






 本文介绍了回归问题的概念,以线性回归为例,解释了如何通过梯度下降法和最小二乘法进行曲线拟合。接着,讨论了神经网络的起源、数学模型以及激活函数的作用,特别强调了Sigmoid和双曲正切函数。最后,概述了前馈神经网络(BP神经网络)的工作原理,包括误差反向传播算法和权重更新的过程,以及BP神经网络的特点和局限性。
本文介绍了回归问题的概念,以线性回归为例,解释了如何通过梯度下降法和最小二乘法进行曲线拟合。接着,讨论了神经网络的起源、数学模型以及激活函数的作用,特别强调了Sigmoid和双曲正切函数。最后,概述了前馈神经网络(BP神经网络)的工作原理,包括误差反向传播算法和权重更新的过程,以及BP神经网络的特点和局限性。
回归问题:让机器观察并总结出一些有代表性的特征,然后根据这些特征对某种事物进行分类或预测。
可是计算机只能认识一堆数字,因此要让机器从事物的特征中找到规律,其实是一个如何在数字中找规律的问题。
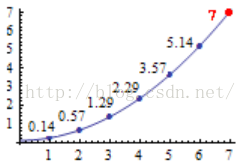
假如:有一串数字,前六个是0.14、0.57、1.29、2.29、3.57、5.14,请问第七个是几?我们把这几个数字在坐标轴上标识一下,可以看到如下图形:
由此可见,回归问题其实是个
曲线拟合(Curve Fitting)
问题。
先随意画一条直线,然后不断旋转它。每转一下,就计算一下每个样本点和直线上对应点的距离(误差),求出所有点的误差之和。这样不断旋转,当误差之和达到最小时,停止旋转。说得再复杂点,在旋转的过程中,还要不断平移这条直线,这样不断调整,直到误差最小时为止。这种方法就是梯度下降法(Gradient Descent)。为什么是梯度下降呢?在旋转的过程中,当误差越来越小时,旋转或移动的量也跟着逐渐变小,当误差小于某个很小的数时,我们就可以收工(收敛, Converge)了。梯度下降法的实质是不断的修改k、b这两个参数值,使最终的误差达到最小。

求误差时使用 累加(直线点-样本点)^2,这样比直接求差距 累加(直线点-样本点) 的效果要好。这种利用最小化误差的平方和来解决回归问题的方法叫最小二乘法(Least Square Method)。
我们根据拟合直线不断旋转的角度(斜率)和拟合的误差画一条函数曲线,如图:
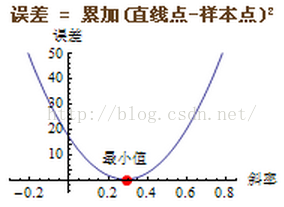
如果能求出曲线上每个点的切线,就能得到切线位于水平状态时时的坐标值,这个坐标值就是我们要求的误差最小值和最终的拟合直线的最终斜率。
这样,梯度下降的问题集中到了切线的旋转上。切线旋转至水平时,切线斜率=0,误差降至最小值。
这样,梯度下降的问题集中到了切线的旋转上。切线旋转至水平时,切线斜率=0,误差降至最小值。
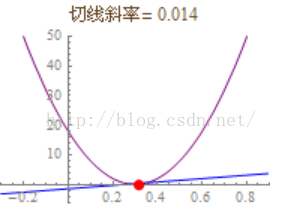
切线每次旋转的幅度叫做
学习率(Learning Rate)
,加大学习率会加快拟合速度,但是如果调得太大会导致切线旋转过度而无法收敛。
注意:对于凹凸不平的误差函数曲线,梯度下降时有可能陷入局部最优解。下图的曲线中有两个坑,切线有可能在第一个坑的最底部趋于水平。

