






cuda流
CUDA流的概念
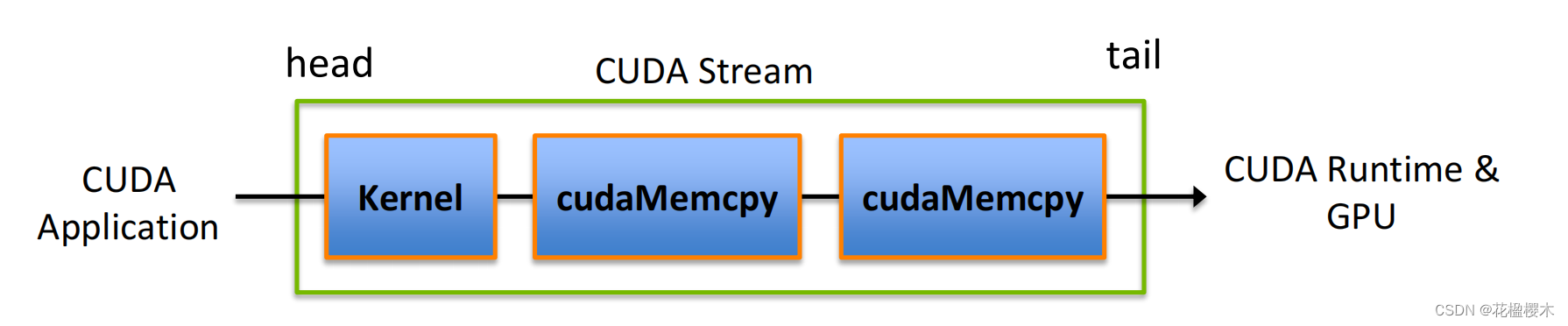
CUDA流在加速应用程序方面起到重要的作用,他表示一个GPU的操作队列,操作在队列中按照一定的顺序执行,也可以向流中添加一定的操作如核函数的启动、内存的复制、事件的启动和结束等,添加的川顺序也就是执行的顺序。一个流中的不同操作有着严格的顺序。但是不同流之间是没有任何限制的。多个流同时启动多个内核,就形成了网格级别的并行。
CUDA流中排队的操作和主机都是异步的,所以排队的过程中并不耽误主机运行其他指令,所以这就隐藏了执行这些操作的开销。
CUDA流的概念
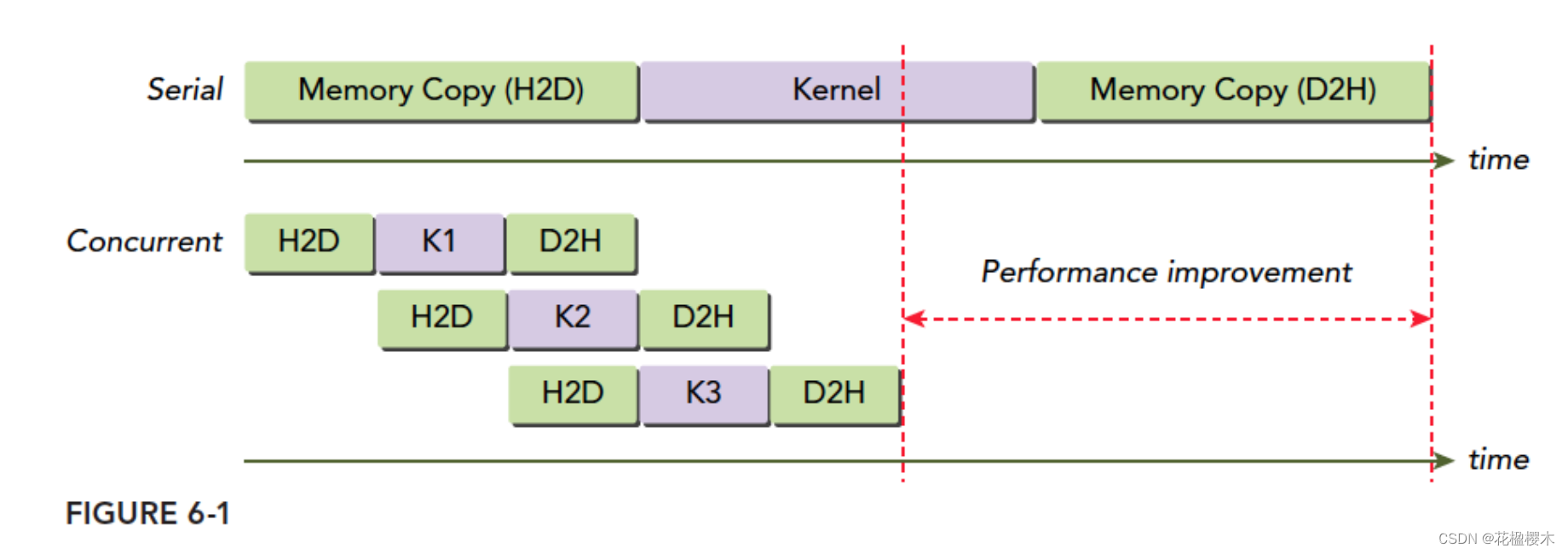
基于流的异步内核启动和数据传输支持以下类型的粗粒度并发
重叠主机和设备计算
重叠主机计算和主机设备数据传输重叠主机设备数据传输和设备计算并发设备计算(多个设备)不支持并发:
a page-locked host memory allocation, a device memory allocation, a device memory set,
a memory copy between two addresses to the same device memory, any CUDA command to the NULL stream
流的创建与销毁
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t
count,cudaMemcpyKind kind, cudaStream_t stream = 0);
cudaError_t cudaStreamCreate(cudaStream_t* pStream);
cudaStream_t a;
kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list);
cudaError_t cudaStreamDestroy(cudaStream_t stream);cuda流加速程序
for (int i = 0; i < nstreams; i++)
{
int offset = i * eles_per_stream;
cudaMemcpyAsync(&d_A[offset], &h_A[offset], eles_per_stream *sizeof(int), cudaMemcpyHostToDevice, streams[i]);
cudaMemcpyAsync(&d_B[offset], &h_B[offset], eles_per_stream *sizeof(int), cudaMemcpyHostToDevice, streams[i]);
……
vector_sum<<<..., streams[i]>>>(d_A + offset, d_B + offset, d_C + offset);
