






笔记连贯,建议全文阅读!
一、RNN
首先,对于处理序列类型的问题,研究者们基于深度学习和神经网络的知识提出了RNN(循环神经网络模型):

其中,x表示输入比如一句话中每个单词的词向量,最早的词向量我们使用one-hot向量表示,w是不同类型的权重参数,y则是对于不同任务我们需要的输出,比如我们需要通过前一个词预测后一个词,我们输入前一个词的词向量x,我们就输出对应后一个词的所有词的概率向量y。从模型我们可以看出,每个后续输出y,都有前面一个词的信息因子a,这就让我们不仅能从当前输入来预测输出,同时还能参考前面的信息。然而,不难发现,对于一句话,只能收集到前面的信息,而不考虑后面的信息是考虑不周全的,比如下面这句话:

我们做命名实体识别任务,如果只考虑到了前面,没看到后面on Sale,很有可能就把teddy bears判断为人名了。
1、Bi-RNN
基于上述问题,我们就提出了双向RNN(Bi-RNN):

这样做,就使得我们在某一时间t输入x时,输出y同时考虑了前后的序列信息,使得我们的预测更加准确。与此同时,我们再来关注,RNN每个细胞单元的内部构造:

把这个细胞结构,放入到我们的网络模型中,通过不断地实验,我们发现,虽然每次输出能获取前面输入的信息,可是随着句子长度的增加,越靠前输入的信息,到后面所能提供的影响就越小,甚至消失。
2、LSTM
基于此类问题,聪明的学者们,又对初始的RNN细胞结构进行了改进,变成了下面这个样子:

这个也就是我们熟知的LSTM。这套结构看起来很复杂(确实也是),但实际上完成的工作也就是,选择性的丢弃一些之前不要的信息,同时选择是否更新新的信息到记忆细胞c中,这样做就可以使得很前面的信息能够长时间的被保留下来而不被丢弃。结合前面提到的双向RNN结构,把两者的优势相互结合,我们就得到了Bi-LSTM,如果你从前面一直看到这,你就可以感受到Bi-LSTM的强大,既可以学习到前后文的信息,同时又可以保留较长时间段的数据信息,这也使得Bi-LSTM成为了较长一段时间内,学者们常用的一个网络模型。
对于接下来解决序列问题发展的概述,需要介绍几个关键性的技术来过渡一下,首先需要介绍的就是词嵌入。
二、word embedding
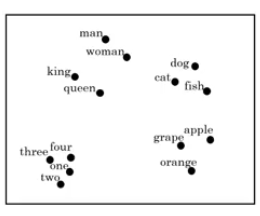
词嵌入从本质上来说就是词向量,与之前one-hot的意义相同,只不过表示的方法不同。词嵌入是把每一个词映射到了高维空间中,意思每一个词都是空间中的一个向量,这个向量有很多个特征,这些特征就用来表示这个词,不同的词对应的特征值也就不相同,假设用300个特征来表征一个词,那这个词就是一个300维的向量。这样表示每个词的好处就是,在空间中比如apple和orange,他们的词向量挨得就会比较近,apple和cat他们的距离就会比较远,这样就方便下游任务做进一步的推理,可以说得到了一段文本的词向量,就基本得到了这段文本的意思。
而获得词嵌入的方法,就比如大家应该都听过的word2vec,其中一种方法为CBOW,通过框定一个范围内的几个词,然后通过前后词来预测中间那个词是什么。当然这个任务不是真正为了预测中间那个词是什么,而是通过这种方法来训练出我们需要的每个单词的词嵌入,也就是一个嵌入矩阵。
三、attention

说完了词嵌入,接下来说的就是大名鼎鼎的注意力机制。首先,我们先要知道什么是encoder-decoder模型,通俗的来说就是,比如我们现在要完成文本翻译任务,输入一句英文通过encoder就变成了这句话的词嵌入,也就是一串数字,之后又通过decoder输出我们需要的中文翻译。而我们的注意力机制就是在decoder翻译成中文的时候,比如we are young中第一个词翻译为“我们”时,我们更多关注的信息是we are young中的“we”,而不是其他词;注意力机制计算所有词对某个特点定时刻输出的注意力权重,让翻译时更加关注注意力权重大的那个词。
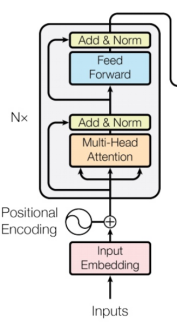
四、Transformer
看完上面这些内容,我们接下来讨论的就是Transformer模型。

Transformer模型对于之前的模型来说是一个很大的改变,他完全替代了RNN的模型结构,并且是并行处理序列问题。
介绍这个模型之前,同样我先给定一个任务,比如翻译任务。首先我们输入要翻译的句子的词嵌入提供给encoder,encoder提取出句子的整体语义编码信息;然后我们把前面t-1个预测好的词嵌入输入给decoder,decoder提取他们的语义后再结合encoder提取的整句话的语义,再进行一个综合提取后输出预测的下一个词的翻译结果。需要补充的就是,此处采用的多头自注意力机制,实际就是用于计算句子本身每个词与其他词之间的相关性,按照我的理解也就是整句话的语义信息。
五、BERT
在Transformer的基础上,google研究团队又提出了预训练模型的集大成之作BERT,BERT其实是一种用于迁移学习的工具,BERT通过开源自监督预训练好的大规模的词嵌入矩阵,很大程度上提高了下游任务的工作水平。
BERT模型实际上就是Transformer的encoder部分,
输入为:
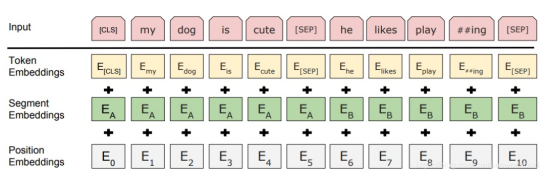
BERT通过两种方法来训练词嵌入,第一种方法叫做MLM,俗称为完形填空。先随机把输入句子中一些词替换为mask,然后用BERT来预测mask的词原先是什么;第二种方法是预测下一句,我们输入两句话,第二句话可能是第一句话的下一句,也可能不是,我们训练BERT来判断下一句话是否属于上一句话。通过上面两种方法,再加上超大规模的语料训练集,我们就得到了一个鲁棒性非常强的相当于一个字典般的词嵌入矩阵。用它来从事后面的下游任务可想而知就会得到很好的效果。
以上就是本人的理解,希望可以帮到大家,同时也欢迎指正!















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









