







Qwen3.0官方介绍
Qwen3 是 Qwen 系列中最新一代的大规模语言模型,提供了一整套密集型和专家混合(MoE)模型。基于广泛的训练,Qwen3 在推理、指令执行、代理能力和多语言支持方面取得了突破性进展,具有以下关键特性:
- 独特支持在单一模型内无缝切换思考模式(用于复杂的逻辑推理、数学和编程)和非思考模式(用于高效的通用对话),确保在各种场景下的最佳性能。
- 显著增强其推理能力,在数学、代码生成和常识逻辑推理方面超越了之前的 QwQ(在思考模式下)和 Qwen2.5 指令模型(在非思考模式下)。
- 优越的人类偏好对齐,擅长创意写作、角色扮演、多轮对话和指令执行,以提供更自然、吸引人和沉浸式的对话体验。
- 在代理能力方面的专长,能够在思考和非思考模式下与外部工具精确集成,并在复杂的基于代理的任务中达到开源模型中的领先性能。
- 支持 100 多种语言和方言,具备强大的多语言指令执行和翻译能力。
所以有必要部署体验一下!
最方便的方式是用ollama部署,但下载完成提示我的ollama版本过低
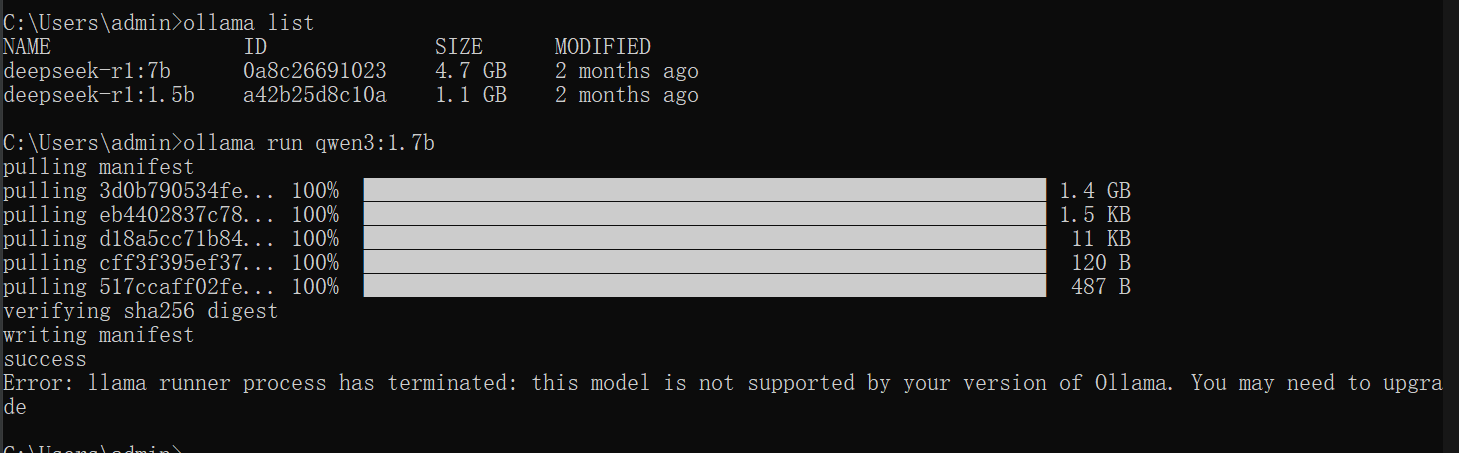
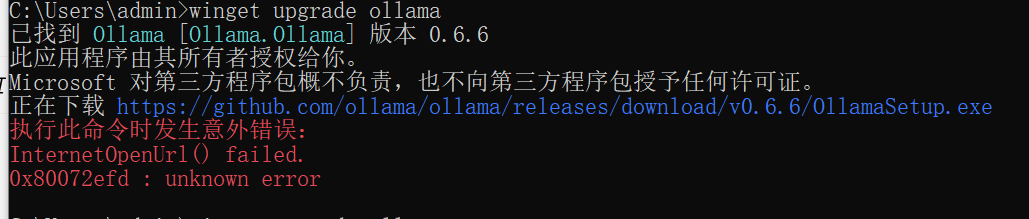