cudaMemcpyAsync(&h_C[offset], &d_C[offset], eles_per_stream *sizeof(int), cudaMemcpyDeviceToHost, streams[i]);
}
for (int i = 0; i < nstreams; i++)
cudaStreamSynchronize(streams[i]); 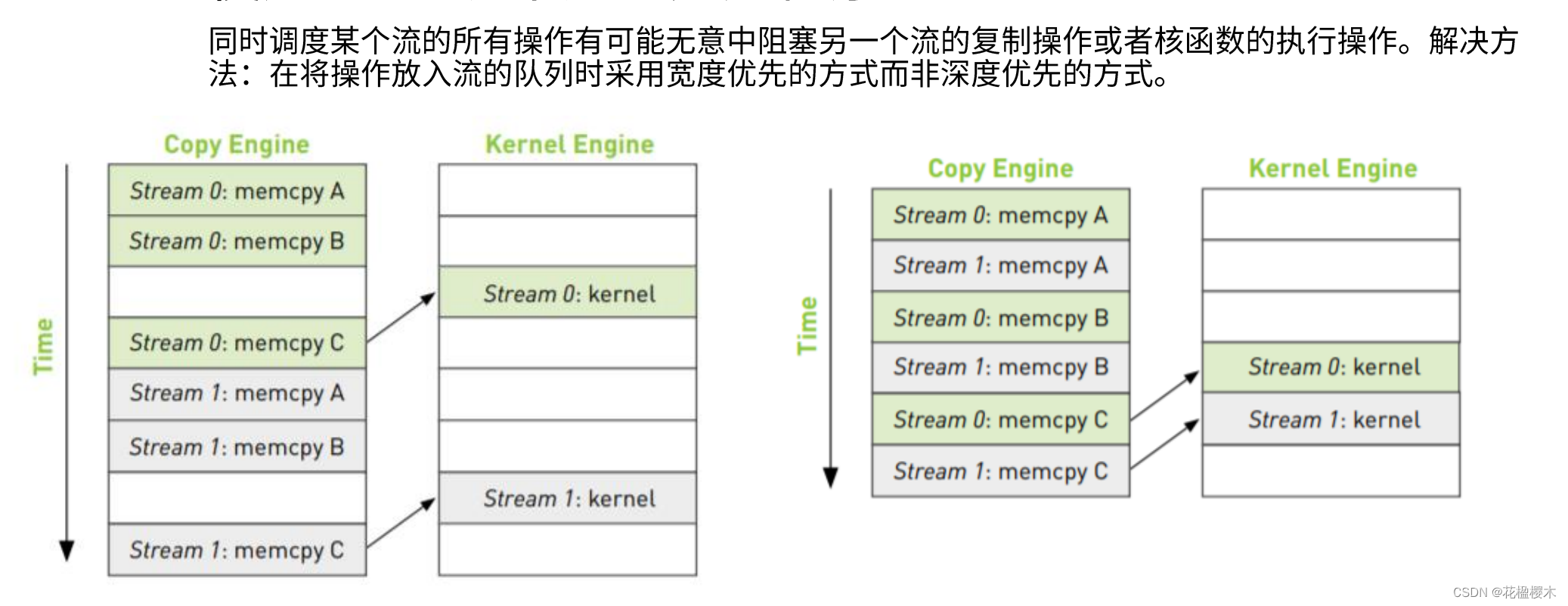
1.CUDA流¶
CUDA程序的并行层次主要有两个,一个是核函数内部的并行,一个是核函数的外部的并行。我们之前讨论的都是核函数的内部的并行。核函数外部的并行主要指:
- 核函数计算与数据传输之间的并行
- 主机计算与数据传输之间的并行
- 不同的数据传输之间的并行
- 核函数计算与主机计算之间的并行
- 不同核函数之间的并行
CUDA流表示一个GPU操作队列,该队列中的操作将以添加到流中的先后顺序而依次执行。我们的所有CUDA操作都是在流中进行的,虽然我们可能没发现,但是有我们前面的例子中的指令,内核启动,都是在CUDA流中进行的,只是这种操作是隐式的,所以肯定还有显式的,所以,流分为:
- 隐式声明的流,我们叫做空流
- 显式声明的流,我们叫做非空流
基于流的异步内核启动和数据传输支持以下类型的粗粒度并发:
- 重叠主机和设备计算
- 重叠主机计算和主机设备数据传输
- 重叠主机设备数据传输和设备计算
- 并发设备计算(多个设备)
接下来,我们就完成下面这个核函数,在两个流并发的实现:
__global__ void kernel( int *a, int *b, int *c ) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define N (1024*1024)
#define FULL_DATA_SIZE (N*20)
__global__ void kernel( int *a, int *b, int *c ) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
int main( void ) {
cudaDeviceProp prop;
int whichDevice;
CHECK( cudaGetDevice( &whichDevice ) );
CHECK( cudaGetDeviceProperties( &prop, whichDevice ) );
if (!prop.deviceOverlap) {
printf( "Device will not handle overlaps, so no speed up from streams\n" );
return 0;
}
cudaEvent_t start, stop;
float elapsedTime;
cudaStream_t stream0, stream1;
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0;
int *dev_a1, *dev_b1, *dev_c1;
// start the timers
