







文章目录

Part_1 爬虫
(1)实现对新闻网页前10页url的爬取,初始的网页url种子为 * ,间隔2秒钟爬取一个页面url。构建pageUrl列表对象对获取到的url进行存储。构建BloomFilter对象对新获取的url是否已存在进行判断,如果不存在则将该url添加pageUrl列表对象中,否则不添加该url。获取完所有的url后,分析url数据存在的问题并设计可行的数据预处理方案。最后,将pageUrl列表对象中存储的url数据保存到文本文件中,每行保存一个url。
Part_1_1 requests 库 向服务器请求数据
主要函数
requests.get(url , verify = False)
1. SSL 安全认证
verify = False //跳过SSL安全认证
对于有的网站,需要SSL证书验证,如:12306等网站
若没有设置SSL , 会报错
但是跳过SSL验证会产生报错信息
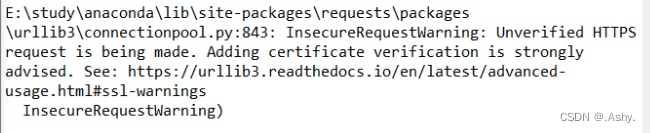
所以加上
requests.packages.urllib3.disable_warnings()
关闭警告
2. 抛出异常 和 编码
r.raise_for_status()
根据返回值确定请求状态是否正常 , 可以放在 try - except 语句里捕捉错误状态并修正
(写在这里好像没起到什么作用 , 但还是写上)
r.encoding = r.apparent_encoding
确定编码
3.请求数据函数封装
# 函数接口 url链接
# 函数名称 请求数据函数
def get_url(x):
requests.packages.urllib3.disable_warnings()
r = requests.get(x , verify = False) # 你需要的网址
#verify = False 忽略https安全证书的验证
r.raise_for_status() # 异常触发语句
r.encoding = r.apparent_encoding # 确定编码语句
return r
Part_1_2 布隆过滤器 BloomFilter
布隆过滤器就类似于 C++ 里的 bitset , 处理的最小单位都是 bit 而非 byte , 所以 快!而且省空间。
作用的话就类似于 C++ 里的map , 原理是多哈希映射;
但这里我做的网页循环请求是线性的请求 , 必然不会出现冲突 ,所以这个过滤器就有点鸡肋了 , 但是还是用上吧;
from pybloom_live import ScalableBloomFilter
bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001)
if seed in bloom:
continue
Part_1_3 循环请求
原理就是根据页面中的 “上页” “下页” 进行的跳转 , 原理我就不说了 , 只要用正则表达式匹配把网页的下一页信息匹配下来就行了
循环请求函数封装
# 函数接口 seed 初始url cnt 爬取个数
# 函数名称 循环请求函数
def curcal_get_url(seed , cnt):
while(cnt):
if seed in bloom:
continue//如果这个网页出现过 , 就不处理
