






一.数据类型
1.基本数据类型
- int(整型)float(浮点型)complex(虚数)bool(布尔)
- 数据有类型,变量没有类型。编译器先在内存里开辟指定数据,然后让变量指向对应的内存
2.对变量的操作
1.通用
- type()可以返回数据的类型,返回值为string类型
- id()可以返回数据或变量的地址
- abs()对整型和浮点型是求绝对值,对虚数是求模长
2.整型
- bin()oct()hex()用来将整数转为二进制,八进制,十六进制。函数的参数必须是整形,但不必须是十进制
3.复数
- 函数complex(x,y)生成复数x+yj,只传一个参数时会当做复数的实部,虚部设为0
- 方法real(),imag(),获取复数的实部或虚部,返回值是浮点数类型
- 方法conjugate(),返回共轭复数
3.类型转换
| int | float | bool | complex | |
| int | 可行 | 非0为True 0为float | 转化为实部 虚部为0 | |
| float | 截取掉小数部分 | 同int->bool | 同int->complex | |
| bool | True->1 False->0 | True->1.0 False->0.0 | True->1+0j False->0j | |
| complex | 不合法 | 不合法 | 实部和虚部都为0为False 其余为True |
二.运算符
1.逻辑运算符
- not>and>or
- and和or连接的表达式的值不一定是ture或false,而是把最后一个计算的表达式的值作为整个表达式的值
- not的结果一定是true或false
2.赋值运算符
- :=俗称海象运算符
3.算数运算符
常用计算与位运算的转化
n//2等价与n>>2
n%2等价于n&1
2**n等价于1<<n
4.三元运算符
语句1 if 判断条件 else 语句2
三.输入输出语句
输入语句input
- 无论输入什么内容,返回类型都为字符串
- input语句的内容会在输入前打印出来
输出语句print
- 使用后会自动换行
- 如果不想换行可以在后面加end=" "
- sep分隔符参数
四.注解与注释
注释
Python有#和""" """/''' '''两种注释
- 在函数内使用注释可以填写参数、返回值、函数说明,将光标移动到函数上会显示这些说明。
- 也可以用print(函数名.__doc__)的方式打印函数注释
- 将注释写在文件最上方就是文档注释,导入文件后可以用print(文件名.__doc__)或print(__import__("文件名").__doc__)的方式打印文档注释
def sum_(*n):
"""
求和函数
:param n: 输入一组数
:return: 这些数的和
"""
ret = 0
for i in n:
ret += i
return ret
print(sum_(1, 2, 3))# 6
print(sum_.__doc__)
"""
求和函数
:param n: 输入一组数
:return: 这些数的和
"""注解
- 类型注解不会真正对类型做验证和判断,当注解类型和实际类型不一样时不会报错,但编辑器会警告
1.变量类型注解
变量:类型
num1: int = 10
teacher_1: teacher = teacher(“huahau”,21)
容器类型注解
my_list: list = [1,2,3]
容器类型详细注解
my_list: list[int] = [1,2,3]
my_tuple: tuple[int,str,bool] = (1,"hello",True)
my_dict: dict[str,int] = {“hello” : 1}
元组每个元素都要注解
字典要给键和值都注解
注释类型注解,支持详细注解
num1 = 10 #type:int
2.函数(方法)类型注解
def 函数方法名(变量名 :类型……)-> 返回值类型
- 传入的是一个函数时可以写成callable[[参数类型],返回值类型]
- 注解自定义类型后,使用变量会显示相应方法和成员变量
def sum(arr :list)-> int :
3.Union类型注解
在typing这个包中
my_dict: dict[str,Union[int,str] = {“hello” : 1,“age” : “20”}