尝试升级ollama,结果。。。
winget upgrade ollama
换个方式,使用modelscope下载模型,用python transformers库推理
modelscope download --model Qwen/Qwen3-1.7B --local_dir Qwen/Qwen3-1.7B
modelscope download --model Qwen/Qwen3-4B --local_dir Qwen/Qwen3-4B
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local_dir deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B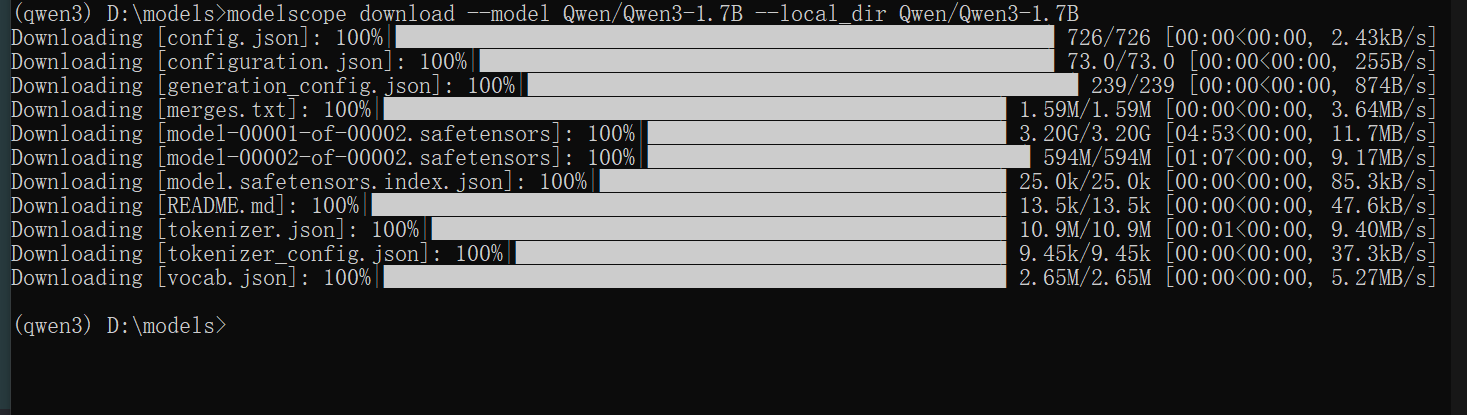
推理示例:你是待办提醒助手,帮我识别用户输入是否是一个待办或提醒,以{\"code\": \"true或false\",\"response\": {\"desc\": \"输入的原文\",\"time\": \"提醒时间\"}},模板样例{\"code\": \"true\",\"response\": {\"desc\": \"明天晚上8点给客户打电话\",\"time\": \"明天晚上8点\"}},返回严格的json格式,不要有其它多余字符。以下是用户输入:开会