微分就是专门求曲线切线的工具,求出的切线斜率叫做导数(Derivative),用dy/dx或f'(x)表示。扩展到多变量的应用,如果要同时求多个曲线的切线,那么其中某个切线的斜率就叫偏导数(Partial Derivative),用∂y/∂x表示,∂读“偏(partial)”。
以上是
线性回归(Linear Regression)
的基本内容,以此方法为基础,把直线公式改为曲线公式,还可以扩展出二次回归、三次回归、多项式回归等多种曲线回归。
当使用二次曲线和多变量(多维)拟合的情况下,特征的数量会剧增,一张50*50像素的灰度图片,如果用二次多项式拟合的话,它有2500*2500/2=3,125,000多少个特征。
于是,“
人工神经网络(ANN, Artificial Neural Network)
”就在这样苛刻的条件下粉墨登场了
下面是
单个神经元
的数学模型:
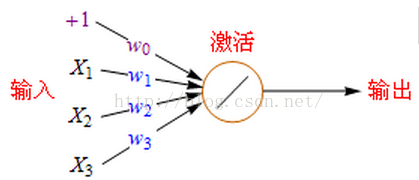
+1代表偏移值(偏置项, Bias Units);X1,X2,X2代表初始特征;w0,w1,w2,w3代表权重(Weight),即参数,是特征的缩放倍数;特征经过缩放和偏移后全部累加起来,此后还要经过一次激活运算然后再输出。激活函数有很多种,后面将会详细说明。
这个数学模型有什么意义呢?下面我对照前面那个 y=kx+b 直线拟合的例子来说明一下。
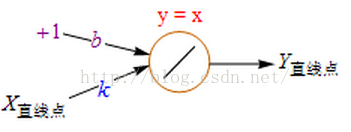
这时我们把激活函数改为
Purelin(45度直线)
,Purelin就是y=x,代表保持原来的值不变。
这样输出值就成了 Y = b + X*k,即y=kx+b。下一步,对于每个点都进行这种运算,利用Y直线点和Y样本点计算误差,把误差累加起来,不断地更新b、k的值,由此不断地移动和旋转直线,直到误差变得很小时停住(收敛)。这个过程完全就是前面讲过的梯度下降的线性回归。
这样输出值就成了 Y = b + X*k,即y=kx+b。下一步,对于每个点都进行这种运算,利用Y直线点和Y样本点计算误差,把误差累加起来,不断地更新b、k的值,由此不断地移动和旋转直线,直到误差变得很小时停住(收敛)。这个过程完全就是前面讲过的梯度下降的线性回归。
一般直线拟合的精确度要比曲线差很多,那么使用神经网络我们将如何使用曲线拟合?答案是使用非线性的激活函数即可,最常见的激活函数是Sigmoid(S形曲线),Sigmoid有时也称为逻辑回归(Logistic Regression),简称logsig。logsig曲线的公式如下:
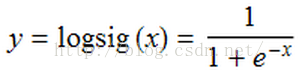
还有一种S形曲线也很常见到,叫
双曲正切函数(tanh)
,或称
tansig
,可以替代logsig。
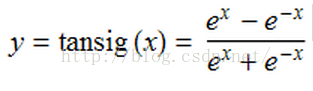
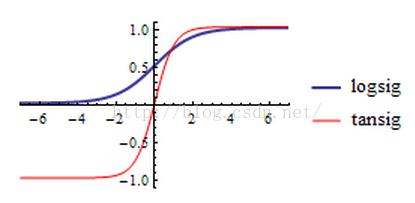