五.数据结构
1.列表 list[]
- 有序,可变
- 属于顺序结构可以用下标访问
- list[start:end:step]切片,start默认为0,end默认为末尾,step默认为1,第一个:不能省略。需要注意的是切片的索引不会导致下标越界,start超出范围会自动调整为0,end超出范围会自动调整为-1
- 元素可重复,可以是不同类型
方法
增
insert(index,val)在下标处插入值
append(val) 在末尾追加值,可以追加多个
extend(list)将可迭代对象的所有元素加入
删
remove(num)删除首次出现的num,num不存在时报错
pop(index)删掉指定位置的值并返回,没有指定位置默认删除最后一个位置
clear()清空
查
index(num)返回num第一次出现的下标
count(num)返回num出现的次数
reverse()逆序
函数
del list[index]删掉指定位置的值不返回,可以使用切片,索引越界时返回空
len(name)获取长度
all当所有值为真或空列表时返回真
any当元素有真时返回真
2.元组 tuple()
- 有序,不可变,可重复
- 元组不可以删除,修改,增添元素,相当于不可变的列表。
- 如果元组只有一个元素,这个元素后面必须在后面加逗号,如果不加会删除多余的括号变成string
- 元组内的列表可以修改
方法
index(num)查找元素下标
count(num)统计某个元素出现的次数
函数
len(tuble)长度
元组解包
在变量前加*表示不定长,当定长和不定长混合时会先给定长变量赋值,然后将剩下的赋值给不定长。解包操作还可以作用在列表,集合,字典,字符串上。解包可以用于函数参数中。
a, *b, c = 1, 2, 3, 4, 5, 6
print(a) # 1
print(b) # [2, 3, 4, 5]
print(c) # 6# 字典解包时只会解包字典的键
a, *b, c = {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
print(a) # a
print(b) # ['b', 'c', 'd', 'e']
print(c) # f
a, *b, c = "python"
print(a) # p
print(b) # ['y', 't', 'h', 'o']
print(c) # n
3.字符串
- ord()字符转ascll码,chr() ascll码转字符
- 不可修改
- 函数eval()可以提取字符串的内容,不建议用
# 字符串转列表,元组会将字符串每个字符取出
str = 'hello world'
print(list(str))
# ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']
print(tuple(str))
# ('h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd')
# 列表转字符串不可以使用str(),要用join方法
arr = ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']
# print(str(arr))
print(''.join(arr))
# hello world
1字符串定义
- 字符串可以用单引号,双引号,三引号定义,使用三引号时可以换行
- 字符串内部需要出现引号时,可以使用与定义时不同的引号
- 字符串内部需要出现与定义时相同的引号可以在引号前加\
str = "hello\"word"2字符串拼接
- 字符串之间可以用+进行拼接
- 只能用于字符串与字符串之间
3字符串格式化
方法一
- 通过占位符进行字符串拼接
- 多个变量拼接时变量要用括号括住,并用逗号隔开


| 占符 | 功能 |
|---|---|
| %s | 将变量转化为字符串进行拼接 |
| %d | 将变量转化为整数进行拼接 |
| 将变量转化为浮点数进行拼接 |
age = 18
height = 180.1
name = "小明"
message = "%s今年%d岁了身高为%f" % ( name , age , height )
print(message)
