






ERA5下载加速
引言
众所周知,ERA5小时尺度以及日尺度数据下载比较困难,一方面是由于数据中心在欧洲,传输速度慢。另一方面也是由于数据量庞大。
目前批量下载的代码有很多,但是存在以下问题:
-
速度慢,几十到几百kb -
下载容易中断,生成无效文件 -
单一线程,提交任务然后等待,速度慢 -
中断下载后,重新提交很麻烦,先找到中断的位置
目前ECMWF数据进行了一些更新,界面更新。
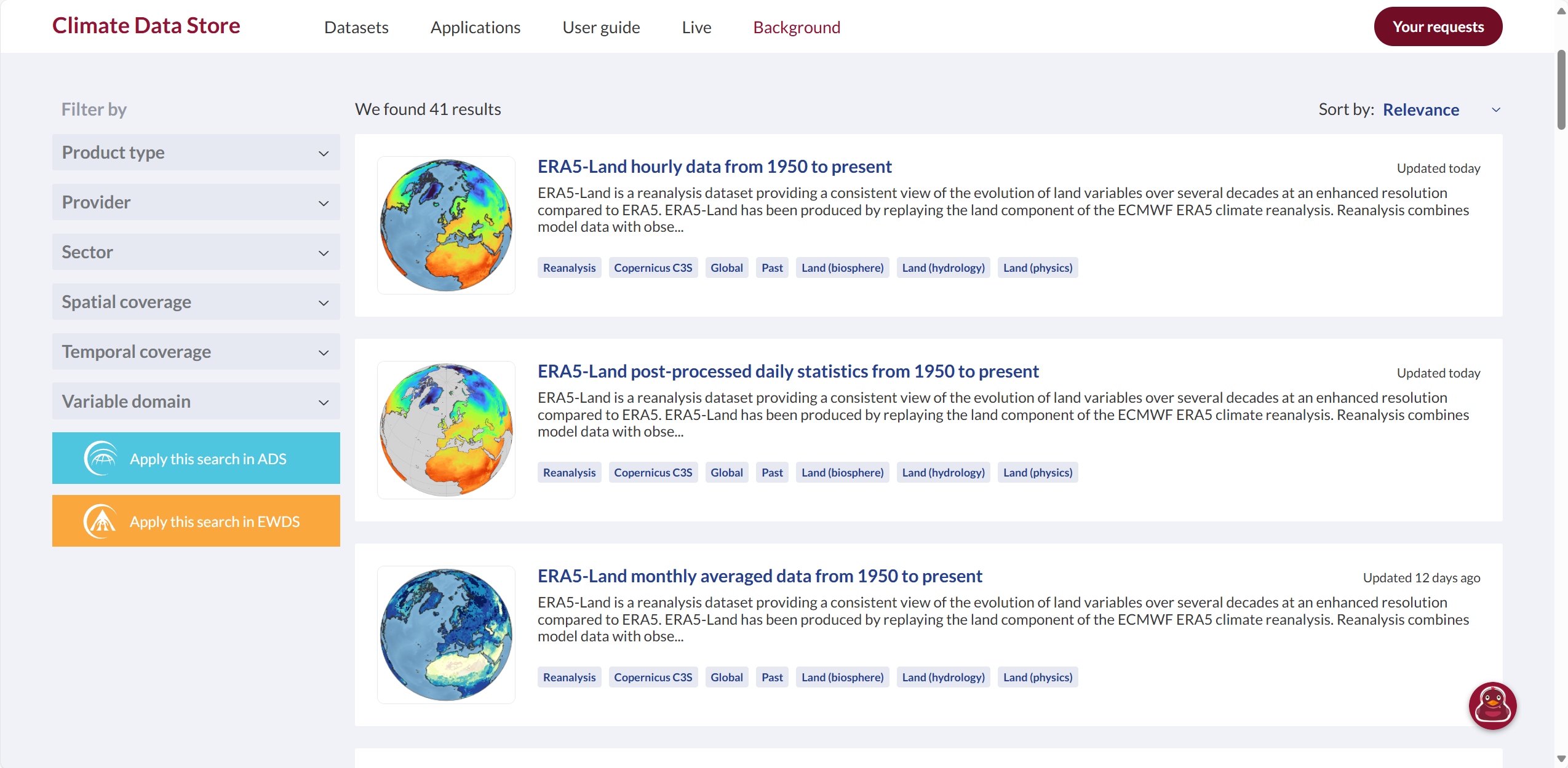
且新增了daily数据,和Google Earth Engine也一致了,变量更全。
借此机会讲述一下流程
预备工作
首先需要安装ECMWF提供的Python库
pip install cdsapi
接下来注册ECMWF账号,在这里注册Climate Data Store (copernicus.eu)
然后打开:
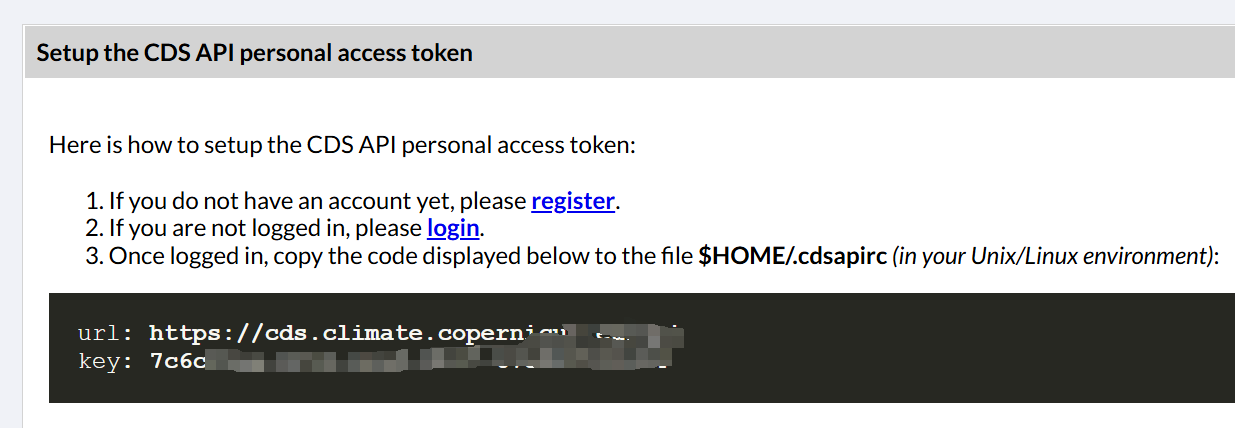
https://cds.climate.copernicus.eu/how-to-api
就能看到url和key
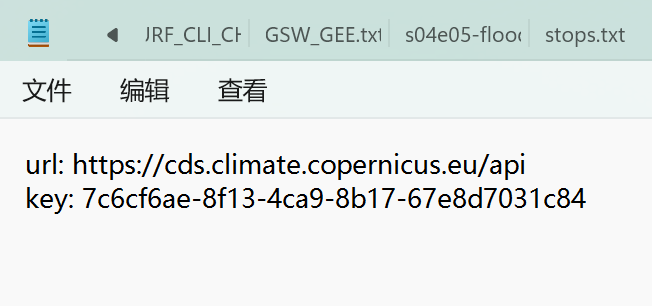
配置文件,C:\Users\user_name\下应该是没有.cdsapi配置文件的,需要自己手动创一个:可以打开记事本,然后复制、粘贴、保存,文件名为.cdsapi,内容如下图注意保存类型选择所有文件
代码
这里直接放代码,使用queue来多线程提速,同时处理4个任务
import cdsapi
import os
import calendar
import netCDF4 as nc
import threading
from queue import Queue
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 创建一个函数来构建下载请求
def download_era5_data(year, month, day, download_dir):
dataset = "derived-era5-pressure-levels-daily-statistics"
request = {
"product_type": "reanalysis",
"variable": ["geopotential"],
"year": year,
"month": [month],
"day": [day],
"pressure_level": [
"300", "500", "700",
"850"
],
"daily_statistic": "daily_mean",
"time_zone": "utc+00:00",
"frequency": "6_hourly"
}
# 定义文件名格式为 年月日.nc,并设置下载路径
filename = f"ERA5_{year}{month}{day}.nc"
filepath = os.path.join(download_dir, filename)
print(f"Checking if file {filename} exists and is complete...")
