







DENCLUE:基于密度分布函数的聚类
DENCLUE是一种基于一组密度分布函数的聚类算法。
首先说一下密度估计的概念:密度估计就是根据一系列观测数据集来估计不可观测的概率密度函数。在基于密度聚类的背景下,不可观测的概率密度函数是待分析的所有可能的对象的总体的真实分布。观测数据集被看做取自该总体的几个随机样本。
不好理解?好,那就通俗的说一下:比如说要找一个女朋友,你不了解她,但是可以先了解她的好朋友,通过她的好朋友来推测她的人品如何。支付宝的芝麻评分也把每个人的好友的信用情况作为指标来评价每个人的信用情况。
DENCLUE算法的主要原理是:
(1) 每个数据点的影响可以用一个数学函数来形式化的模拟,它描述了数据点在邻域的影响,被称为影响函数。
(2) 数据空间的整体密度(全局密度函数)可以被模拟为所有数据点的影响函数总和。
(3) 聚类可以通过密度吸引点得到,这里的密度吸引点是全局密度函数的局部最大值。
(4) 使用一个步进式爬山过程,把待分析的数据分配到密度吸引点X*所代表的簇中。
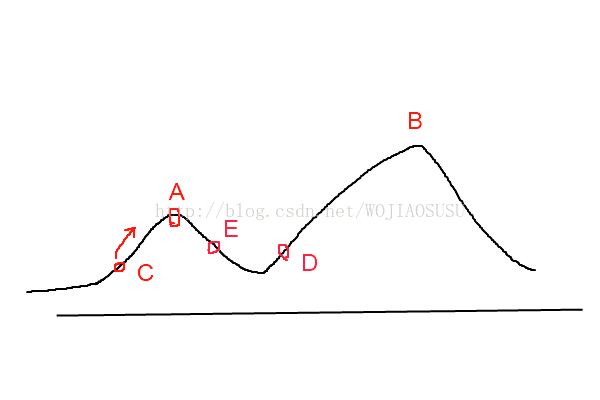
爬山法是深度优先搜索的改进算法。在这种方法中,使用某种贪心算法来帮助我们决定在搜索空间中向哪个方向搜索。由于爬山法总是选择往局部最优的方向搜索,所以可能会有“无解”的风险,而且找到的接不一定是最优解。但是他比深度优先搜索的效率要高很多。爬山算法模型图可以由下图轻松理解。如果感兴趣的话,可以详细了解优化算法,爬山算法,蚁群算法,模拟退火算法。
DENCLUE算法步骤:输入:数据集D,邻域半径参数r
(1) 对数据点占据的邻域空间推导密度函数。
(2) 通过沿密度最大的方向(即梯度方向)移动,识别密度函数的最大局部点(这是局部吸引点),将每个点关联到一个密度吸引点。
(3) 定义与特征的密度吸引点相关联的点构成的簇
(4) 丢弃与非平凡密度吸引点相关联的簇(密度吸引点X’称为非平凡密度吸引点,如果f(X’)<r,r为设定的阈值。)
(5) 若两个密度吸引点之间存在密度大于或者等于r的路径,则合并他们所代表的簇。对所有的密度吸引点重复此过程,直到不在改变时,算法终止。
在DBSCAN和OPTICS中,密度通过统计被半径参数r定义的邻域中的对象个数来计算,这种密度估计对半径r非常敏感。为了解决这个歌问题,可以使用核密度估计。核密度估计的一般思想是简单的。我们把每个观测对象看做看做周围区域中高概率密度的一个指示器。对于核函数的选择,可以使用高斯核函数。
DENCLUE可以被看作是多种聚类算法的一般化,主要特点:
(1) 发现任意形状的簇
(2) 处理噪声(孤立点数据)
(3) 一次扫描
(4) 需要设置密度参数作为终止条件。














 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









