






在 Zookeeper 的帮助下,一个 Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选一个新的 JobManager 来接管 Flink 集群。
一、下载

二、集群规划
| 10.9.70.172 | 10.9.70.166 | 10.9.70.168 | ||
|---|---|---|---|---|
| JSYF3 | JSYF1 | JSYF2 | ||
| Flink | (Master + Slave): JobManager + TaskManager | (Master + Slave): JobManager + TaskManager | (Slave):TaskManager | |
| Zookeeper | server.3 | server.1 | server.2 | |
| Hadoop | master | slave1 | slave2 | |
| NameNode、ResourceManager、SecondaryNameNode | DataNode、NodeManager | DataNode、NodeManager |
三、zookeeper集群安装
zookeeper
启动ZooKeeper
./home/bin/zk.sh start
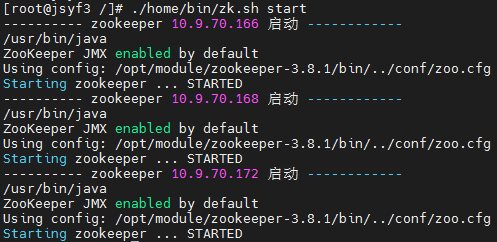
四、HDFS搭建
cd /opt/software/hadoop/hadoop-3.3.5/sbin/
./start-dfs.sh

五、部署Flink集群
1、安装包解压
tar -zxvf /opt/software/flink/flink-1.17.0-bin-scala_2.12.tgz