# 检查文件是否已存在,且文件完整
if os.path.exists(filepath):
try:
# 尝试打开文件以验证其完整性
with nc.Dataset(filepath, 'r') as ds:
print(f"File {filename} is complete and valid.")
except OSError as e:
# 如果文件不完整或损坏,删除并重新下载
print(f"File {filename} is corrupted. Redownloading...")
os.remove(filepath)
download_file_from_era5(request, filepath)
else:
# 如果文件不存在,则直接下载
print(f"File {filename} does not exist. Starting download...")
download_file_from_era5(request, filepath)
# 创建一个函数来执行实际下载
def download_file_from_era5(request, filepath):
print(f"Downloading data to {filepath}...")
client = cdsapi.Client()
client.retrieve("derived-era5-pressure-levels-daily-statistics", request).download(filepath)
print(f"Download completed for {filepath}")
# 定义下载目录
download_dir = r"F:\ERA5\surface\geopotential"
print(f"Checking if download directory {download_dir} exists...")
# 检查目录是否存在,不存在则创建
if not os.path.exists(download_dir):
print(f"Directory {download_dir} does not exist. Creating directory...")
os.makedirs(download_dir)
else:
print(f"Directory {download_dir} already exists.")
# 定义下载任务队列
queue = Queue()
# 创建一个下载工作线程类
class DownloadWorker(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self.queue = queue
def run(self):
while True:
year, month, day = self.queue.get()
print(f"Worker {threading.current_thread().name} processing download for {year}-{month:02d}-{day:02d}...")
try:
# 将月份和日期格式化为两位数
month_str = f"{month:02d}"
day_str = f"{day:02d}"
download_era5_data(str(year), month_str, day_str, download_dir)
except Exception as e:
print(f"Error downloading data for {year}-{month_str}-{day_str}: {e}")
finally:
print(f"Worker {threading.current_thread().name} finished processing download for {year}-{month:02d}-{day:02d}.")
self.queue.task_done()
# 创建四个工作线程
print("Creating worker threads...")
for x in range(4):
worker = DownloadWorker(queue)
worker.daemon = True
worker.start()
print(f"Worker thread {worker.name} started.")
# 循环遍历2000到2023年,将任务加入队列
print("Adding download tasks to the queue...")
for year in range(2000, 2024):
for month in range(1, 13):
# 获取当前月份的最大天数
_, max_day = calendar.monthrange(year, month)
for day in range(1, max_day + 1):
print(f"Adding task for {year}-{month:02d}-{day:02d} to the queue...")
queue.put((year, month, day))
# 等待所有任务完成
print("Waiting for all tasks to complete...")
queue.join()
print("All download tasks completed.")