下面是它们的函数图形,从图中可以看出logsig的数值范围是0~1,而tansig的数值范围是-1~1。
融入了e的螺旋线,在不断循环缩放的过程中,可以完全保持它原有的弯曲度不变,就像一个无底的黑洞,吸进再多的东西也可以保持原来的形状。这一点至关重要!它可以让我们的数据在经历了多重的Sigmoid变换后仍维持原先的比例关系。
下图是几种比较常见的神经元的网络形式:
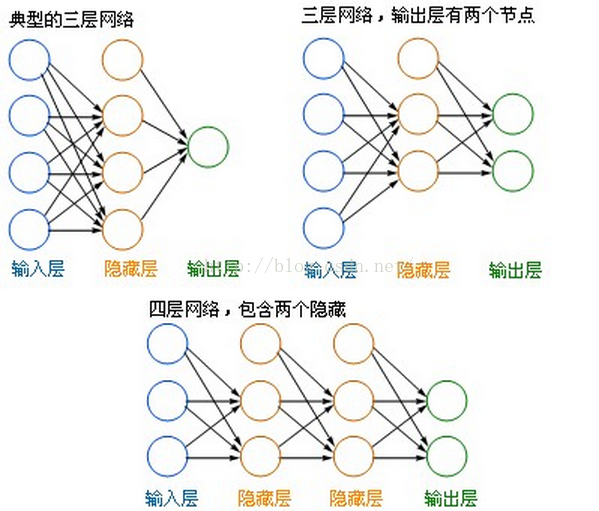
- 左边蓝色的圆圈叫“
输入层
”,中间橙色的不管有多少层都叫“
隐藏层
”,右边绿色的是“
输出层
”。
- 每个圆圈,都代表一个神经元,也叫 节点(Node) 。
- 输出层可以有多个节点,多节点输出常常用于分类问题。
- 理论证明,任何多层网络可以用三层网络近似地表示。
- 一般凭经验来确定隐藏层到底应该有多少个节点,在测试的过程中也可以不断调整节点数以取得最佳效果。
- 每个圆圈,都代表一个神经元,也叫 节点(Node) 。
- 输出层可以有多个节点,多节点输出常常用于分类问题。
- 理论证明,任何多层网络可以用三层网络近似地表示。
- 一般凭经验来确定隐藏层到底应该有多少个节点,在测试的过程中也可以不断调整节点数以取得最佳效果。
计算方法:
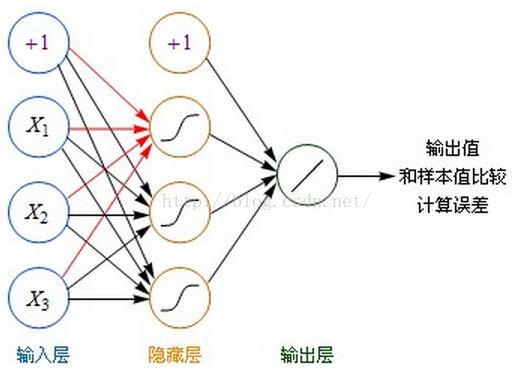
- 虽然图中未标识,但必须注意每一个箭头指向的连线上,都要有一个权重(缩放)值。
- 输入层的每个节点,都要与的隐藏层每个节点做点对点的计算,计算的方法是加权求和+激活,前面已经介绍过了。(图中的红色箭头指示出某个节点的运算关系)
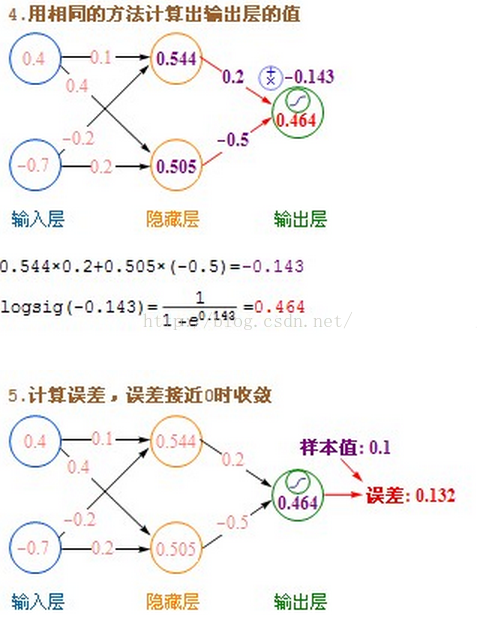
- 利用隐藏层计算出的每个值,再用相同的方法,和输出层进行计算。
- 隐藏层用都是用Sigmoid作激活函数,而输出层用的是Purelin。这是因为Purelin可以保持之前任意范围的数值缩放,便于和样本值作比较,而Sigmoid的数值范围只能在0~1之间。
- 起初输入层的数值通过网络计算分别传播到隐藏层,再以相同的方式传播到输出层,最终的输出值和样本值作比较,计算出误差,这个过程叫前向传播(Forward Propagation)。
- 输入层的每个节点,都要与的隐藏层每个节点做点对点的计算,计算的方法是加权求和+激活,前面已经介绍过了。(图中的红色箭头指示出某个节点的运算关系)
- 利用隐藏层计算出的每个值,再用相同的方法,和输出层进行计算。
- 隐藏层用都是用Sigmoid作激活函数,而输出层用的是Purelin。这是因为Purelin可以保持之前任意范围的数值缩放,便于和样本值作比较,而Sigmoid的数值范围只能在0~1之间。
- 起初输入层的数值通过网络计算分别传播到隐藏层,再以相同的方式传播到输出层,最终的输出值和样本值作比较,计算出误差,这个过程叫前向传播(Forward Propagation)。
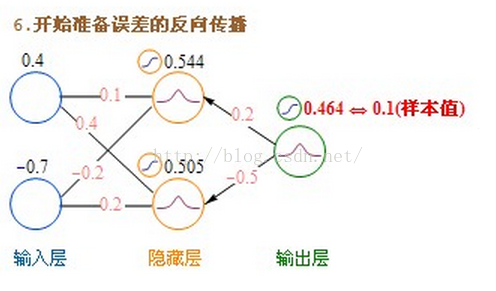
