







文章目录
(68) MR的概述&优缺点
MapReduce是一个分布式运算程序的编程框架,简单的说,就是一个 分布式计算框架,是Hadoop的核心所在。
MR的核心功能,是将用户编写的业务逻辑代码和自身组件相融合,整合成一个完整的分布式运算程序,并发运行在Hadoop集群上。
优点:
- 易于编程。用户只关心业务逻辑就可以;
- 良好的扩展性。可动态增加服务器节点,以解决计算资源不足的问题;
- 高容错性。如果有一台节点崩溃,不会影响整个集群的计算。其他可用节点会接过崩溃节点的任务,继续计算。
- 适合海量数据的计算。这里的海量,一般是指TB以上级别的。
缺点:
- 不擅长实时计算。无法达到mysql这种毫秒级查询,无法快速响应;
- 不擅长流式计算。指数据一条条过来,实时的流式计算。一般是spark streaming和flink适合做这个。MR的特性决定了其数据源必须是静态的。
- 不擅长DAG有向无环图。像是迭代计算,即DAG中,任务一的输出会作为任务二的输入,任务二的输出则会作为任务三的输入,以此类推,是一个链式的结构。MR不擅长处理这种,当然,只是不擅长,不是不支持。相比来讲,spark更适合用来处理这种任务。( 因为spark的中间结果是基于内存的,而MR是基于磁盘,重复IO性能太低下 )
(69)MR的核心思想
经典案例:统计一段话中每个单词出现的总次数,其中a~p的结果放在一个文件,q~z的结果放在一个文件里。
MR的计算分为两个阶段:Map阶段和Reduce阶段。
接下来我们以经典案例,来讲解MR的主要工作流程,如图:
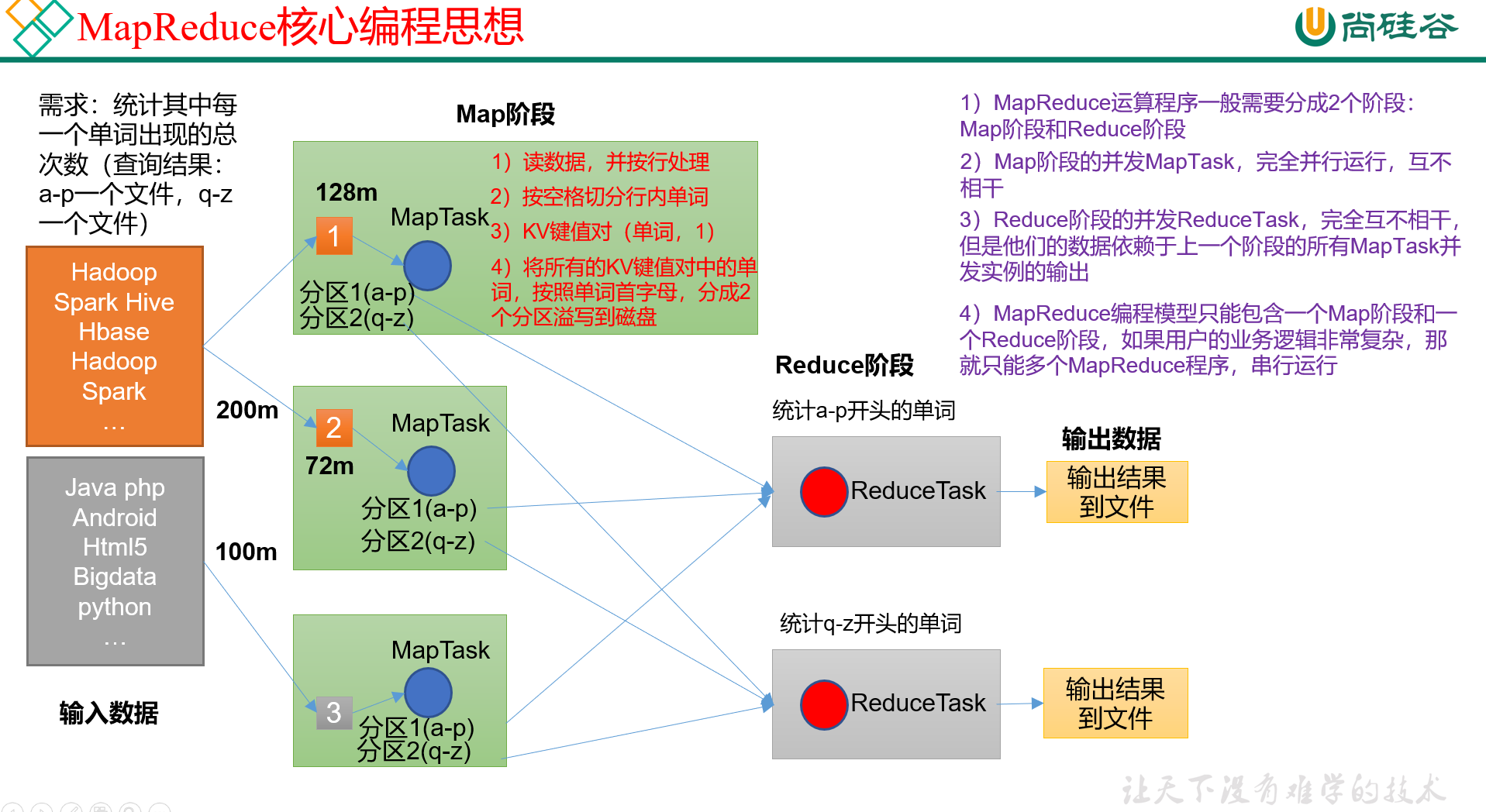
1) Map阶段,是任务分配阶段,一般是按照块大小,每个MapTask负责处理一块数据。这个块一般是128M。
这个阶段的MapTask并发实例,完全并发运行,互不相干。
在我们刚说的这个案例里,MapTask中都做了些什么呢?