CHECK( cudaEventCreate( &start ) );
CHECK( cudaEventCreate( &stop ) );
// initialize the streams
CHECK( cudaStreamCreate( &stream0 ) );
CHECK( cudaStreamCreate( &stream1 ) );
// allocate the memory on the GPU
CHECK( cudaMalloc( (void**)&dev_a0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_b0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_c0, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_a1, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_b1, N * sizeof(int) ) );
CHECK( cudaMalloc( (void**)&dev_c1, N * sizeof(int) ) );
// allocate host locked memory, used to stream
CHECK( cudaHostAlloc( (void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
CHECK( cudaHostAlloc( (void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
CHECK( cudaHostAlloc( (void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault ) );
for (int i=0; i<FULL_DATA_SIZE; i++) {
host_a[i] = rand();
host_b[i] = rand();
}
CHECK( cudaEventRecord( start, 0 ) );
// now loop over full data, in bite-sized chunks
for (int i=0; i<FULL_DATA_SIZE; i+= N*2) {
// enqueue copies of a in stream0 and stream1
CHECK( cudaMemcpyAsync( dev_a0, host_a+i, N * sizeof(int), cudaMemcpyHostToDevice, stream0 ) );
CHECK( cudaMemcpyAsync( dev_a1, host_a+i+N, N * sizeof(int), cudaMemcpyHostToDevice, stream1 ) );
// enqueue copies of b in stream0 and stream1