- 精度控制:利用m.n可以对数据进行精度控制,m为宽度,n为小数点精度
- m小于数字位数时不会生效,大于数字位数时会在前面补足空格
- n会进行四舍五入
age = 18
height = 180.58
name = "小明"
message = "%s今年%3d岁了身高为%.1f" % ( name , age , height )
print(message)

方法二
" ".format( )
<参数序号>:<格式控制标记>>

| b | 二进制格式 |
| c | 把整数转换成 Unicode 字符 |
| d | 十进制格式 |
| o | 八进制格式 |
| x | 小写十六进制格式 |
| X | 大写十六进制格式 |
| e/E | 科学计数法格式 |
| f/F | 固定长度的浮点数格式 |
| % | 使用固定长度浮点数显示百分数 |
| +、-、# | 表示填充字符 |
方法三
f-string
f"{变量1}具体内容{变量2}"

age = 18
height = 180.58
name = "小明"
message = f"%{name}今年{age}岁了身高为{height}"
print(message)
上面几种格式化方式还适用于表达式
print("1*1的结果为%d" % (1*1))
print(f"1*1的结果为{1*1}") 
4方法
index(string,start)返回查找内容从start位置开始第一次出现的起始下标,没有找到时返回ValueError异常
find(string,start) 返回查找内容从start位置开始第一次出现的起始下标,没有找到时返回-1
replace(string1,string2)将1替换为2,没有修改原字符串,而是返回一个新字符串
split(分割符)按照分割符分割字符串,返回一个列表
strip(string)去除前后指定字符串,参数不写就会去除空格
count(num)统计某个元素出现的次数
upper()全部转化为大写
函数
len(tuble)长度
4.字典 dict{}
- 无序,可变,不可重复
- 由键值对构成,键是唯一的,必须使用不可变的数据类型
- 非顺序结构,没有下标,只能通过键访问
- 可以嵌套
- 遍历字典是遍历它的键
- 字典转换为列表,元组,集合只将键放入列表
方法
keys()以dict_keys类型返回所有键
values()以dict_values类型返回所有值
items() 以dict_items类型返回可遍历的(键, 值) 元组数组
fromkeys(可迭代对象,值)用可迭代对象为键,值为值创建一个字典,可迭代对象有值重复时,只会生成一个键
增
setdefault(键,值)如果字典里不存在这个键,则增加键值对,返回值。如果字典里存在这个键,不作任何操作,并且返回字典中这个键对应的值,注意不是自己传入的值
查
get(键,默认值)根据键返回值,键不存在时返回默认值(需要传入),没传入时返回None
删
clear()清空字典
pop(key,默认值)删除key的键值对并返回值。如果键不存在返回默认值(需要给定),否则引起keyerror
popitem()以元组的形式返回最近的项
del (dict)
del (key)
改
dict1.update(dict2) 如果两个字典有相同的键,会使用dict2中的值来更新dict1中相应键的值。如果dict2中的某个键在dict1中不存在,这个键-值对会被添加到dict1中,此方法会修改原字典
函数
len()键值对数量
5.集合 set{}
- 集合的元素必须可哈希(不可变)
- 不可重复,无序
- S | T 在集合 S 和 T 的所有元素
- S - T 在集合 S 但不在 T 中的元素
- S & T 同时在集合 S 和 T 中的元素
- S ^ T集合 S 和 T 中非相同元素
- S = T 或 S < T 返回 True / False ,判断 S 和 T 的子集关系
- S >= T 或 S > T 返回 True / False ,判断 S 和 T 的包括关系
set1.update(set2) 将set2的内容加入到set1
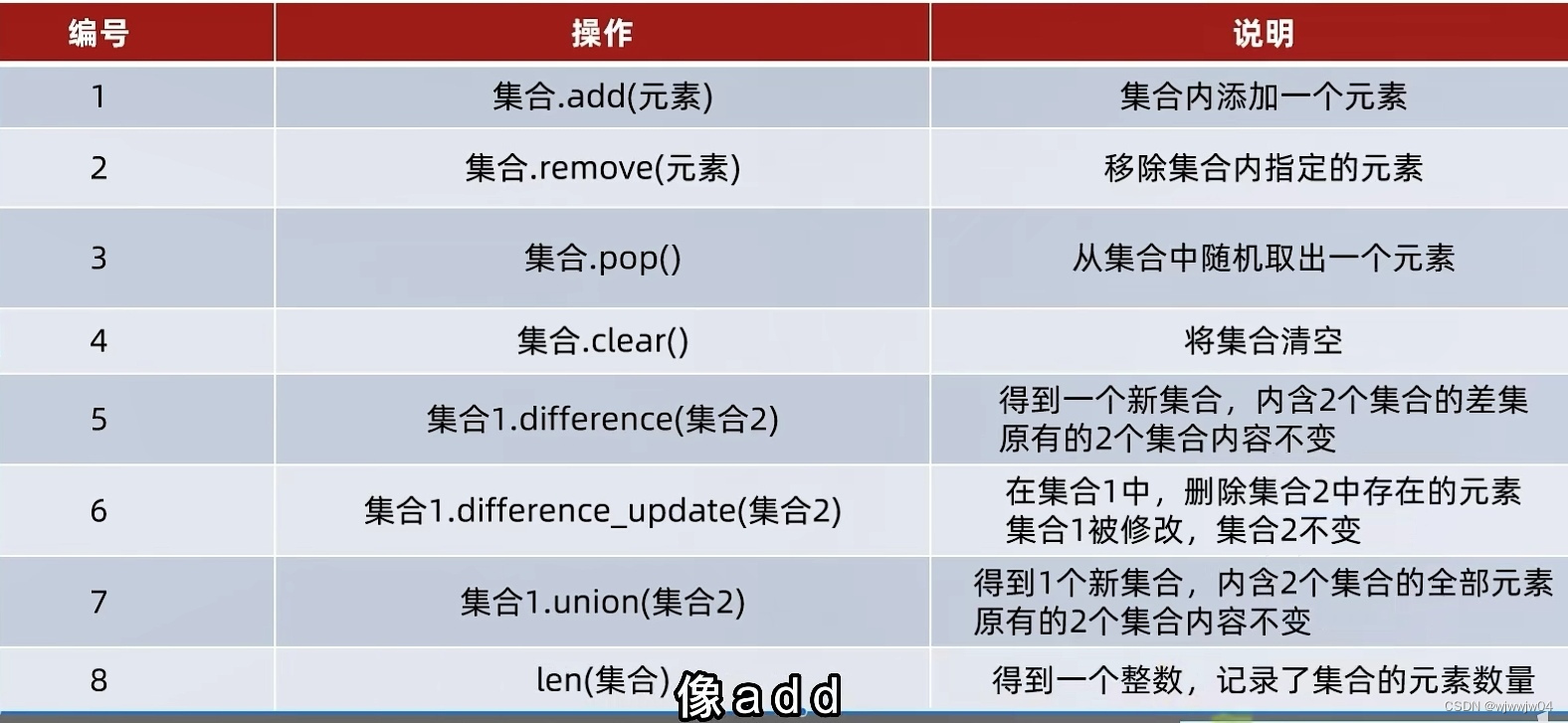
6.总结
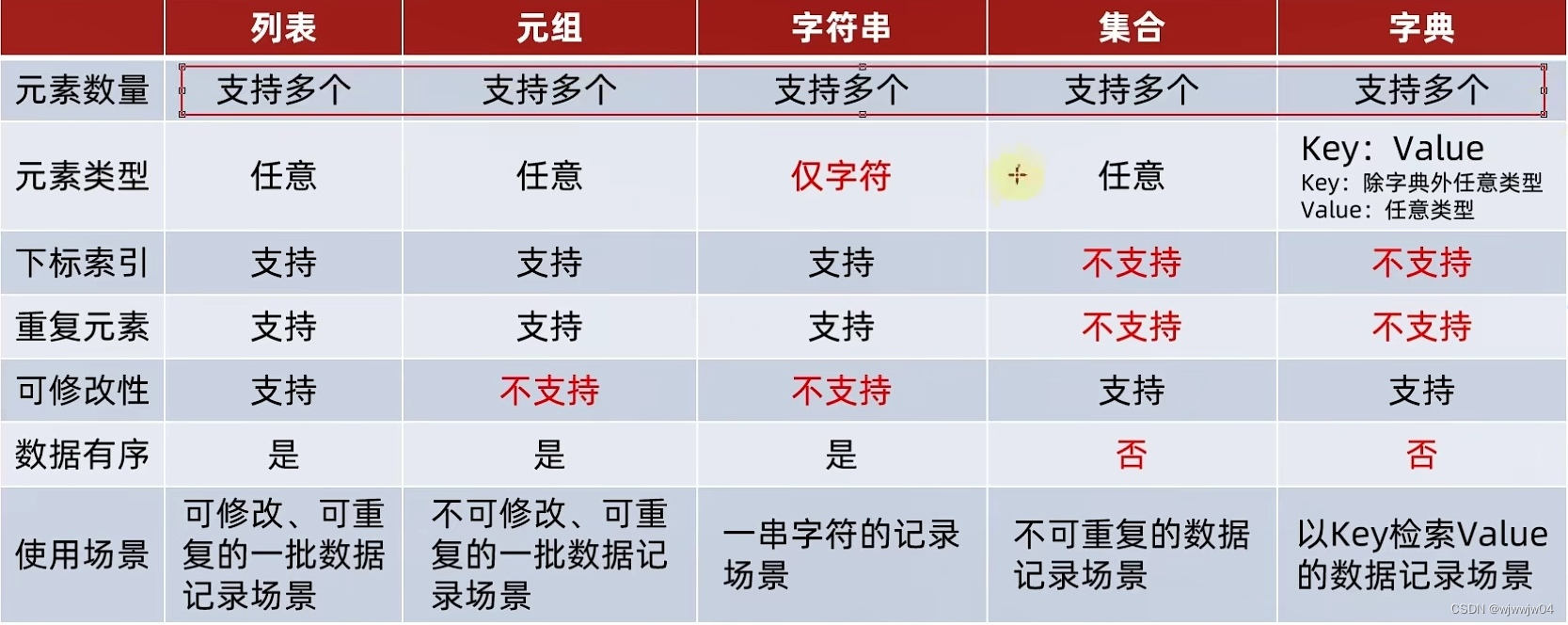
