






操作系统
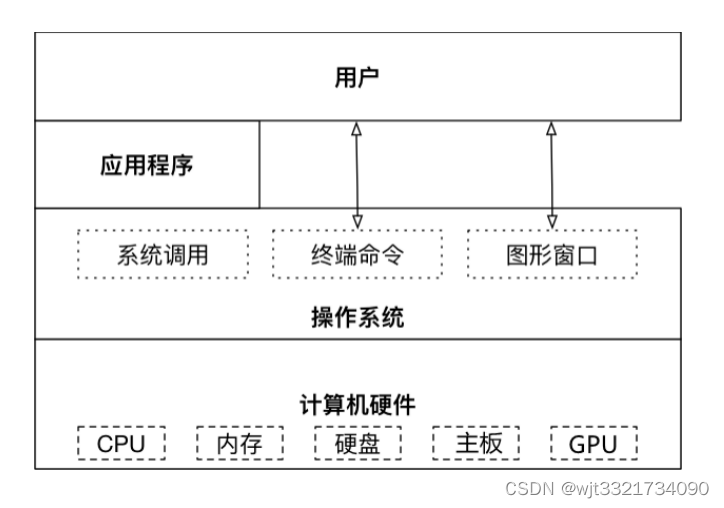
操作系统的作用:
是现代计算机系统中最基本和最重要的系统软件。
是配置在计算机硬件上的第一层软件,是对硬件系统的首次扩展。
主要作用是管理好硬件设备,并为用户和应用程序提供一个简单的接口,以便于使用。
而其他的诸如编译程序、数据库管理系统,以及大量的应用软件,都直接依赖于操作系统的支持。
X86 UBUNTU与L4T UBUNTU 的区别
X86 Ubuntu:是指运行在X86架构CPU的linux ubuntu版本的操作系统。
L4T Ubuntu: L4T是linux for tegra的缩写,Tegra是集成了ARM架构的CPU和NVIDIA的GPU的处理器芯片,所以L4T Ubuntu就是为运行在基于arm架构的Tegra芯片上的linux ubuntu版本的操作系统,它是专门为Tegra定制的Ubuntu特殊版本。
应用场景:ARM处理器定位于嵌入式平台,应用在开发板、边缘设备、
智能设备上;X86定位于桌面PC和服务器。
ARM是为了低功耗高效率设计的,而X86是为了追求高性能。
设计架构:ARM是精简指令集(RISC)架构;x86是复杂指令集(CISC)
架构。
ARM几乎都采用Linux的操作系统;X86多为window系统也可采用linux
操作系统。
UBUNTU目录结构
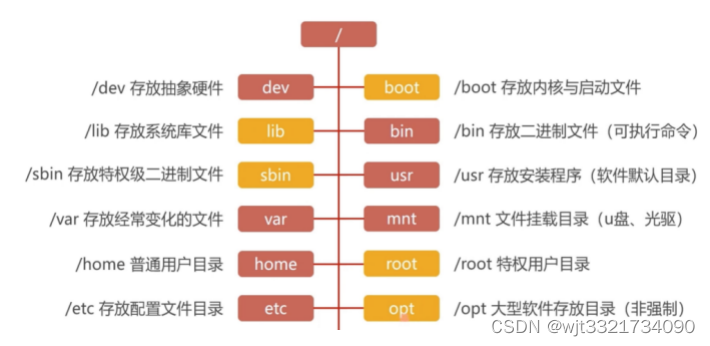
UBUNTU权限管理
exit 退出当前用户
sudo+命令 使用户可以在自己的环境下执行本需要root权限的命令
修改形式字母法:chmod(u g o a) (+ - =)(文件名)
修改形式数字法:chmod+数字组合+文件名
cd [dir] 切换到指定目录
ls [-opt][dir,file] 查看指定目录所有内容