chmod -R 755 /opt/software/flink/flink-1.17.0
2、配置环境变量
vim /etc/profile
# set flink env
export FLINK_HOME=/opt/software/flink/flink-1.17.0
export PATH=$FLINK_HOME/bin:$PATH
source /etc/profile
3、修改flink-conf.yaml
vim /opt/software/flink/flink-1.17.0/conf/flink-conf.yaml
jobmanager.rpc.address: JSYF3
jobmanager.bind-host: 0.0.0.0
jobmanager.memory.process.size: 10240m
taskmanager.bind-host: 0.0.0.0
taskmanager.host: JSYF3
taskmanager.memory.process.size: 20480m
#taskmanager.memory.flink.size: 16384m
taskmanager.numberOfTaskSlots: 2
parallelism.default: 2
rest.port: 8081
rest.address: JSYF3
rest.bind-address: 0.0.0.0
rest.bind-port: 8080-8090
akka.ask.timeout: 60s
web.timeout="1000000"
web.submit.enable: true
#历史服务器
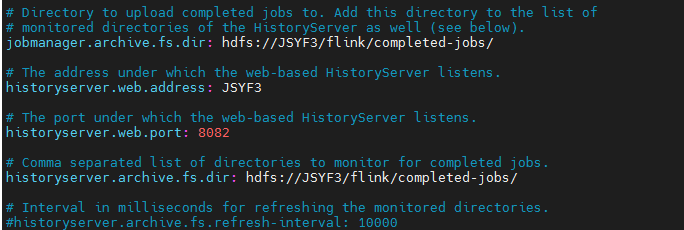
