







太阳能电池板已经成为农业、交通、建筑和酒店等多个行业中受欢迎的可再生能源来源。通过利用太阳的能量,我们可以在不损害环境的情况下产生电力。然而,使用太阳能电池板面临着一些挑战,其中最大的之一是它们表面上尘埃的积累。这会显著降低它们的效率,限制它们在能源生产和其他应用中的实用性。
为了解决这个问题,自动化可以在确保太阳能电池板定期及时维护方面发挥关键作用。通过自动化清洁过程,我们可以提高生产效率和效率,同时还减少能源生产的环境影响。总体而言,太阳能电池板的潜在好处是广泛而多样的,借助自动化的帮助,我们可以克服与它们使用相关的挑战,继续推动这个令人兴奋且迅速发展的领域的进展。
借助深度学习和大量计算资源的帮助,我们可以在太阳能电池板上尘埃积累时向当局发出警报。卷积神经网络(CNN)以其图像识别能力而闻名。迁移学习是一种利用复杂任务的预训练权重的方法,用于我们的太阳能电池板尘埃检测任务。因此,这些方法可以用来提高深度学习模型的准确性和F1分数。
本文将实施一个关于构建太阳能电池板尘埃检测分类器的项目。对大量神经网络配置进行测试,最终确定在实时部署中使用的最佳架构。
导入库
我们将查看在构建太阳能电池板尘埃检测分类器过程中使用的一系列库的列表。
# Importing the basic libraries to be used in the notebook
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
import cv2
from tqdm import tqdm
from tensorflow.keras.applications import Xception, VGG16, VGG19
from tensorflow.keras.applications import InceptionV3, MobileNet, InceptionV3
import random
from tensorflow.keras.layers import Input, Dropout, Flatten, Dense
from tensorflow.keras.layers import AveragePooling2D, GlobalAveragePooling2D
from tensorflow.keras import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.metrics import roc_curve, roc_auc_score, auc
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
from tensorflow.keras.applications.mobilenet import MobileNet
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.optimizers import RMSprop
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Model
from tensorflow.keras.applications.resnet50 import ResNet50
import warnings
warnings.filterwarnings('ignore')
print("Is GPU Available: {}".format(tf.config.list_physical_devices('GPU')))在构建深度学习应用程序时,我们可以使用众多库,包括TensorFlow、NumPy、Pandas和OS等。虽然一开始可能会让人感到不知所措,但了解如何在代码中使用这些库可以极大地简化开发过程,并使我们的模型更加有效。
通过利用这些强大的工具,我们可以简化数据处理、特征工程、模型训练和部署。通过对这些库及其功能的扎实掌握,我们可以更轻松、更高效地构建更复杂和准确的模型。
在本文中,我们将广泛使用这些库来构建我们的太阳能电池板尘埃检测分类器。通过实际示例和逐步说明,你将学会如何利用这些工具的力量,并将它们应用于实际问题。
读取数据
要开始构建我们的太阳能电池板尘埃检测分类器,第一步是从本地计算机上预定义路径加载图像。然而,这些图像的确切位置可能会根据用户计算机的配置而有所不同。
为执行此加载操作,我们定义一个单独的函数,从指定路径提取图像,同时舍弃任何低分辨率的图像。这确保我们的数据集只包含适用于深度学习模型训练的高质量图像。
# Defining a function to load images
def load_images(directory, grayscale = GRAYSCALE, size = SIZE):
destination_dir = directory + "_Discarded"
if not os.path.exists(destination_dir):
os.makedirs(destination_dir)
images = [] # Creating a list to store the images in the form of array
