







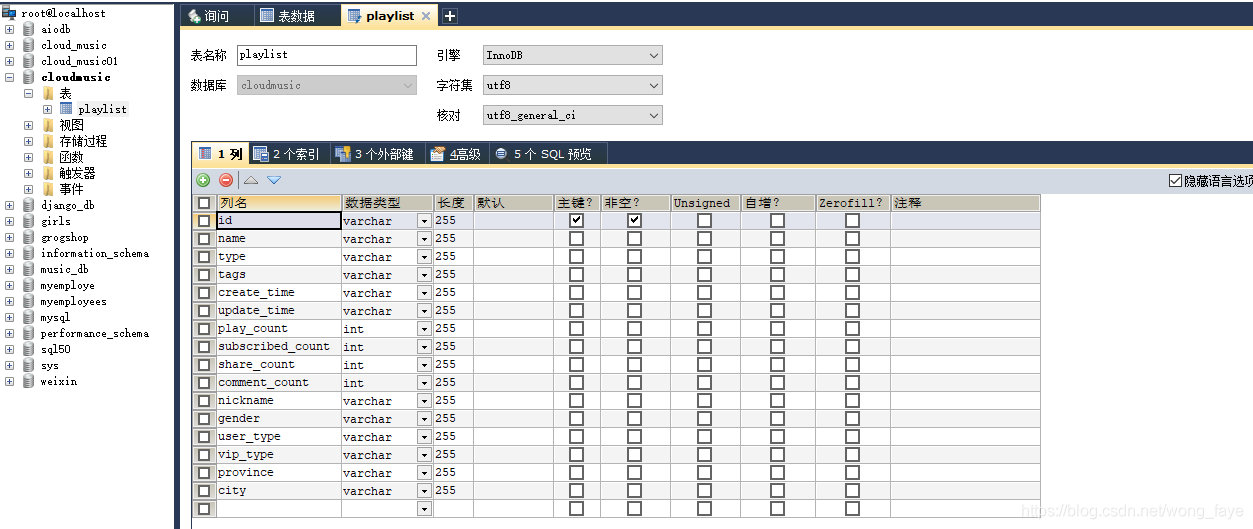
1.创建数据库
(1)创建如下数据库
(2)导入包、连接数据库
import re
import csv
import json
import time
import pymysql
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
# 歌单类型链接
type_url = "https://music.163.com/discover/playlist"
# 连接数据库
db = pymysql.connect(
host = "localhost",
user = "root",
password = "123",
port=3306,
db = "cloudmusic"
)
cursor = db.cursor()
2.获取歌单类型
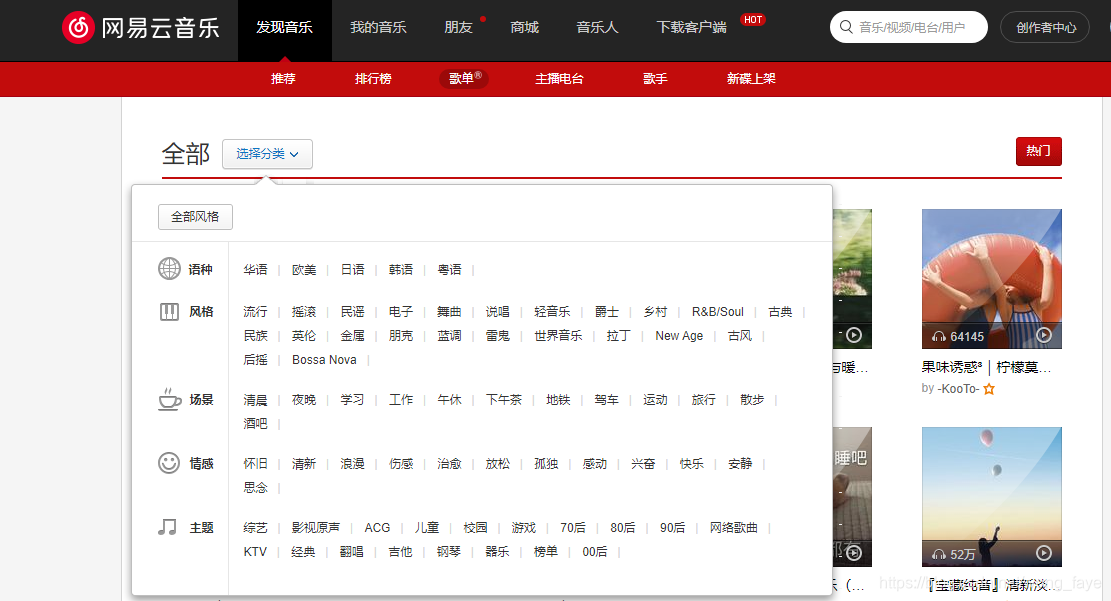
"""获取歌单类型"""
def get_playlist_type(url):
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'lxml')
types = [t.text for t in soup.select("a.s-fc1")][1:]
return types
3.获取歌单ID
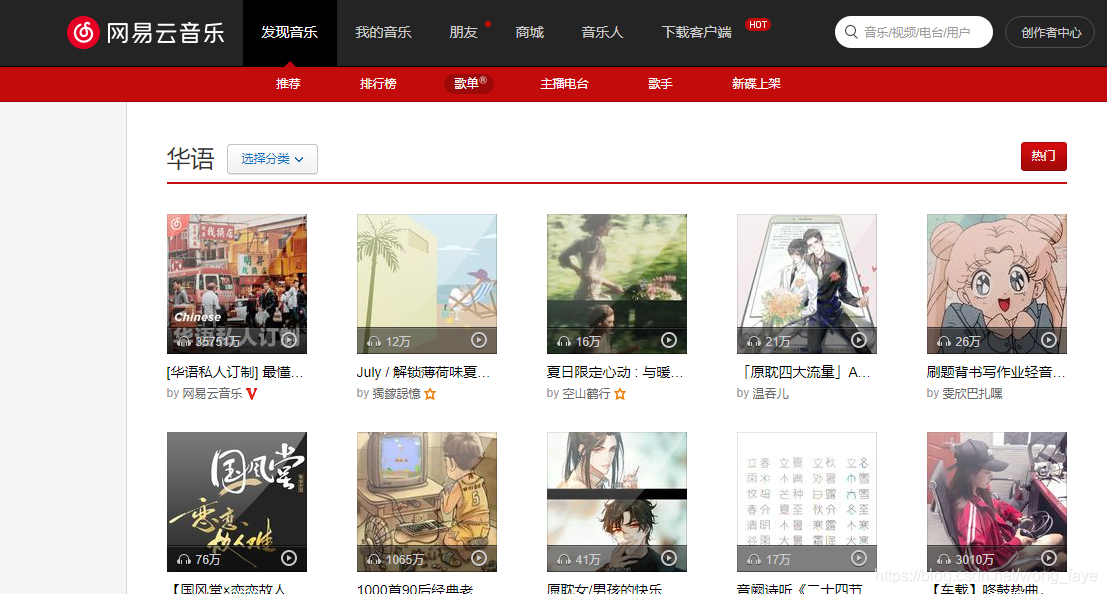

