






论文标题:Decorate the Newcomers: Visual Domain Prompt for Continual Test Time Adaptation
论文链接:https://arxiv.org/abs/2212.04145
代码:https://github.com/Jo-wang/Daily-Paper-Reading/blob/main/test-time/Decorate%20the%20Newcomers%3A%20Visual%20Domain%20Prompt%20for%20Continual%20Test%20Time%20Adaptation.md
引用:Gan Y, Bai Y, Lou Y, et al. Decorate the newcomers: Visual domain prompt for continual test time adaptation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2023, 37(6): 7595-7603.

导读
持续测试时间自适应(Continual Test-Time Adaptation,CTTA)旨在在没有访问源数据的情况下,将源模型不断地适应变化的未标记目标领域。现有的方法主要集中在以自训练为基础的模型适应,例如为新领域数据集预测伪标签。
由于伪标签存在噪声和不可靠性,这些方法在处理动态数据分布时容易发生灾难性遗忘和误差累积问题。在 NLP 领域的提示学习的启发下,本文提出了在目标领域学习图像级视觉域提示的方法,同时保持源模型参数冻结。在测试过程中,通过使用学到的视觉提示来重构输入数据,可以将变化的目标数据集适应到源模型上。
具体而言,我们设计了两种类型的提示,即领域特定提示和领域无关提示,以提取当前领域知识并在持续适应中保持领域共享知识。此外,我们设计了一种基于稳态的提示适应策略,以抑制领域敏感参数,使领域不变提示更有效地学习领域共享知识。从依赖于模型的范式转变为不依赖于模型的范式使得能够绕过灾难性遗忘和误差累积问题。