| list | tuple | set | dict | str | |
| list | 合法 | 合法 | 非法 | 整个list直接转化为str 如果需要每个元素连接在一起可以用join方法 | |
| tuple | 合法 | 合法 | 非法 | 同list->str | |
| set | 合法 | 合法 | 非法 | 同list->str | |
| dict | 合法 | 合法 | 合法 | 同list->str | |
| str | 合法 | 合法 | 合法 | 非法 |
如果需要哈希计数可以这样写
arr = "python"
dic = {}
for i in arr:
dic[i] = dic.get(i, 0) + 1
print(dic)7.通用操作
len
max
min
sorted(对象,key ,reverse=False)递增排序,返回为列表,如果要递减把reverse改为true ,不改变原列表,返回一个新列表,key为自定义比较函数
8.推导式
- 表达式 for 变量 in 可迭代对象 if 条件
- 元组没有推导式
- 推导式的效率比for循环高
# 生成二维矩阵
arr = [[i * 5 + j for j in range(1, 6)] for i in range(0, 5)]
print(arr)
'''
[
[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]
]
'''# 平铺嵌套列表
vec = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
arr = [j for i in vec for j in i]
print(arr)
# [1, 2, 3, 4, 5, 6, 7, 8, 9]注意:生成二维列表时不要用列表的*操作。通过查看每一行的地址可以发现,每一行的地址是相同的,当修改一行中的一个元素时,其他行的相应元素也发生变化。应该使用for循环或列表推导式。
arr = [[1, 2]] * 5
print(arr)
# [[1, 2], [1, 2], [1, 2], [1, 2], [1, 2]]
arr[1][1] = 3
print(arr)
# [[1, 3], [1, 3], [1, 3], [1, 3], [1, 3]]
for i in arr:
print(id(i))
'''
1872437963584
1872437963584
1872437963584
1872437963584
1872437963584
'''arr = [[1,2] for _ in range(0,5)]
print(arr)
# [[1, 2], [1, 2], [1, 2], [1, 2], [1, 2]]
arr[1][1] = 3
print(arr)
# [[1, 2], [1, 3], [1, 2], [1, 2], [1, 2]]
for i in arr:
print(id(i))
'''
1422633990144
1422634384960
1422634384896
1422634384704
1422634384576
'''9.生成器表达式
- (表达式 for 变量 in 可迭代对象 if 条件)
- 生成器表达式的结果是一个生成器对象,具有惰性求值的特点,只在需要时生成新元素(并且每个元素只生成一次)
- 使用生成器对象的元素时,可以根据需要将其转化为列表或元组,也可以使用生成器对象的__next__()方法或者内置函数 next ()进行遍历,或者直接使用 for 循环来遍历其中的元素。但是不
- 生成器具有记忆性,当一次遍历生成器遍历到某个位置停止后,下一次遍历会从上一次中断的地方继续开始遍历
其他数据结构
- collections库里Counter是以dict为父类实现的哈希计数器
- queue在collections里
方法
pop
popleft
append
appendleft
六.循环
1.for……in…… :
遍历列表无法定义循环条件
for i in list :
print(i)2.range 整数列表
一个参数 range(end)默认从0开始
两个参数 range(start,end)
三个参数 range(start,end,step)
左闭右开,不包括end
3.