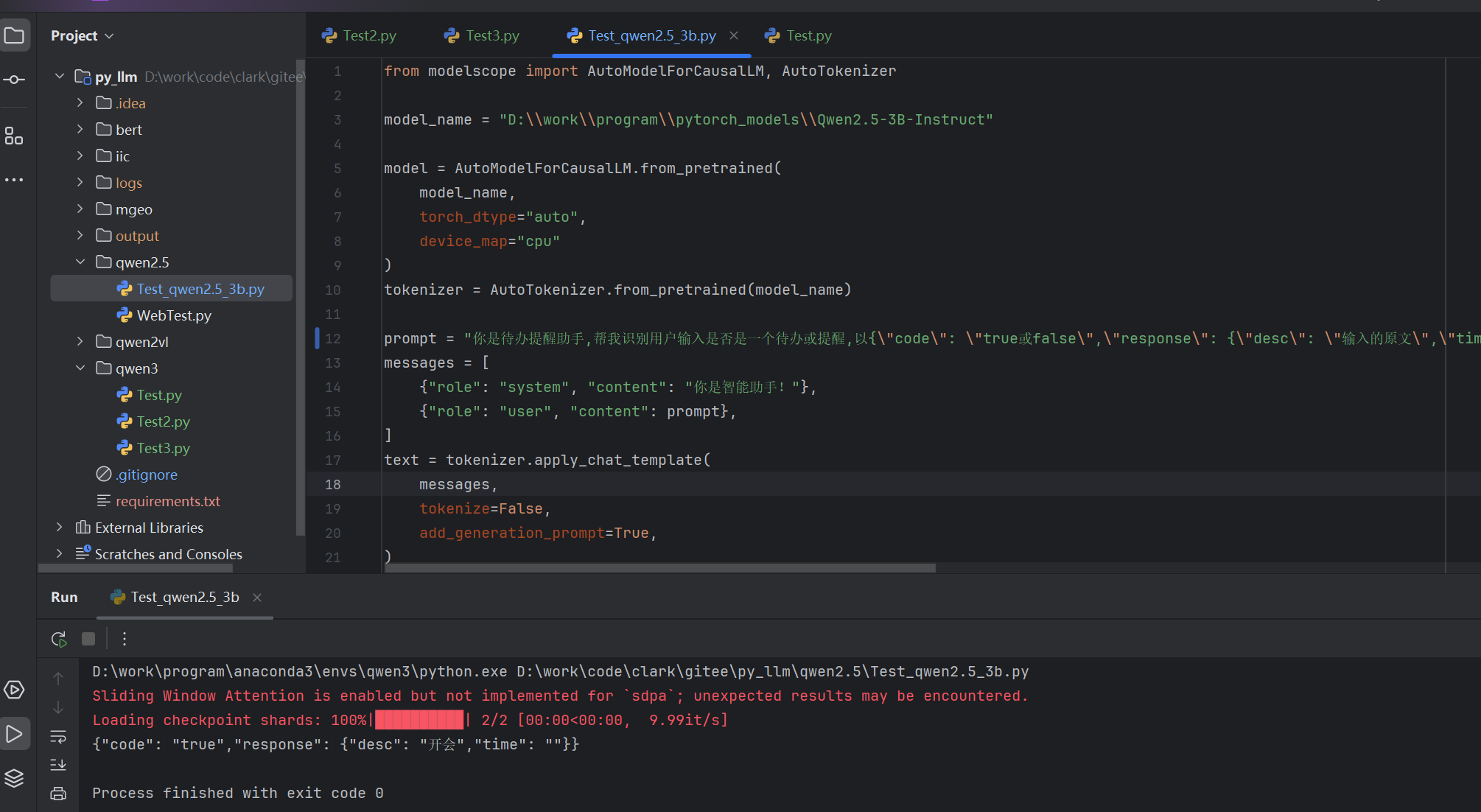
使用qwen2.5:3b推理结果
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "D:\\work\\program\\pytorch_models\\Qwen2.5-3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="cpu"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "你是待办提醒助手,帮我识别用户输入是否是一个待办或提醒,以{\"code\": \"true或false\",\"response\": {\"desc\": \"输入的原文\",\"time\": \"提醒时间\"}},模板样例{\"code\": \"true\",\"response\": {\"desc\": \"明天晚上8点给客户打电话\",\"time\": \"明天晚上8点\"}},返回严格的json格式,不要有其它多余字符。以下是用户输入:开会"