for filename in tqdm(os.listdir(directory)):
img = cv2.imread(os.path.join(directory, filename))
try:
height, width, _ = img.shape
# move images with small dimenstions to the discarded folder
if (height < 800 and width < 400 ) or (height < 400 and width < 800 ):
shutil.move(os.path.join(directory, filename), os.path.join(destination_dir, filename))
continue
if grayscale:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.resize(img, size)
x = np.array(img)
x = np.expand_dims(x, axis=0)
images.append(x)
except Exception as e:
continue
return images
# Loading the clean and dusty solar panel images from directories
# This can take about 2 minutes to run and load the images and convert them to array
clean_images_array = load_images(clean_images_dir, grayscale = GRAYSCALE)
dusty_images_array = load_images(dirty_images_dir, grayscale = GRAYSCALE)我们已将清洁和尘埃覆盖的太阳能电池板存储为用于计算的数组列表。请注意,我们处理的是一个小型数据集,不存在内存错误等问题。如果处理大型数据集,建议使用ImageDataGenerator,因为它以批量从磁盘加载数据。
探索性数据分析(EDA)
这是机器学习生命周期的重要部分,用于检查ML模型使用的数据集是否存在数据不一致和异常值。通过这种方式,可以采取特征工程步骤来删除这些数据点,有助于构建强大的分类器。

上图是我们将在分类器中使用的图像列表,以确定面板是干净的还是尘土飞扬的。需要注意的是,有一些图像包含文本。还有其他一些图像包含白色背景或没有适当裁剪。因此,在特征工程阶段,采取措施删除这些图像,因为它们可能会使我们的分类器在进行准确预测时感到困惑。
特征工程
为了确保只有高质量的图像用于训练,我们采取步骤舍弃数据集中具有白色背景的图像。通过实施以下代码,识别并删除任何具有主要白色背景的图像。通过这样做,我们可以提高模型训练过程的整体准确性和可靠性。
# This function returns the paths of images that contain white background
def remove_white_background_images(path, threshold = 0.2):
image_paths = []
for image in tqdm(os.listdir(path)):
image_path = os.path.join(path, image)
image_array = cv2.imread(image_path)
try:
image_array = cv2.resize(image_array, (224, 224), interpolation = cv2.INTER_AREA)
except:
continue
gray = cv2.cvtColor(image_array, cv2.COLOR_BGR2GRAY)
_, binary_image = cv2.threshold(gray, 240, 255, cv2.THRESH_BINARY)
white_pixel_count = cv2.countNonZero(binary_image)
total_pixel_count = binary_image.shape[0] * binary_image.shape[1]
percentage_of_white_pixels = white_pixel_count / total_pixel_count
if percentage_of_white_pixels > threshold:
image_paths.append(image_path)
return image_paths
white_background_image_paths = remove_white_background_images(clean_images_path)
white_background_image_paths_dusty = remove_white_background_images(dusty_images_path)
