






GPU的存储单元

CPU:
malloc();
memset();
free();
GPU:
cudaMalloc();
cudaMemset();
cudaFre();
memory copy between cpu and gpu:
cudaMemcpy(oid* dst,const void* src, size_t count,cudaMemcpyKind kind)
cudaMemcpyKind:
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
cudaMemspyDeviceToDevice
cudaMemcpyHostToHost
矩阵相乘样例



#include<stdio.h>
#include<math.h>
#define block_size 16
__global__ void gpu_matrix_mul(int* a,int* b,int* c,int m,int n,int k)
{
int col=blockIdx.x*blockDim.x+threadIdx.x;
int row=blockIdx.y*blockDim.y+threadIdx.y;
int sum=0;
if(col<k&&row<m)
{
for(int i=0;i<n;i++)
{
sum+=a[row*n+i]*b[i*k+col];
}
c[row*k+col]=sum;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc,const char* argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a,*h_b,*h_c,*h_cc;
cudaMallocHost((void**)&h_a,sizeof(int)*m*n);
cudaMallocHost((void**)&h_b,sizeof(int)*n*k);
cudaMallocHost((void**)&h_c,sizeof(int)*m*k);
cudaMallocHost((void**)&h_cc,sizeof(int)*m*k);
int *d_a, *d_b, *d_c;
cudaMemcpy(d_a,h_a,sizeof(int)*m*n,cudaMemcpyHostToDevice);
cudaMemcpy(d_b,h_b,sizeof(int)*n*k,cudaMemcpyHostToDevice);
unsigned int grid_rows=(m+block_size-1)/block_size;
unsigned int grid_cols=(k+block_size-1)/block_size;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(block_size, block_size);
gpu_matrix_mul<<<dimGrid,dimBlock>>>(d_a,d_b,d_c,m,n,k);
cudaMemcpy(h_c,d_c,sizeof(int)*m*k,cudaMemcpyDeviceToHost);
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok) printf("Ac!\n");
else printf("Wrong!\n");
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
cudaFreeHost(h_cc);
return 0;
}将RGB转化为灰度图
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
//将RGB图像转化成灰度图
//out = 0.3 * R + 0.59 * G + 0.11 * B
__global__ void im2gray(uchar3 *in, unsigned char *out, int height, int width)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
if (x < width && y < height)
{
uchar3 rgb = in[y * width + x];
out[y * width + x] = 0.30f * rgb.x + 0.59f * rgb.y + 0.11f * rgb.z;
}
}
int main()
{
Mat src = imread("1.jpg");
uchar3 *d_in;
unsigned char *d_out;
int height = src.rows;
int width = src.cols;
Mat grayImg(height, width, CV_8UC1, Scalar(0));
cudaMalloc((void**)&d_in, height * width * sizeof(uchar3));
cudaMalloc((void**)&d_out, height * width * sizeof(unsigned char));
cudaMemcpy(d_in, src.data, height * width * sizeof(uchar3), cudaMemcpyHostToDevice);
dim3 threadsPerBlock(32, 32);
dim3 blocksPerGrid((width + threadsPerBlock.x - 1) / threadsPerBlock.x, (height + threadsPerBlock.y - 1) / threadsPerBlock.y);
im2gray<<<blocksPerGrid, threadsPerBlock>>>(d_in, d_out, height, width);
cudaMemcpy(grayImg.data, d_out, height * width * sizeof(unsigned char), cudaMemcpyDeviceToHost);
imwrite("save.png", grayImg);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}错误检测与事件
错误检测函数:
__host__device__const char* cudaGetErrorName(cudaError_t error)
__host__device__const char* cudaGetErrorString(cudaError_t error)
__host__device__cudaError_t cudaGetLastError(void)
__host__device__cudaError_t cudaPeekAtLastError(void)
#pragma once
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m)
{
for(int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
CHECK(cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
