






决策树原理在上一篇博客中决策树算法原理以及ID3、C4.5、CART算法
目录
下面是将代码的实现:
代码实现
声明
本人才疏学浅,将核心的用来构建决策树的功能函数给写好了,倒在了处理数据的路上,本人忙活了三四个小时,处理数据犯了老难,不是不能处理,是太麻烦太累,感觉还要肝5-6小时,于是我放弃了,大家也就通过我的代码加深对决策树算法原理的印象就好
所以,若有人根据我写的功能函数,将处理数据完整过程写了出来,请联系我,我不胜感激!
构造数据集
#决策树用ID3算法实现
import math
#构造数据集, 该数据集是构造的天气适不适合打球的数据集
datas=[
['样本id','天气','温度','湿度','风力','类别'],
['X1','晴','高','大','无' ,'否'],
['X2','晴','高','大','无','否'],
['X3','云','高','大','无','是'],
['X4','雨','中','大','无','是'],
['X5','雨','低','小','无','是'],
['X6','雨','低','小','有','否'],
['X7','云','低','小','有','是'],
['X8','晴','中','大','无','否'],
['X9','晴','低','小','无','是'],
['X10','雨','中','小','无','是'],
['X11','晴','中','小','有','是'],
['X12','云','中','大','有','是'],
['X13','云','高','小','无','是'],
['X14','雨','中','大','有','否']]数据清洗
#数据清洗
datas_=[]
for x in datas:
x=x[1:]
datas_.append(x)
#print(datas_)#去掉样本id这个特征
features=datas_[0]
datas_=datas_[1:]# 去掉样本的第一行
print(datas_)构造功能函数
def P(x,n):#概率函数,x应当为一个二维数组,也就是样本集,n为某特征对应的值列表,
feanum=len(x)
print('样本的个数:',feanum)
#print(x)
m=len(n)
zerolist=[]
for x in range(m):
zerolist.append(0)
for y1 in x:
for y2 in range(m):
if y1[y2] in m:
zerolist[y2]=zerolist[y2]+1
print(zerolist)
for x in range(m):
n[x]=zerolist[x]/feanum
print(n)
return n
#返回一个list,list对应的值就是n对应的某特征值或者类别值就是在x子集中的概率
def splf(x,y):#清除特征的函数,x为样本集,y为要清除的特征在features所对应的下标
for n in x:
a=n[y]
n.remove(a)
print(x)
return x
#返回一个二维列表,就是清除某特征后的样本集
def spl(x,y):#拆分数据集的函数 x 为样本集也就是二位列表,y为作为我们拆分依据的x某特征的值的字典,
fea=list(y.keys())
for y1 in x:
for y2 in y1:
if y2 in fea:
y[y2].append(y1)
print(y)
return y
#返回一个字典,字典的键值就是某特征的各个值,对应的值就是拆分后的二位列表
def Com(x):# 信息熵函数,x应当为一个一维概率列表,对应的是某类别值或特征值在对应样本集的占比或者说概率
num=len(x)
for y in range(num):
x[y]=x[y]*math.log(x[y],2)
print(x)
sum=0
for y in x:
sum=sum+y
if sum<0:
return -sum
else:
return sum
#返回一个值,这个值就是该类别值或者特征值的信息熵
def Cen(x,y):# 条件熵函数,x应当是一个一维概率列表,里面是特征各个值对应的子样本集所占的比重,或者说概率,y应当是一个二维的概率列表每一行都对应着一个子样本,里面是该子样本里某类别的比重或者说概率
num1=len(x)
for n in range(num1):
y[n]=Com(y[n])
x[n]=x[n]*y[n]
print(x)
sum=0
for z in x:
sum=sum+z
return sum#返回的是一个列表,对应特征的条件熵
def gc(x,y):# 信息增益函数,x,y应当是两个值
if x-y>=0:
return x-y
else:
return -(x-y)数据处理(我倒在了这里)
#建立决策树之前的分析
def main():
print(features)#['天气', '温度', '湿度', '风力', '类别']
list1=['是','否']#类别
lst2=['晴','云','雨']#天气
list3=['高','低','中']#温度
list4=['大','小']#湿度
list5=['无','有']#风力
#定义操作函数:
f=features
def con1(x,y):#信息熵
a=P(x,y)
print(a)
b=Com(a)
return b
def con2(x,y):#条件熵
a=P(x,y)
#....... 太累了,我放弃了,其实后面就是自行的数据处理然后调用前面的功能函数后面根据信息增益找到根节点
main()
#.......................................
#.......................................
#......................................
#就这样处理数据调用函数得到结果
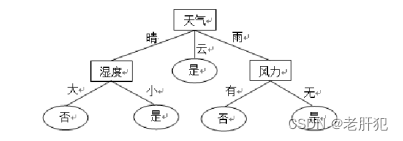
建立模型
def tree(x):
if x[0]=='晴' :
if x[2]=='大':
print('否')
elif x[2]=='小':
print('是')
elif x[0]=='云' :
print('是')
elif x[0] == '雨':
if x[3]=='有':
print('否')
elif x[3] == '无':
print('是')该模型只适用于上面我们的数据集,主要是体现一个思想
测试
test=['晴','高','大','无' ]
#得到一个模型,这个模型只是针对该数据集:
def tree(x):
if x[0]=='晴' :
if x[2]=='大':
print('否')
elif x[2]=='小':
print('是')
elif x[0]=='云' :
print('是')
elif x[0] == '雨':
if x[3]=='有':
print('否')
elif x[3] == '无':
print('是')
tree(test)

道歉
我知道对于代码实现来说,应当是完整的,本代码的数据处理部分恰好能体现决策树建立的一步步的思路,我提一下我们一开始比较信息增益后选择的根节点是天起,然后根据天气的值将数据集氛围多个子数据集,然后再次根据信息增益......
本人才疏学浅,未能完整代码奉上,我很抱歉!















 5624
5624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