pwd [-opt] 打印当前工作目录
cat [-opt][file] 查看文件内容/创建文件/文件合并/追加文件内容等
more [-opt] file 分页显示文件内容
touch [-opt] file 若文件不存在则创建,否则修改
mkdir [-opt] file 创建目录
mkdir -p 层级创建目录 eg.mkdir -p a/b/c
rm [-opt] file 不可恢复地删除文件或目录
rmdir [-opt] dir 删除空目录
cp [-opt] src target 复制文件或目录
mv [-opt] src/dir target/dir 移动/重命名文件或目录
find [path][-opt][exp] 在目录中搜索文件
grep [-opt][pattern][file] 在文本文件中查找内容
date 查看系统时间
cal -y 查看当年日历
df [-opt][file] 显示磁盘容量等
du [-opt][file] 显示目录下文件大小
ps [opt] 查看进程信息
top [-opt]动态显示进程有序详细信息
kill [-signal] pid 终止进程
jtop查看工具:sudo -H pip install -U jetson-stats
ifconfig [-opt]或 ip addr 查看或配置网卡信息
ping [-opt] destination 检测到目标地址链接通讯是否正常
ssh [-opt][user@hostname]
makefile
example 1:
test: test.c
gcc test.c -o testexample 2:
CC = gcc
main: main.c tool.o bar.o
$(CC) main.c tool.o bar.o -o main
tool.o: tool.c
$(CC) -c tool.c
