










该系列是上海AI Lab举行的书生 浦语大模型训练营的相关笔记部分。
该笔记是第七节课,学习大语言模型评测的基本概念,以及评测系统OpenCompass的使用。
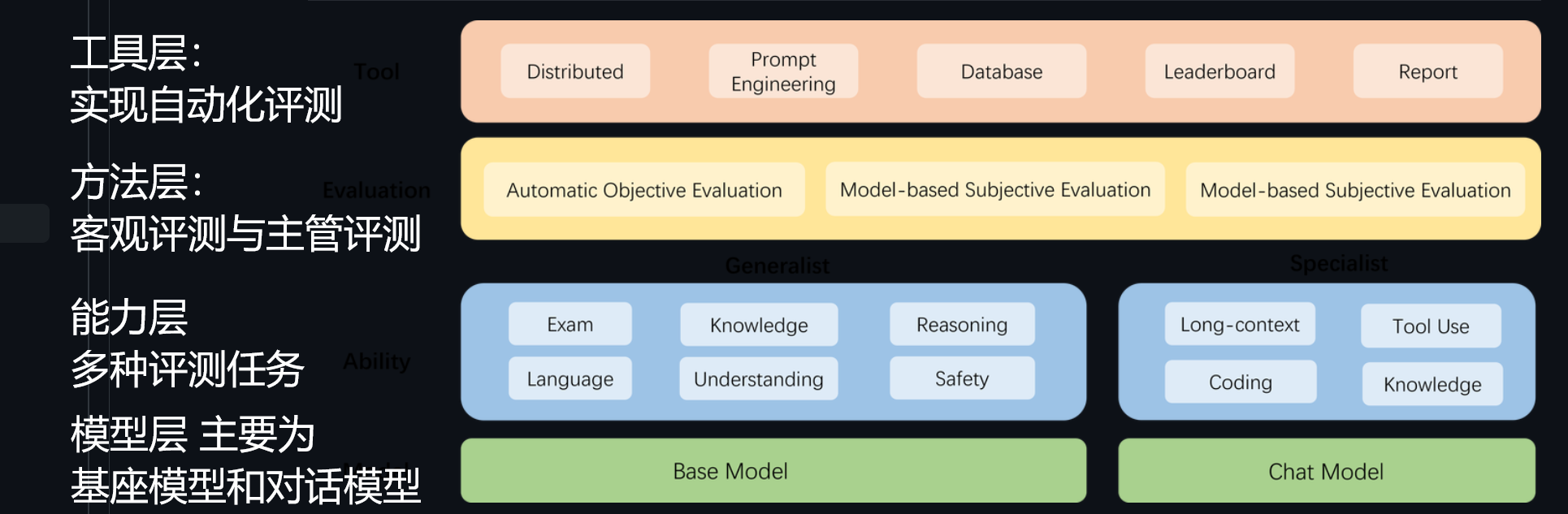
0. 大模型评测
对于大模型的评测,我们主要有四类模型。
- 基座模型:从互联网的海量数据中无监督训练出来的模型,它主要学习的是文本相似度,例如,如果问他“中国的首都是哪里?”,它可能会回答“美国的首都是哪里?俄罗斯的首都是哪里”等,因为这些句子比较相似。
- 对话模型:对话模型是在基座模型的基础上经过有监督微调(SFT)或者人类偏好对齐(RLHF)得到的模型,这时候它可以正确理解问题并给出答案。
- 此外还有公开权重的模型和API模型等。

关于模型评价的方法,主要分为客观评测与主观评测。

此外,在对模型进行评测时,会用到prompt engineering,目的是制造高质量的问答数据对,从而让模型得分具有较好的区分度:

此外,还可以将prompt engineering用于小样本学习与思维链技术等进行评测:

后面就是关于OpenCompass优点的介绍,此处就先略去了。OpenCompass的逻辑结构如下:
1. 实战:使用 OpenCompass 评测 internlm2-chat-1_8b 模型在 C-Eval 数据集上的性能(基础作业)
首先创建开发机,GPU选择10% * A100,cuda版本选择11.7
然后安装环境:
studio-conda -o internlm-base -t opencompass
source activate opencompass
cd ~
git clone -b 0.2.4 https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
之后,我们需要准备数据:
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
运行!
python run.py --datasets ceval_gen \
--hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \
--tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \
--model-kwargs trust_remote_code=True device_map='auto' 、
--max-seq-len 1024 \
--max-out-len 16 \
--batch-size 2 \
--num-gpus 1 \
--debug
可能会遇到mmengineimport error的错误,pip install 即可. 但后来发现缺的包太多了,直接运行:
pip install -r requirements.txt
pip install protobuf
export MKL_SERVICE_FORCE_INTEL=1
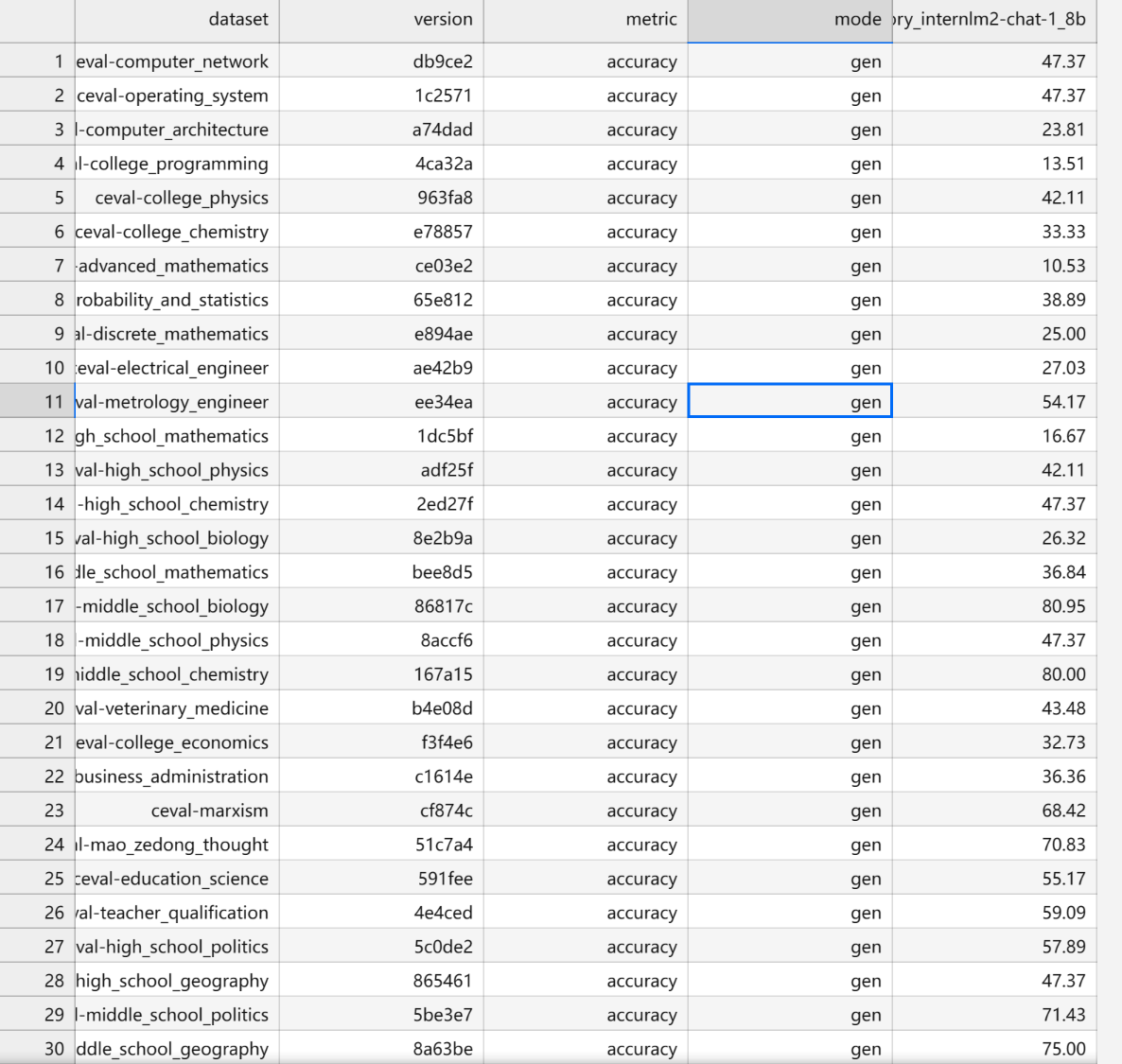
结果如下:
2. 在OpenCompass上传自己的数据集(进阶作业)
待更新















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









