







我们知道,被测对象期望是“干系方对于被测对象质量特性的预期”。因为质量特性一定会受各种外部条件的影响,所以被测对象期望本质上是一种因果关系,也就是“在什么条件下,被测对象应该有什么特性”。“因”和“果”,是被测对象期望里的两大要素。
假设我们要测试一台车,被测对象期望是:“在各种路况条件下,提供全面的驾驶安全性保障”,其中“因”的部分就是“在各种路况条件下”,“果”的部分就是“提供全面的驾驶安全性保障”。
期望的具象化分解,实际上是针对“因”进行的分解,比如把“各种路况条件”分解成铺装道路、越野道路、湿滑道路3种条件:
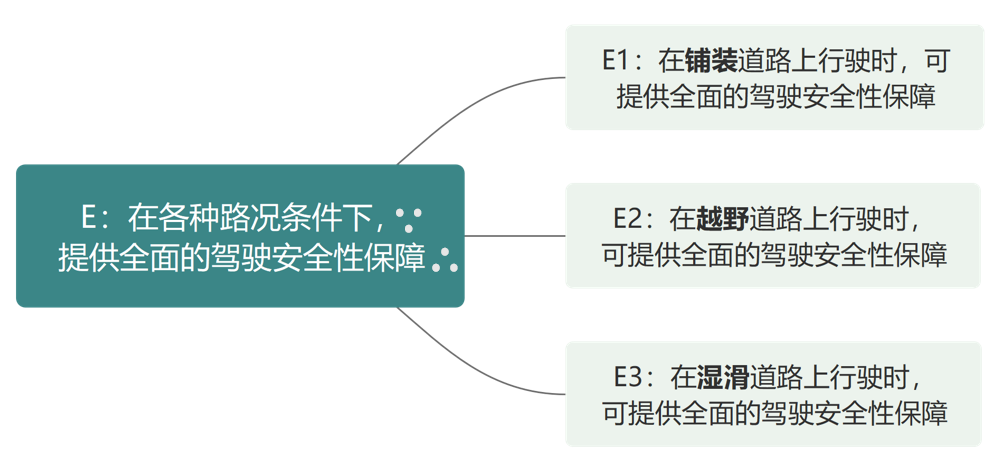
这样,原始期望就被分解成3个子期望,原始期望的测试输入空间,就被细分成3个比较小的子空间,在这些子空间里选取用例,相对来说就简单一些。所以我们说,具象化分解是用来缓解测试选择问题的。
另一方面,我们也可以针对“果”进行分解,比如把“提供全面的驾驶安全性保障”,分解成3种子目标:
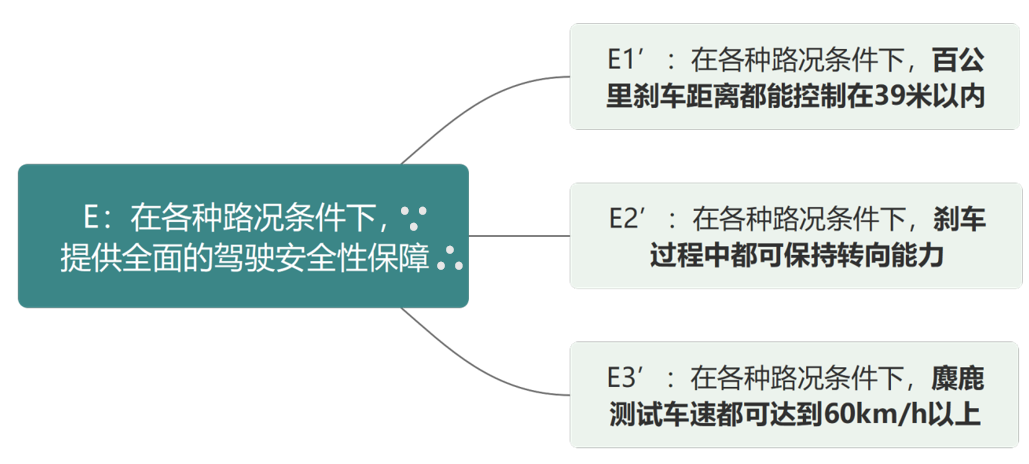
比起“提供全面的驾驶安全性保障”,这些子目标都只关注单一的安全性指标,相对来说更容易进行观察和验证,这就可以帮助我们缓解测试准绳问题。
从测试设计的角度来看,被测对象期望所代表的,是“测试输入”和“测试输出”之间的一种因果关系:
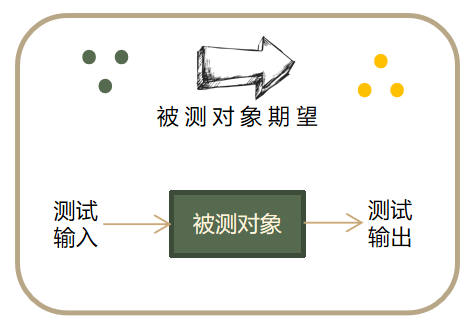
借用离散数学的方法,我们把被测对象期望表示成一个有序对集合,这里d表示一个测试输入点,e表示一个测试输出点。d和e构成一个有序对,意味着输入d的时候,对应的输出应该是e。所有这种有序对构成的集合,就可以表示期望的因果关系。
如果任意一个d,都只对应着唯一的一个e,被测对象期望就是一个确定的因果关系——有什么样的因,必然会有什么样的果。比如:

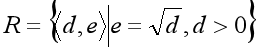
用R这种期望来建立测试准绳的话,预期结果是很明确的:输入4,输出就应该是2。
如果一个d,对应着多个不同的e,期望就是一个不确定的因果关系——同一个因,可能有不同的果,比如:
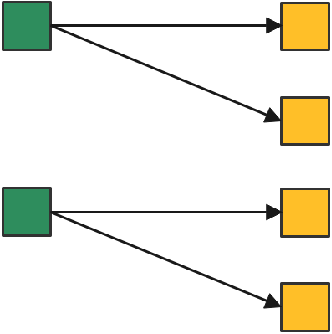
![]()
用R'这种期望来建立测试准绳的话,预期结果就不够明确:输入4,输出可能是2,也可能是-2。
R和R’两个期望相较而言,直觉上R给我们提供的信息更多。当然,我们也可以做一些定量的度量。在信息论里,用“熵”这个指标来度量信息的多少。一个随机变量,取值的不确定性越大,熵就越大,信息量就越少。
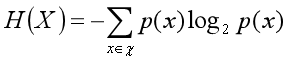
我们借用熵这个指标,来度量被测对象期望所包含的冗余信息量。假设期望R的一个测试输入点d,对应着n个测试输出点。为了简化问题,我们假设n个测试输出点出现的概率相同,都是1/n。于是,R在d这个测试输入点上的熵就是:
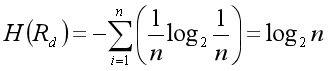
那么,这个期望,在d=4这个测试输入点上对应1个测试输出点,熵就是0;
这个期望,在d=4上对应2个测试输出点,熵就是1。所以,在d=4这个点上,R的熵比R’小,R的冗余信息比R’多。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









