






net = cv::dnn::readNetFromONNX(modelPath);
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
//else
//{
// net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
// net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
//}
cpu 13900k
gpu 4090
开门见山先说目前为止的总结: 推理还是用GPU快 如果就要用CPU只能参考模型优化,剪枝,知识蒸馏,或者降低最后模型尺寸 大概640*640的时候是100占用 320*320 70 160*160 40
精度出现问题,只有把目标放大才能识别到 应该是改变了视野感受问题,这个比较专业我也不懂。 也可能是训练问题,yolo cfg的default 里 imagz 是960 如果设置成[640,640]会不会更好还没测试,之后每天总结再补上。
使用CUDA 显卡占用不增加 (PS已解决,如果想用CUDA模块 需要重新编译OPENCV 编译成GPU版本)
OpenCV4.8 GPU版本CMake编译详细步骤 与CUDA代码演示-CSDN博客
但我还没试直接转trt了 XD
CPU还是100 有什么办法降低占用 这才单类模型 模型才11mb 13900推理要占100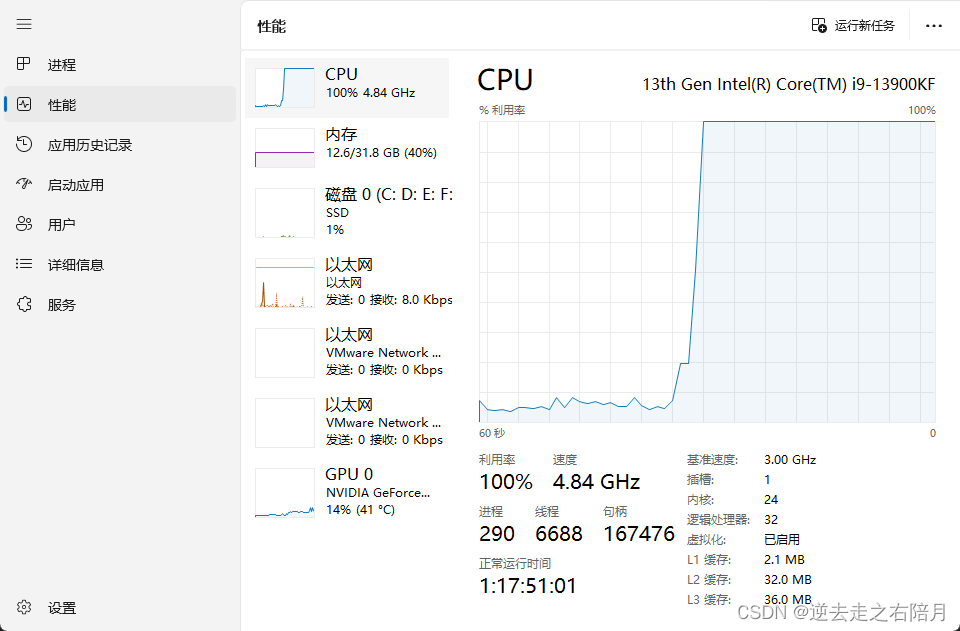 ?是否是模型训练问题 没有优化问题 导致计算量过高
?是否是模型训练问题 没有优化问题 导致计算量过高
####
昨天尝试打包 在另一台5800电脑上运行 cpu只占 70 模型大小依旧640✘640 因为用224✘224 出现识别的图片需要放大才能识别到目标,还不知道原因,或许是输入图片尺寸太小所以卷积视野感受也变小了?新手不太懂,今天研究剪枝 或者模型优化,int8量化的模型dnn读取错误 f16就可以 暂不知原因,或转trt尝试,又或看看dnn cuda为什么不可用
#####################################################
1.11 今天用到TRT 下面是DNN得 CUDA 跟TensorRT 区别
TensorRT_tensorrt和cuda的区别-CSDN博客文章浏览阅读2.5k次,点赞2次,收藏17次。对于任何用到shape、size返回值的参数时,例如:tensor.view(tensor.size(0), -1)这类操作,避免直接使用tensor.size的返回值,而是加上int转换,tensor.view(int(tensor.size(0)), -1),断开跟踪。按照说的这么修改,基本总能成。下载onnx,保留其proto协议文件,生成pb.h、pb.cpp,只使用这几个即可,不需要onnx全部,Protocol Buffers,为了解决任何语言之间的数据序列化反序列化工作。_tensorrt和cuda的区别https://blog.csdn.net/qq_44089890/article/details/130023963我的理解总结 就是 TensorRT 是NV自家得只用于加速推理过程 毕竟自家显卡自己肯定知道怎么优化最好,把模型先优化成利于显卡计算。
而DNN CUDA也是NV家的 但是不止用于推理过程,而且支持模型框架多(不知道Tensor支持除了TRT之外的嘛,没查现写的
所以cuda灵活一点但速度没有trt快
今天编译Tensorrt遇到的问题是在onnx转trt出现 INT64错误 原因就是TensorRT支持INT32精度的模型但不支持INT64 后来我用了一个封装好的训练加转模型的软件没这个问题,但我中间百度了一下解决方法是
onnx模型转TensorRT模型的trt模型报错:Your ONNX model has been generated with INT64 weights. while TensorRT
至于INT64是怎么造成的 对于我这种模型结构还不了解的暂时没法解答,回头知道答案再补上
明天补上trt C++部署安装。















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