bloom.add(seed)//没出现过就存到过滤器里
pageurl.append(seed)//把url放到列表
r = get_url(seed)//请求url
pattern = "<span class=\"p_next p_fun\"><a href=\"(.*)\">下页</a></span>"
newsInfo = re.findall(pattern, r.text)//用正则表达式提取下页信息
seed = "*" + newsInfo[0]//更新url(这里省略了关键信息 , 大家自己补全)
cnt = cnt - 1//循环体
Part_2 BeautifulSoup 数据解析
2)读取url列表对象或文件中的url,对于请求到的每个新闻网页数据,分别使用正则表达式、BeautifulSoup(或Selenium)进行网页数据的解析,提取每个新闻的标题、对应的正文页面URL和发布日期;要求爬取每个网页的时间间隔为2秒。
Part_2_1 Beautiful 函数
这一步是提取内容

Part_2_2 find 和 find_all 函数
这里需要根据我们想要提取内容在网页中的标签合理的使用这两个方法
 以我们要找的三个内容为例 , 首先大类标签是
以我们要找的三个内容为例 , 首先大类标签是
<ul class="dj_lb1">
对应的我们把内容都提取出来
newsLevel1 = soup.find_all('ul', class_='dj_lb1')
在每个大标签里 , 我们要找的小标签一定是
<li id="line_u12_0" style="display:none;">
所以下一重循环就是
newsLevel2 = news.find_all('li', id = re.compile("line_u12_\d"))
最后到了内容子标签 , 提取内容
<a href="../../info/1047/14866.htm" target="_blank" title="学校领导到枣庄市山亭区调研第一书记工作">学校领导到枣庄市山亭区调研第一书记工作</a>
放到三个列表里存起来
title_all.append(news.a['title'])
herf_all.append(news.a['href'])
time_all.append(news.span.string)

Part_2_2 数据解析函数封装
# 函数接口 url链接
# 函数名称 数据解析函数
def get_info(x):
r = get_url(x)
# MongoDB 解析数据(相当于re库的功能)
soup = BS(r.text , "html.parser")
newsLevel1 = soup.find_all('ul', class_='dj_lb1')
for news in newsLevel1:
newsLevel2 = news.find_all('li', id = re.compile("line_u12_\d"))
for news in newsLevel2:
title_all.append(news.a['title'])
herf_all.append(news.a['href'])
time_all.append(news.span.string)