从输出结果来看,白底图像被准确识别。然而,数据中存在一些误报。但我们可以继续使用这种方法收集没有白底的图像。
模型训练
让我们看一下所有可能用于训练太阳能电池板尘埃分类器的模型列表。初始配置是一个深度适中的卷积神经网络,其中包含卷积层、最大池化层和平坦层。以下是代码实现。
配置1
model = Sequential()
model.add(Conv2D(8, (2, 2), activation = 'relu', input_shape = INPUT_SHAPE))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Conv2D(4, (2, 2), activation = 'relu'))
model.add(Flatten())
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', optimizer = 'Adam',
metrics = ['accuracy'])
model.summary()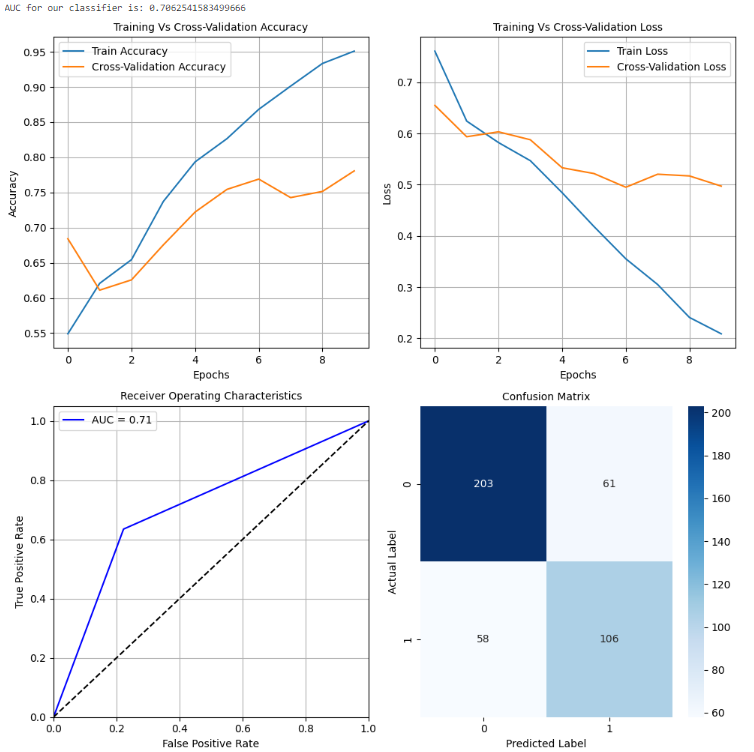

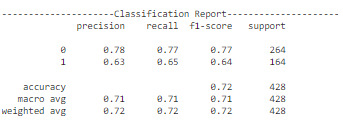
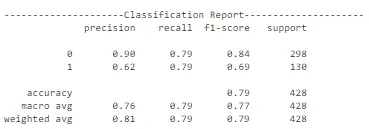
有一个设计用于绘制所有指标的列表并让我们更好地了解这些指标的模型性能的功能。其中包括分类报告、混淆矩阵和其他图表,帮助我们确定用于生产的最佳模型。
随着训练轮次的增加,准确性有所提高,错误有所减少。此外,值得注意的是,随着额外训练,交叉验证错误也减少了。这意味着仍有更多的空间进行进一步的训练。必须小心,以防止模型过拟合训练数据。我们还可以查看其他配置,以确定实时部署的最佳模型。
配置2
model = Sequential()
model.add(Conv2D(4, (2, 2), activation = 'relu', input_shape = INPUT_SHAPE))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Conv2D(2, (2, 2), activation = 'relu'))
model.add(Flatten())
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', optimizer = 'Adam',
metrics = ['accuracy'])
model.summary()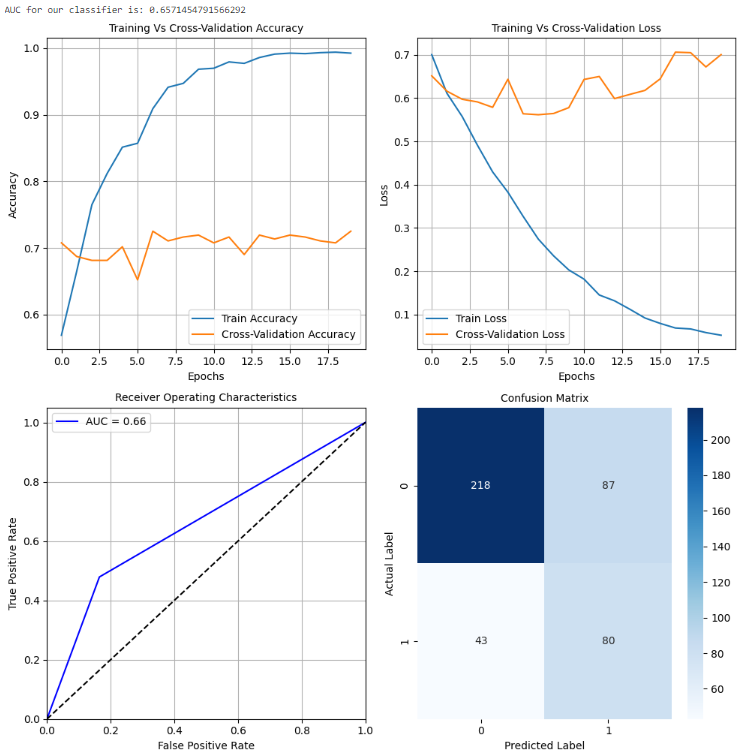

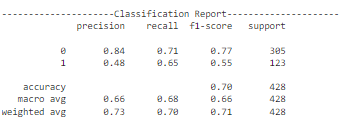
如上述代码所示,定义了一个新的配置。跟踪数据集性能的指标。此配置倾向于在训练准确性有所提高的同时,交叉验证准确性下降或保持稳定。损失曲线也反映了这一点,随着轮次的增加,训练损失减少,而交叉验证损失增加。因此,该模型在训练数据上过拟合,对测试集的改进不大。
配置3
model = Sequential()
model.add(Conv2D(2, (3, 3), activation = 'relu', input_shape = INPUT_SHAPE))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.6))
model.add(Conv2D(2, (2, 2), activation = 'relu'))
model.add(Flatten())
model.add(Dropout(0.6))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', optimizer = 'Adam',
metrics = ['accuracy'])
model.summary()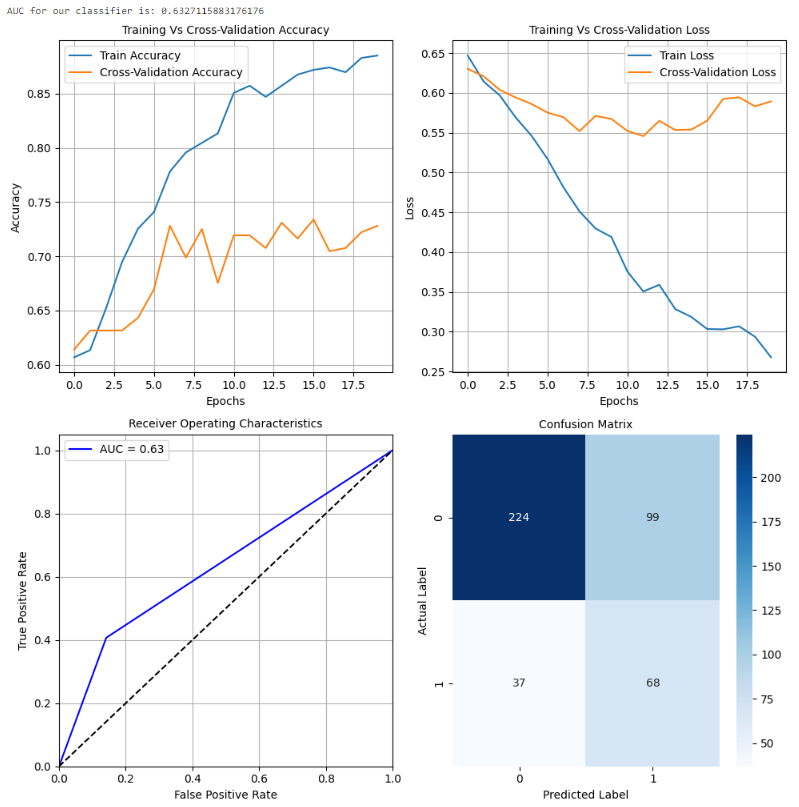

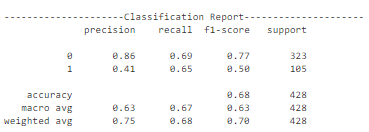
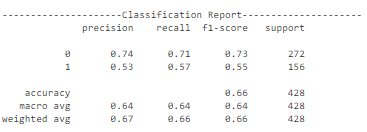
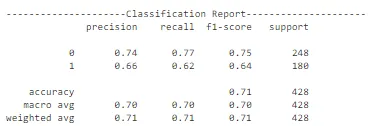
此配置的行为与前一个配置相似,存在过拟合问题。然而,这些曲线表明,与前一个配置相比,模型在训练数据上的过拟合程度较小。模型在测试数据上的准确性约为68%。正类别的精度也相当低。因此,可以使用其他配置和迁移学习方法来在很大程度上提高模型的性能。
配置4
model = Sequential()
model.add(Conv2D(2, (2, 2), activation = 'relu', input_shape = INPUT_SHAPE))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Flatten())
