




Flink集群有两种部署的模式,分别是Standalone以及YARNCluster模式。
Standalone模式:Flink必须依赖于ZooKeeper来实现JobManager的HA(Zookeeper 已经成为了大部分开源框架HA必不可少的模块)。在Zookeeper的帮助下,一个Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于Standby状态。当工作中的JobManager失去连接(如宕机或Crash),ZooKeeper会从Standby中选举新的JobManager来接管Flink集群。
YARN Cluaster模式:Flink就要依靠YARN本身来对JobManager做HA了。其实这里完全是YARN的机制。对于YARNCluster模式来说,JobManager和TaskManager都是启动在YARN的Container中。此时的 JobManager,其实应该称之为Flink Application Master。也就说它的故障恢复,就完全依靠着YARN中的ResourceManager(和 MapReduce的AppMaster一样)。由于完全依赖了YARN,因此不同版本的YARN可能会有细微的差异。
目录
Local模式
1、解压flink安装包并重命名
tar -zxf flink-1.9.3-bin-scala_2.11.tgz
mv flink-1.9.3 flink
2、配置flink环境变量

#需要配置 HADOOP_CONF_DIR 环境变量,否则会有提示
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
3、配置文件flink/conf说明

需要配置的文件有:masters、slaves、flink-conf.yaml文件,其中masters文件是用来配置HA的,只要我们不配置HA(高可 用性)的话,就不需要配置masters文件;slaves是用来配置从节点个数(flink也是master/slave结构);flink-conf.yaml文件 用来配置集群其他相关信息
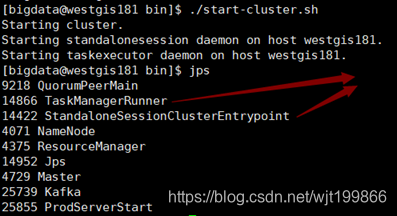
4、Local模式中JobManager和TaskManager共用一个JVM来完成WorkLoad。如果验证一个简单的应用,Local 模式是最方便的,实际应用中大多使用Standalone或者Yarn Cluster。Local模式只需要将安装包解压,使用./bin/start-cluster.sh启动即可,看到有如下两个进程即启动成功,使用stop-cluster.sh即可关闭集群
Standalone模式
1、配置master文件(主节点地址和端口)
vim masters
#设置主节点,非HA模式只配置一个即可
westgis181:8081
2、配置slaves文件
vim slaves
#设置从节点
westgis182
westgis183
3、配置flink-conf.yaml文件
vim $FLINK_HOME/conf/flink-conf.yaml
修改设置如下即可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