CHECK( cudaMemcpyAsync( dev_b0, host_b+i, N * sizeof(int), cudaMemcpyHostToDevice, stream0 ) );
CHECK( cudaMemcpyAsync( dev_b1, host_b+i+N, N * sizeof(int), cudaMemcpyHostToDevice, stream1 ) );
kernel<<<N/256,256,0,stream0>>>( dev_a0, dev_b0, dev_c0 );
kernel<<<N/256,256,0,stream1>>>( dev_a1, dev_b1, dev_c1 );
CHECK( cudaMemcpyAsync( host_c+i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0 ) );
CHECK( cudaMemcpyAsync( host_c+i+N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1 ) );
}
CHECK( cudaStreamSynchronize( stream0 ) );
CHECK( cudaStreamSynchronize( stream1 ) );
CHECK( cudaEventRecord( stop, 0 ) );
CHECK( cudaEventSynchronize( stop ) );
CHECK( cudaEventElapsedTime( &elapsedTime,
start, stop ) );
printf( "Time taken: %3.1f ms\n", elapsedTime );
// cleanup the streams and memory
CHECK( cudaFreeHost( host_a ) );
CHECK( cudaFreeHost( host_b ) );
CHECK( cudaFreeHost( host_c ) );
CHECK( cudaFree( dev_a0 ) );
CHECK( cudaFree( dev_b0 ) );
CHECK( cudaFree( dev_c0 ) );
CHECK( cudaFree( dev_a1 ) );
CHECK( cudaFree( dev_b1 ) );
CHECK( cudaFree( dev_c1 ) );
CHECK( cudaStreamDestroy( stream0 ) );
CHECK( cudaStreamDestroy( stream1 ) );
return 0;
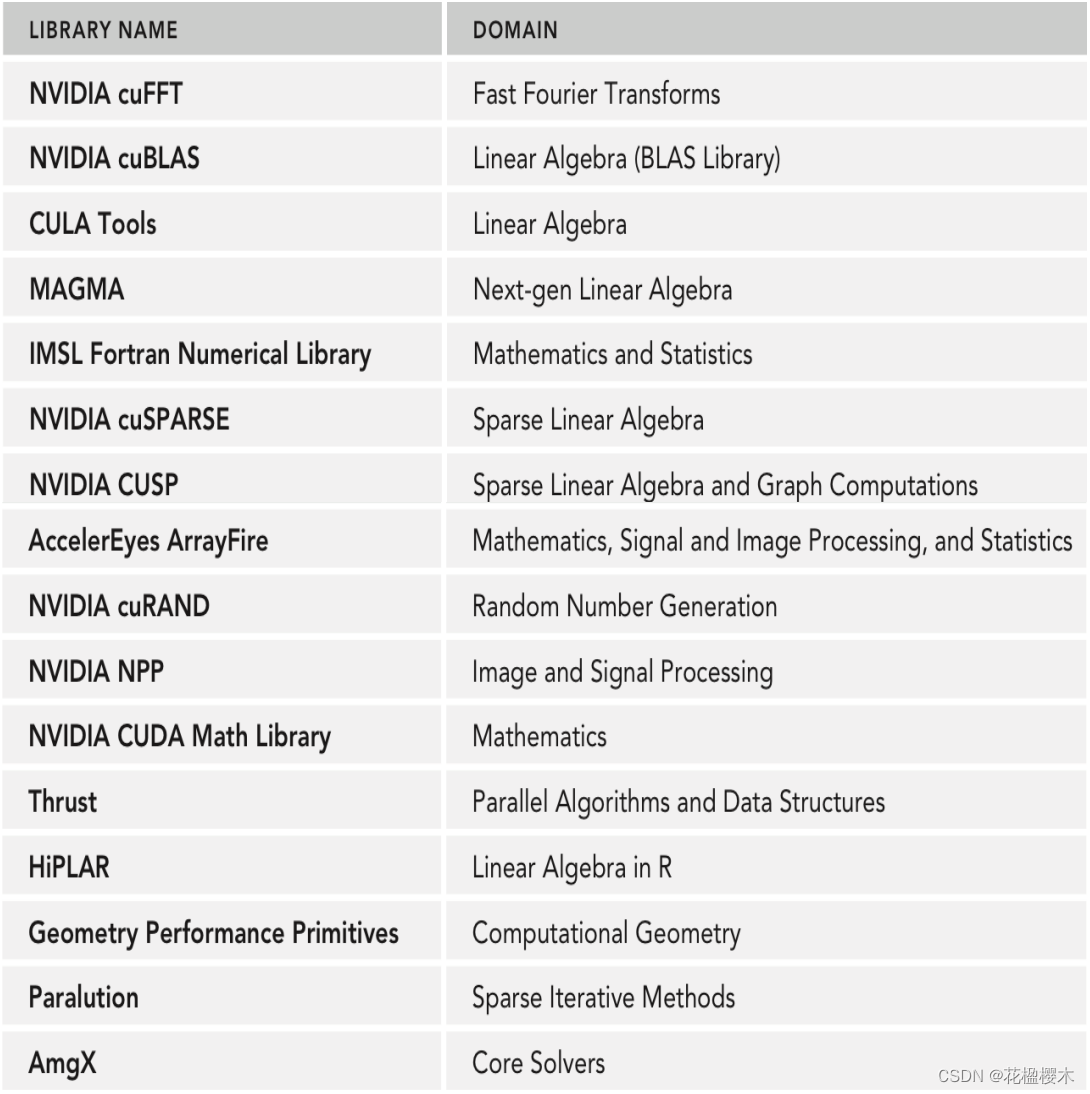
}cuda库

基本流程
1. 创建一个图书馆专用句柄,用于管理对库的操作有用的上下文信息。
操作有用的上下文信息。许多CUDA库都有一个句柄的概念,即在主机上存储不透明的库专用信息许多库函数会访问这些信息,程序员有责任管理这个句柄