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', optimizer = 'Adam',
metrics = ['accuracy'])
model.summary()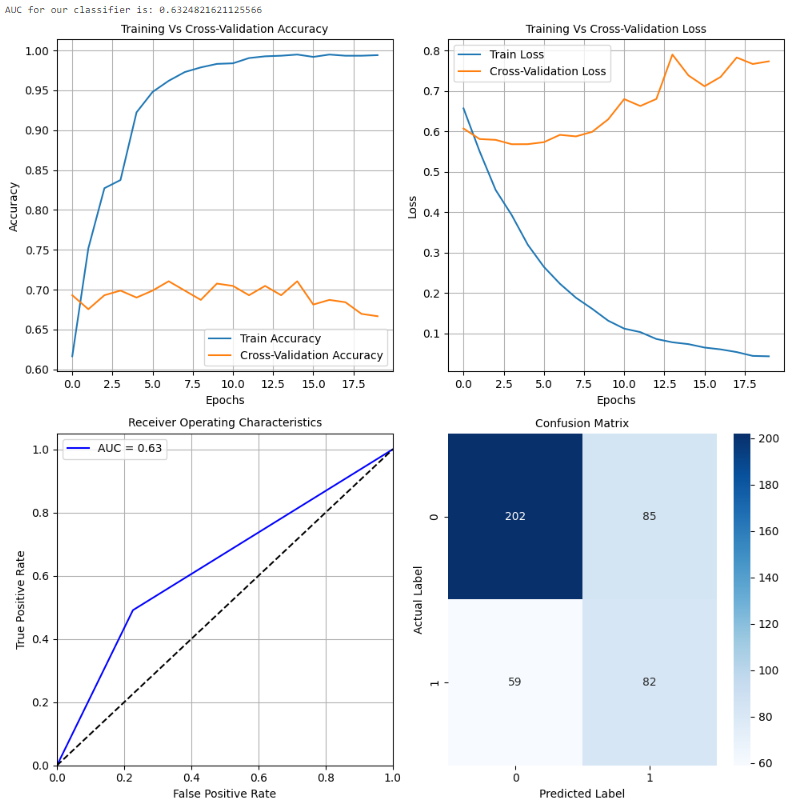

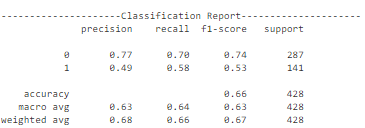
此模型性能与前两个测试的配置非常相似。在训练和损失曲线中存在对训练数据的过拟合。自定义CNN配置并没有像预期的那样工作,特别是对于正类别的准确性和f1-score较低。可以使用更复杂的附加模型,因为它们应该能够找到数据中的潜在模式并做出良好的预测。
迁移学习模型
我们可以查看迁移学习模型的列表,并确定其在测试集上的性能。这些模型是在包含大量样本的ImageNet数据上预先训练的。我们提取这些网络的权重,用于我们的太阳能电池板尘埃检测任务,并重新训练最后几层以节省计算。
VGG 16
# Loading the VGG16 Model and using transfer learning for our task
headmodel = VGG16(weights = "imagenet", include_top = False,
input_shape = (224, 224, 3))
model = headmodel.output
model = AveragePooling2D(pool_size = (2, 2))(model)
model = Flatten(name = 'flatten')(model)
model = Dense(64, activation = 'relu')(model)
model = Dropout(0.3)(model)
model = Dense(32, activation = 'relu')(model)
model = Dropout(0.1)(model)
model = Dense(1, activation = 'sigmoid')(model)
final_model = Model(inputs = headmodel.input, outputs = model)
for layer in headmodel.layers[: -2]:
layer.trainable = False
opt = Adam(lr = 1e-2)
final_model.compile(loss = "binary_crossentropy", optimizer = opt,
metrics = ["accuracy"])
final_model.summary()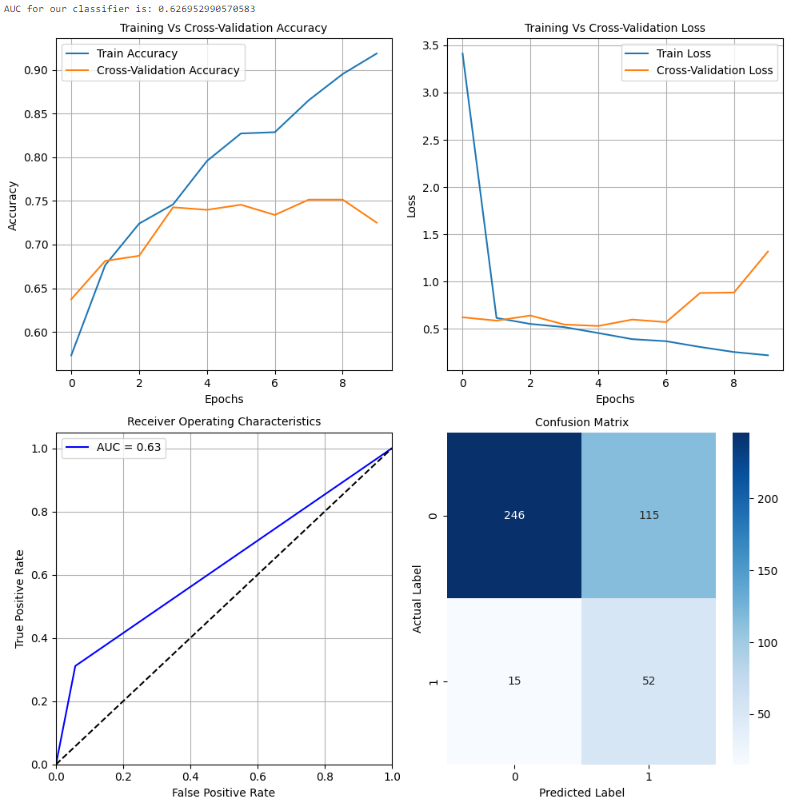


该架构在测试数据上表现良好,准确度约为70%。然而,在交叉验证数据上存在一些过拟合。因此,随着轮次的增加(对整个数据集的迭代),准确性下降。让我们考虑一下其他架构的列表,并确定最佳的部署模型。
VGG 19
# Loading the VGG19 Model and using transfer learning for our task
headmodel = VGG19(weights = "imagenet", include_top = False,
input_shape = (224, 224, 3))
model = headmodel.output
model = AveragePooling2D(pool_size = (2, 2))(model)
model = Flatten(name = 'flatten')(model)
model = Dense(64, activation = 'relu')(model)
model = Dropout(0.3)(model)
model = Dense(32, activation = 'relu')(model)
model = Dropout(0.1)(model)
model = Dense(1, activation = 'sigmoid')(model)
final_model = Model(inputs = headmodel.input, outputs = model)
for layer in headmodel.layers[: -2]:
layer.trainable = False
opt = Adam(lr = 1e-2)
final_model.compile(loss = "binary_crossentropy", optimizer = opt,
metrics = ["accuracy"])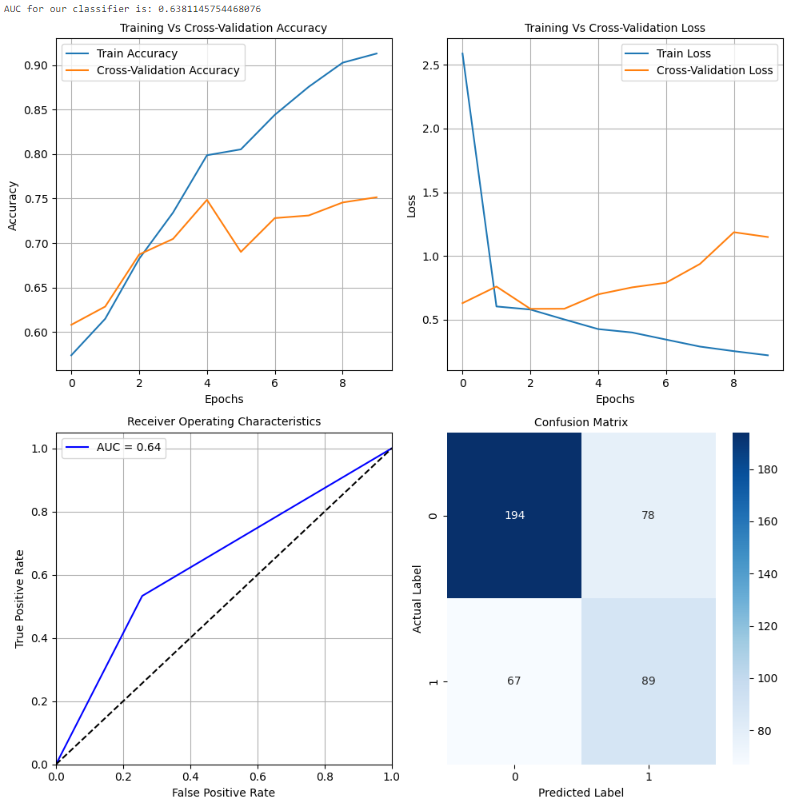

与VGG 16相比,VGG 19网络的性能似乎较差。这是因为前者网络更复杂,导致过拟合的机会更大。当我们探索VGG 16网络时,它也容易过拟合。通过增加网络的复杂性,模型更有可能过拟合训练数据。
InceptionNet
# Loading the InceptionNet Model and using transfer learning for our task
headmodel = InceptionV3(weights = "imagenet", include_top = False,