total = 0
count = 0
for i in range(101):
total = total + i
count = count + 1
total累加 count计数器
七.函数
1.函数定义
def function(num):
#代码
return
2.函数参数
- 位置参数(位置参数):按照传入的顺序和函数定义时参数的顺序读取参数
- 关键字参数:使用键=值的形式传递参数,不要求参数顺序,位置参数必须放在关键字参数前面
- 默认参数:在函数定义时对参数赋值,函数调用时可以传入也可以不传入,不传入时使用默认值,定义时必须默认参数在最后面
- 函数也可以作为参数传入另一个函数中这时传入的是函数的运算逻辑
- 不定长参数:使用时传入参数数量不定,函数定义时在参数前加*,所有参数会被放入一个元组中,形式参数一般命名为args。在参数前加**,要以键=值的形式传入,所有参数会被放入一个字典中,形式参数一般命名为kwargs
Python 函数参数的传递方式是按值传递,但是这里的“值”对于可变类型(如列表、字典等)来说,传递的是对象的引用,而不是对象本身。这意味着在函数内部对可变类型参数进行修改,会影响到原对象。但这并不意味着是按引用传递,因为Python仍然遵循按值传递的原则,只不过对于可变类型,这个“值”是对象的引用。
在函数内部对可变类型参数进行修改,会影响到原对象。在函数内部将可变类型参数重新绑定,不会影响到原对象。这是因为函数内部的参数只是原对象引用的一个拷贝,重新绑定这个拷贝并不会影响到原始的引用。
def f(*args, **kwargs):
print(args)
print(type(args))
print(kwargs)
print(type(kwargs))
f(1, 2, 3, dog=12, cat=34)
"""
(1, 2, 3)
<class 'tuple'>
{'dog': 12, 'cat': 34}
<class 'dict'>
"""
f([1, 2, 3], {'a': 12, 'b': 13})
"""
([1, 2, 3], {'a': 12, 'b': 13})
<class 'tuple'>
{}
<class 'dict'>
"""3.变量作用域
- 局部变量:定义在函数内的变量,只在函数内有效
- 全局变量:定义在函数外的变量,在整个程序都能访问,在函数里也可以不传入直接使用
- 在函数内可以使用global来说明这是全局变量
4.函数返回值
- Python中函数可以有多个返回值,return 返回值1,返回值2,需要使用多个变量按照返回值的数量和顺序接收。a,b=function()
5.lambda匿名函数
语法:函数名(lambda 传入参数 :函数体(一行代码))
- 匿名函数只能使用一回
- 函数体只能有一行
6.闭包
1.条件(要同时满足)
- 在外层函数内定义了内层函数
- 内层函数使用了外层函数的变量
- 外层函数的返回值是内层函数
这时内层函数就是闭包
2.作用域
内层函数可以使用外层函数定义的变量,只可访问不可修改
7.装饰器
装饰器是闭包的具体应用,可以在已有函数的基础上为它附加功能。
可以多个装饰器包装同一个函数
标准写法
def robot(oldfunc):
def newfunc(*args,**kwargs):
ret = oldfunc(*args,**kwargs)
return ret
return newfunc# 不含参数装饰器
def robot(oldfunc):
def newfunc():
print("-" * 30)
oldfunc()
print("-" * 30)
return newfunc # 注意这里的函数没有括号,返回的不是函数调用
@robot
def show():
print("python")
show()
"""
------------------------------
python
------------------------------
"""# 含参
def robot(oldfunc):
def newfunc(s):
print("-" * 30)
oldfunc(s[::-1]) # 这里传入的参数可以和newfunc的参数不一致
print("-" * 30)
return newfunc
@robot
def show(s: str):
print(s)
show("hello")
"""
------------------------------
olleh
------------------------------
"""注意: 当尝试在嵌套函数内部修改一个外部作用域的变量时,python 默认会在局部作用域中查找该变量。如果没有找到,它会在包含作用域中查找,但是如果找到的是一个只读变量(例如函数参数或外部函数的局部变量,且未使用 nonlocal 或 global 声明),尝试修改它会导致一个错误。nonlocal 关键字告诉 python 我们想要修改的是外部作用域的变量,而不是创建一个新的局部变量。