Part_3 MongoDb 数据库
(3)对于从网页中解析到的新闻数据,构建csv文件或MongoDB数据库保存每个新闻的标题、对应的正文页面URL,以及每个新闻的发布日期。
Part_3_1 数据下载
- 下载数据库
数据库下载
如果win10 不能下载 msi 文件
那么就
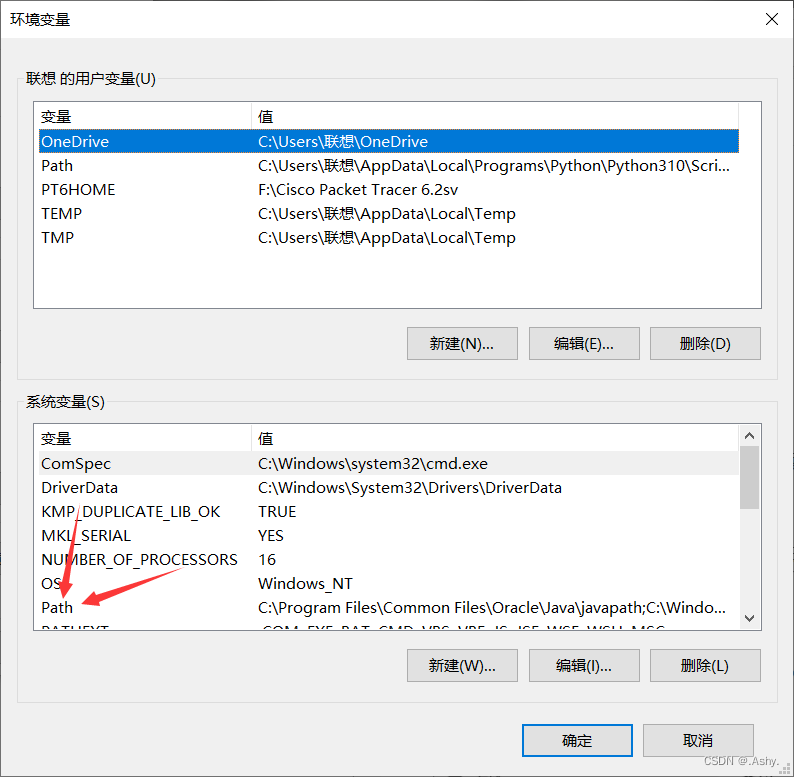
win10下载msi文件权限不足解决 - 配置路径
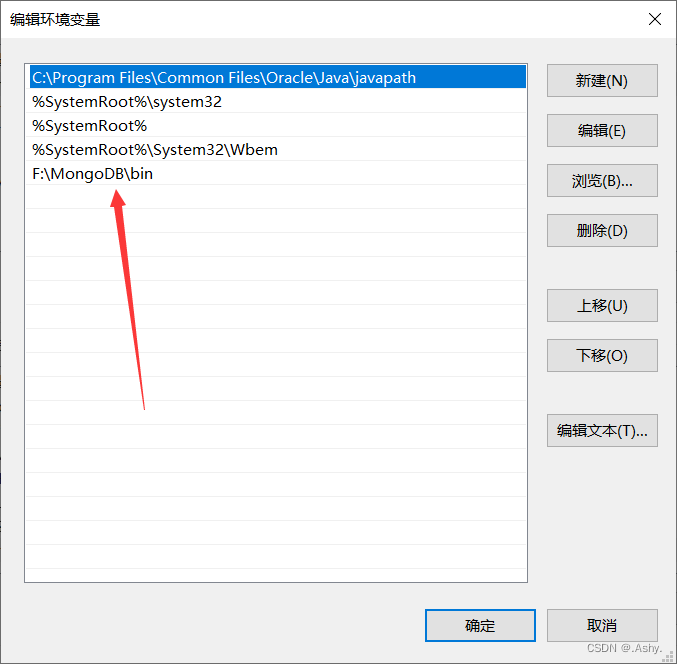
把下载好的文件的 bin 文件夹的路径配置到系统变量的 path 中 , 一定注意 , 是放到系统的path环境变量中 ,
右键 此电脑 -> 属性 -> 高级系统设置 -> 环境变量 -> 系统变量 path
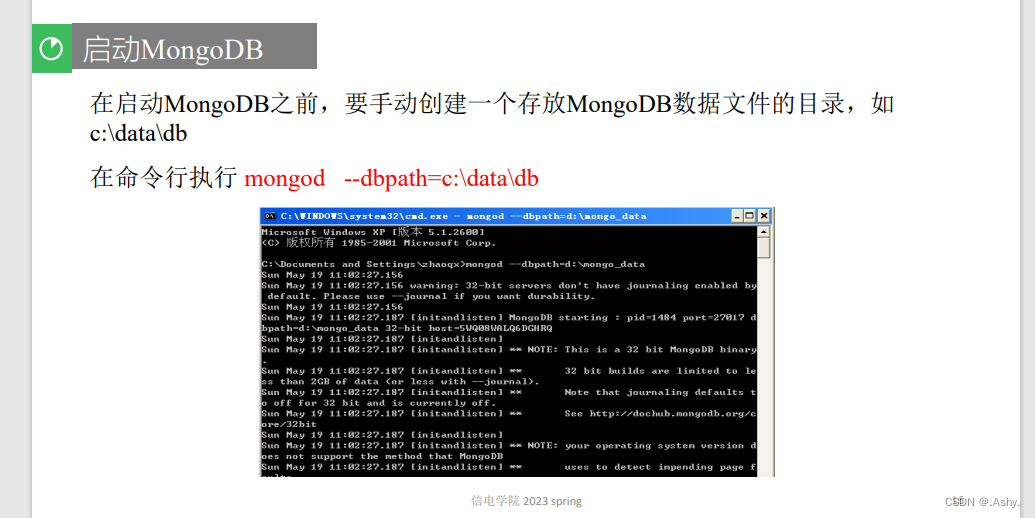
启动 mangodb
Part_3_2 anaconda 下载 momgodb
打开 anaconda prompt , 输入
pip install mongo
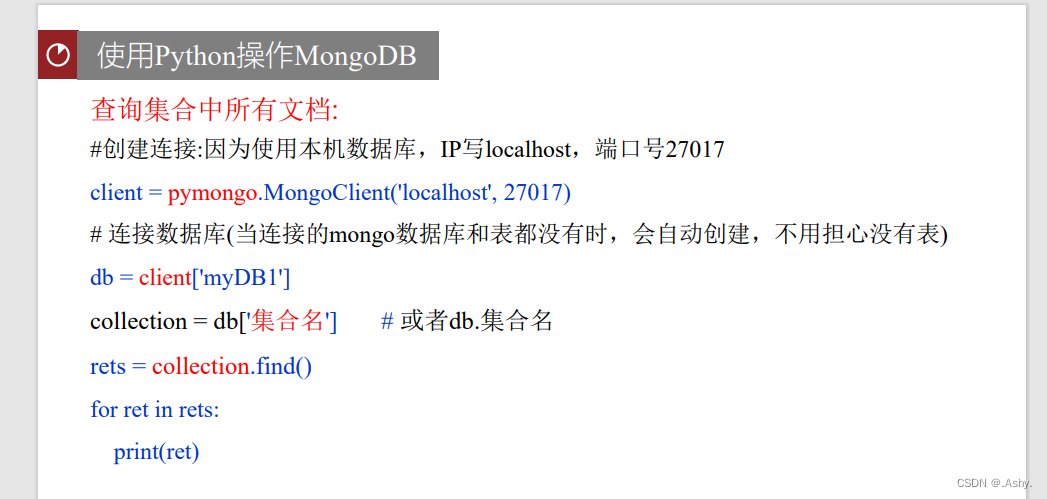
Part_3_2 使用

Part_3_2 存储和查看函数封装
# 函数接口 无
# 函数名称 存储和查看函数
def store_and_get():
client = pymongo.MongoClient('localhost', 27017)
db = client['collegeNewsDB']
collection = db['collegeNews']
length = len(title_all)
for i in range(0 , length):
collection.insert_one({"url" : herf_all[i], "title" : title_all[i] , "time" : time_all[i]})
newsData = collection.find()
for news in newsData:
print(news)
最后不要忘了引入库
from pybloom_live import ScalableBloomFilter
import requests , re
from bs4 import BeautifulSoup as BS
import pymongo
那么就到这里啦
# -*- coding: utf-8 -*-
"""
Published By Li
"""
from pybloom_live import ScalableBloomFilter
import requests , re
from bs4 import BeautifulSoup as BS
import pymongo
bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001)
pageurl = []
title_all = []
herf_all = []
time_all = []
# header={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"}
def get_url(x):
# 请求数据
requests.packages.urllib3.disable_warnings()