前面讲过,使用梯度下降的方法,要不断的修改k、b两个参数值,使最终的误差达到最小。神经网络可不只k、b两个参数,事实上,网络的每条连接线上都有一个权重参数,如何有效的修改这些参数,使误差最小化,成为一个很棘手的问题。从人工神经网络诞生的60年代,人们就一直在不断尝试各种方法来解决这个问题。直到80年代,误差反向传播算法(BP算法)的提出,才提供了真正有效的解决方案,使神经网络的研究绝处逢生。
BP算法是一种计算偏导数的有效方法,它的基本原理是:利用前向传播最后输出的结果来计算误差的偏导数,再用这个偏导数和前面的隐藏层进行加权求和,如此一层一层的向后传下去,直到输入层(不计算输入层),最后利用每个节点求出的偏导数来更新权重。

为了便于理解,后面我一律用“
残差(error term)
”这个词来表示
误差的偏导数
。
输出层→隐藏层:残差 = -(输出值-样本值) * 激活函数的导数
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 激活函数的导数
例如:如果输出层用Purelin作激活函数,Purelin的导数是1,输出层→隐藏层:残差 = -(输出值-样本值)
如果用Sigmoid(logsig)作激活函数,那么:Sigmoid导数 = Sigmoid*(1-Sigmoid)
输出层→隐藏层:残差 = -(Sigmoid输出值-样本值) * Sigmoid*(1-Sigmoid) = -(输出值-样本值)*输出值*(1-输出值)
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 当前节点的Sigmoid*(1-当前节点的Sigmoid)
如果用tansig作激活函数,那么:tansig导数 = 1 - tansig^2
输出层→隐藏层:残差 = -(输出值-样本值) * 激活函数的导数
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 激活函数的导数
例如:如果输出层用Purelin作激活函数,Purelin的导数是1,输出层→隐藏层:残差 = -(输出值-样本值)
如果用Sigmoid(logsig)作激活函数,那么:Sigmoid导数 = Sigmoid*(1-Sigmoid)
输出层→隐藏层:残差 = -(Sigmoid输出值-样本值) * Sigmoid*(1-Sigmoid) = -(输出值-样本值)*输出值*(1-输出值)
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 当前节点的Sigmoid*(1-当前节点的Sigmoid)
如果用tansig作激活函数,那么:tansig导数 = 1 - tansig^2
残差全部计算好后,就可以更新权重了:
输入层:权重增加 = 当前节点的Sigmoid * 右层对应节点的残差 * 学习率
隐藏层:权重增加 = 输入值 * 右层对应节点的残差 * 学习率
偏移值的权重增加 = 右层对应节点的残差 * 学习率
学习率前面介绍过,学习率是一个预先设置好的参数,用于控制每次更新的幅度。