bar.o: bar.c
$(CC) -c bar.c
clean:
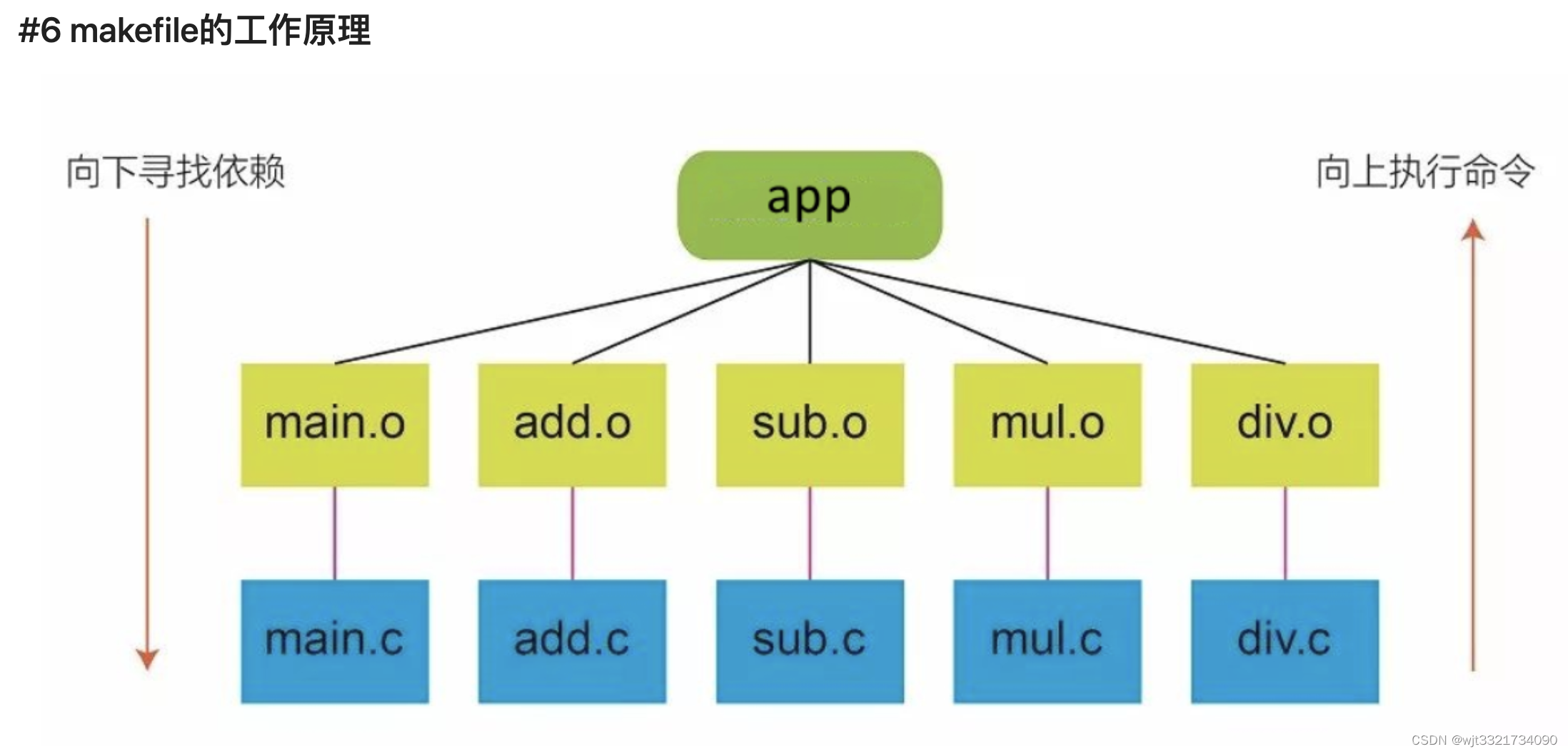
rm *.o mainexample 3:
OBJ = main.o add.o sub.o mul.o div.o
CC = gcc
app: $(OBJ)
$(CC) -o app $(OBJ)
main.o: main.c
$(CC) -c main.c
add.o: add.c
$(CC) -c add.c
sub.o:sub.c
$(CC) -c sub.c
mul.o: mul.c
$(CC) -c mul.c
div.o: div.c
$(CC) -c div.c
.PHONY : clean
clean :
-rm $(OBJ) app 什么是Makefile
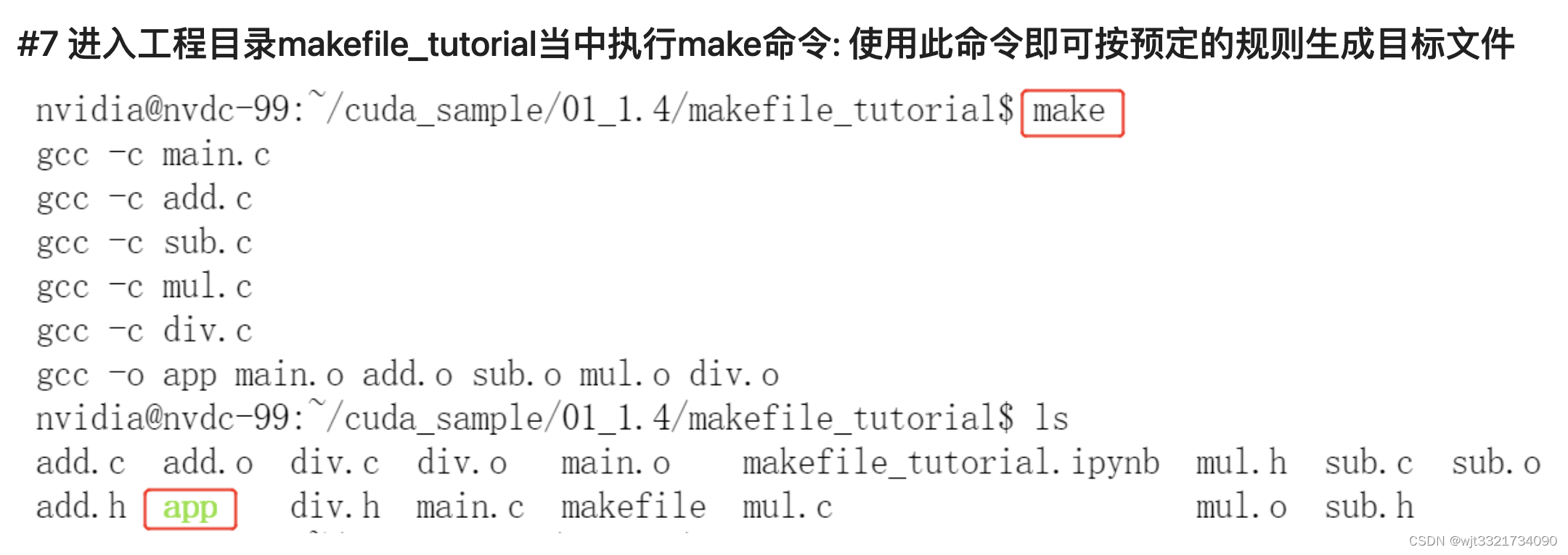
1. 一个企业级项目,通常会有很多源文件,有时也会按功能、类型、模块分门别类的放在不同的目录中,有时候也会在一个目录里存放了多个程序的源代码。这时,如何对这些代码的编译就成了个问题。Makefle就是为这个问题而生的,它定义了一套规则,决定了哪些文件要先编译,哪些文件后编译,哪些文件要重新编译。
2. 整个工程通常只要一个make命令就可以完成编译、链接,甚至更复杂的功能。可以说,任何一个Linux源程序都带有一个Makefile文件。如果能掌握Makefile文件的编写方法,就能脱离可视化编译器,使用编译链工具编译出所需的目标文件。
Makefile的优点
1. 管理代码的编译,决定该编译什么文件,编译顺序,以及是否需要重新编译;
2. 节省编译时间。如果文件有更改,只需重新编译此文件即可,无需重新编译整个工程;
3. 一劳永逸。Makefile通常只需编写一次,后期就不用过多更改。


什么是cuda?