传入歌单页的链接地址,解析,用正则匹配链接,去掉非数字字符,提取出数字,就是歌单的ID,t是从传入的链接解析出的歌单类型,如“华语”,之后将歌单ID和歌单类型传入获取歌单信息的函数中。
"""获取歌单id"""
def get_playlist_id(url):
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'lxml')
ids = [re.sub(r"\D+", "", i['href']) for i in soup.select("a.msk")]
t = re.search('https.*cat=(.*)&limit', url).group(1)
get_playlist_info(ids, t)
4.获取歌单信息
获取歌单信息我们使用网易云的API,传入歌单ID即可
https://api.imjad.cn/cloudmusic/?type=playlist&id=
获取到一个json文件信息

可以使用json解析器解析,网上随便可以找到
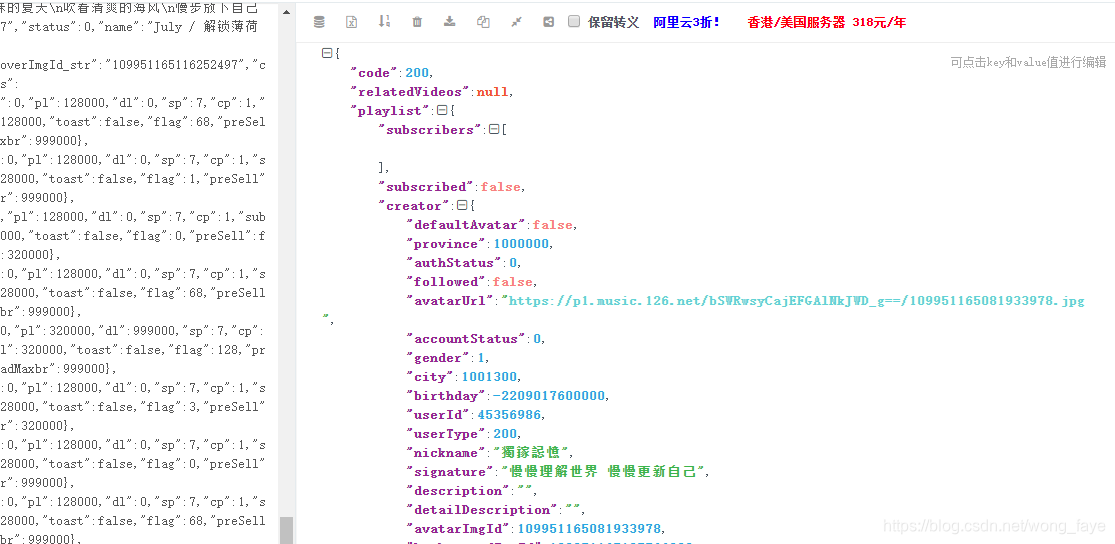
接下来就可以从json文件中提取数据了,但是我们看到province和city字段都是省份和城市的代码,需要转换成汉字的城市名,因此在网站找到了一份城市代码表,进行匹配。