//cudaThreadSynchronize();
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
return 0;
}cuda的事件(event)
CUDA event本质是一个GPU时间戳,这个时间戳是在用户指定的时间点上记录的。由于GPU本身支持记录时间戳,因此就避免了当使用CPU定时器来统计GPU执行时间时可能遇到的诸多问题。
__host__cudaError_t cudaEventCreate(cudaEvent_t* event)
create an event object
__host__device__cudaError_t cudaEventCreateWithFlags(cudaEvent_t* event,unsigned int flags)
vreate an event objevct with the specified flags
__host__device__cudaError_t cudaEventDestroy(cudaEvent_t event)
destroy an event object
__host__cudaError_t cudaEventElapsedTime(float* ms,cudaEvent_t start,cudaEvent_t end)
computes the elapsed time between events.
__host__cudaError_t cudaEventQuety(cudaEvent_t event)
queries an event's status
__host__device__cudaError_t cudaEventRecord(cudaEvent_t event,cudaStream_t stream=0)
records an event.
__host__cudaError_t cudaEventRecordWithFlags(cudaEvent_t event,cudaStream_t stream=0,unsighned int flags=0)
records an event.
__host__cudaError_t cudaEventSynchronize(cudaEvent_t event)
waits for an event to complete.
流中的任意点都可以通过API插入事件以及查询事件完成的函数,只有事件所在流中其之前的操作都完成后才能触发事件完成。默认流中设置事件,那么其前面的所有操作都完成时,事件才出发完成。 事件就像一个个路标,其本身不执行什么功能,就像我们最原始测试c语言程序的时候插入的无数多个printf一样。
创建和销毁:
声明:
cudaEvent_t event;创建:
cudaError_t cudaEventCreate(cudaEvent_t* event);销毁:
cudaError_t cudaEventDestroy(cudaEvent_t event);添加事件到当前执行流:
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);等待事件完成,设立flag:
cudaError_t cudaEventSynchronize(cudaEvent_t event);//阻塞
cudaError_t cudaEventQuery(cudaEvent_t event);//非阻塞当然,我们也可以用它来记录执行的事件:
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop);#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m)
{
for(int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
CHECK(cudaEventRecord(start));
//cudaEventQuery(start);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
CHECK(cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
//cudaThreadSynchronize();
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
return 0;
}cuda存储单元
- 寄存器
寄存器是速度最快的存储单元,位于GPU芯片的SM上,用于存储局部变量。每个SM(SMX)上有成千上万的32位寄存器,当kernel函数启动后,这些寄存器被分配给指定的线程来使用。
- Local Memory
Local Memory本身在硬件中没有特定的存储单元,而是从Global Memory虚拟出来的地址空间。Local Memory是为寄存器无法满足存储需求的情况而设计的,主要是用于存放单线程的大型数组和变量。Local Memory是线程私有的,线程之间是不可见的。由于GPU硬件单位没有Local Memory的存储单元,所以,针对它的访问是比较慢的。从上面的表格中,也可以看到跟Global Memory的访问速度是接近的。
- Shared Memory
Shared Memory位于GPU芯片上,访问延迟仅次于寄存器。Shared Memory是可以被一个Block中的所有Thread来进行访问的,可以实现Block内的线程间的低开销通信。在SMX中,L1 Cache跟Shared Memory是共享一个64KB的告诉存储单元的,他们之间的大小划分不同的GPU结构不太一样;
- Constant Memory
Constant Memory类似于Local Memory,也是没有特定的存储单元的,只是Global Memory的虚拟地址。因为它是只读的,所以简化了缓存管理,硬件无需管理复杂的回写策略。Constant Memory启动的条件是同一个warp所有的线程同时访问同样的常量数据。
- Global Memory
Global Memory在某种意义上等同于GPU显存,kernel函数通过Global Memory来读写显存。Global Memory是kernel函数输入数据和写入结果的唯一来源。
- Texture Memory
Texture Memory是GPU的重要特性之一,也是GPU编程优化的关键。Texture Memory实际上也是Global Memory的一部分,但是它有自己专用的只读cache。这个cache在浮点运算很有用,Texture Memory是针对2D空间局部性的优化策略,所以thread要获取2D数据就可以使用texture Memory来达到很高的性能。从读取性能的角度跟Constant Memory类似。
- Host Memory
主机端存储器主要是内存可以分为两类:可分页内存(Pageable)和页面 (Page-Locked 或 Pinned)内存。
可分页内存通过操作系统 API(malloc/free) 分配存储器空间,该内存是可以换页的,即内存页可以被置换到磁盘中。可分页内存是不可用使用DMA(Direct Memory Acess)来进行访问的,普通的C程序使用的内存就是这个内存
example:光学跟踪