1.编写第一个Cuda程序
- 关键词:"__global__" , <<<...>>> , .cu
在当前的目录下创建一个名为hello_cuda.cu的文件,编写第一个Cuda程序:
- 当我们编写一个hello_word程序的时候,我们通常会这样写:
#include <stdio.h>
void hello_from_cpu()
{
printf("Hello World from the CPU!\n");
}
int main(void)
{
hello_from_cpu();
return 0;
}1.当我们在讨论GPU和CUDA时,我们一定会考虑如何调用每一个线程,如何定为每一个线程。其实,在CUDA编程模型中,每一个线程都有一个唯一的标识符或者序号,而我们可以通过threadIdx来得到当前的线程在线程块中的序号,通过blockIdx来得到该线程所在的线程块在grid当中的序号,即:
threadIdx.x 是执行当前kernel函数的线程在block中的x方向的序号
blockIdx.x 是执行当前kernel函数的线程所在block,在grid中的x方向的序号- 如果我们要把它改成调用GPU的时候,我们需要在void hello_from_cpu()之前加入 __global__标识符,并且在调用这个函数的时候添加<<<...>>>来设定执行设置
- 示例:
-
#include <stdio.h> __global__ void hello_from_gpu() { printf("Hello World from the GPU!\n"); } int main(void) { hello_from_gpu<<<1, 1>>>(); cudaDeviceSynchronize(); return 0; }2.编写完成之后,我们要开始编译并执行程序,在这里我们可以利用nvcc进行编译,指令如下:
-
!/usr/local/cuda/bin/nvcc -arch=compute_72 -code=sm_72 hello_cuda.cu -o hello_cuda -run3.这里我们也可以利用编写Makefile的方式来进行编译
-
TEST_SOURCE = hello_cuda.cu TARGETBIN := ./hello_cuda CC = /usr/local/cuda/bin/nvcc $(TARGETBIN):$(TEST_SOURCE) $(CC) $(TEST_SOURCE) -o $(TARGETBIN) .PHONY:clean clean: -rm -rf $(TARGETBIN) -rm -rf *.o!make
