切分
LZ4 压缩:693M,压缩时间:6.4s,解压时间:2.36s,不可切分
LZO 压缩:684M,压缩时间:7.6s,解压时间:11.1s,带序号可切分
GZIP 压缩:447M,压缩时间:85.6s,解压时间:21.8s,不可切分
BZIP2:压缩:390M,压缩时间:142.3s,解压时间:62.5s,可切分
总结:压缩比和压缩时间成反比,压缩比越小,耗费时间越大
两个矛盾:
耗费CPU、时间与存储空间、传输速度、IO的矛盾
压缩比与压缩、解压缩时间的矛盾
ps:追求合适场景使用合适方式图解MapReduce
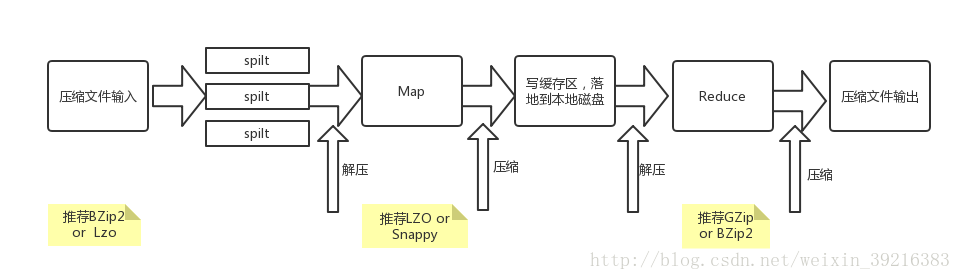
1.第一次传入压缩文件,应选用可以切片的压缩方式,否则整个文件将只有一个Map执行
2.第二次压缩应选择压缩解压速度快的压缩方式
3.第三次压缩有两种场景分别是:一.当输出文件为下一个job的输入,选择可切分的压缩方式例如:BZip2。二.当输出文件直接存到HDFS,选择压缩比高的压缩方式。
hive参数
hive.exec.compress.output 设置是否压缩
mapreduce.output.fileoutputformat.compress.codec 设置压缩Reduce类型输出
hive.intermediate.compression.codec 设置中间Map压缩类型
可选类型:
org.apache.hadoop.io.compress.DefaultCodec
org.apache.hadoop.io.compress.GzipCodec
org.apache.hadoop.io.compress.BZip2Codec
com.hadoop.compression.lzo.LzoCodec
org.apache.hadoop.io.compress.Lz4Codec
org.apache.hadoop.io.compress.SnappyCodec
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec
</value>
</property>
mapred-site.xml switch+codec
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
2) 第二种方式 在 hive 客户端代码层实现
mapreduce.map.output.fileoutputformat.compress
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;
create table page_views_bzip2
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
as select * from page_views;
create table page_views_snappy
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
as select * from page_views;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2360
2360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