例如:cublasHandle_t,cufftHandle ,cusparseHandle_t, curandGenerator_t
2. 为输入和输出的设备内存分配到库函数。
3. 如果输入不是库支持的格式。转换它们,使之能被库访问。
许多CUDA库只接受特定格式的数据。
例如:以列为主的数组与以行为主的数组
4.用支持的格式的输入来填充预先分配的设备内存支持的格式的输入。
在许多情况下,这一步仅仅意味着cudaMemcpy或其变体,以使数据可以在设备上访问。
或其变体之一,使数据可以在GPU一些库提供了自定义的传输函数,例如:cublasSetVector为CUBLAS库优化了strided copies
5. 配置要执行的库的计算。
在一些库中,这是一个没有问题的事情。其他的需要额外的元数据来执行库的计算
在某些情况下,这种配置采取了额外的形式传递给库函数的额外参数的形式,其他的则是在库处理中设置字段在库的句柄中。
6. 执行一个库调用,将所需的计算卸载到计算到GPU上。
不需要特定的GPU知识
7. 从设备内存中检索该计算的结果内存中获取计算结果,可能是以库确定的格式。
同样,这可能是一个简单的cudaMemcpy或需要 一个库专用的函数
8. 如果有必要,将检索到的数据转换为 应用程序的本地格式。
如果需要转换为库的特定格式。
这个步骤确保应用程序现在可以使用计算的数据
一般来说,最好是保持应用程序的格式和库的格式相同。一般来说,最好保持应用程序的格式和库的格式相同,以减少重复转换的开销。重复转换的开销
9. 释放CUDA资源。
包括通常的CUDA清理(cudaFree,cudaStreamDestroy,等等)以及任何库特有的清理工作。
10. 继续进行应用程序的剩余部分。





CV-CUDA
CV-CUDA是一个开源项目,使开发人员能够在云规模的人工智能TAT成像和计算机视觉TCV 工作负载中构建高效、GPU加速的预处理和后处理管道。
借助一组针对数据中心GPU性能进行手动优化的专用CV和图像处理内核,CV-CUDA可确保使用这些内核构建的处理管道得到执行,从而在整个复杂工作负载中提供更高的吞吐量。
(CV-CUDA 可以提供超过10倍的吞吐量改进和更低的云计算成本。CV-CUDA将提供与C/C++、Python的轻松集成,以及与PyTorch等常见深度学习【DL】框架的接口。
example:
#include "error.cuh"
#include <stdio.h>
#include <cublas_v2.h>
void print_matrix(int R, int C, double* A, const char* name);
int main(void)
{
int M = 2;
int K = 3;
int N = 2;
int MK = M * K;
int KN = K * N;
int MN = M * N;
double *h_A = (double*) malloc(sizeof(double) * MK);