然后我们就可以得到一个名为hello_cuda.exe的程序,我们开始执行一下
!./hello_cuda
接下来我们尝试多个文件协同编译, 修改Makefile文件:
- 编译hello_from_gpu.cu文件生成hello_from_gpu.o
- 编译hello_cuda02-test.cu和上一步生成的hello_from_gpu.o, 生成./hello_cuda_multi_file
-
TEST_SOURCE = hello_cuda02-test.cu TARGETBIN := ./hello_cuda_multi_file CC = /usr/local/cuda/bin/nvcc $(TARGETBIN):hello_cuda02-test.cu hello_from_gpu.o $(CC) $(TEST_SOURCE) hello_from_gpu.o -o $(TARGETBIN) hello_from_gpu.o:hello_from_gpu.cu $(CC) --device-c hello_from_gpu.cu -o hello_from_gpu.o .PHONY:clean clean: -rm -rf $(TARGETBIN) -rm -rf *.o!make -f Makefile_Multi_file !./hello_cuda_multi_file !make -f Makefile_Multi_file clean利用nvprof进行查看程序性能
-
!sudo /usr/local/cuda/bin/nvprof ./hello_cudaCUDA编程模型---线程组织
-
本次课程将介绍以下内容:
- 使用多个线程的核函数
- 使用线程索引
- 多维网络
- 网格与线程块
#include <stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
printf("Hello World from block %d and thread %d!\n", bid, tid);
}
int main(void)
{
hello_from_gpu<<<5,3>>>();
cudaDeviceSynchronize();
return 0;
}
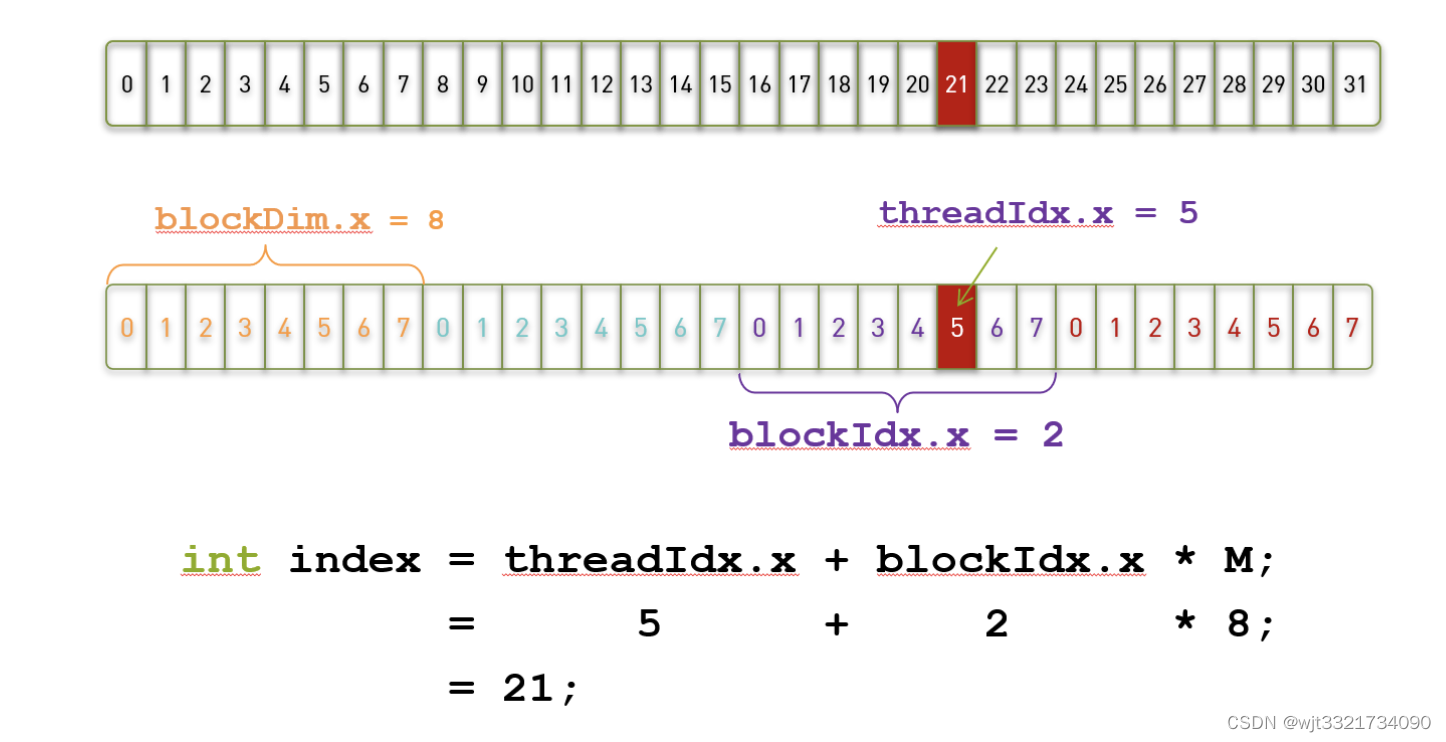
2.那我们如何能够得到一个线程在所有的线程中的索引值?比如:我们申请了4个线程块,每个线程块有8个线程,那么我们就申请了32个线程,那么我需要找到第3个线程块(编号为2的block)里面的第6个线程(编号为5的thread)在所有线程中的索引值怎么办?