jobmanager.archive.fs.dir: hdfs://JSYF3:9000/flink/completedjobs/
historyserver.web.address: JSYF3
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://JSYF3:9000/flink/completedjobs/
# 在Standalone基础上,增加如下内容
# 开启HA,使用文件系统作为快照存储
#state.backend.type: hashmap
state.backend: filesystem
# 启用检查点,可以将快照保存到HDFS
state.checkpoints.dir: hdfs://JSYF3:9000/flink-checkpoints
state.savepoints.dir: hdfs://JSYF3:9000/flink-savepoints
jobmanager.execution.failover-strategy: region
# 使用zookeeper搭建高可用
high-availability.type: zookeeper
# 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://JSYF3:9000/flink/ha/
# 配置ZK集群地址
high-availability.zookeeper.quorum: JSYF3:2181,JSYF1:2181,JSYF2:2181
# HA重试次数
yarn.application-attempts: 5
# 只有在10s内flink job失败后被yarn重新拉起才算做1次attempts。
yarn.application-attempt-failures-validity-interval: 10000
4、修改masters
vim /opt/software/flink/flink-1.17.0/conf/masters
JSYF3:8081 JSYF1:8081
5、修改workers
vim /opt/software/flink/flink-1.17.0/conf/workers
JSYF1 JSYF2 JSYF3
6、添加HADOOP_CONF_DIR环境变量
vim /etc/profile
# set hadoop env
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
source /etc/profile
每台节点都要添加
7、分发
ansible JSYF1,JSYF2 -m copy -a 'src=/opt/software/flink/ dest=/opt/software/flink/ mode=755 owner=root'
8、修改JSYF 166上的flink-conf.yaml
vim /opt/software/flink/flink-1.17.0/conf/flink-conf.yaml
jobmanager.rpc.address: JSYF1
taskmanager.host: JSYF1
rest.address: JSYF1
9、重新启动Flink集群,172 JSYF3上执行
bash /opt/software/flink/flink-1.17.0/bin/start-cluster.sh

10、使用jps命令查看
发现没有Flink相关进程被启动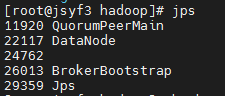
