







Global对象的encodeURI()、encodeURIComponent()、decodeURI()、decodeURIComponent()方法对URI(Uniform Resource Identifiers,通用资源标识符)进行编码和解码,以便发送给浏览器。
有效的URI中不能包含某些字符,例如:空格、中文、+等,而以上两个编码方法可以对URI进行编码,它们用特殊的UTF-8编码替换所有无效的字符,从而让浏览器可以接受和理解。
encodeURI()主要用于整个URIencodeURIComponent()主要用于对URI中的某一段进行编码,两者的主要区别:
encodeURI()不会对本身属于URI的特殊字符进行编码,例如:“: / ? #”;而encodeURIComponent()则会对发现的任何非标准字符进行编码。例如:
var uri = "http://10.88.54.23:8020/test/images 图片翻转.html#start";
console.log("encodeURI(uri)");
console.log(encodeURI(uri));
console.log("encodeURIComponent(uri)");
console.log(encodeURIComponent(uri));输出结果:

以上可以看到,encodeURI()编码后的结果是除了空格和汉字之外的其他字符都是原封不动的,但是encodeURIComponent()则使用对应的编码替换所有非字母数字的字符。这就是对整个URI使用encodeURI(),而只能对附加在现有URI后面的字符串使用encodeURIComponent()的原因。
decodeURI()只能对使用encodeURI()替换的字符进行解码,但是decodeURIComponent()可以解码任何特殊字符的编码。
var uriEncode = encodeURI(uri);
var uriEncodeComponent = encodeURIComponent(uri);
console.log("decodeURI(uriEncode)");
console.log(decodeURI(uriEncode));
console.log("decodeURIComponent(uriEncode)");
console.log(decodeURIComponent(uriEncode));
console.log("decodeURIComponent(uriEncodeComponent)");
console.log(decodeURIComponent(uriEncodeComponent));结果:
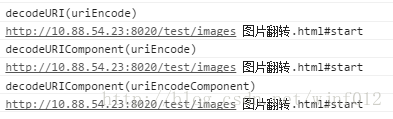
调用decodeURIComponent()方法所有特殊字符编码都被替换成了原来的字符,得到了一个未经转义的字符,但是这个字符并不是一个有效的URI。这是为什么呢?
这里的四个方法都是以Unicode标准进行编码解码的,也就是说将汉字视为3字节进行处理,一个汉字编码后变为类似的%hh%hh%hh的形式,相应的,解码函数的参数必须和编码结果的格式保持一致,这样二者才可以实现互逆,否则就会报错“被解码的URI不是合法的编码”。我们程序中常用的GB2312,GBK,UTF-8处理中文都是2字节的。














 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