这时,我们就需要blockDim 和 gridDim这两个变量:
- gridDim表示一个grid中包含多少个block
- blockDim表示一个block中包含多少个线程
也就是说,在上面的那个例子中,gridDim.x=4, blockDim.x=8
那么,我们要找的第22个线程(编号为21)的唯一索引就应该是,index = blockIdx.x * blockDim.x + threadIdx.x
接下来,我们通过完成一个向量加法的实例来实践一下,我们来实现的cpu代码如下:
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
void add(const double *x, const double *y, double *z, const int N)
{
for (int n = 0; n < N; ++n)
{
z[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{
bool has_error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
has_error = true;
}
}
printf("%s\n", has_error ? "Errors" : "Pass");
}
int main(void)
{
const int N = 100000000;
const int M = sizeof(double) * N;
double *x = (double*) malloc(M);
double *y = (double*) malloc(M);
double *z = (double*) malloc(M);
for (int n = 0; n < N; ++n)
{
x[n] = 1;
y[n] = 2;
}
add(x, y, z, N);
check(z, N);
free(x);
free(y);
free(z);
return 0;
}为了完成这个程序,我们先要将数据传输给GPU,并在GPU完成计算的时候,将数据从GPU中传输给CPU内存。这时我们就需要考虑如何申请GPU存储单元,以及内存和显存之前的数据传输。在result2中我们展示了如何完成这一过程的方法:
我们利用cudaMalloc()来进行GPU存储单元的申请,利用cudaMemcpy()来完成数据的传输
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
__global__ void add(const double *x, const double *y, double *z, int cnt)
{
int idx=threadIdx.x+blockIdx.x*blockDim.x;
if(idx<cnt)
{
z[idx]=x[idx]+y[idx];
}
}
void check(const double *z, int cnt)
{
bool flag = false;
for (int i = 0; i < cnt; i++)
{
if (fabs(z[i] - 3) > (1.0e-10))
{
flag = true;
}
}
if(flag>0) printf("Wrong!\n");
else printf("Accept!\n");
}
int main(void)
{
const int N=10000;
double* h_x=(double*) malloc(sizeof(double)*N);
double* h_y=(double*) malloc(sizeof(double)*N);
double* h_z=(double*) malloc(sizeof(double)*N);
for (int i = 0; i < N; i++)
{
h_x[i] = 1;
h_y[i] = 2;
}
double *d_x,*d_y,*d_z;
cudaMalloc((void**)&d_x,sizeof(double)*N);
cudaMalloc((void**)&d_y,sizeof(double)*N);
cudaMalloc((void**)&d_z,sizeof(double)*N);
cudaMemcpy(d_x,h_x,sizeof(double)*N,cudaMemcpyHostToDevice);
cudaMemcpy(d_y,h_y,sizeof(double)*N,cudaMemcpyHostToDevice);
const int block_size=128;
const int grid_size=(N+block_size-1)/block_size;
add<<<grid_size,block_size>>>(d_x, d_y, d_z, N);
cudaMemcpy(h_z,d_z,sizeof(double)*N,cudaMemcpyDeviceToHost);
check(h_z, N);
free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}Sobel边缘检测kernel优化
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
//GPU实现Sobel边缘检测
// x0 x1 x2
// x3 x4 x5
// x6 x7 x8
__global__ void sobel_gpu(unsigned char* in, unsigned char* out, int imgHeight, int imgWidth)
{
int x = threadIdx.x + blockDim.x * blockIdx.x;
int y = threadIdx.y + blockDim.y * blockIdx.y;