查看日志
cat /opt/software/flink/flink-1.17.0/log/flink-root-standalonesession-0-jsyf3.log

下载jar包并在Flink的lib目录下放入该jar包并分发使Flink能够支持对Hadoop的操作
下载地址:
https://mvnrepository.com/search?q=commons-cli
https://mvnrepository.com/artifact/org.apache.flink/flink-shaded-hadoop-3-uber
https://mvnrepository.com/artifact/org.apache.flink/flink-hadoop-compatibility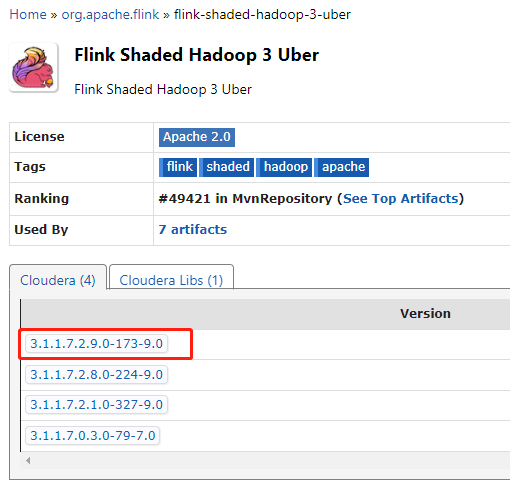
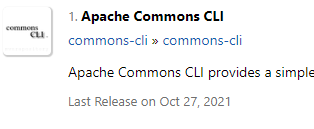
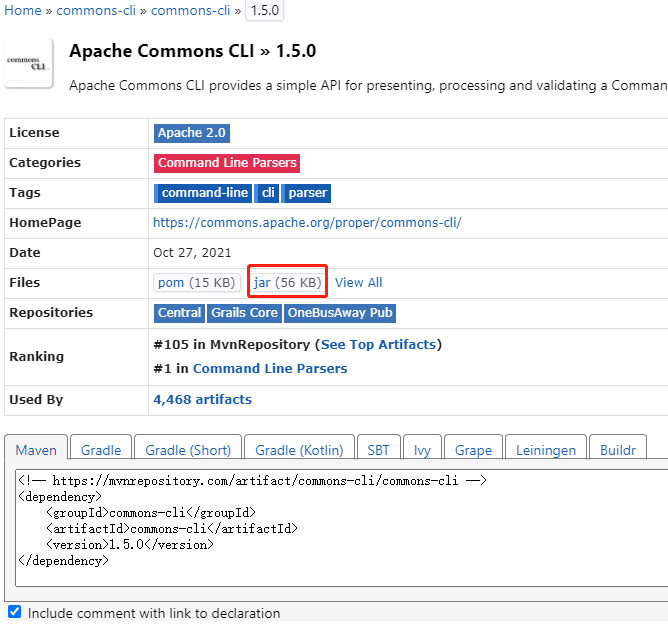
放入 /opt/software/flink/flink-1.17.0/lib/ 目录下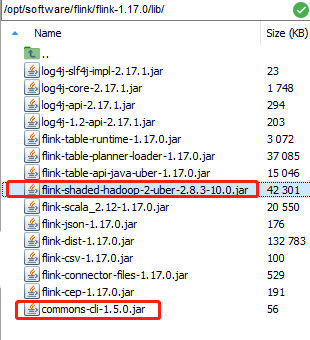
分发至两外两台服务器
ansible JSYF1,JSYF2 -m copy -a 'src=/opt/software/flink/flink-1.17.0/lib/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar dest=/opt/software/flink/flink-1.17.0/lib/ mode=755 owner=root'
