







上边博文学习了一下AGNES算法与DIANA算法,针对伸缩性差一级不能撤销先前步骤所做的工作,学习一下BIRCH聚类算法。
BIRCH算法:Balanced Iterative Reducing and Clustering using Hierarchies.利用层次结构的平衡迭代规约和聚类。名字真的长的不行了。
该算法是为大量数值数据聚类设计的,它将层次聚类(在初始微聚类阶段)与诸如迭代的划分这样的其它聚类算法(在其后的宏聚类阶段)集成在了一块。它克服了凝聚聚类方法面临的两个困难:(1)可伸缩性(2)不能撤销先前步骤所做的工作。
BIRCH使用聚类特征来概括一个簇,使用聚类特征树(CF-树)来表示聚类的层次结构。这些结构帮助聚类方法在大型数据库甚至在流数据库中取得了好的速度和伸缩性,还使得BIRCH方法对新对象增量或动态聚类也非常有效。
考虑一个n个d维的数据对象或者点的簇。簇的聚类特征(Clustering Feature,CF)是一个三维向量,汇总了对象簇的信息,定义如下:
CF =《n,LS,SS》 n为样本的数量,LS为n个点的线性和,SS为数据点的平方和。
聚类特征本质上给定簇的统计汇总,使用聚类特征可以避免存储个体对象或者点的详细信息。我们只需要固定大小的空间来存储聚类特征即可。
例:聚类特征的计算:
假设簇c1有三个点:(2,5),(3,2)(4,3),那么C1的聚类特征:
n=3,LS=(2+3+4,5+2+3)=(9,10) SS=(4+9+16,25+4+9)=(29,38) (平方和)
CF1=《3,(9,10),(29,38)》
看完上面这个例子,聚类特征的概念应该有所了解了。
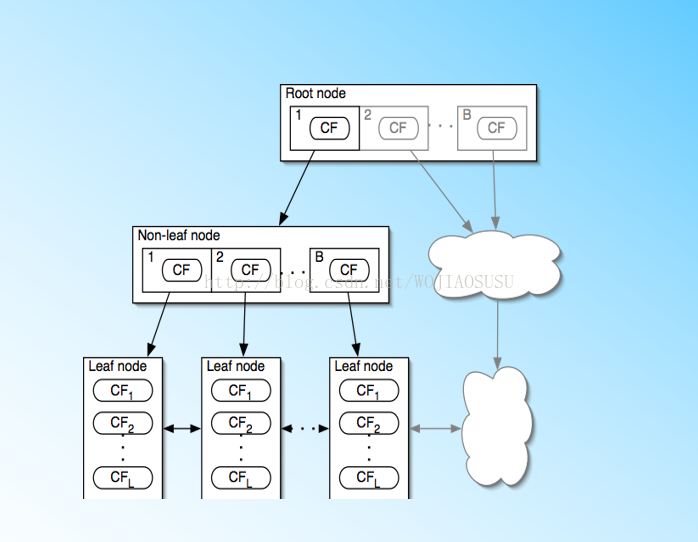
CF-树一颗高度平衡的叔,存储了层次聚类的聚类特征。对于CF Tree,我们一般有几个重要参数,
第一个参数是每个内部节点的最大CF数B。(即非叶子节点的最大子女数)
第二个参数是每个叶子节点的最大CF数L。(即叶子节点的最大子女数)
第三个参数是针对叶子节点中某个CF中的样本点来说的,它是叶节点每个CF的最大样本半径阈值T,也就是说,在这个CF中的所有样本点一定要在半径小于T的一个超球体内。这三个参数对聚类效果的影响是巨大的,可以这么说BIRCH聚类算法是对参数敏感型算法。
如图为聚类特征树,先有个概念。
接下来,讲解一下BIRCH的生成过程。如果对数据结构里面的树结构比较熟悉,那么BIRCH算法就是 a piece
of cake!当然不熟悉的看懂这个算法也是分分钟的。
(1)首先定义好三个参数:B,L,T
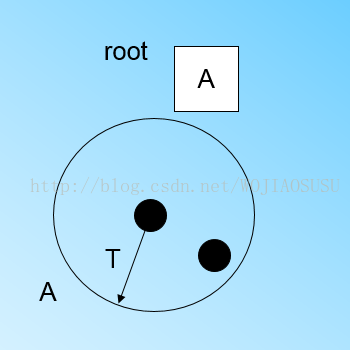
(2)最开始的时候树是空的。扫描数据,第一个点加入时,将它放入到新建的三元组A中,此时三元组A的n=1.此时这个三元组A就是根节点。如图所示,本来想上传自己手画的版本,加了许多注释,但是发现太丑了!