例子
计数器
def robot(oldfunc):
count = 0
def newfunc(s):
nonlocal count # 使用nonlocal关键字声明我们要修改的是外部作用域的变量
oldfunc(s)
count += 1
print(f"函数调用了{count}次")
return newfunc
@robot
def show(s: str):
print(s)
show("hello")
show("hello")
show("hello")
"""
hello
函数调用了1次
hello
函数调用了2次
hello
函数调用了3次
"""
# 注意:在这个例子中,我们使用了nonlocal关键字来明确指定我们要修改的是外部作用域的变量count。
# 如果不使用nonlocal,Python会尝试在局部作用域中查找count变量,如果找不到会抛出一个错误。
# 当你在闭包内修改一个在外层作用域定义的变量时,通常需要nonlocal关键字。注
使用递归函数时可以调用functools库中的lru_cache
装饰器来加速递归,原理是记忆化搜索。
八.文件
1.打开
1.open函数
open(name,mode,encoding)
- name:文件名,可以包含文件路径。没有路径时在Python下查找
- mode:模式,有r只读,w写,a追加。当文件不存在时w,a会创建新文件。w会删除原有内容
- encoding编码格式,用关键字参数直接指定,推荐UTF-8
2.读取
1.read方法
read(num)
- 按字符数读取数据,如果没有传入num会读取文件里的所有数据
- 使用多个read会从上一次读取的位置开始继续读取
2.readlines()方法
- 按行把整个文件的内容一次性读取,返回一个列表,每一行的数据为一个元素
- 从上一次读取位置开始继续读取
3.readline()方法
- 只读一行
4.for
- 用for循环也可以读取,一次读取一行
3.关闭
1.close方法
- 内置flush
2.with open()as 变量名 :
- 执行完代码块以后自动关闭文件
- open和函数open一样
4.写入
1.write()
将内容写入到内存中
2.flush()
将内存中的写入到硬盘文件中,close也有此功能
5.seek()方法
移动文本指针
九.异常
在Python中,异常是一种特殊的对象,通常是Exception类或其子类的实例。这些类定义了如何处理程序中出现的错误或异常情况。当Python解释器在执行程序时遇到错误时,它会抛出一个异常对象。如果程序没有捕获和处理这个异常,那么程序就会终止运行并显示一个错误消息。
Python内置了许多异常类,如ValueError、TypeError、IndexError等,用于表示不同类型的错误情况。此外,程序员还可以定义自己的异常类,这些类应该继承自内置的Exception类或其子类。
总之,异常在Python中是通过类来实现的,这些类提供了一种机制来处理程序运行时的错误情况。
- 异常具有传递性,都没有捕获时会报错
raise语句:
当使用raise语句时,可以抛出一个异常类的实例,或者只是抛出异常类本身(这会导致Python自动创建一个不带任何参数的异常实例)。在try/except语句块中,可以使用except子句来捕获并处理特定的异常。
n = int(input())
try:
if n < 100:
raise ValueError("输入数的平方小于 100!")
else:
print(n ** 2)
except Exception as e:
print(e)assert语句:
assert是一个用于调试目的的语句,它用于测试一个条件是否为真。如果条件为真,assert语句什么也不做;如果条件为假,它会引发一个AssertionError异常。这在你想要确保代码中的某个条件总是为真时特别有用。
n = int(input())
try:
assert n>=100,"输入数的平方小于 100!"
print(n**2)
except Exception as e:
print(e)1.捕获异常
try:
可能发生错误的代码
except:
如果出现异常执行的代码
2.捕获指定异常
try:
可能发生错误的代码
except 具体异常 as 变量:
如果出现异常执行的代码
用变量保存异常
try:
可能发生错误的代码
except (异常1,异常2……) as 变量:
如果出现异常执行的代码
捕获多个异常
3.捕获全部异常
try:
可能发生错误的代码
except Exception as 变量:
如果出现异常执行的代码
4.