input_shape = (224, 224, 3))
model = headmodel.output
model = AveragePooling2D(pool_size = (2, 2))(model)
model = Flatten(name = 'flatten')(model)
model = Dense(64, activation = 'relu')(model)
model = Dropout(0.3)(model)
model = Dense(32, activation = 'relu')(model)
model = Dropout(0.1)(model)
model = Dense(1, activation = 'sigmoid')(model)
final_model = Model(inputs = headmodel.input, outputs = model)
for layer in headmodel.layers[: -2]:
layer.trainable = False
opt = Adam(lr = 1e-2)
final_model.compile(loss = "binary_crossentropy", optimizer = opt,
metrics = ["accuracy"])
final_model.summary()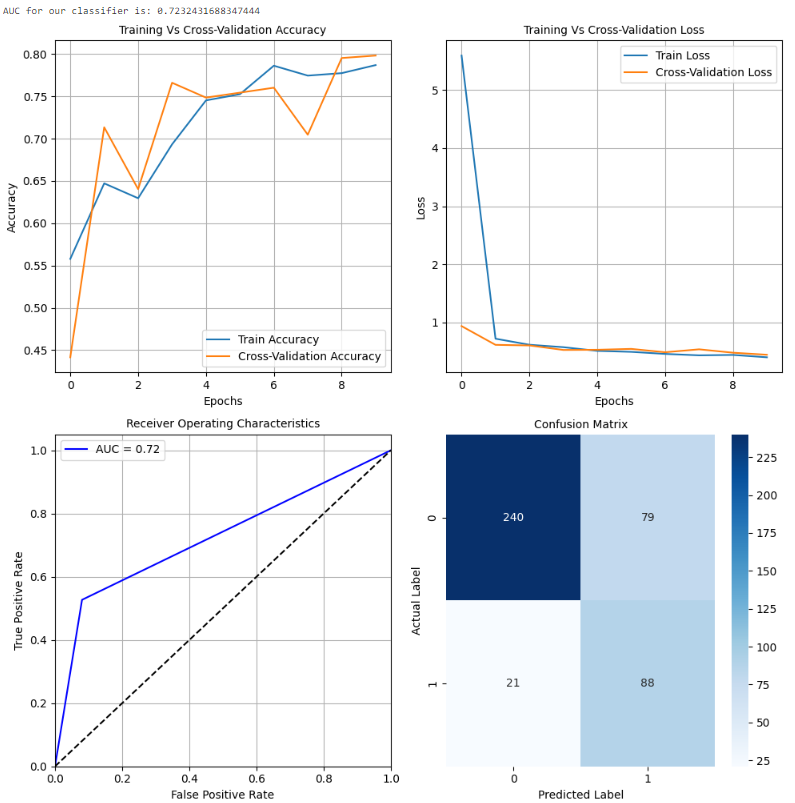
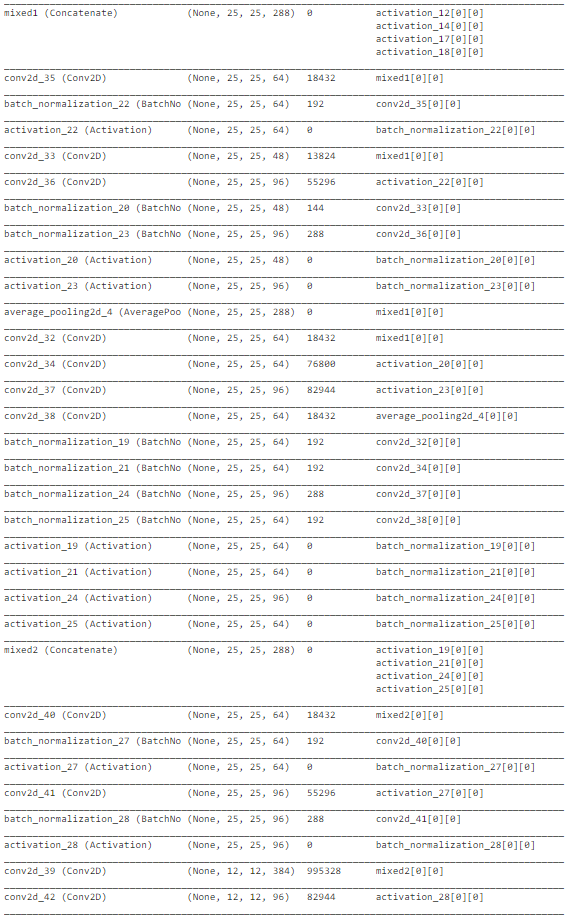
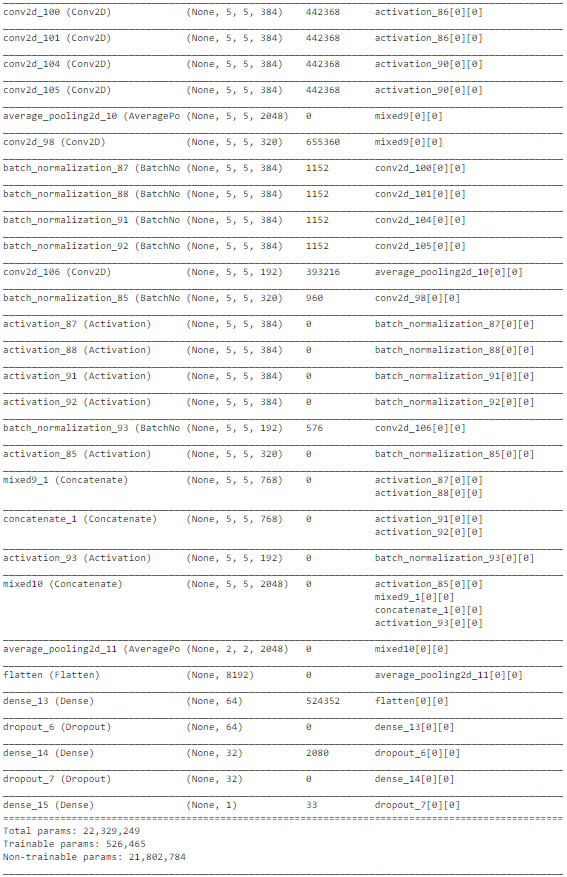
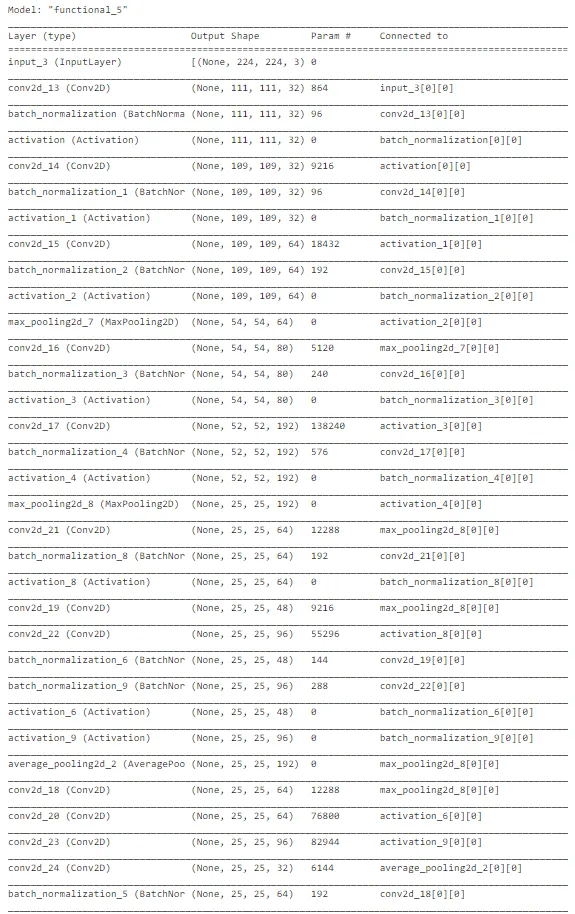
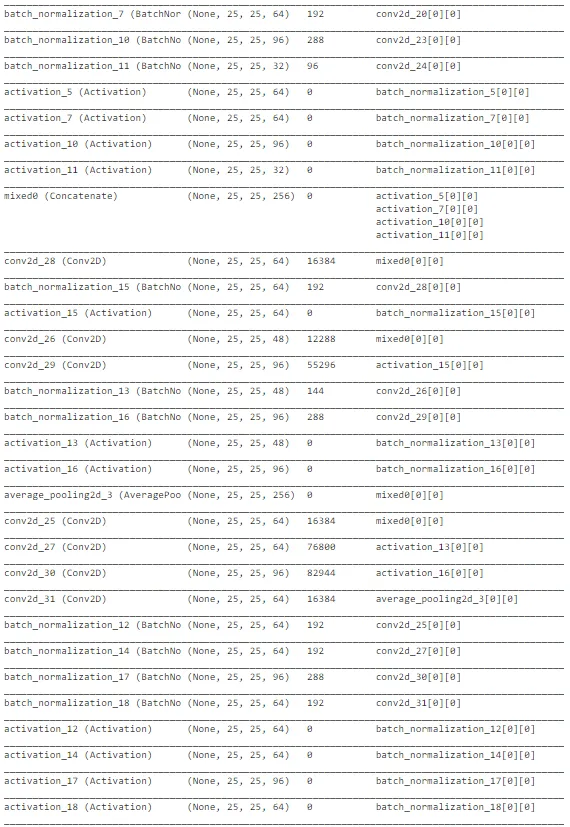
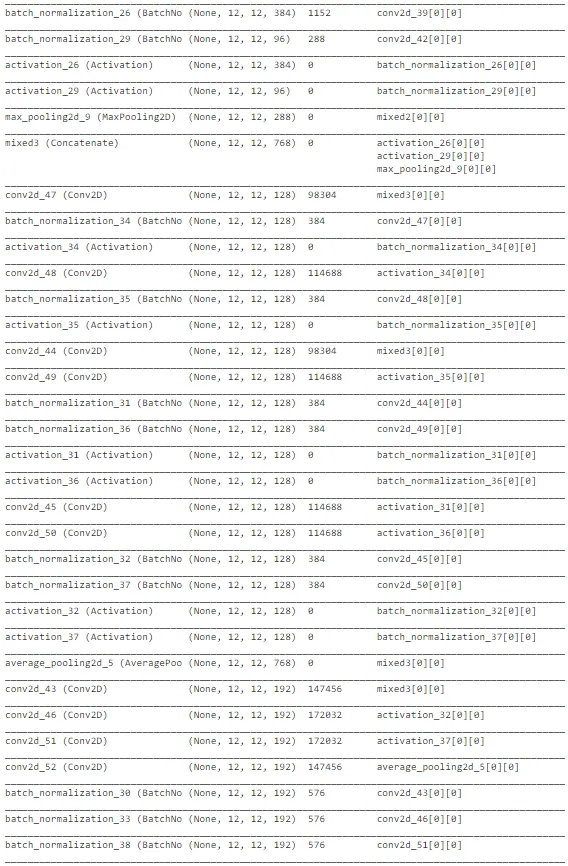
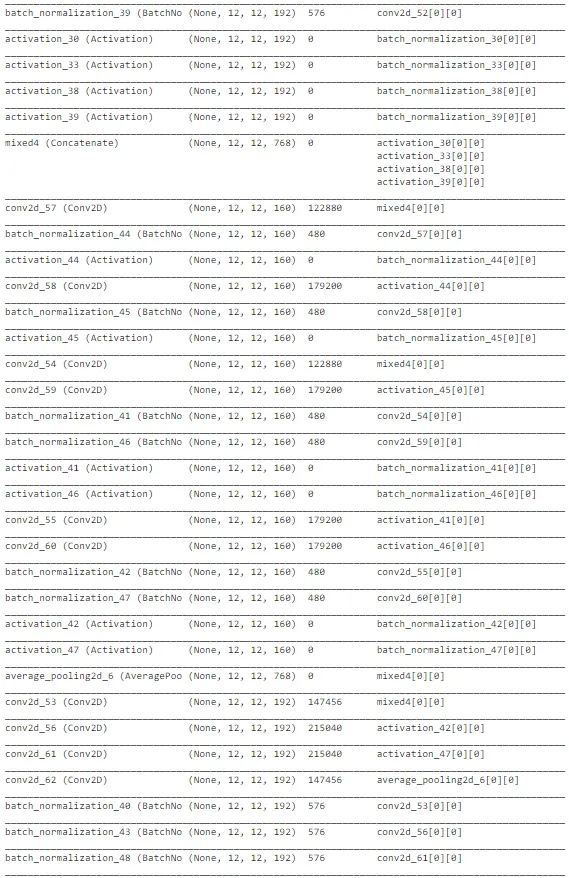
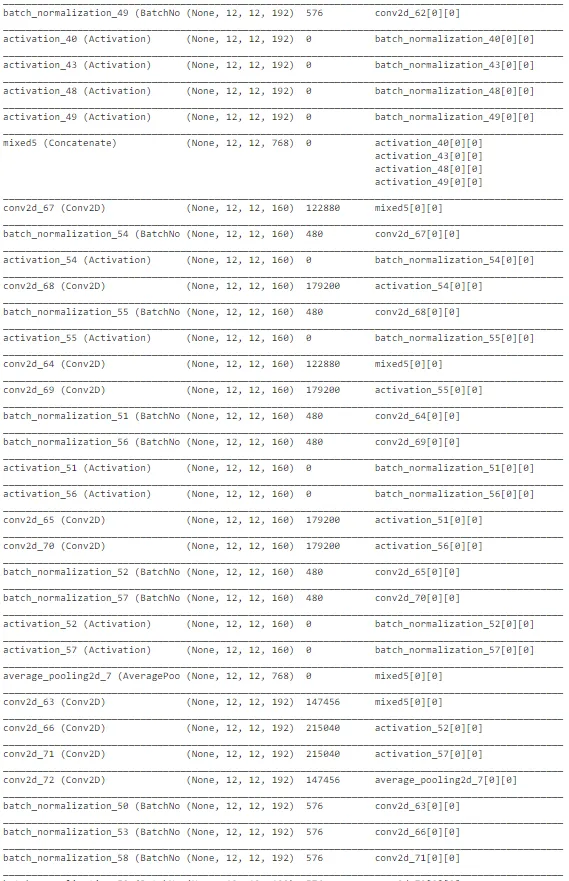
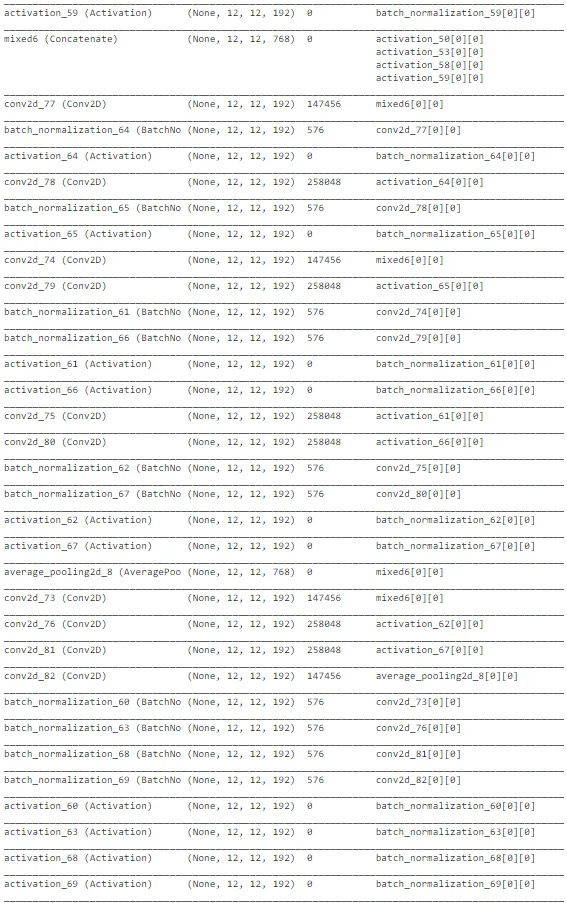
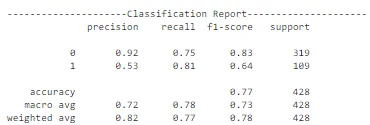
如上图所示,InceptionNet的架构非常复杂,深度大,具有许多隐藏单元。由于网络已经在“ImageNet”上训练过,我们可以从中提取有用的权重,仅考虑训练最后几层以加速该过程。总体而言,InceptionNet在测试数据上的表现最佳,准确性约为77%。
MobileNet
# Loading the MobileNet Model and using transfer learning for our task
headmodel = MobileNet(weights = "imagenet", include_top = False,
input_shape = (224, 224, 3))
model = headmodel.output
model = AveragePooling2D(pool_size = (2, 2))(model)
model = Flatten(name = 'flatten')(model)
model = Dense(64, activation = 'relu')(model)
model = Dropout(0.3)(model)
model = Dense(32, activation = 'relu')(model)
model = Dropout(0.1)(model)
model = Dense(1, activation = 'sigmoid')(model)
final_model = Model(inputs = headmodel.input, outputs = model)
for layer in headmodel.layers[: -2]:
layer.trainable = False
opt = Adam(lr = 1e-2)
final_model.compile(loss = "binary_crossentropy", optimizer = opt,
metrics = ["accuracy"])
final_model.summary()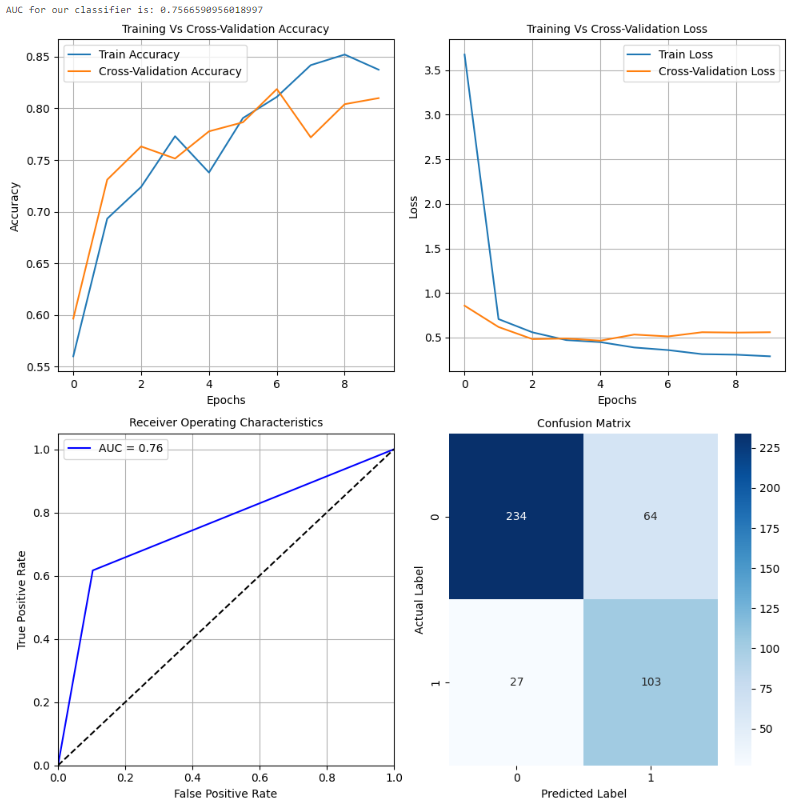



MobileNet 在测试数据上表现异常出色,整体准确率约为 79%。准确度曲线和损失曲线还显示,该模型在训练集上的性能不仅提高,而且在交叉验证数据上也有所增加。此外,该模型可以进一步训练,并通过超参数调整来提高测试数据(未见数据)的性能和泛化能力。请注意进行推理所需的计算复杂性。这表明它可以在较小的配置中很好地泛化,并且能够提供良好的性能。
Xception 网络
