







我们之所以在数据集上进行聚类分析,是因为我们假定数据集中的对象属于不同的固有类别。即聚类分析的目的就是发现隐藏的类别。基于概率模型的聚类
从统计学上讲,我们可以假定隐藏的类别是数据空间的一个分布,可以使用不同的概率密度函数(或者分布函数)进行精确的表示。我们称这种隐藏的类别为概率簇。对于一个概率簇C,它的密度函数f和数据空间的点o, f(o)是C的一个实例在o上出现的相对似然。
假设我们想通过聚类分析找出K个聚类簇C1,C2..C k。对于n个对象的数据集D,我们可以把D看做这些簇的可能实例的一个有限样本。从概念上讲,我们可以 假定D按如下方法形成。每个簇Cj(1<=j<=k)都与一个实例从该簇抽烟的概率Wj相关联。通常假定W1,W2…Wk作为问题设置的一部分给定,并且W1+W2+…+Wk=1,确保所有对象都有这K个簇产生。其实说白了就是:数据集D被认为是由这K个簇产生的,有了这一个前提之后,基于概率模型的聚类分析的任务是推导出最可能产生数据集D的K个聚类簇。接下来就是度量K个聚类簇的集合和它们的概率产生观测数据集的似然。
我们假定每个对象是独立的产生的,因此对于数据集D={O1,O2,O3…},我们有:
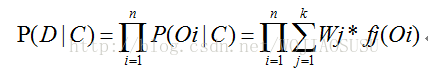
现在的主要任务是,找出K个聚类簇的集合C,使得P(D|C)最大化。但是最大化通常是难以处理的,因为通常来说,簇的概率密度函数可以取任意复杂的形式。为了使得基于概率模型的聚类是计算可行的,我们通常假定概率密度函数是一个参数分布。
设是K个簇的分布的参数。那么上式可以改写成:
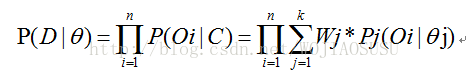
Pj为簇Cj的概率密度函数。
使用参数概率分布模型,基于概率模型的聚类任务是推导出最大化的参数集。
总结:基于概率模型的聚类就是进行参数估计,找出K个簇的参数集合来使得似然函数最大。
在这里介绍一种参数估计算法EM算法,EM算法用于含有隐变量的极大似然估计和最大后验概率估计。对于EM算法,会在以后的博文中单独重点的学习一下。














 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