messages = [
{"role": "system", "content": "你是智能助手!"},
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response){"code": "true","response": {"desc": "开会","time": ""}}
再使用qwen3:1.7b对比
执行报错,可能是我的transformer版本过低

更新transformers库
pip install --upgrade transformers -i https://mirrors.aliyun.com/pypi/simple/
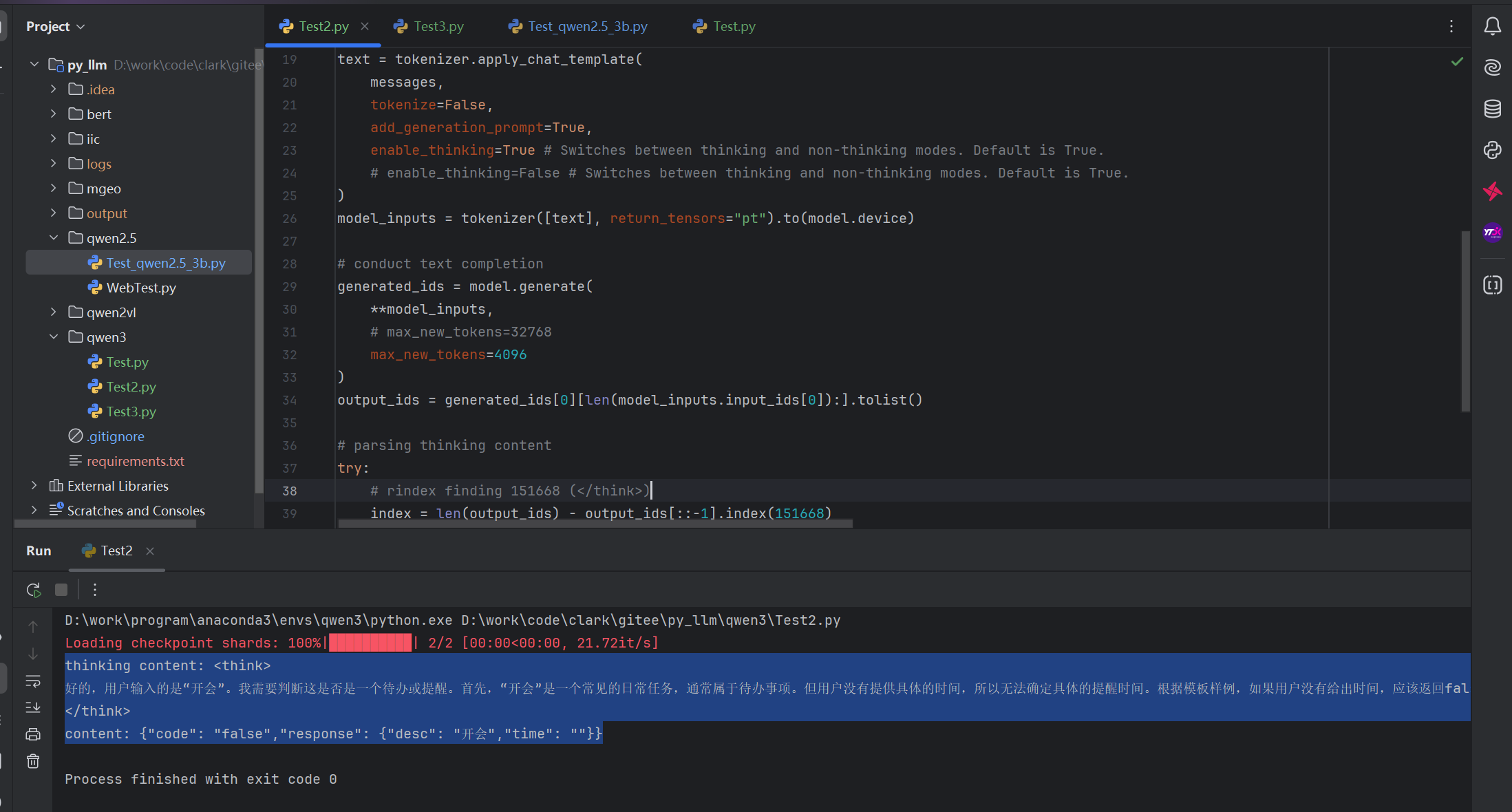
再次执行,开思考过程enable_thinking=True
thinking content: <think>
好的,用户输入的是“开会”。我需要判断这是否是一个待办或提醒。首先,“开会”是一个常见的日常任务,通常属于待办事项。但用户没有提供具体的时间,所以无法确定具体的提醒时间。根据模板样例,如果用户没有给出时间,应该返回false,因为缺少必要信息。因此,正确的响应应该是code为false,desc为“开会”,time为空字符串。