int index = y * imgWidth + x;
int Gx = 0;
int Gy = 0;
unsigned char x0, x1, x2, x3, x4, x5, x6, x7, x8;
if (x > 0 && x < imgWidth && y>0 && y < imgHeight)
{
x0 = in[(y - 1) * imgWidth + x - 1];
x1 = in[(y - 1) * imgWidth + x ];
x2 = in[(y - 1) * imgWidth + x + 1];
x3 = in[(y) * imgWidth + x - 1];
x4 = in[(y ) * imgWidth + x ];
x5 = in[(y ) * imgWidth + x + 1];
x6 = in[(y + 1) * imgWidth + x - 1];
x7 = in[(y + 1) * imgWidth + x ];
x8 = in[(y + 1) * imgWidth + x + 1];
Gx = (x0 + x3 * 2 + x6) - (x2 + x5 * 2 + x8);
Gy = (x0 + x1 * 2 + x2) - (x6 + x7 * 2 + x8);
out[index] = (abs(Gx) + abs(Gy)) / 2;
}
}
//CPU实现Sobel边缘检测
void sobel_cpu(Mat srcImg, Mat dstImg, int imgHeight, int imgWidth)
{
int Gx = 0;
int Gy = 0;
for (int i = 1; i < imgHeight - 1; i++)
{
uchar* dataUp = srcImg.ptr<uchar>(i - 1);
uchar* data = srcImg.ptr<uchar>(i);
uchar* dataDown = srcImg.ptr<uchar>(i + 1);
uchar* out = dstImg.ptr<uchar>(i);
for (int j = 1; j < imgWidth - 1; j++)
{
Gx = (dataUp[j - 1] + 2 * data[j - 1] + dataDown[j - 1])-(dataUp[j + 1] + 2 * data[j + 1] + dataDown[j + 1]);
Gy = (dataUp[j - 1] + 2 * dataUp[j] + dataUp[j + 1]) - (dataDown[j - 1] + 2 * dataDown[j] + dataDown[j + 1]);
out[j] = (abs(Gx) + abs(Gy)) / 2;
}
}
}
int main()
{
//利用opencv的接口读取图片
Mat img = imread("WechatIMG19437.jpeg", 0);
int imgWidth = img.cols;
int imgHeight = img.rows;
//利用opencv的接口对读入的grayImg进行去噪
Mat gaussImg;
GaussianBlur(img, gaussImg, Size(3, 3), 0, 0, BORDER_DEFAULT);
//CPU结果为dst_cpu, GPU结果为dst_gpu
Mat dst_cpu(imgHeight, imgWidth, CV_8UC1, Scalar(0));
Mat dst_gpu(imgHeight, imgWidth, CV_8UC1, Scalar(0));
//调用sobel_cpu处理图像
sobel_cpu(gaussImg, dst_cpu, imgHeight, imgWidth);
//申请指针并将它指向GPU空间
size_t num = imgHeight * imgWidth * sizeof(unsigned char);
unsigned char* in_gpu;
unsigned char* out_gpu;
cudaMalloc((void**)&in_gpu, num);
cudaMalloc((void**)&out_gpu, num);
//定义grid和block的维度(形状)
dim3 threadsPerBlock(32, 32);
dim3 blocksPerGrid((imgWidth + threadsPerBlock.x - 1) / threadsPerBlock.x,
(imgHeight + threadsPerBlock.y - 1) / threadsPerBlock.y);
//将数据从CPU传输到GPU
cudaMemcpy(in_gpu, img.data, num, cudaMemcpyHostToDevice);
//调用在GPU上运行的核函数
sobel_gpu<<<blocksPerGrid,threadsPerBlock>>>(in_gpu, out_gpu, imgHeight, imgWidth);
//将计算结果传回CPU内存
cudaMemcpy(dst_gpu.data, out_gpu, num, cudaMemcpyDeviceToHost);
imwrite("save3.png", dst_gpu);
//显示处理结果, 由于这里的Jupyter模式不支持显示图像, 所以我们就不显示了
//imshow("gpu", dst_gpu);
//imshow("cpu", dst_cpu);
//waitKey(0);
//释放GPU内存空间
cudaFree(in_gpu);
cudaFree(out_gpu);
return 0;
}生成结果如下:
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









