







前言
高通AIMET [1] 是一个开源程式库,用于优化已训练的神经网络模型。开发者可以将 AIMET 的压缩和量化算法整合到 PyTorch 和 TensorFlow 的模型构建流程中,用于自动化后训练优化及模型微调,从而省去手动优化神经网络的繁琐过程。而AIMET 的量化模拟 (Quantization Simulation) 提供了模拟量化硬体效果的功能,让使用者可以在模拟过程中应用后训练或微调技术,以恢复模型的准确度,最终将模型部署在目标设备上。本篇将介绍量化模拟的基本原理与流程,了解其如何找到模型的最佳量化缩放与偏移参数,以观察应用这些技术后量化准确度的变化,并以VGG11 [2] 模型为例示范。
QuantSim 工作流程
QuantSim为AIMET之API之一,当 QuantSim 被创建后,可以使用其现有的管道在 QuantSim 物件中微调模型,以下是模拟目标量化精度的工作流程:
- 从预训练的浮点 FP32 模型开始,并通过在模型图中插入量化模拟操作来创建模拟模型。
- 找到插入的量化模拟操作的最佳量化参数,如缩放和偏移值,且需要使用者提供回调方法,会将一些具代表性的数据样本传递给模型,以找到最佳量化参数。
- 返回一个量化模拟模型,该模型可以在评估管道中替代原始模型使用。
- 使用者可以调用 .export() 函式保存移除量化节点的模型副本,并生成一个包含每个激活函式和权重张量量化缩放和偏移参数的编码文件。
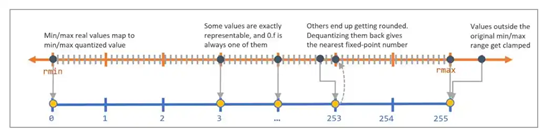
图一、反量化过程中这些四舍五入的值会回到最接近的定点数,从而产生量化噪声。
QuantSim最佳量化参数原理
- 导入量化噪声: 由于反量化后的值可能与量化前的值不完全相同,这两者之间的差异即为量化噪声,为了模拟量化噪声,QuantSim 在模型图中添加了量化操作节点。生成的模型图可以直接用于使用者的评估或训练流程中,图一显示如何将实数值(如 rmin 和 rmax)对应到量化值的范围(如 0 到 255)。
