







- 缘起:因刚进入推荐领域,看同事周报中出现的一些推荐相关指标中有很多自己没见过的概念,下面梳理下p值的概念,主要转载了公众号上的文章,写的诙谐又生动易懂。
- 文章转载自:https://www.163.com/dy/article/DGA9BHU00511CT4D.html
- 整体说明:A/B实验即为A/B对照组。p值大小衡量结果的巧合性(值越大越偶然,值越小越有意义),以下为转载文章:
1、p值
你应该知道,手机的“推送通知”对挽留用户很重要吧。发一个推送,用户没准就会点开好久不用的App了!(我之前的文章也有详细介绍过优化“推送通知”的办法,点这里:网易垃圾推送让我气到围笑)
所以,你又有了一个想法,想试试,个性化通知内容,是不是有效。
于是,你分别给两组人发了不一样的推送通知。

第一组收到的是非个性的:“屠龙宝刀点就送!明星都在玩!”
第二组则有一点点个性化:“{$Name},屠龙宝刀点就送!明星都在玩!”
好了,结果是,在发出推送的24小时内:
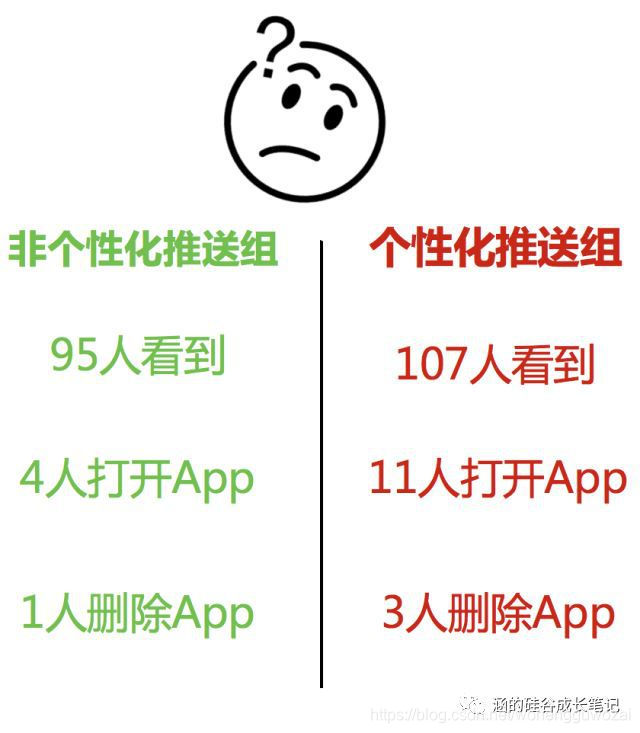
第一组,有95个人看到了,有4个人打开了App,但有1个人删除了你的App (可能是因为太烦了)。
第二组,有107个人看到了,有11个人打开了App,但是有3个人删除了你的App。。。
这结果就很尴尬了,喜忧参半的悖论?于是你打开了知乎,问到:
谢邀。如果只看打开率的话,那可能是第二组更好,可是第二组的删除率又上升了。
这怎么搞!
还好我们有统计学。。。
p值是啥?
这个事情,要是交给统计学家,会怎么处理呢?
他们会计算p值(p Value)。
什么意思呢?
p就是概率Probability,p值就是说:新方案根本没啥卵用的可能性。。。
咋算呢?
为了简单,咱先只看打开率。
那么第一组用户的打开率是:4/95 = 4.21%
现在问题的关键是,我们需要知道,第二组这个打开人数的增长,到底是一个恰好出现的偶然结果,还是真的因为“个性化”的通知内容有效而提高的呢?
要知道,很多用户即使不看通知,也会打开App的呀!
统计方法上,我们会先来一个“无效假设(Null Hypothesis)”:也就是假设“个性化”通知根本没啥卵用,于是我们有:
如果“无效假设”成立,第二组的真实打开率,那就是维持4.21%不变嘛,和第一组一样*。
那么,我们来看看,按照4.21%这个打开率,第二组出现11个人打开App的概率是多少呢?
这是一道高考送分题,答案就是:
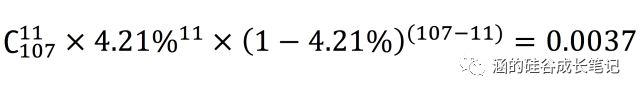
这个值,就是p值, p = 0.0037。它代表,“个性化通知”没有任何用处的概率仅为0.0037。
其实,p值就表示了:实验结果纯属巧合的可能性。
所以p值当然是越低越好啦,那么多低是低呢?标准是啥?
硅谷各公司,普遍采用的p值标准线是0.05。
也就是,如果 p < 0.05, 就代表数据有统计学显著性(Statistically Significant,口语交流时,简称"Stat-Sig"),实验结果是有意义的,无效假设将被驳回(Reject)。
你看,咱打开率的p值小于0.05,那么就可以说:“个性化”通知,对于促进用户打开App,有效。
我们再回过头来,看看两组删除率的p值,经过计算,我们得出p = 0.1795,大于0.05,也就是说,删除率上升,纯属偶然!
这下好啦!!产品决策清晰了!
相比原来的非个性化推送,我们发现个性化的推送打开率有显著性提升,而删除率则没有显著的统计学差异。
于是,你们欢快地决定:上线“个性化推送”功能!! PM今晚请大家吃鸡!!
2、A/B测试
上面提到的,整个新产品的验证过程,被称之为“A/B Test”(AB测试)。A和B就是指,实验里的两个组。

AB测试是最最简单的工具啦,实际工作中会遇到更多的奇葩情况,那“A/B Test”可就不够了。比如,涉及到两个用户以上的社交功能,还有涉及到“钱“的情况等等,这些我以后再讲。。。
可以说,硅谷就是由实验驱动着的。无论是一个小小的UI变动,还是推荐算法模型的升级,都会进行一次实验。因为实在是太常用了,很多大型App里,往往同时运行着超级多的实验。
为了提高效率,各厂们都纷纷开发了,专门的实验工具和分析系统,让人们快速使用。
比如:
Google旗下Analytics产品的Content Experiments工具:
他可以快速的通过UI创建一个实验,还能在运行时,利用Multi-armed bandit算法,自动调整并分配流量比例,到不同的用户组,以加快实验速度。结束后,还会自动生成报表。

















 3073
3073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