double *h_B = (double*) malloc(sizeof(double) * KN);
double *h_C = (double*) malloc(sizeof(double) * MN);
for (int i = 0; i < MK; i++)
{
h_A[i] = i;
}
print_matrix(M, K, h_A, "A");
for (int i = 0; i < KN; i++)
{
h_B[i] = i;
}
print_matrix(K, N, h_B, "B");
for (int i = 0; i < MN; i++)
{
h_C[i] = 0;
}
double *g_A, *g_B, *g_C;
CHECK(cudaMalloc((void **)&g_A, sizeof(double) * MK));
CHECK(cudaMalloc((void **)&g_B, sizeof(double) * KN));
CHECK(cudaMalloc((void **)&g_C, sizeof(double) * MN));
cublasSetVector(MK, sizeof(double), h_A, 1, g_A, 1);
cublasSetVector(KN, sizeof(double), h_B, 1, g_B, 1);
cublasSetVector(MN, sizeof(double), h_C, 1, g_C, 1);
cublasHandle_t handle;
cublasCreate(&handle);
double alpha = 1.0;
double beta = 0.0;
cublasDgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N,
M, N, K, &alpha, g_A, M, g_B, K, &beta, g_C, M);
cublasDestroy(handle);
cublasGetVector(MN, sizeof(double), g_C, 1, h_C, 1);
print_matrix(M, N, h_C, "C = A x B");
free(h_A);
free(h_B);
free(h_C);
CHECK(cudaFree(g_A));
CHECK(cudaFree(g_B));
CHECK(cudaFree(g_C));
return 0;
}
void print_matrix(int R, int C, double* A, const char* name)
{
printf("%s = \n", name);
for (int r = 0; r < R; ++r)
{
for (int c = 0; c < C; ++c)
{
printf("%10.6f", A[c * R + r]);
}
printf("\n");
}
}














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