此后,对全部数据都反复进行这样的计算,直到输出的误差达到一个很小的值为止。
以上介绍的是目前最常见的神经网络类型,称为前馈神经网络(FeedForward Neural Network),由于它一般是要向后传递误差的,所以也叫BP神经网络(Back Propagation Neural Network)。
输入层:权重增加 = 当前节点的Sigmoid * 右层对应节点的残差 * 学习率
隐藏层:权重增加 = 输入值 * 右层对应节点的残差 * 学习率
偏移值的权重增加 = 右层对应节点的残差 * 学习率
学习率前面介绍过,学习率是一个预先设置好的参数,用于控制每次更新的幅度。
此后,对全部数据都反复进行这样的计算,直到输出的误差达到一个很小的值为止。
以上介绍的是目前最常见的神经网络类型,称为前馈神经网络(FeedForward Neural Network),由于它一般是要向后传递误差的,所以也叫BP神经网络(Back Propagation Neural Network)。
BP神经网络的特点和局限:
- BP神经网络可以用作分类、聚类、预测等。需要有一定量的历史数据,通过历史数据的训练,网络可以学习到数据中隐含的知识。在你的问题中,首先要找到某些问题的一些特征,以及对应的评价数据,用这些数据来训练神经网络。
- BP神经网络主要是在实践的基础上逐步完善起来的系统,并不完全是建立在仿生学上的。从这个角度讲,实用性 > 生理相似性。
- BP神经网络中的某些算法,例如如何选择初始值、如何确定隐藏层的节点个数、使用何种激活函数等问题,并没有确凿的理论依据,只有一些根据实践经验总结出的有效方法或经验公式。
- BP神经网络虽然是一种非常有效的计算方法,但它也以计算超复杂、计算速度超慢、容易陷入局部最优解等多项弱点著称,因此人们提出了大量有效的改进方案,一些新的神经网络形式也层出不穷。
- BP神经网络可以用作分类、聚类、预测等。需要有一定量的历史数据,通过历史数据的训练,网络可以学习到数据中隐含的知识。在你的问题中,首先要找到某些问题的一些特征,以及对应的评价数据,用这些数据来训练神经网络。
- BP神经网络主要是在实践的基础上逐步完善起来的系统,并不完全是建立在仿生学上的。从这个角度讲,实用性 > 生理相似性。
- BP神经网络中的某些算法,例如如何选择初始值、如何确定隐藏层的节点个数、使用何种激活函数等问题,并没有确凿的理论依据,只有一些根据实践经验总结出的有效方法或经验公式。
- BP神经网络虽然是一种非常有效的计算方法,但它也以计算超复杂、计算速度超慢、容易陷入局部最优解等多项弱点著称,因此人们提出了大量有效的改进方案,一些新的神经网络形式也层出不穷。
详细的计算过程图:
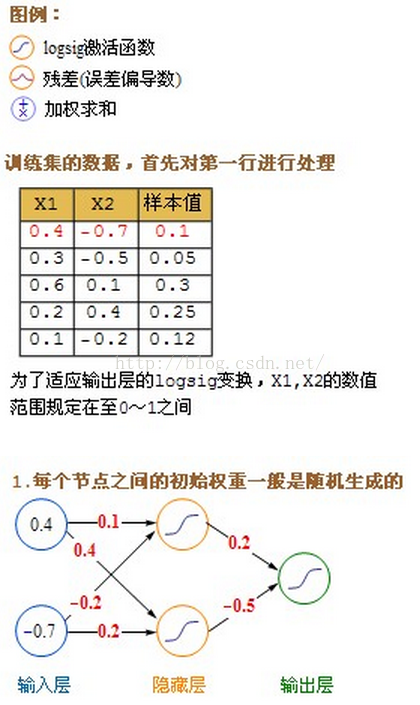
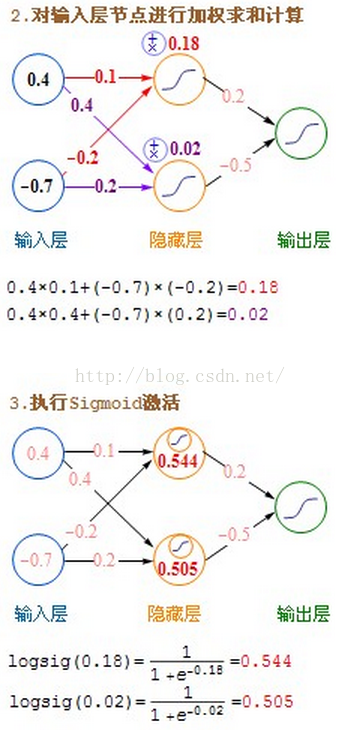



















 98
98

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