# Loading the Xception Model and using transfer learning for our task
headmodel = Xception(weights = "imagenet", include_top = False,
input_shape = (224, 224, 3))
model = headmodel.output
model = AveragePooling2D(pool_size = (2, 2))(model)
model = Flatten(name = 'flatten')(model)
model = Dense(64, activation = 'relu')(model)
model = Dropout(0.3)(model)
model = Dense(32, activation = 'relu')(model)
model = Dropout(0.1)(model)
model = Dense(1, activation = 'sigmoid')(model)
final_model = Model(inputs = headmodel.input, outputs = model)
for layer in headmodel.layers[: -2]:
layer.trainable = False
opt = Adam(lr = 1e-2)
final_model.compile(loss = "binary_crossentropy", optimizer = opt,
metrics = ["accuracy"])
final_model.summary()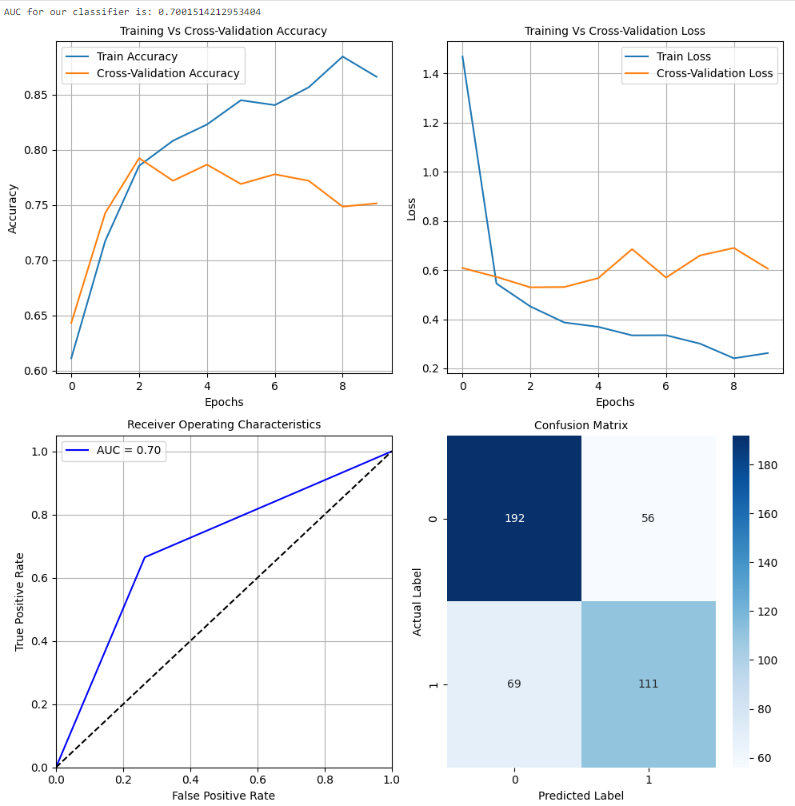
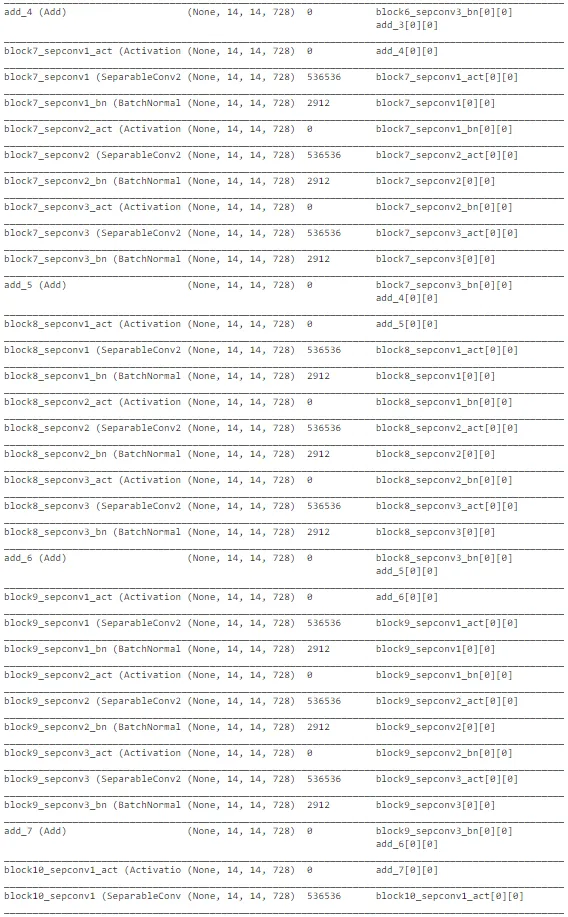
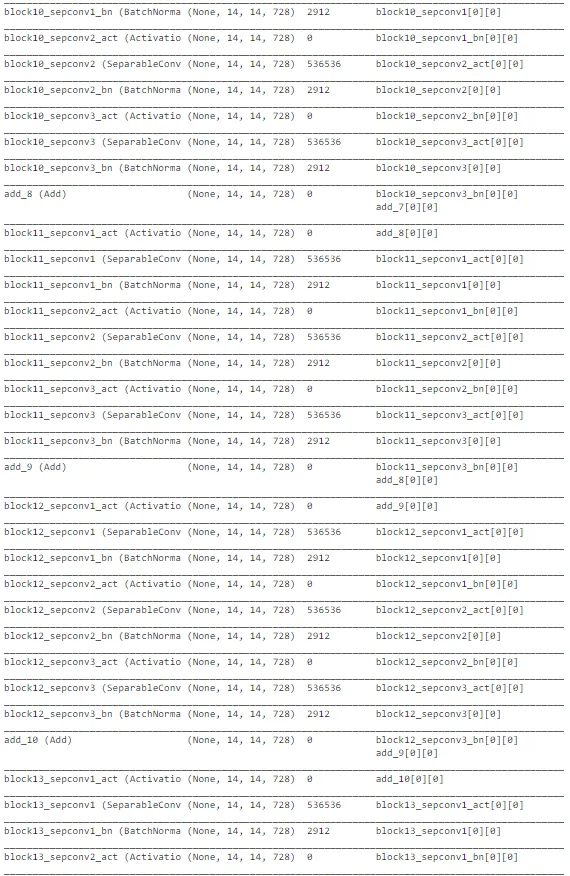
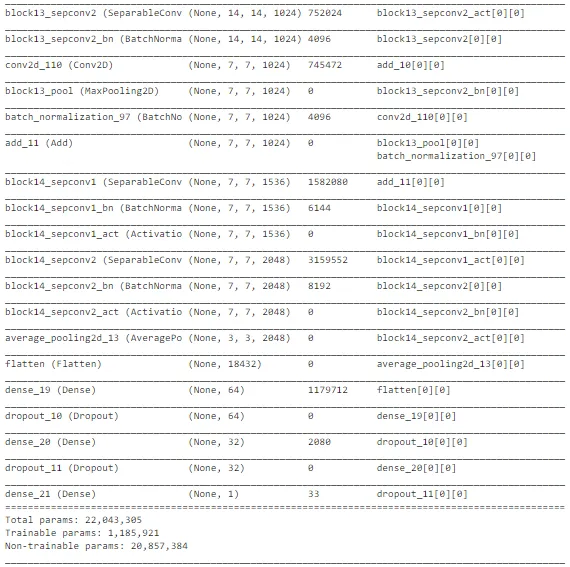
如上所示,Xception 架构也是复杂的。最后几层被修改以确保对太阳能电池板尘埃检测任务可训练。它在测试数据上表现良好,准确率约为 71%。然而,随着轮次的增加,训练准确性和交叉验证准确性之间的差距在增加,它有过拟合的趋势。在所有模型中,MobileNet 的性能最佳。但让我们还是探索一下潜在的模型列表,以确定最佳模型并进行预测。
MobileNetV2
# Loading the MobileNetV2 Model and using transfer learning for our task
headmodel = MobileNetV2(weights = "imagenet", include_top = False,
input_shape = (224, 224, 3))
model = headmodel.output
model = AveragePooling2D(pool_size = (2, 2))(model)
model = Flatten(name = 'flatten')(model)
model = Dense(64, activation = 'relu')(model)
model = Dropout(0.3)(model)
model = Dense(32, activation = 'relu')(model)
model = Dropout(0.1)(model)
model = Dense(1, activation = 'sigmoid')(model)
final_model = Model(inputs = headmodel.input, outputs = model)
for layer in headmodel.layers[: -2]:
layer.trainable = False
opt = Adam(lr = 1e-2)
final_model.compile(loss = "binary_crossentropy", optimizer = opt,
metrics = ["accuracy"])
final_model.summary()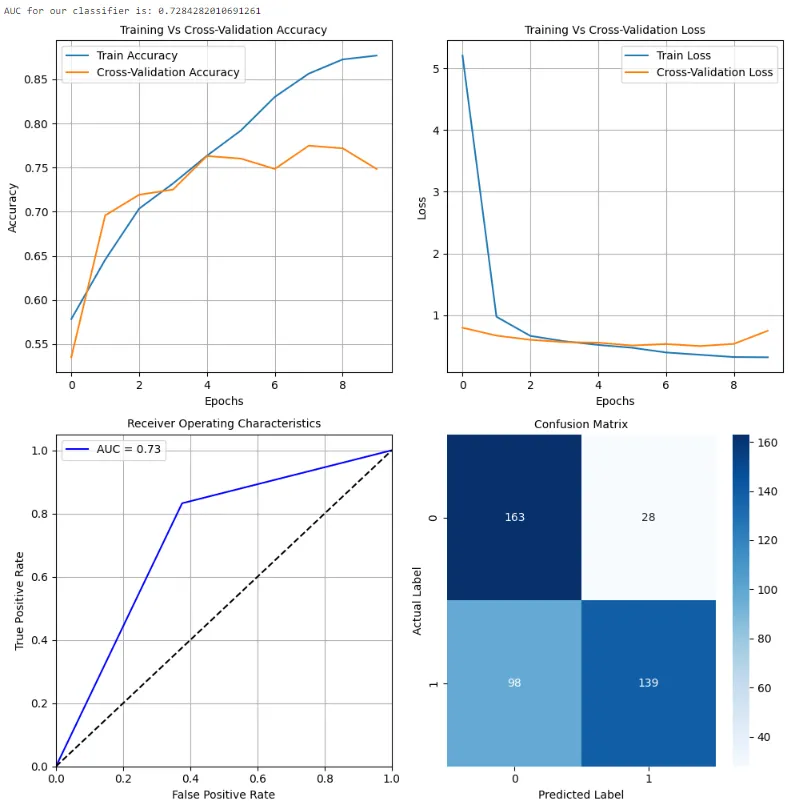
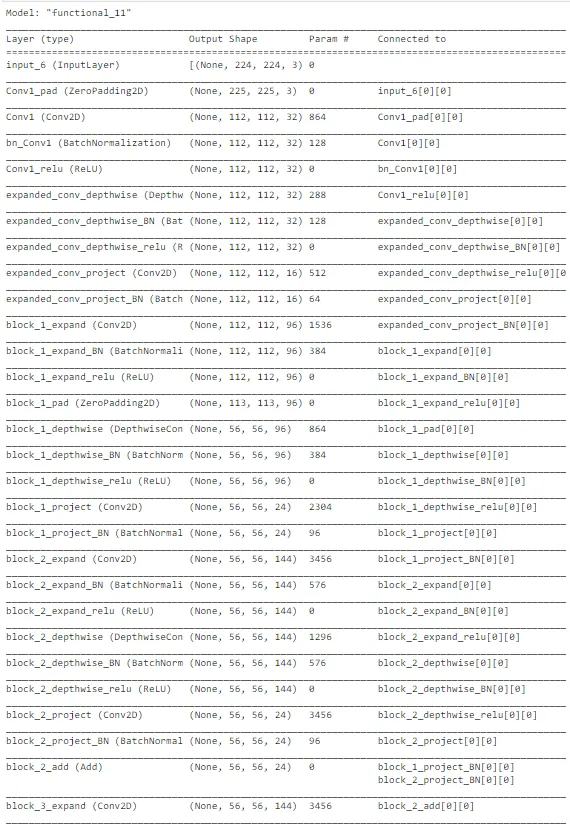
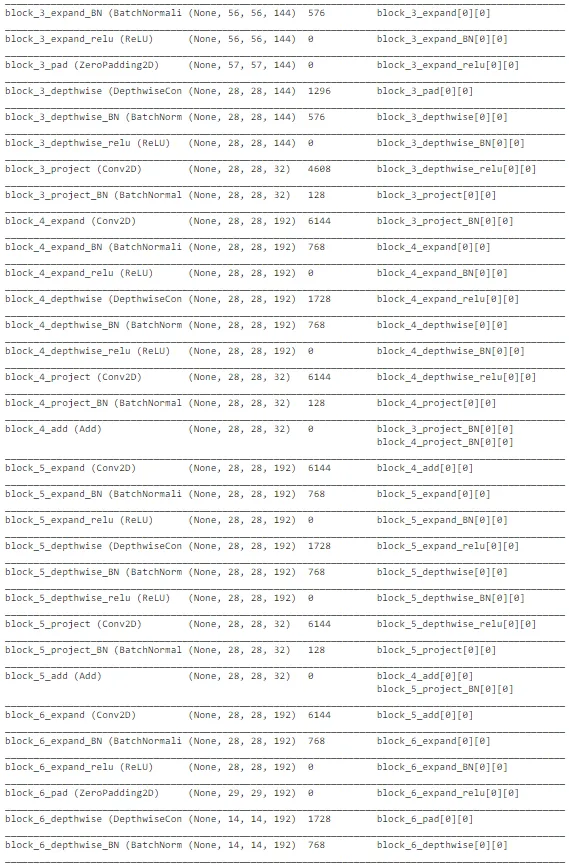
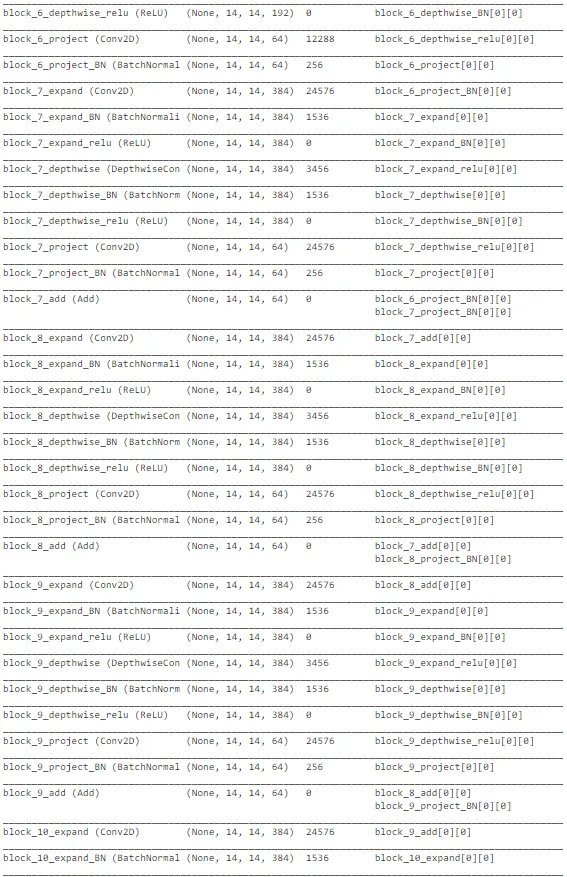
上述图表显示了 MobileNetV2 架构在图像识别任务中的整体性能,用于预测太阳能电池板是否清洁或带有灰尘。这种架构在某种程度上是复杂的。在最后几层,添加了额外的层和单元以优化我们任务的权重。模型的整体性能并不像之前引用的初始 MobileNet 模型那样好。此外,这种架构更为复杂,需要良好的计算能力,以确保低延迟应用。因此,我们可以将 MobileNet 作为实时部署以进行预测的最佳模型之一。
ResNet 50