try:
可能发生错误的代码
except Exception as 变量:
如果出现异常执行的代码
else:
没有异常执行的代码
finally:
有无异常都要执行的代码
else和finally都是可选项
八.模块
1.导入
import 模块名 as 别名(可选)
from 模块名 import *
from 模块名 类,变量,方法
from 模块名 import 功能名 as 别名
- 如果导入了不同模块的同名功能后面的会覆盖前面的
- 使用import导入的对象要使用模块名.对象名的形式访问
- 使用form导入的对象不需要要使用模块名.对象名的形式访问,直接使用对象名即可
- 当以模块形式导入时__name__会被自动设置为模块名,作为程序直接运行时__name__被自动设置成“__main__”
- 导入模块时会执行模块内的全部代码,如果不想让部分代码执行可以 下面这样做,只有模块作为主函数运行时才会执行。
if __name__==“__main__”:
代码
- __all__=[]使用import*只会导入列表里指定的功能
2.包
1.创建
文件夹内有模块和__init__.py时就是一个包
2.导入
import 包名.模块名
from 包 import 模块名
from 包.模块 import 类,对象,变量
__all__=[]写在__init__.py控制导入对象
3.安装第三方包
在命令行输入
pip install 包名
pip install -i 网站 包名
从指定网站安装
九.类与对象
class teacher :
def __init__(self,name,age)
self.name = name
self.age = age_
- teacher是类名
- __init__(self)是初始化函数,注意init前后有两个下划线
- 可以不写任何东西用pass代替
- 类变量在构造函数外定义,通过类名访问或修改
1.成员变量
name,age就是teacher的属性
- _xxx保护成员,一般建议在类对象和子类对象中访问这些成员,不建议在类外部通过对象直接访问
- __xxx私有成员,一般只有类对象自己能访问,子类对象也不能直接访问该成员。但在类外部可以通过对象名._类名__xxx这样的特殊形式访问
- __xxx__系统定义的特殊成员
2.方法(成员函数)
- 公有方法,私有方法
- 实例方法定义时必须有参数self,使用方法时,self会自动传入,在方法内部想要访问成员变量必须用self
- 静态方法和类方法都可以通过类名和对象名调用,但在这两种方法中不能访问属于对象的成员,只能访问属于类的成员
- 类方法:@classmethod 静态方法:@staticmethod
- 一般以cls作为类方法的第一个参数表示该类自身,在调用类方法时不需要为该参数传值
- 静态方法可以不接受任何参数
3.对象
类是对象的模板 对象是类的实例
teacher_1 = teacher(“huahau”,21)
#类的实例化,不需要传入self,实例化时自动执行初始化函数
4.魔术方法
1.构造方法
class teacher :
name = None
age=None#可以省略
def __init__(self,name,age)self.name = nameself.age = age
- teacher是类名
- __init__(self)是初始化函数,注意init前后有两个下划线
- 构建对象时会自动运行
2.

- __repr__返回的字符串应该是一个有效的Python表达式,而__str__返回的字符串主要用于向用户展示。
- 在没有定义__str__方法的情况下,Python会调用__repr__方法以获取对象的字符串表示,这通常用于调试。但在需要向用户展示对象时(比如通过print函数),最好定义__str__方法。
5.封装
私有成员和私有变量在定义前要加__两个下划线
用户无法使用,类内成员可以使用
6.继承
单继承
class 类名 (父类名):
类内容体
多继承
class 类名 (父类名):
类内容体
- 多继承是相同的成员方法和成员变量,写在前面的父类名优先级高
- 子类默认不继承父类的构造函数,子类的构造函数可以用 super().__init__() 或 父类名.__init__(self) 调用父类的构造函数,最好避免使用super
7.复写
在子类中重新定义与父类同名的成员属性或方法
如果复写后需要调用父类的成员或方法可以
1.父类名.成员变量
父类名.成员方法(self)
2.super().成员变量
super().成员方法
不加self
8.多态
多种状态,完成某个行为时,使用不同的对象会得到不同的状态,常作用在继承关系上。
- 如函数形参接收父类对象,实际传入子类对象工作