r = requests.get(x , verify = False , timeout = 2) # 你需要的网址
#verify = False 忽略https安全证书的验证
r.raise_for_status() # 异常触发语句
r.encoding = r.apparent_encoding # 确定编码语句
return r
def get_info(x):
r = get_url(x)
# MongoDB 解析数据(相当于re库的功能)
soup = BS(r.text , "html.parser")
newsLevel1 = soup.find_all('ul', class_='dj_lb1')
for news in newsLevel1:
newsLevel2 = news.find_all('li', id = re.compile("line_u12_\d"))
for news in newsLevel2:
title_all.append(news.a['title'])
herf_all.append(news.a['href'])
time_all.append(news.span.string)
def curcal_get_url(seed , cnt):
while(cnt):
if seed in bloom:
continue
bloom.add(seed)
pageurl.append(seed)
r = get_url(seed)
pattern = "<span class=\"p_next p_fun\"><a href=\"(.*)\">下页</a></span>"
newsInfo = re.findall(pattern, r.text)
seed = "https://www.ytu.edu.cn/ydxw/" + newsInfo[0]
cnt = cnt - 1
def store_and_get():
client = pymongo.MongoClient('localhost', 27017)
db = client['collegeNewsDB']
collection = db['collegeNews']
length = len(title_all)
for i in range(0 , length):
collection.insert_one({"url" : herf_all[i], "title" : title_all[i] , "time" : time_all[i]})
newsData = collection.find()
for news in newsData:
print(news)
if __name__ == "__main__":
seed = "https://www.ytu.edu.cn/ydxw/xxyw.htm"
cnt = 5
curcal_get_url(seed , cnt)
for i in pageurl:
url = i
get_info(url)
store_and_get()

















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