实验证明,所提出的方法在四个广泛使用的基准数据集上,包括 CIFAR-10C、CIFAR-100C、ImageNet-C 和 VLCS 数据集,取得了显著的性能提升,优于现有方法。
本文贡献
我们在处理 CTTA 问题时提出了一种轻量级的提示方法,据我们所知,这是首个从输入图像级别处理 CTTA 问题的方法。通过使用视觉域提示动态更新输入图像像素的一小部分,实现了领域自适应,并缓解了误差累积问题。
我们进一步引入了一种基于内稳态的即时适应策略,通过限制过度适应导致的领域敏感参数来避免灾难性的遗忘。
根据在广泛的基准数据集上进行的实验,我们提出的方法优于大多数最先进的方法,涵盖了合成和真实世界的领域差距。这证明了我们的方法在性能和成本上都是实用的,胜过了大多数最先进的方法。
本文方法
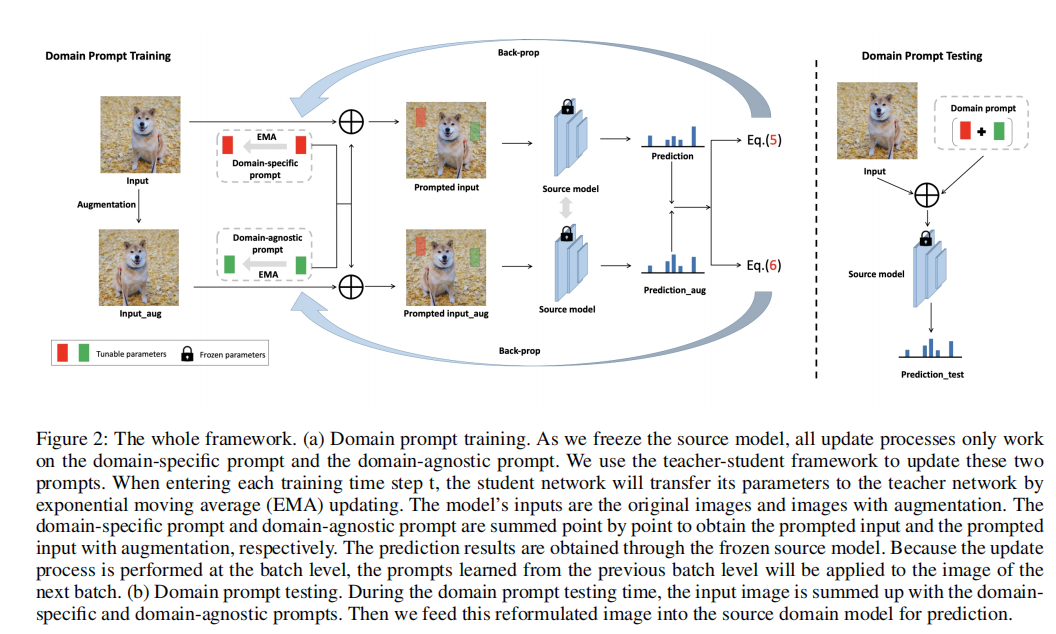
该框架包括两个模块,一个是视觉域提示模块(包括两种类型的提示),另一个是基于稳态的提示更新策略(见图2)。
(a) 域提示训练。当我们冻结源模型时,所有的更新进程都只在域特定的提示符和与域无关的提示符上工作。我们使用师生框架来更新这两个提示。当进入每个训练时间步长t时,学生网络将通过指数移动平均(EMA)更新将其参数传递到教师网络。模型的输入是原始图像和增强图像。将域指定提示和域不可知提示逐点求和,分别得到提示输入和经过增强的提示输入。通过冻结源模型得到了预测结果。因为更新过程是在批处理级别上执行的,所以从上一个批处理级别学习到的提示将应用于下一个批处理的图像。(b) 域提示符测试。在域提示测试期间,输入图像用域指定提示和域不可知提示进行总结。然后,我们将这个重新制定的图像输入源域模型进行预测。
通过视觉域提示持续测试时间适应
我们提出的轻量级视觉域提示包括两种类型:领域特定提示(DSP)和领域无关提示(DAP)。作为输入数据和模型之间的信使,视觉域提示直接添加在输入图像的一部分上,然后将装饰后的图像输入源模型进行预测。这些提示会根据两种不同的损失函数定期更新。领域特定提示旨在提取当前领域知识,而领域无关提示对维持领域共享知识产生影响。
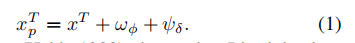
在公式1中,将领域特定提示表示为 ,将领域无关提示表示为