ansible JSYF1,JSYF2 -m copy -a 'src=/opt/software/flink/flink-1.17.0/lib/commons-cli-1.5.0.jar dest=/opt/software/flink/flink-1.17.0/lib/ mode=755 owner=root'
重新启动Flink集群,JSYF3上执行
bash /opt/software/flink/flink-1.17.0/bin/start-cluster.sh

jps
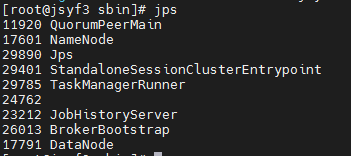
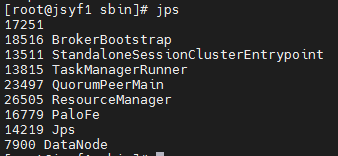
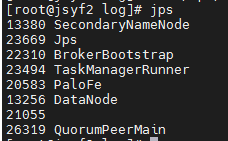
netstat -lnp|grep 8081
11、测试
访问WebUI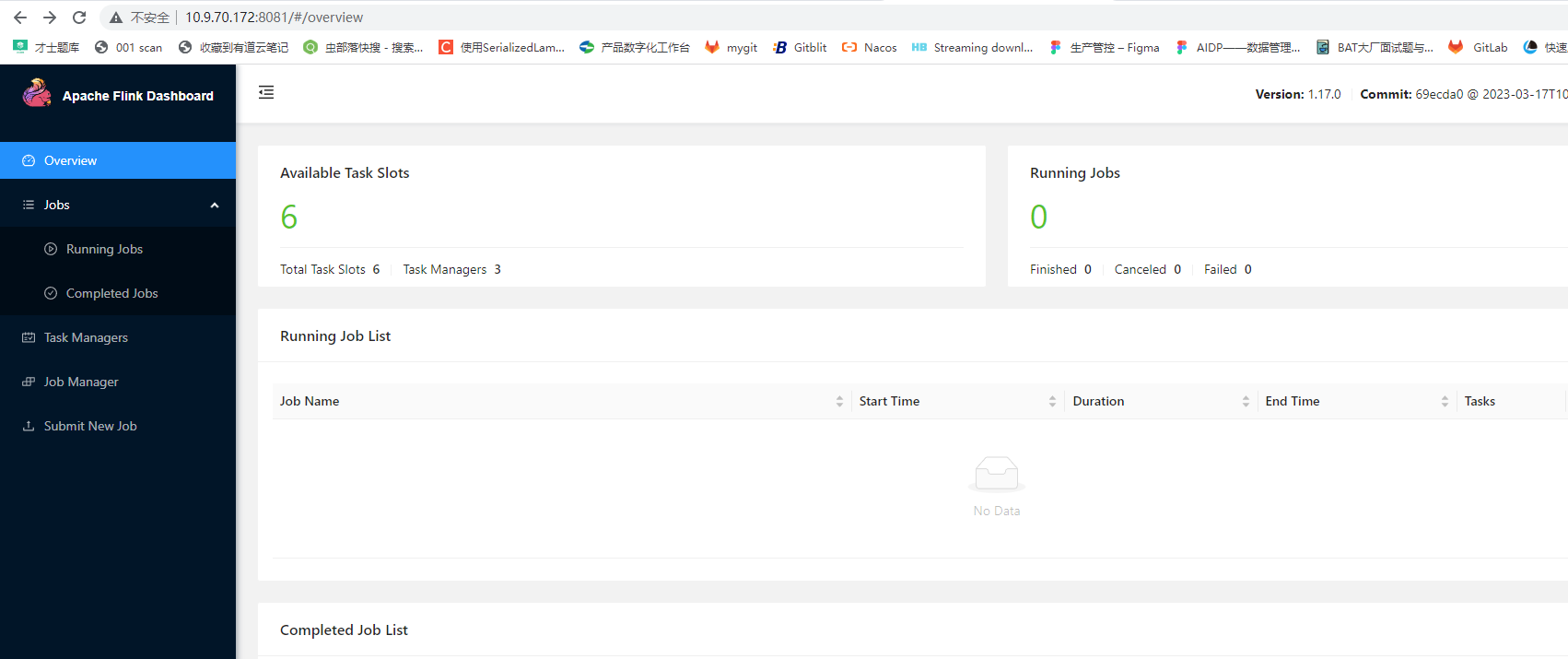
http://10.9.70.172:8081/#/job-manager/config
http://10.9.70.166:8081/#/job-manager/config
8081拒绝访问
执行 wget http://localhost:8081,确定flink在本地可以访问netstat -ano

本地可以访问
vim /opt/software/flink/flink-1.17.0/conf/flink-conf.yaml
rest.bind-address: 0.0.0.0
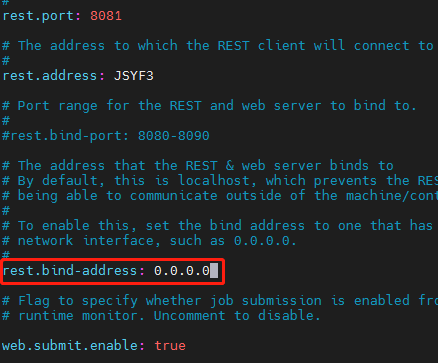
分发至其他服务器
重启flink
12、执行wc