</think>
content: {"code": "false","response": {"desc": "开会","time": ""}}
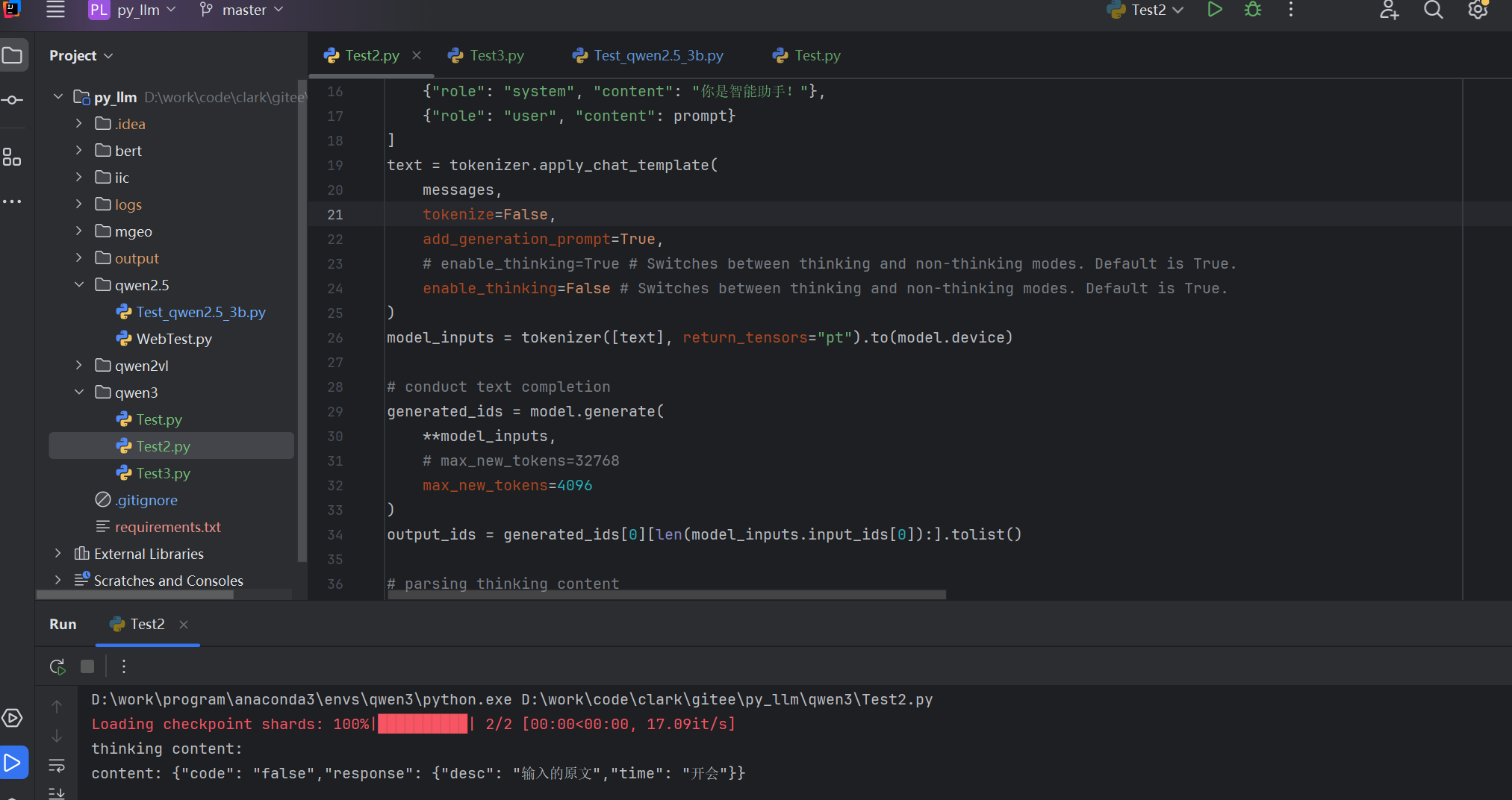
关掉思考过程再试试
thinking content:
content: {"code": "false","response": {"desc": "输入的原文","time": "开会"}}
再换qwen3:4B试试,关思考过程
thinking content:
content: {"code": "false","response": {"desc": "开会","time": "null"}}
从这个用例看很明显,qwen3:1.7B、qwen3:4B的推理能力不如qwen2.5:3B!!!
后续我将继续增加测试用例,并增加deepseek-r1:1.5B模型的测试

















 2200
2200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