- 抽象类:含有抽象方法的类为抽象类,抽象方法:方法体是空实现(pass)的类为抽象方法
需要子类复写父类
注意:
下面的程序是定义了一个类并且实例化,是可以运行的。如果加上注释掉的部分就会有一条这样的报错maximum recursion depth exceeded,递归调用深度过大。先介绍一下这两个装饰器,装饰器前的名字必须和修饰的方法一样,@property定义一个可读属性,如果没有@<property>.setter这个装饰器,那么属性就是只读的,有这个装饰器就变成了可读写的,每当你访问这个属性时会调用getting方法,当你试图修改时会调用setting方法。问题就在这里,当我们修改name时会调用一次name的setting方法,方法里有这样一条语句self.name = name解释器会试图寻找名为name的属性,无论这个属性是变量还是方法(不要认为name后没有加括号就代表调用的一定是变量而不是方法,解释器只是寻找名为name的属性)name被定义成了方法,解释器就会在这一句执行方法,就又调用了name的setting方法,就这样形成了无限循环。修改的方法就是避免方法的名字和变量的名字一样,可以在变量名前加一个下划线来区分他们。
如果没有装饰器就不会发生这样无限调用的情况,果你不为 name 方法加上装饰器,那么 name 就仅仅是一个普通的实例方法。当你尝试在 __init__ 方法中设置 self.name = name 时,Python 解释器会直接为这个实例创建一个名为 name 的属性,并赋予其提供的值 name。在这种情况下,不会有任何递归调用发生,因为你没有定义一个方法来捕获这个赋值操作。
class Singer:
def __init__(self, name):
self.name = name
# @property
# def name(self):
# return self.name
#@name.setter
#def name(self, name):
# self.name = name
n = Singer('**')十.高级函数
1.zip
zip(*iterables)
- 该函数将可迭代对象作为参数并返回一个迭代器。此迭代器生成一系列元组,其中包含来自每个可迭代对象的元素。 zip() 可以接受任何类型的可迭代对象,例如文件、列表、元组、字典、集合等。
- 如果参数只有一个迭代器,会返回一个生成一系列单项元组的迭代器
- 如果传入多个可迭代对象,并且长度不同,返回的迭代器长度为最小的可迭代对象长度
- 如果没有传入参数会返回一个空列表
2.map
map(function,iterable1,……)
- 将指定函数依次作用于可迭代对象的每个元素,并返回一个迭代器对象
3.filter
filter(function,iterable)
- 将可迭代对象的每个元素传给函数进行判断,并返回所有判断为True的元素,返回一个迭代器对象
- 返回的迭代器对象只能执行一次,想多次使用可以转换为list
十一.常用模块
1.random随机数库
常用:
random.random()生成一个[0,1)范围内的随机浮点数
random.randint(a,b)生成一个[a,b]范围内的随机整数
random.randrange(start,end[,step])生成一个范围内的随机整数,可以指定步长
random.uniform(a,b)生成一个[a,b]范围内的随机浮点数
random.choise(arr)从一个序列中随机选择一个元素
random.shuffle(arr)随机打乱序列的顺序,直接修改原序列
random.sample(arr,k)从序列中随机选择k个元素,返回列表
2.time
time.time()获取当前时间的时间戳
time.localtime()将时间戳转化为当前时区的struct_time
time.strftime(str,struct_time)将struct_time格式化
%Y 四位数年
%y 两位数年
%m 月
%d 日
%H 时
%M 分
%S 秒
3.datetime

datetime.datetime.now()
datetime.datetime.strftime()
十二.常用函数
divmod(x,y)返回x和y的商和余数
round(num,bit)将num四舍五入到bit位,bit默认是0
json转换不同编程语言中的数据
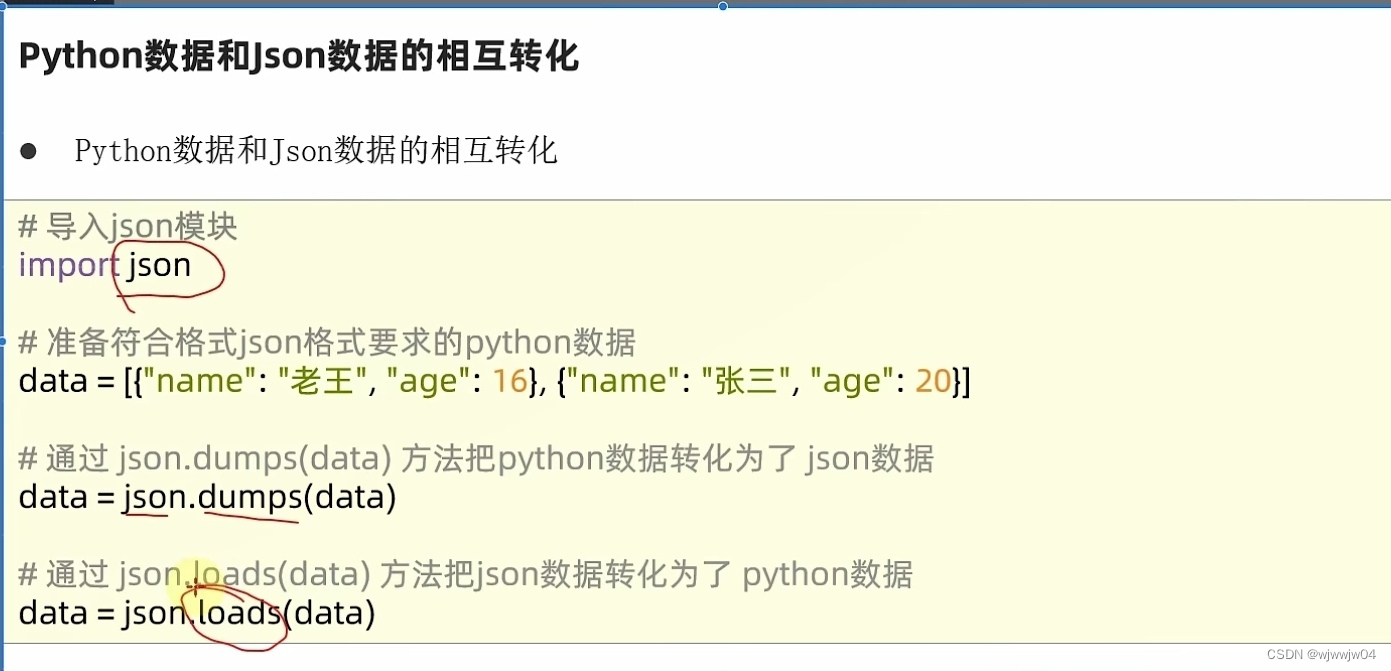
如果要正确现实中文,dumps传入ensure_ascii=False关掉acsii码转换















 32万+
32万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