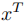
其次,根据 Hebbian 理论,我们采用了不同的损失函数来确保神经元的可塑性并增强其稳定性。Hebbian 理论表明,可塑性是一种神经元之间检测和增强共同活动的突触机制,包括 Hebbian 可塑性和稳态可塑性,旨在在短时间内迅速稳定神经元活动。这启发了我们实现 DSP 和 DAP 的功能。
更新提示机制
更新提示的机制是使用教师-学生网络作为框架。当学生网络
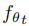

基于稳态的提示适应策略
我们使用交叉熵损失来优化 DSP 以学习领域特定知识。至于 DAP,为了提取更多领域无关的知识,我们使用额外的稳态正则化。通过限制对领域变化敏感的参数,我们达到了挖掘领域无关知识的目标。
参数对不同领域的敏感性
定义
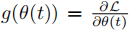
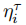

稳态因子被定义为:

在公式 4 中,这个正则化项将惩罚那些对领域变化敏感的参数,并稳定地更新领域无关的参数,以巩固领域无关的知识。
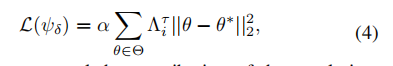
注意,进入新的目标领域时,

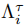
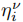
损失函数
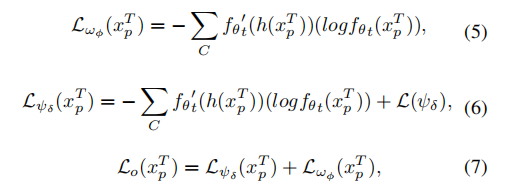
实验
实验结果
与其他方法的比较:
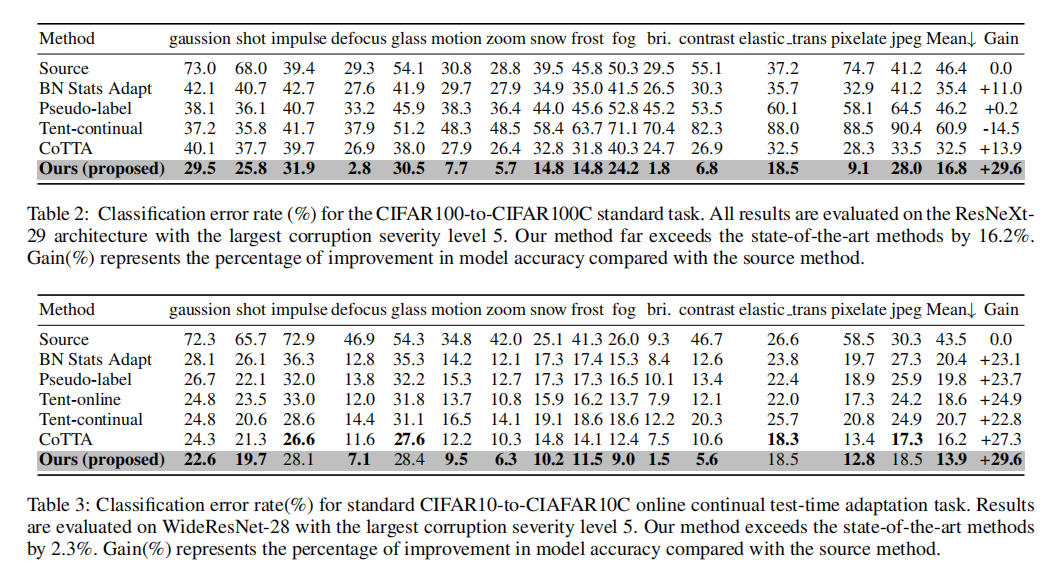
在VLCS上的抗遗忘性能:
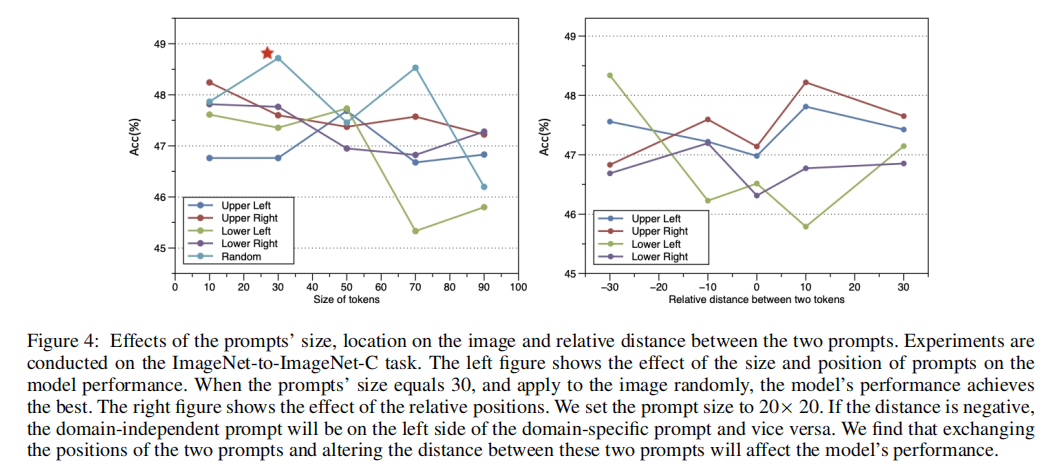
提示大小的影响:
消融实验

结论
为了解决CTTA的错误积累问题,我们首先引入了一个视觉域提示的概念,即 1) 小图像标记,2) 动态地添加到输入图像上,将它们从不断变化的目标域转移到规则域。然后,我们提出了一个新的框架,通过视觉域提示(VDP)的持续测试时间自适应,它包括VDP更新模块和基于内稳态的自适应策略。我们从使用轻量级的域提示符令牌来改变输入图像的角度来解决这个问题。在多个基准数据集上的大量实验表明,我们的方法以相对较小的成本实现了SOTA性能。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