代码需要修改dataset和request
一般是先手动预选择需要下载的数据,然后复制API提供的内容并替换:
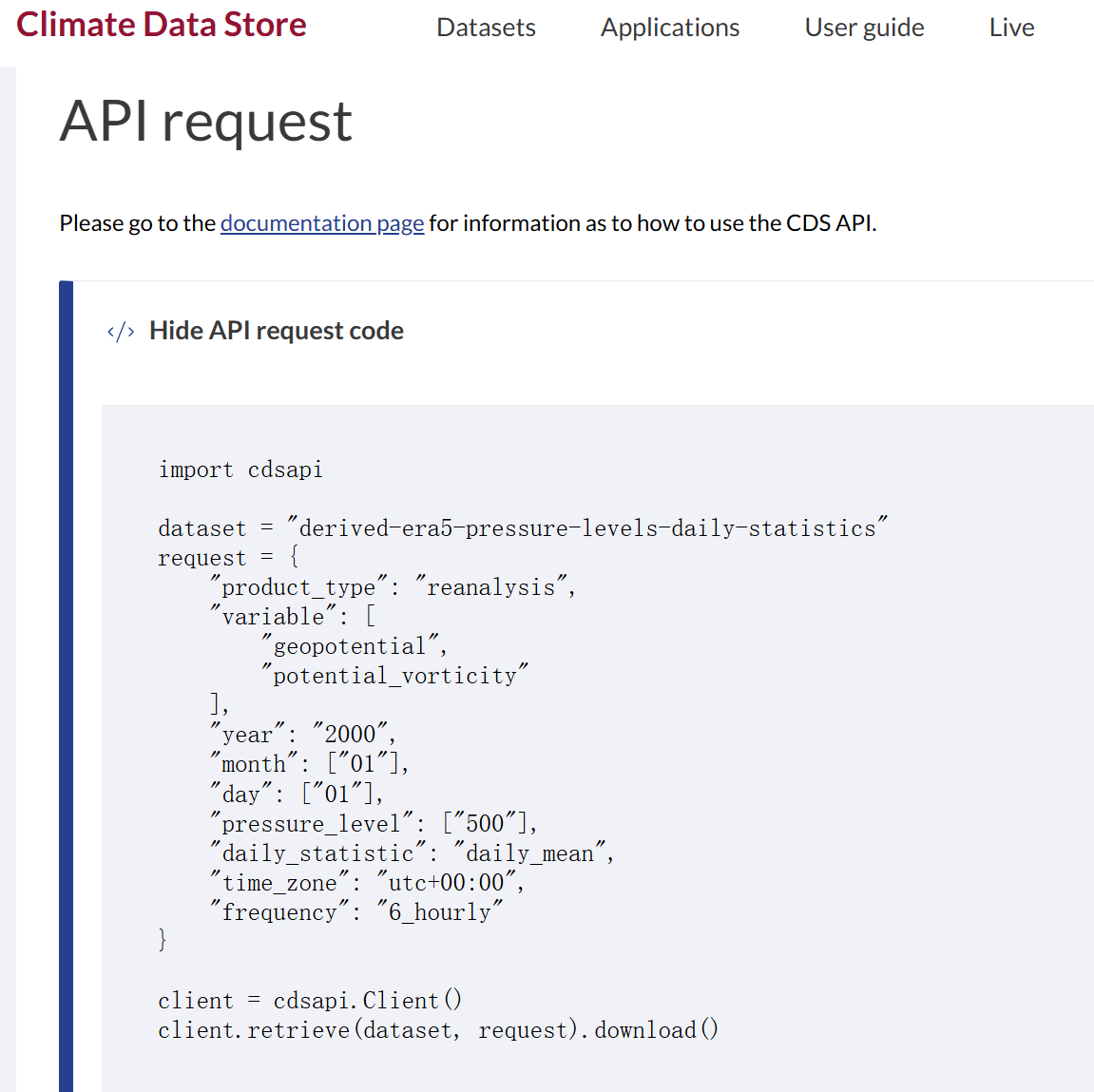
然后替换路径即可
这里是每天下载一个文件,也可以按照你的需求更改循环代码
代码有几个优点,可以说得上是ERA5下载的终极版了:
-
中断下载可以反复运行,补充未下载的内容
-
可以按照循环内所有的文件,检测下载中断的文件,并重新下载
-
四线程提速
-
无需借助任何辅助下载软件
下载提速
一般来说下载速度还是比较快的,大多数在几M/s,偶尔也会几百k/s
这里采用气象家园-kermit 提供的方法。
找到下载的cdsapi库的安装目录,打开目录下的api.py,一般可以在conda环境中找到
搜索这段代码:
def _download(self, url, size, target):
在这段代码中添加下面一行代码,然后保存
url=url.replace(".copernicus-climate.eu",".nuist.love")
这个url是他做的镜像网站,在一些情况下可以加速。
本文由 mdnice 多平台发布


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