# Load the ResNet50 model with pre-trained ImageNet weights
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224,224,3))
# Freeze the base model layers so they are not updated during training
for layer in base_model.layers:
layer.trainable = False
# Add a GlobalAveragePooling2D layer and a dense layer to the base model
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
# Add a final dense layer with a specific number of units and activation function
predictions = Dense(1, activation='sigmoid')(x)
# Create the final model by specifying the inputs and outputs
model = Model(inputs=base_model.input, outputs=predictions)
# Compile the model
model.compile(optimizer=Adam(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy'])
# Print the model summary
model.summary()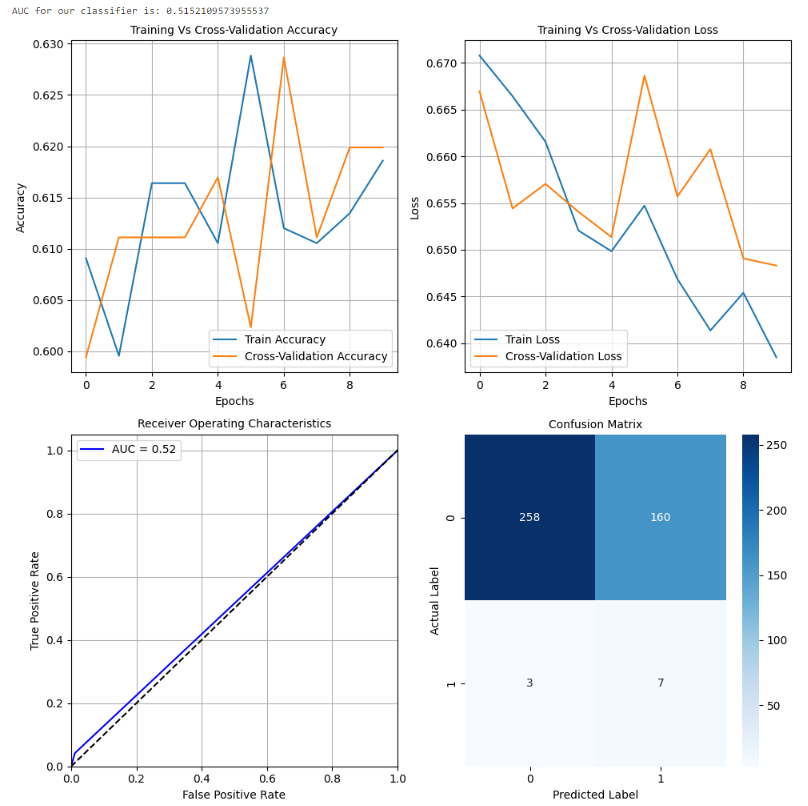
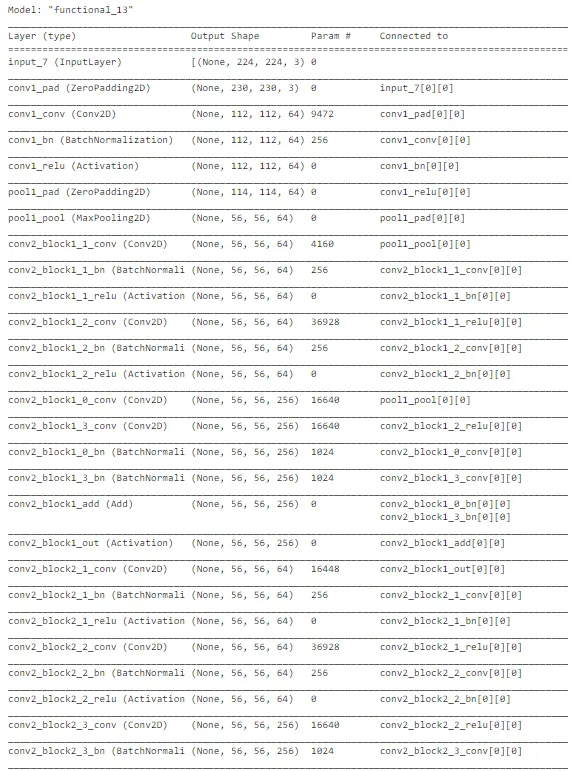
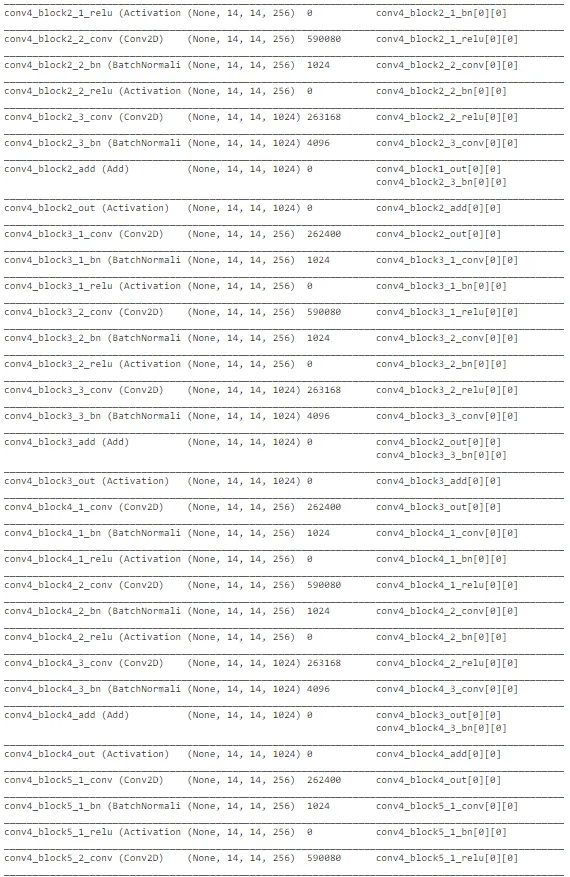
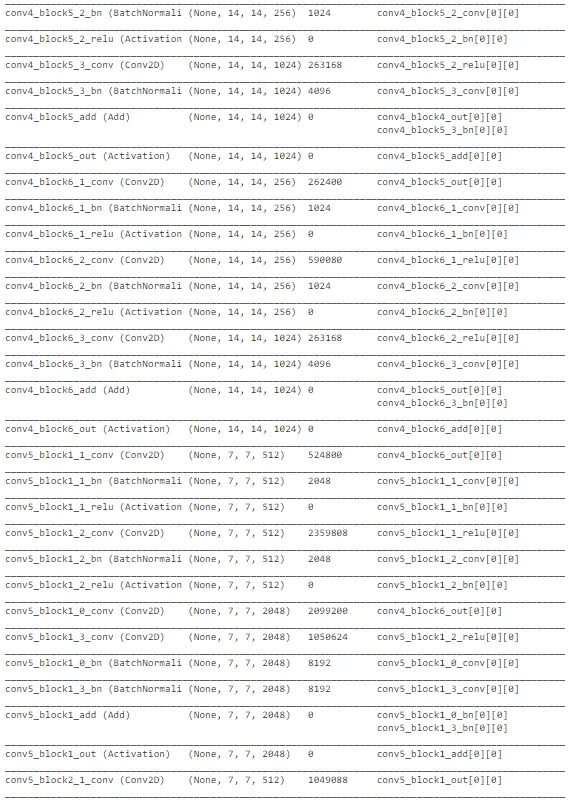
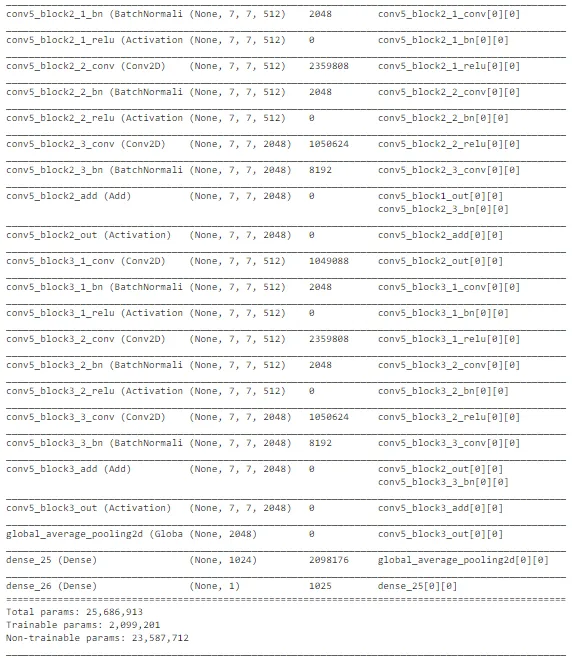
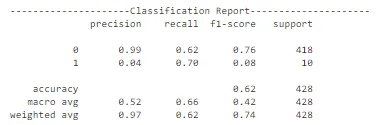
在观察精度曲线和损失曲线等曲线时,ResNet 架构存在很多随机性。总体而言,关于交叉验证数据的准确性存在上升的趋势。然而,该模型未能捕捉到训练数据中的重要差异,以便在测试数据上做出良好的预测。因此,它在测试集上表现较差。可以进行进一步的训练以改善性能。考虑到计算复杂性,我们可以在进行超参数优化后继续使用 MobileNet 架构进行部署。ResNet 对于其他与图像相关的任务可能是不错的选择,但对于这个任务来说,MobileNet 表现最佳。
超参数调整
这一步在计算机视觉中很重要,其中会选择最佳模型,并更改超参数以确定模型性能的变化。它们可以在很大程度上提高模型的性能。现在,让我们专注于从最佳模型中更改一些超参数。学习速率和批量大小是可以提高模型性能的一些超参数。我们将使用这些超参数来提高性能。由于 MobileNet 在测试数据上的性能最佳,我们使用该模型并进行超参数调整以获得最佳的可实现结果。
学习速率
# Loading the MobileNet Model and using transfer learning for our task
headmodel = MobileNet(weights = "imagenet", include_top = False,
input_shape = (224, 224, 3))
model = headmodel.output
model = AveragePooling2D(pool_size = (3, 3))(model)
model = Flatten(name = 'flatten')(model)
model = Dense(64, activation = 'relu')(model)
model = Dropout(0.3)(model)
model = Dense(32, activation = 'relu')(model)
model = Dropout(0.1)(model)
model = Dense(1, activation = 'sigmoid')(model)
final_model = Model(inputs = headmodel.input, outputs = model)
for layer in headmodel.layers[: -2]:
layer.trainable = False
opt = Adam(lr = 0.0011)
final_model.compile(loss = "binary_crossentropy", optimizer = opt,
metrics = ["accuracy"])
fitted_model = final_model.fit(X_train, y_train, epochs = 10,
validation_data = (X_cv, y_cv),