(3)当第二个点扫描加入时,如果第二个点在已经加入的第一个点的T范围内,那么两个点位于同一个CF内,如图所示。
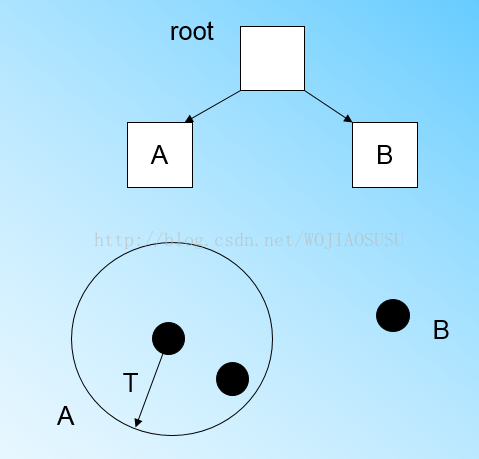
(4)当扫描加入的第三个点不在已有的CF的超球体范围内,那么需要新建一个CF-B。如图所示。
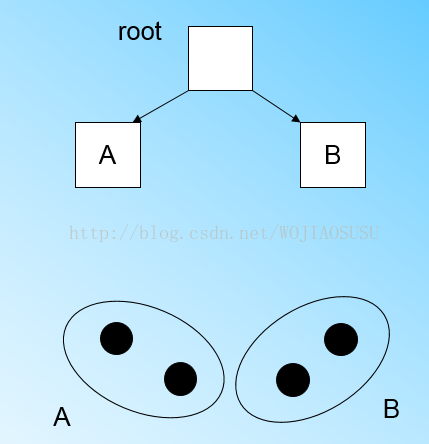
(5)当扫描加入第四个点时,我们发现新加入的点在CF-B的超球体范围内,加入。如图所示
(6)可能会发现,说了这么多,之前设定的几个参数怎么没出现过,不是说很重要吗?好,接下来就涉及到参数问题了。
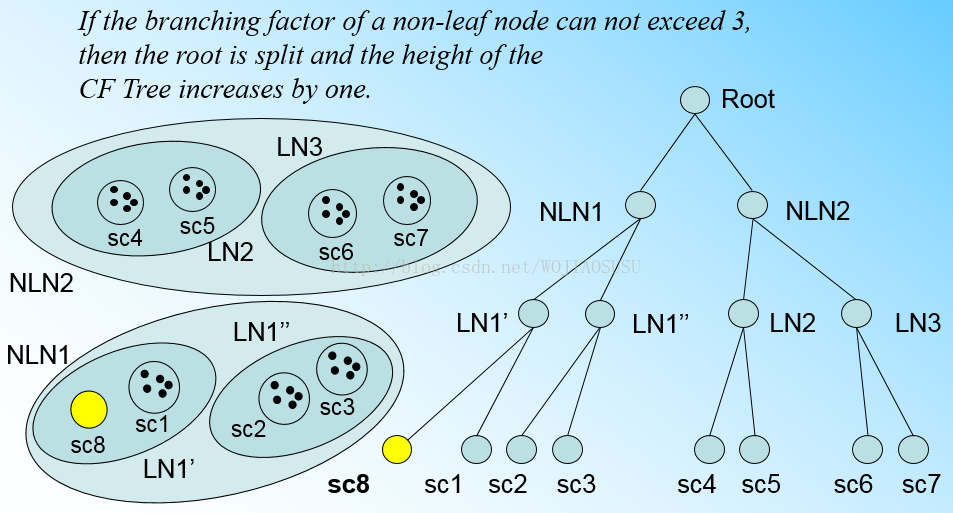
如下图所示,如果我们设定的L=3,那么对图中的LN1叶子节点来说,其CF数量已经达到上限。但是我们扫描新加入的点sc8距离LN1最近,但是却又不在生sc1,sc2,sc3的超球体内,只能建立一个新的CF了,但是CF数量又达到上限。怎么办?

(7)为了解决上述问题,只能讲LN1分裂了,在LN1的CF组里面,找到两个相聚最远的CF分别做两个叶子节点的种子CF,剩下的CF以及要新建的sc8按照距离远近加入到距离最近的叶子节点上。

(8)到了第7个过程,感觉已经大功告成了,NO,参数问题又来了,如果我们此时设置的B=3,那么很明显root节点的最大CF已经超出上限了,怎么办》只能继续想上分裂了。即如果我们在叶子节点处发生了分裂,一定要向上检查父节点是否还满足参数要求。即传递性。
给定有限的内存,BIRCH一个重要的考虑是最小化I/O时间。BIRCH采用了一种多阶段聚类技术:数据集的单遍扫描产生一个基本的好聚类,而一或者多遍的额外扫描可以进一步改善聚类质量。在实际应用中,BIRCH算法主要分为两个阶段:
阶段一:BIRCH扫描数据库,建立一棵存放于内存的初始CF-树,他可以被看做数据的多层压缩,试图保留数据的内在聚类结构。(单遍扫描,完成基本的聚类)
阶段二:BIRCH采用某个(选定的)聚类算法对CF树的叶节点进行聚类,把稀疏的簇当做离群点处理,把稠密的簇合并为更大的簇。(即可以进行进一步的处理,比如此时可以使用K-MEANS算法进行下一步处理)
阶段一中,CF-树被动态的改造。该方法支持增量聚类。新数据的加入,完全可以自适应改变CF-树结构。不必重建。
通过修改阈值,CF-树的大小可以改变。如果存储CF-树的内存大于主存大小,可以定义较大的阈值,并重建CF-树。重建过程从旧树的叶节点构建一颗新书。这样重建树的过程不需要重读所有的对象或者点。
总结下BIRCH算法的优缺点:
BIRCH算法的主要优点有:
1) 节约内存,所有的样本都在磁盘上,CF Tree仅仅存了CF节点和对应的指针。
2) 聚类速度快,只需要一遍扫描训练集就可以建立CF Tree,CF Tree的增删改都很快。
3) 可以识别噪音点,还可以对数据集进行初步分类的预处理
4)可伸缩能力强,具有较好的聚类质量。
BIRCH算法的主要缺点有:
1) 由于CF Tree对每个节点的CF个数有限制,导致聚类的结果可能和真实的类别分布不同.
2) 对高维特征的数据聚类效果不好。此时可以选择Mini Batch K-Means
3) 如果数据集的分布簇不是类似于超球体,或者说不是凸的,则聚类效果不好。















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