/opt/software/flink/flink-1.17.0/bin/flink run /opt/software/flink/flink-1.17.0/examples/batch/WordCount.jar
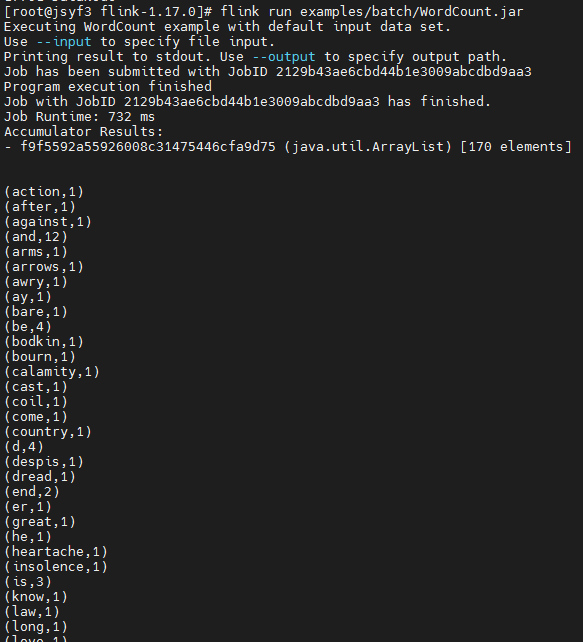
kill掉其中一个master,在172上执行
kill -9 30979
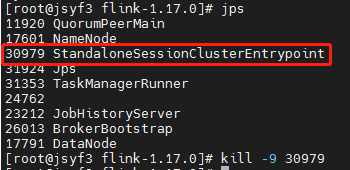
JSYF3/172拒绝访问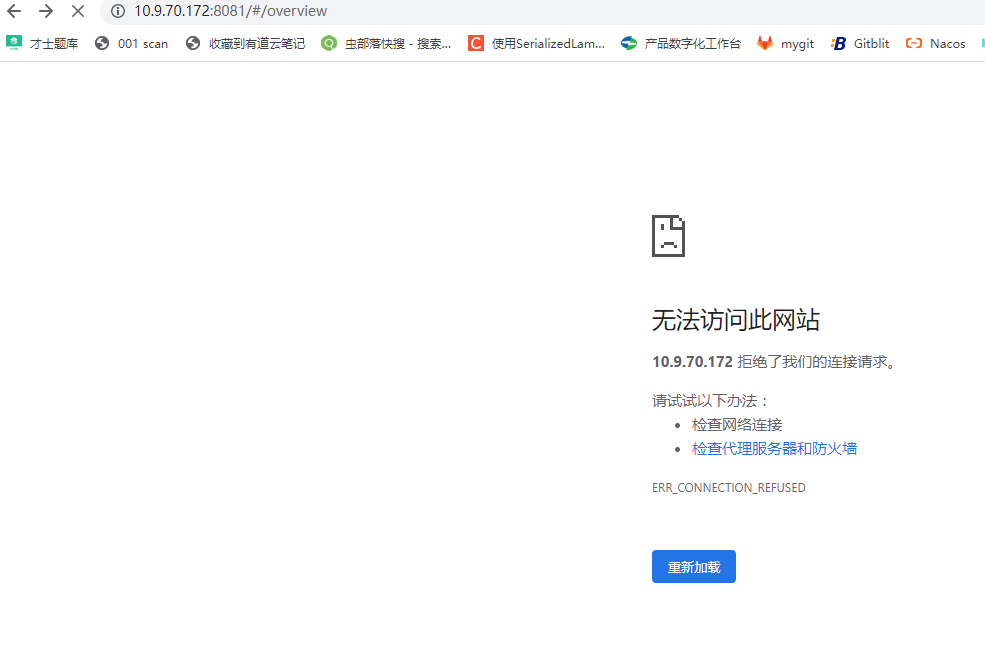
JSYF1/166正常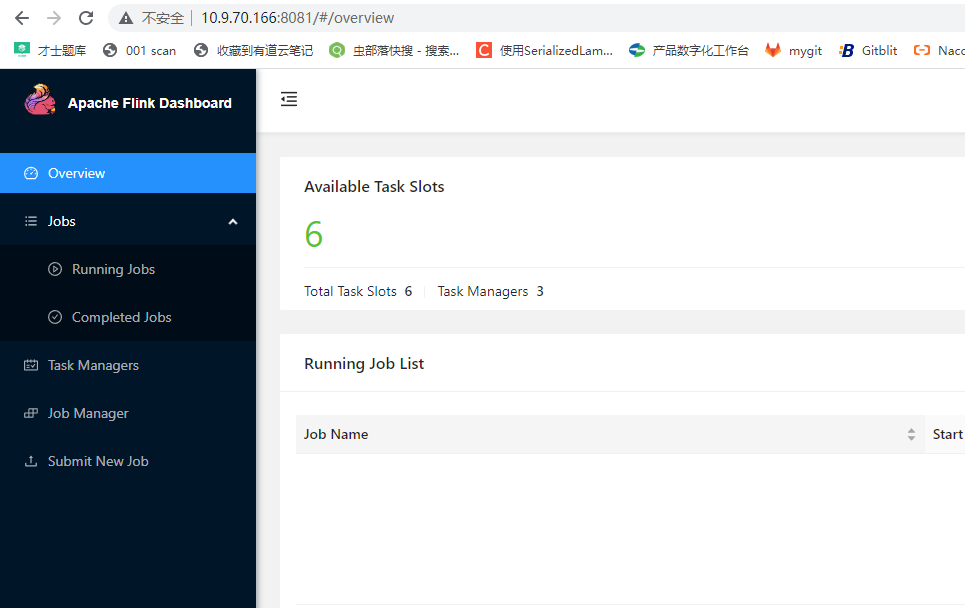
再次提交WC任务,可以执行,说明高可用在起作用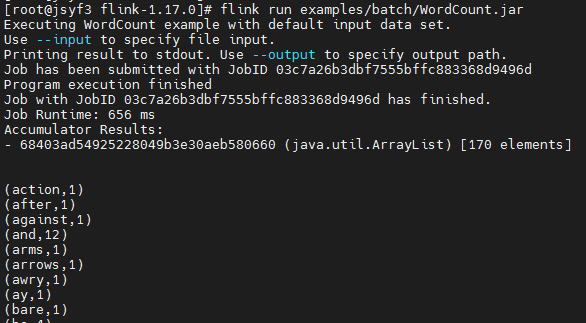
接着杀掉JSYF1的master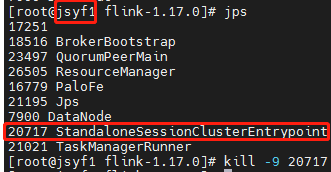
此时,JSYF1的web ui也无法访问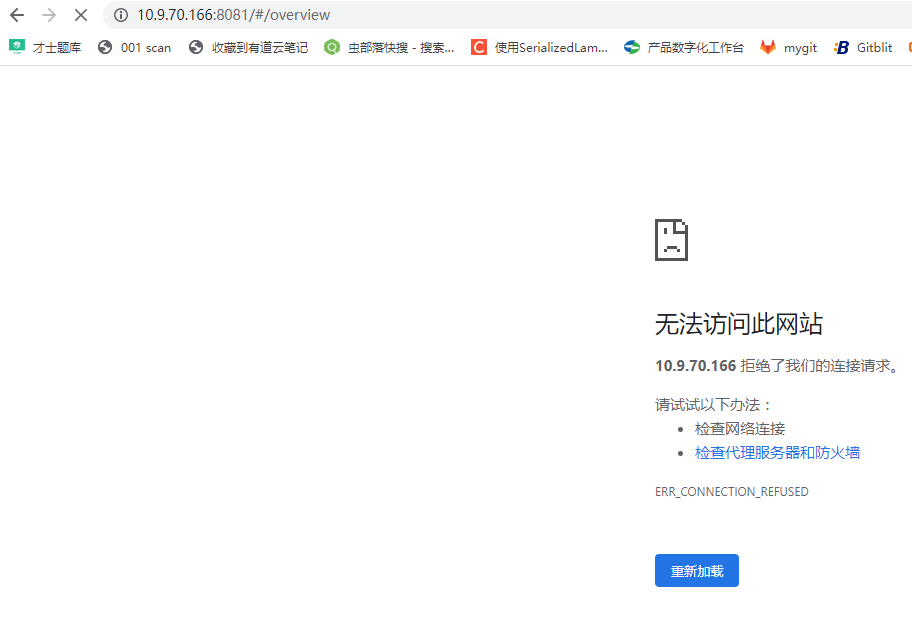
再次提交任务,出现错误,无法运行任务
六、Flink on Yarn模式集群搭建及测试
1.为什么要使用Flink on Yarn
yarn管理资源,可以按需使用,提高整个集群的资源利用率
任务有优先级,可以根据优先级合理的安排任务运行作用
基于yarn的调度系统,能够自动化的处理各个角色的容错
2.集群规划
跟standalone保持一致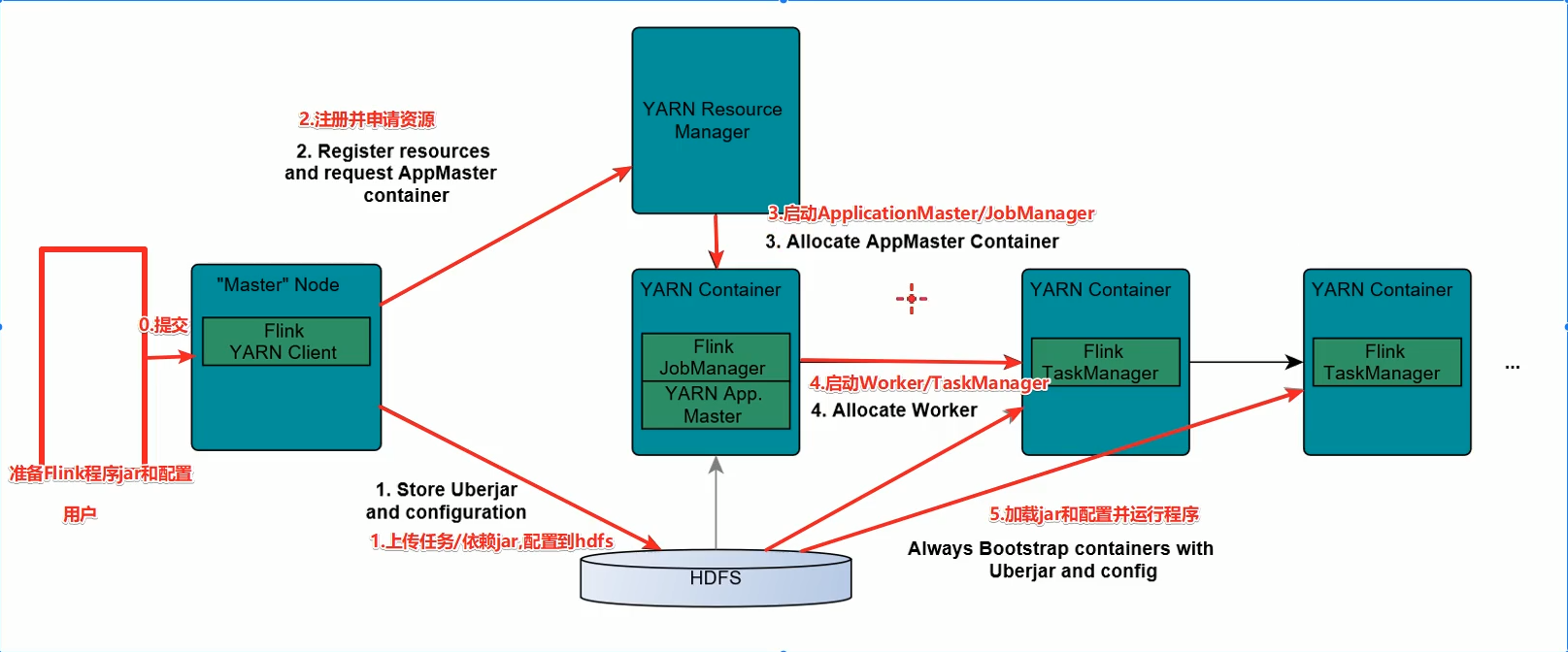
3、修改yarn的配置
vim /opt/software/hadoop/hadoop-3.3.5/etc/hadoop/yarn-site.xml