- 一行一行读数据,进行处理;
- 按照空格分割行内单词;
- 把切出来的单词,组成KV键值对(单词,1)
- 将所有的KV键值对,按照单词首字母,分成两个分区(ap分区和qz分区),导出至磁盘保存。
2) Reduce阶段,就是任务汇总统计阶段。
这一阶段的ReduceTask并发实例也是互不相干,但是它们依赖于Map阶段所有MapTask并发实例的输出。
在这个案例里,因为结果需要有2个文件,所以这里会有2个ReduceTask,一个负责汇总出ap,一个负责汇总出qz,并分别输出至文件。
在一个MR计算过程中,只能包含一个Map阶段和一个Reduce阶段。如果用户的业务逻辑过于复杂,那么可以创建多个MR计算程序,串行计算。这就相当于链式的有向无环图计算了。
一些问题细节:
- MapTask内部是如何工作的?
- ReduceTask内部是如何工作的?
- MapTask内部是如何排序、控制分区的?
- MapTask和ReduceTask之间是如何衔接的?
这些问题都将在后面一一解答。
MapReduce进程
一个完整的MR程序在分布式运行的时候,会产生三种类型的进程:
- MrAppMaster:是ApplicationMaster的子进程,负责整个Mr程序的过程调度及状态协调;
- MapTask:负责Map阶段的数据处理流程;
- ReduceTask:负责Reduce阶段的数据处理流程
MapTask和ReduceTask似乎都是yarnchild,这里仅供参考一下。
(70)官方WC源码&序列化类型
WordCount(即WC),这是Hadoop里一个很经典的MR案例,教程后面很多地方在讲解底层原理的时候都会以WC为例做讲解。
官方WordCount的源码在哪儿呢?
大概在Hadoop安装目录的share/hadoop/mapreduce/hadoop-mapreduce-example-xxx.jar,这里面存储了Hadoop的一些代码案例。
jar包反编译工具:jd-gui。
WC的源码里,核心是三个类:
- 主类,负责调度/驱动
- TokenizerMapper类,继承了Mapper
- IntSumReducer类,继承了Reducer
分工很明确。
另外,这里简单介绍下hadoop中常用的数据序列化类型,后面讲序列化的时候会用到:
| Java类型 | Hadoop Writable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
(71)MR的编程规范
用户在编写一个完整的MR程序时,需要实现3个部分,即Mapper、Reducer和Driver。
Mapper
Mapper阶段:
- 用户自定义的Mapper,要继承对应的系统Mapper类;
- Mapper的输入数据需要是KV键值对的形式;
- Mapper中的业务逻辑,需要写在Mapper类里声明的map()方法里;
- Mapper的输出数据,也需要是KV对的形式;
- map()方法对每一个KV对,都调用一次;(每个KV都会跑一遍属于自己的map()方法)
Reducer
Reducer阶段:
- 用户自定义的Reducer,要继承对应的系统Reducer类;
- Reducer的输入类型跟Mapper的输出类型是要保持一致的。这个很好理解,串行的毕竟;
- Reducer的业务逻辑,需要写在Reducer类里声明的reduce()方法里;
- 在ReduceTask进程中,reduce()对==每一组相同K==的KV对,都调用一次;(所以这里容易发生数据倾斜)
注意,最后一条,Mapper跟Reducer是不一样的。Reducer是每一组相同K的KV对,进一个reduce()。
这个其实很好理解,Reducer阶段就是做汇总的,它是一个数据量减少的过程,其实就是一个把n条具有相同特征的数据,合并成一条数据的过程。
以WC举例,第一句话里字母a出现了3次,第二句话里字母a出现了4次,即mapper会分别输出两个键值对,即(a,3)和(a,4),Reducer则会将这两个键值对输入同一个reduce()进行加和,并最终输出(a,7)。
Driver
Driver阶段:
相当于yarn集群的客户端,用于提交整个程序到YARN集群,具体提交的是什么呢?其实是封装了MR程序相关运行参数的一个job对象。所以驱动类里其实就是定义一些运行参数之类的。
(72)WordCount案例需求分析
一个标准的WordCount需求:统计给定的文本文件中,每一个单词出现的次数。
我们需要针对这个需求,编写对应的Mapper、Reducer和Driver。
这里就不展示代码了,只是展示一下各个类的主要功能。
Mapper负责:
- 将MapTask传过来的文本内容先转换成string;
- 根据空格将这一行切分成单词;
- 将切出来的单词,包装成键值对<单词,1>的形式;
Reducer负责:
- 将相同K的value值加在一起;
- 输出该K的总次数;
Driver阶段:
- 获取配置信息,获取job对象实例;
- 指定本程序的jar包所在的本地路径;
- 关联Mapper和Reducer业务类;
- 指定Mapper的输出类型(K和V是什么类型);
- 指定最终输出的类型。(整个MR程序结束后的输出,而不是Reducer阶段的输出)
- 指定job的输入文件的所在目录;
- 指定job的输出结果的所在目录(输出目录不能提前存在?);
- 提交作业;















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