batch_size = BATCH_SIZE)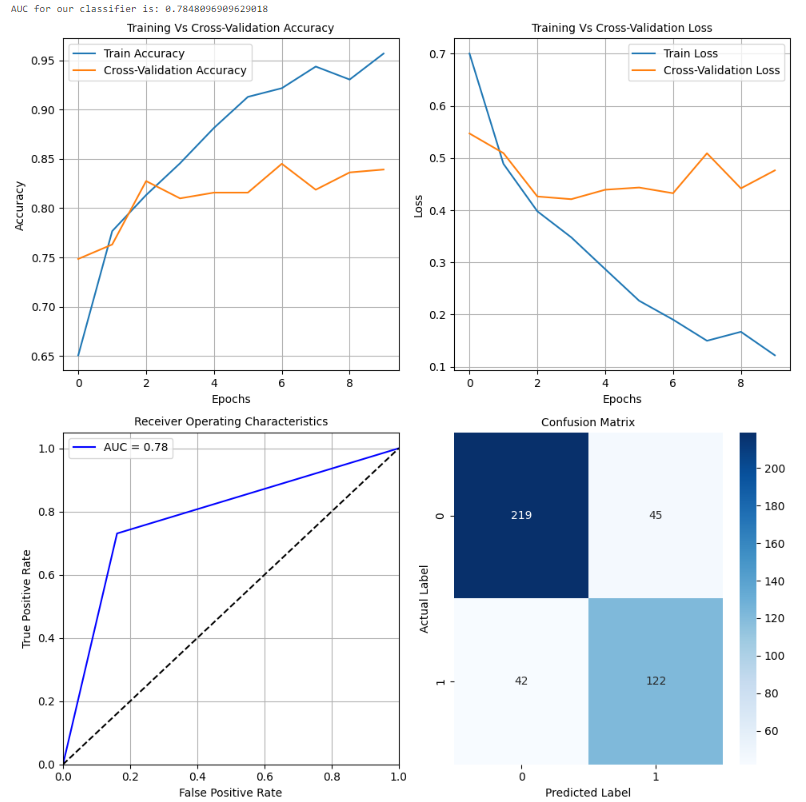



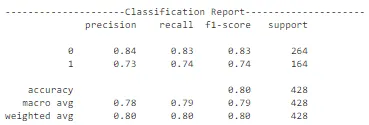
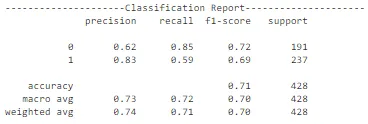
在进行超参数调整并确定最佳学习速率后,我们选择的模型(MobileNet)在测试数据集上表现出显著的1%性能提升。值得注意的是,我们保留了与之前相同的架构,同时专注于确定最佳学习速率以实现最佳结果。
虽然我们不会深入探讨如何进行超参数调整的具体细节,但值得注意的是,有另一个关键的超参数,我们可以探索以最大化在未见数据点上的性能。通过考虑这个额外的超参数,我们可以确保我们的模型在超出训练数据集之外的预测结果方面更加有效。
批量大小
# Loading the MobileNet Model and using transfer learning for our task
headmodel = MobileNet(weights = "imagenet", include_top = False,
input_shape = (224, 224, 3))
model = headmodel.output
model = AveragePooling2D(pool_size = (3, 3))(model)
model = Flatten(name = 'flatten')(model)
model = Dense(64, activation = 'relu')(model)
model = Dropout(0.3)(model)
model = Dense(32, activation = 'relu')(model)
model = Dropout(0.1)(model)
model = Dense(1, activation = 'sigmoid')(model)
final_model = Model(inputs = headmodel.input, outputs = model)
for layer in headmodel.layers[: -2]:
layer.trainable = False
opt = Adam(lr = 0.0011)
final_model.compile(loss = "binary_crossentropy", optimizer = opt,
metrics = ["accuracy"])
fitted_model = final_model.fit(X_train, y_train, epochs = 10,
validation_data = (X_cv, y_cv),
batch_size = BATCH_SIZE + 64)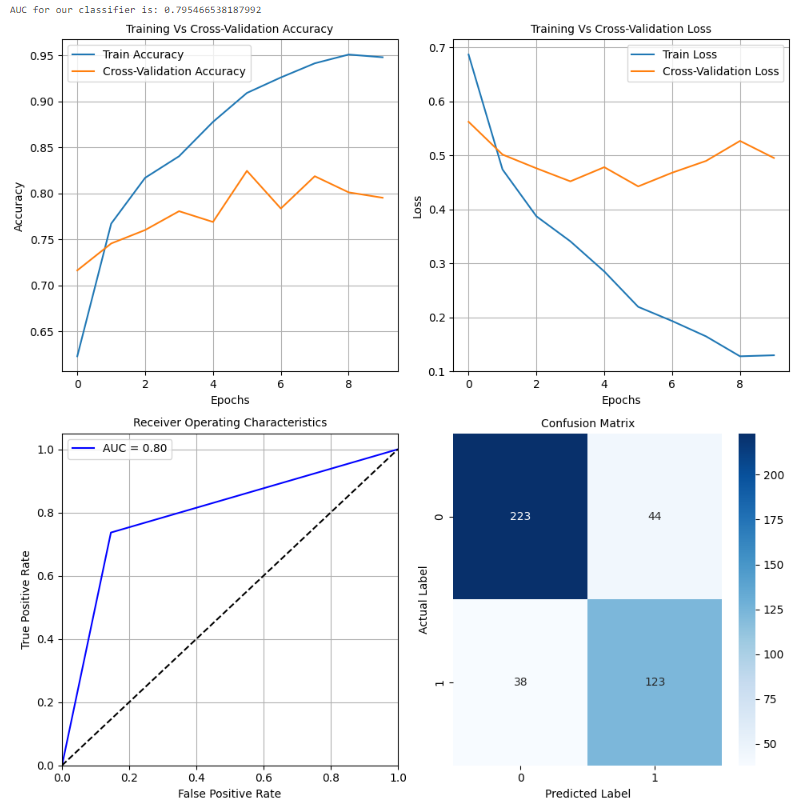



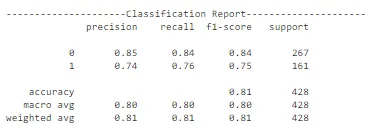
在成功进行超参数调整的过程中,我们使用了最佳学习速率来确定深度学习模型的最佳批量大小。在这种情况下,批量大小为 128 实现了最大的性能提升,在测试数据集上显著提高了 2%。这强调了超参数调整的重要性,这可以是增强深度学习模型准确性和可靠性的强大工具。展望未来,我们的下一步是保存经过超参数调整的最终模型并实时部署它,在摄像头模块或 Web 界面中使用,用户可以上传太阳能电池板的图像。通过利用深度学习的力量,我们的模型可以准确识别面板是否清洁或带有灰尘,为用户提供有价值的见解。这个项目强调了超参数调整在改善各种问题和应用程序性能方面的潜力。
保存最佳模型
# Saving the best hyperparameter tuned model
final_model.save('Models/Mobilenet.h5')现在,我们已经付出了努力来开发、训练和测试一系列复杂的深度学习模型,是时候保存表现最佳的模型以备将来使用了。我们通过以一种可轻松检索的方式存储模型来实现这一点,从而可以在之后方便地检索它,根据开发者的具体需求进行实时或批量推断。
通过保存最佳模型,我们可以确保我们优化模型性能的努力不会白费,并且我们的辛勤工作会以准确、可靠的结果形式得到回报。这代表了深度学习过程中的一个重要步骤,并强调了这些技术在促使各种应用程序和领域的改进方面的力量。
结论
通过阅读本文,你现在应该对机器学习项目涉及的各个阶段有一个全面的了解,包括数据收集、特征工程、模型训练、模型选择、超参数调整和模型部署。这些步骤中的每一步对项目的成功至关重要,需要仔细关注和考虑以实现最佳结果。
然而,一旦模型部署,工作并没有结束。定期监控其性能是重要的,特别是在处理实时数据时。这使你能够及时发现潜在问题,如模型漂移、数据漂移或安全问题,并采取措施加以解决。
总体而言,本文提供了深度学习过程的宝贵概述,突显了在构建准确可靠的模型时涉及的许多挑战和机会。希望你会发现它具有信息性和帮助性,期待在未来继续探索这个令人兴奋且迅速发展的领域。感谢你抽出时间阅读本文。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