"""获取歌单信息"""
def get_playlist_info(ids, t):
playlist_url = "https://api.imjad.cn/cloudmusic/?type=playlist&id={}"
urls = [playlist_url.format(i) for i in ids]
for url in urls:
try:
response = requests.get(url=url, headers=headers)
json_text = response.text
json_playlist = json.loads(json_text)["playlist"]
except:
continue
# 歌单ID、歌单名、歌单类型、标签、创建时间、最后更新时间、播放量、收藏量、转发量、评论数
# 用户名、性别、用户类型、VIP类型、省份、城市
playlistID = str(json_playlist["id"])
name = json_playlist["name"]
playlistType = t
tags = "、".join(json_playlist["tags"])
createTime = time.strftime("%Y-%m-%d", time.localtime(int(str(json_playlist["createTime"])[:-3])))
updateTime = time.strftime("%Y-%m-%d", time.localtime(int(str(json_playlist["updateTime"])[:-3])))
playCount = json_playlist["playCount"]
subscribedCount = json_playlist["subscribedCount"]
shareCount = json_playlist["shareCount"]
commentCount = json_playlist["commentCount"]
nickname = json_playlist['creator']['nickname']
gender = str(json_playlist['creator']['gender'])
userType = str(json_playlist['creator']['userType'])
vipType = str(json_playlist['creator']['vipType'])
province = str(json_playlist['creator']['province'])
city = str(json_playlist['creator']['city'])
# 匹配性别、省份、城市代码
if gender == '1':
gender = '男'
else:
gender = '女'
# 打开行政区代码文件
with open("country.csv", encoding="utf-8") as f:
rows = csv.reader(f)
for row in rows:
if row[0] == province:
province = row[1]
if row[0] == city:
city = row[1]
if province == '香港特别行政区':
city = '香港特别行政区'
if province == '澳门特别行政区':
city = '澳门特别行政区'
if province == '台湾省':
city = '台湾省'
if province == str(json_playlist['creator']['province']):
province = '海外'
city = '海外'
if city == str(json_playlist['creator']['city']):
city = province
playlist = [playlistID, name, playlistType, tags, createTime, updateTime,
playCount, subscribedCount, shareCount, commentCount,
nickname, gender, userType, vipType, province, city]
print(playlist)
save_to_db(playlist)
5.保存到数据库
"""保存到数据库"""
def save_to_db(l):
sql = """insert into playlist(id, name, type, tags, create_time, update_time,
play_count, subscribed_count, share_count, comment_count, nickname,
gender, user_type, vip_type, province, city)
values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""
try:
cursor.execute(sql, (l[0],l[1],l[2],l[3],l[4],l[5],l[6],l[7],l[8],l[9],l[10],l[11],l[12],l[13],l[14],l[15]))
db.commit()
except:
db.rollback()
6.主函数
使用多进程爬取,因为每个类型的歌单有37-38页,因此我们每种类型爬取前37页。
def main():
types = get_playlist_type(type_url)
urls = []
for t in types:
for i in range(37):
url = "https://music.163.com/discover/playlist/?order=hot&cat={0}&limit=35&offset={1}".format(t, i*35)
urls.append(url)
pool = Pool(10)
for url in urls:
pool.apply_async(get_playlist_id, args=(url,))
pool.close()
pool.join()
if __name__ == "__main__":
main()
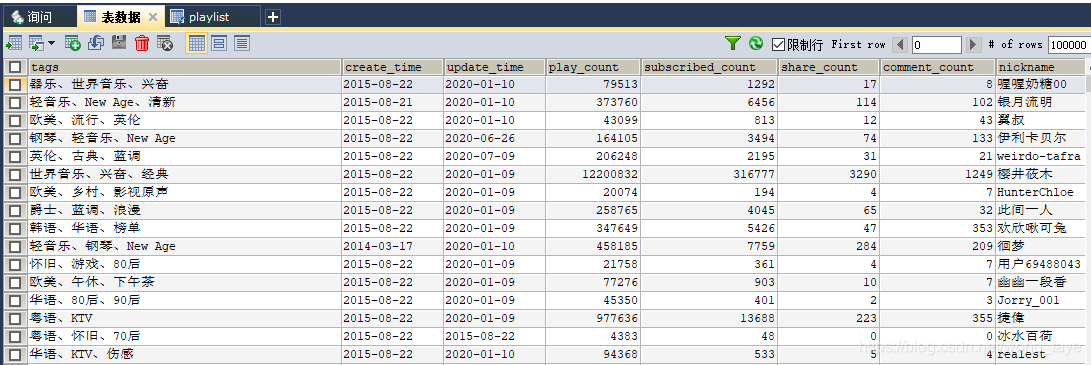
7.爬取结果

















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