example:热传导模型
heat dissipating from warm cells into cold cells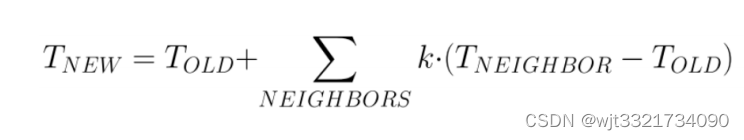


多种存储单元



Shared Memory:
The only two types of memory that actually reside on the GPU chip are register and shared memory.
所以,Shared Memory是目前最快的可以让多个线程沟通的地方。
那么,就有可能会出现同时有很多线程访问Shared Memory上的数据。
为了克服这个同时访问的瓶颈,Shared Memory被分成32个逻辑块(banks)
Successive sections of memory are assigned to successive banks

bank conflict
1.同常量内存一样,当一个 warp 中的所有线程访问同一
地址的共享内存时,会触发一个广播(broadcast)机制到warp 中所有线程,这是最高效的。
2.如果同一个 half-warp/warp 中的线程访问同一个
bank 中的不同地址时将发生 bank conflict。3.每个 bank 除了能广播(broadcast)还可以多播(mutilcast)(计算能力 >= 2.0),也就是说,如果一个warp 中的多个线程访问同一个 bank 的同一个地址时(其他线程也没有访问同一个bank 的不同地址)不会发生bank conflict。
4.即使同一个 warp 中的线程 随机的访问不同的 bank,只要没有访问同一个 bank 的不同地址就不会发生bank conflict。
没有bank conflict:

有bank conflict:

避免方法:
memory padding:

当我们在处理矩阵乘法时,假设矩阵M(m,k)*N(k,n) = P(m,n)。那么,矩阵M中的一个数值m(x,y),就要被grid中所有满足threadIdx.y+blockIdx.y*blockDim.y = y的线程从Global Memory中读一次,一共就是K次。那么,我们看到这么多重复读取,就可以把这个变量放在Shared Memory中,极大地减少每次的读取时间。










#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m)
{
for(int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
__global__ void gpu_matrix_mult_shared(int *d_a, int *d_b, int *d_result, int n)
{
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int tmp = 0;
int idx;
for (int sub = 0; sub < gridDim.x; ++sub)
{
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row<n && (sub * BLOCK_SIZE + threadIdx.x)<n? d_a[idx]:0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * n + col;
tile_b[threadIdx.y][threadIdx.x] = col<n && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0;
__syncthreads();
for (int k = 0; k < BLOCK_SIZE; ++k)
{
tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x];
}
__syncthreads();
}
if(row < n && col < n)
{
d_result[row * n + col] = tmp;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=1000;
int n=1000;
int k=1000;
int *h_a, *h_b, *h_c, *h_cc,*h_cs;
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cs, sizeof(int)*m*k));
cudaEvent_t start,stop,stop_share;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventCreate(&stop_share));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c,*d_c_share;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
CHECK(cudaMalloc((void **) &d_c_share, sizeof(int)*m*k));
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
CHECK(cudaEventRecord(start));
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c_share, n);
CHECK(cudaMemcpy(h_cs, d_c_share, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
CHECK(cudaEventRecord(stop_share));
CHECK(cudaEventSynchronize(stop_share));
float elapsed_time,elapsed_time_share;
CHECK(cudaEventElapsedTime(&elapsed_time,start,stop));
CHECK(cudaEventElapsedTime(&elapsed_time_share, stop, stop_share));
printf("time1:%g ms\n",elapsed_time);
printf("time2:%g ms\n",elapsed_time_share);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
CHECK(cudaMemcpy(h_c, d_c, sizeof(int)*m*k, cudaMemcpyDeviceToHost));
//cudaThreadSynchronize();
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
CHECK(cudaFreeHost(h_cc));
return 0;
}















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









