







一、深度学习
1.基本定义
在现在的人工智能领域,数据挖掘类的算法大致可以分为两类,第一种是机器学习算法,第二种是深度学习算法。深度学习算法,可以叫做深度神经网络算法。神经网络的结构可以如下图所示:
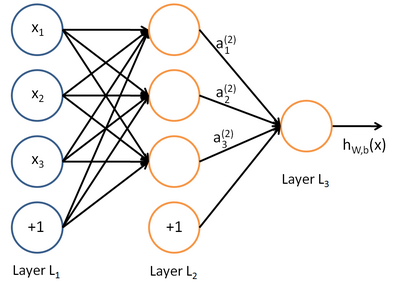
上图中每个圆圈都是一个神经元,每条线叫神经元的链接。
上图中神经元可以分为三层,层与层直接有神经元连接,层内无神经元连接。最左边的层叫输入层。最右边的层叫输出层。输入层和输出层直接的叫隐藏层。
深度神经网络:隐藏层大于2的神经网络。
深度网络和宽度网络的区别:
(1)一个仅有一个隐藏层的神经网络就能拟合任何一个函数,但是它需要很多很多的神经元。
(2)而深层网络用少得多的神经元就能拟合同样的函数。也就是为了拟合一个函数,要么使用一个浅而宽的网络,要么使用一个深而窄的网络。而后者往往更节约资源。
二、感知器(也叫感知机)
1.感知器的基本定义
感知器: 也叫感知机,也叫神经元,神经网络的基本组成单元。
感知器的定义:
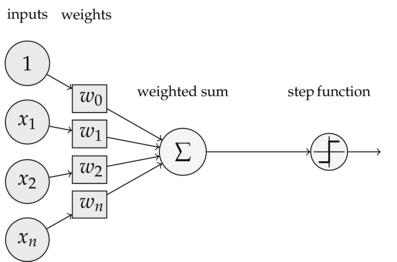
可以看到,一个感知器有如下组成部分:
- 输入权值: 一个感知器可以接收多个输入 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn),每个输入上有一个权值,此外还有一个偏置项 b b b,就是上图中的 w 0 w_0 w0。
- 激活函数: 感知器的激活函数可以有很多选择,比如我们可以选择下面这个阶跃函数来作为激活函数
f ( x ) = { 1 z>0 0 otherwise f(x)= \begin{cases} 1& \text{z>0}\\ 0& \text{otherwise} \end{cases} f(x)={10z>0otherwise - 输出: 感知器的输出由下面的公式来计算
y = f ( w ∗ x + b ) y =f(w*x +b) y=f(w∗x+b)
2.感知器的训练
前面的权重项和偏置项的值是如何获得的呢?这就要用到感知器训练算法:将权重项和偏置项初始化为0,然后,利用下面的感知器规则迭代的修改
w
i
w_i
wi和
b
b
b,直到训练完成。
w
i
=
w
i
+
∇
w
i
w_i = w_i + \nabla w_i
wi=wi+∇wi (公式1)
b
=
b
+
∇
b
b = b+\nabla b
b=b+∇b (公式2)
其中:
∇
w
i
=
α
(
t
−
y
)
x
i
\nabla w_i = \alpha(t-y)x_i
∇wi=α(t−y)xi
∇
b
=
α
(
t
−
y
)
\nabla b= \alpha(t-y)
∇b=α(t−y)
w
i
w_i
wi是输入
x
i
x_i
xi对应的权重项。
b
b
b是偏置项。
t
t
t是训练样本的实际值,也就是label。
y
y
y是感知器的输出值。
α
\alpha
α是学习率的常数。















 2329
2329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