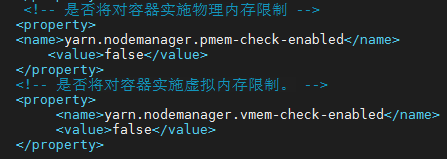
4.启动相关的服务
zookeeper
hdfs
yarn
flink
historyserver(可选)
cd /opt/software/flink/flink-1.17.0/
./bin/historyserver.sh start

http://10.9.70.172:8082/#/overview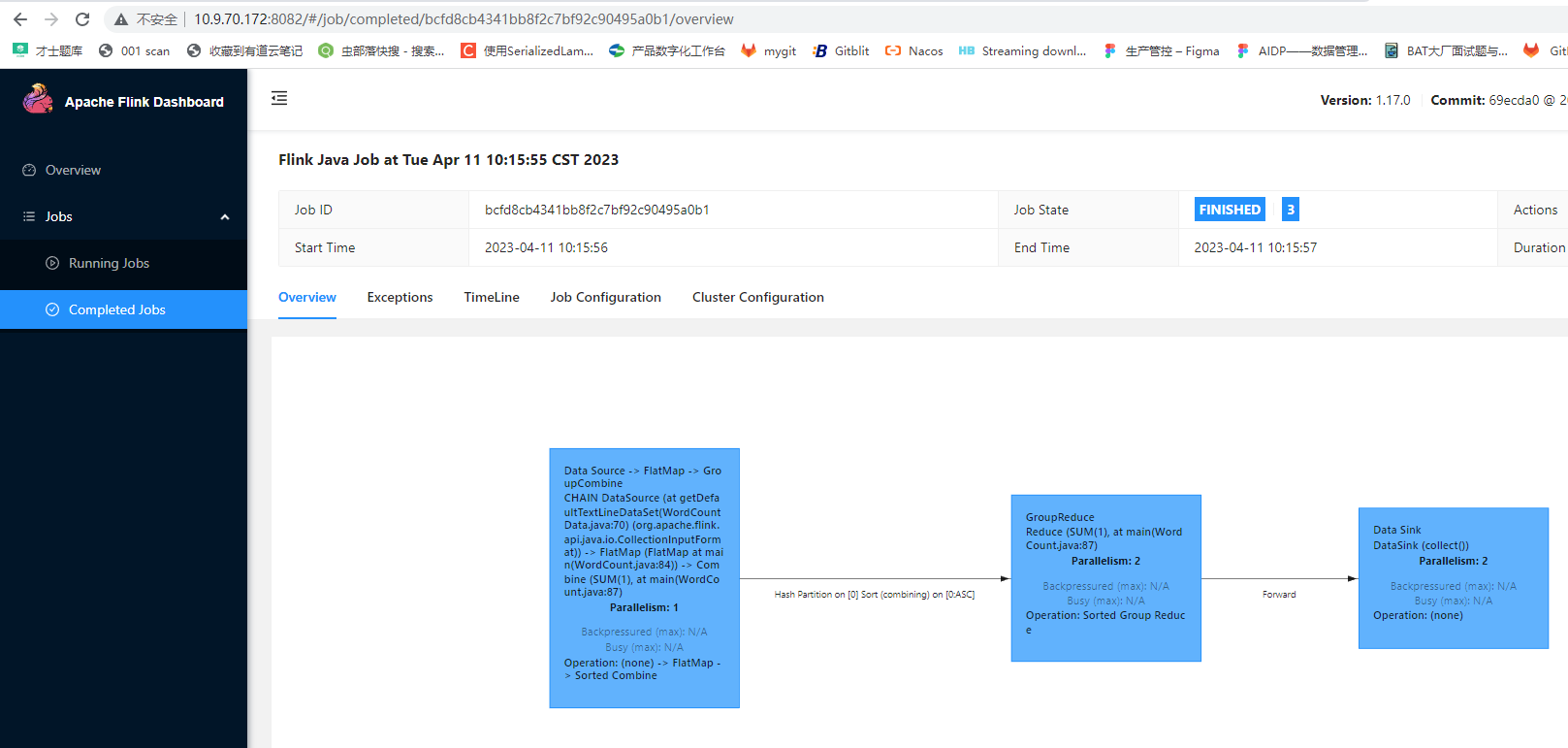
5.flink on yarn提交任务的模式
有两种模式
session模式 :会话模式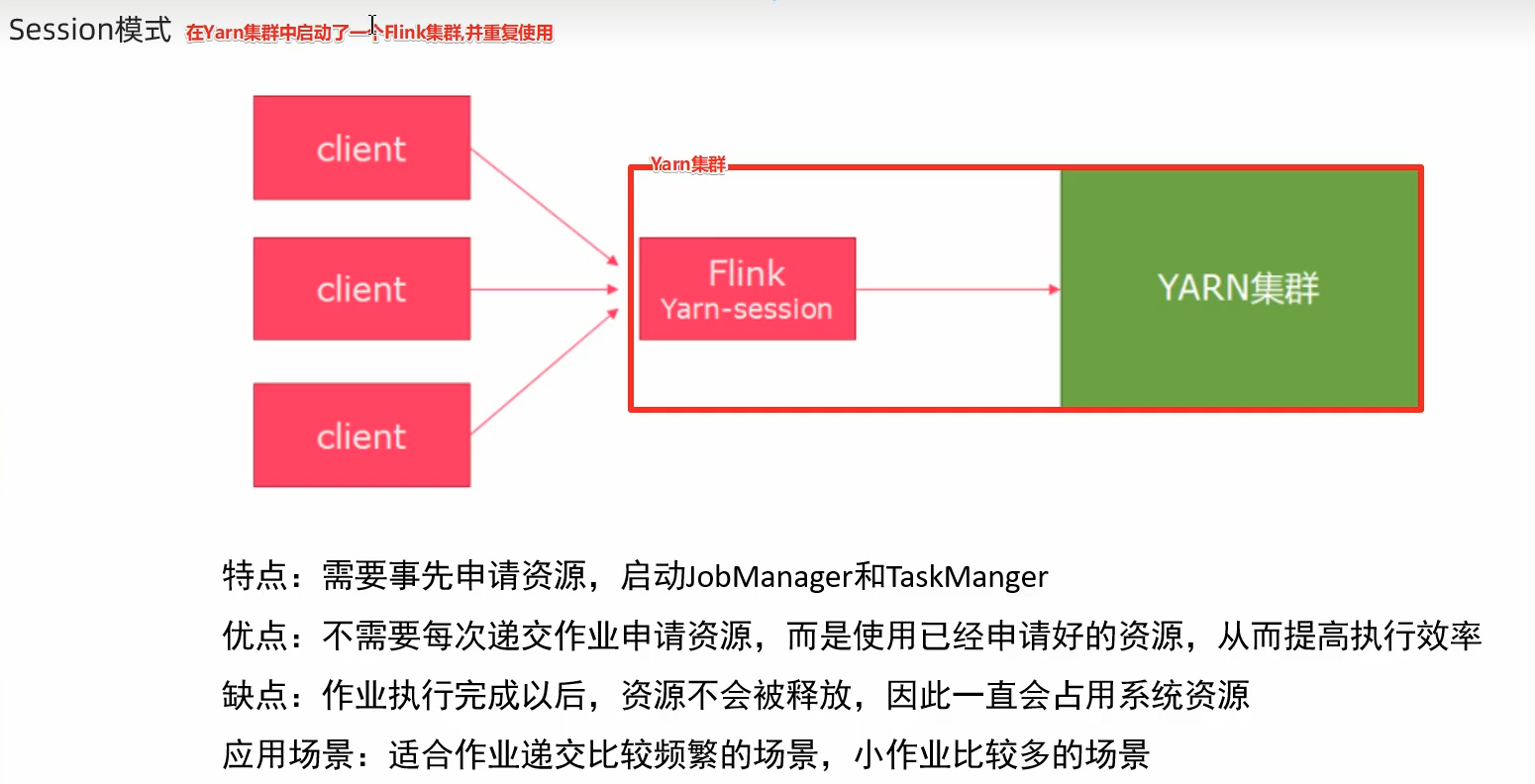
per-job模式:每任务模式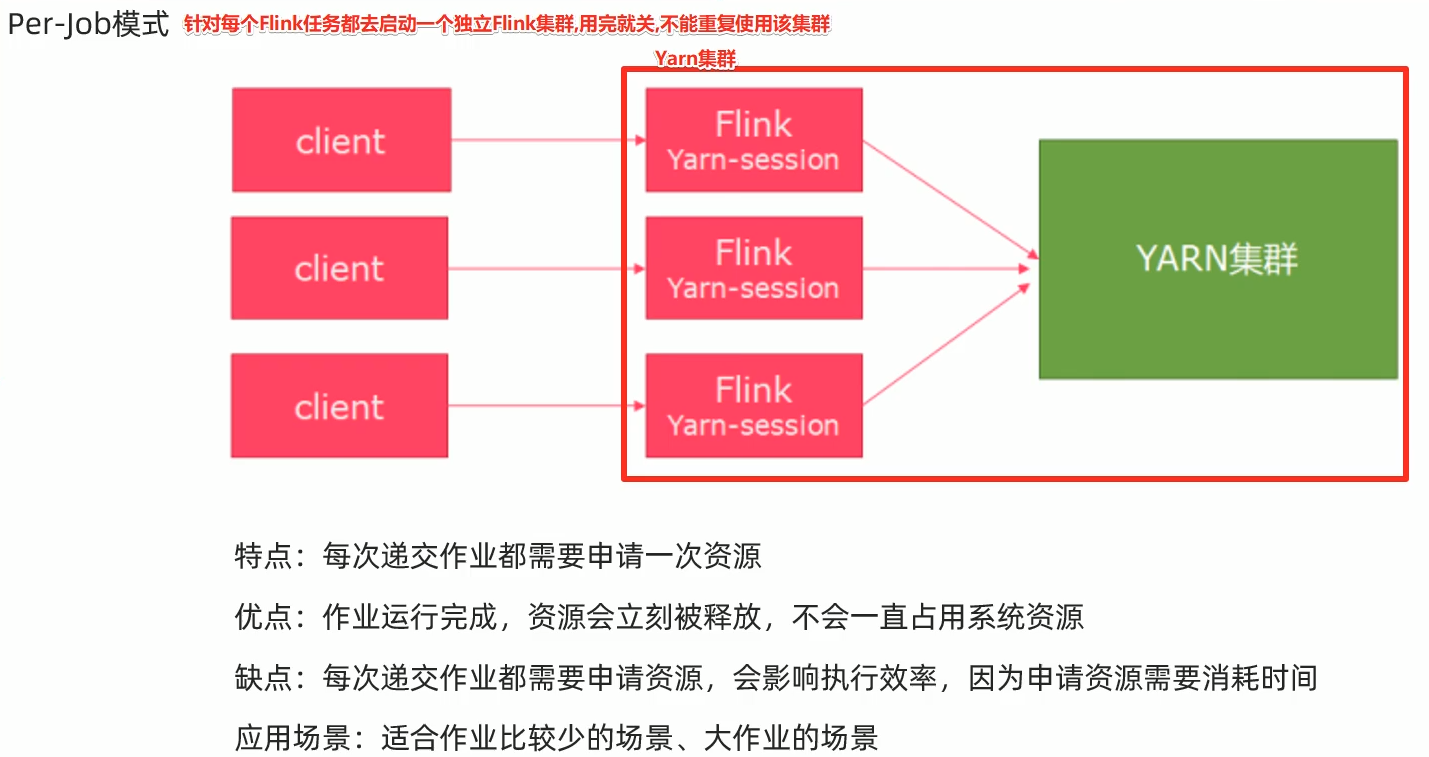
【注】
Downloads
Flink高手之路2-Flink集群的搭建
Flink高手之路2-Flink集群的搭建_W_chuanqi的博客-CSDN博客
ZooKeeper 高可用服务
2、Flink入门 02.安装部署
Flink入门 02.安装部署
3、基于Flink CDC 和 Doris Connector 实现 MySQL分库分表数据数据实时入Doris
基于Flink CDC 和 Doris Connector 实现 MySQL分库分表数据数据实时入Doris
4、Flink History Server
Flink History Server - 码农教程
5、各种问题解答
Flink 问题记录_新手路上的程序员的博客-CSDN博客
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