- 确认量化参数: 使用 QuantSim时会分析并确定每个量化操作的最佳量化编码(即缩放和偏移参数)。会将一些校准样本通过模型,为每一层的输出张量创建直方图来得知浮点数的分布,如图二所示,而每层的编码包括四个数值:Min (qmin)、Max (qmax)、Delta、Offset。
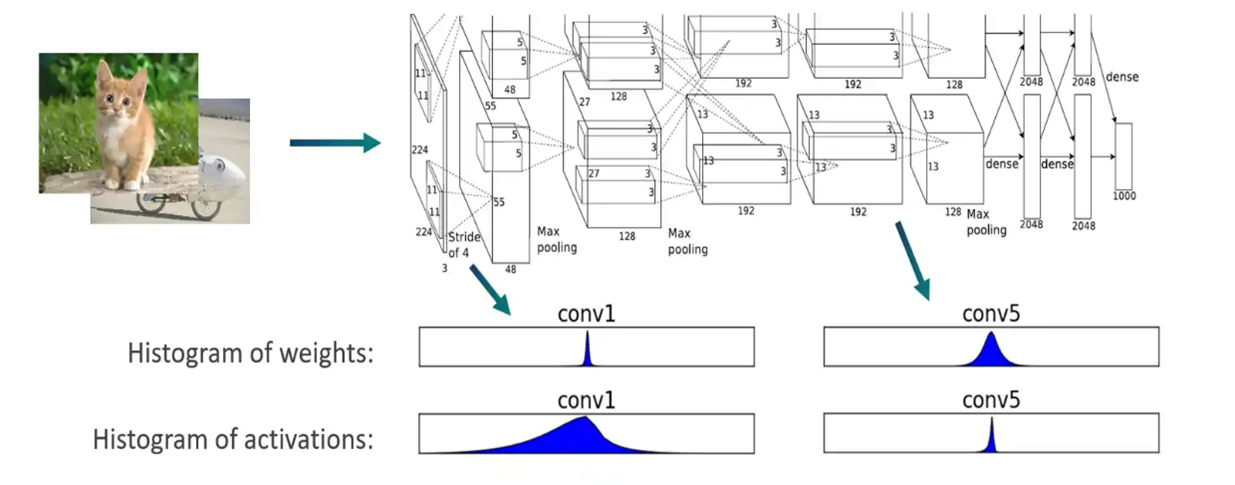
图二、透过输出张量创建直方图来得知浮点数的分布。
QuantSim以VGG11为例之程式实现
- VGG11介绍: VGGNet 在 2014 年由牛津大学 Visual Geometry Group 提出,特点是重复采用同一组基础模组,并改用小卷积核替代中大型卷积核,其架构由 n 个 VGG Block 与3个全连接层所组成,如图三所示。
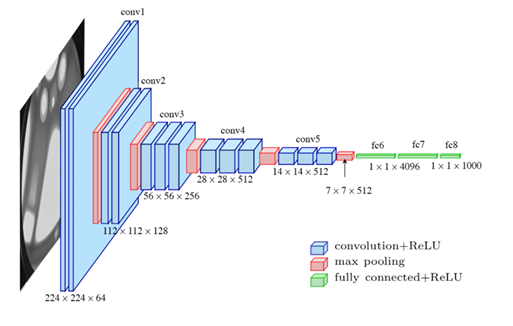
图三、vgg16 论文上的架构图。
如图四所示,我们使用PyTorch训练和评估VGG11模型以进行CIFAR-10图像分类,首先定义了数据预处理操作和载入CIFAR-10数据集,然后建立了一个适合CIFAR-10的VGG11模型,并使用非预训练模型进行训练。
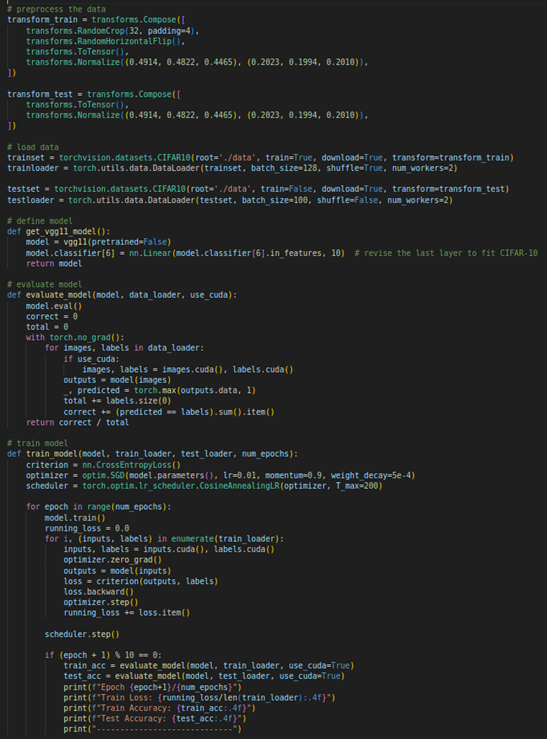
图四、建立VGG11模型与载入CIFAR-10数据集。
- QuantSim 程式解释: 如图五所示,首先,建立一个大小为(1, 3, 32, 32)的随机张量作为dummy_input,用于模拟输入资料。然后,使用QuantizationSimModel [3] 建立一个量化模拟模型,设定量化方案为'tf'(TensorFlow风格),且预设输出和参数均为8bits。接着,定义一个forward_pass_callback函式,用于在计算编码时评估模型,而 compute_encoding函式则是用来确定最佳的量化参数,随后,使用测试资料集评估量化后的模型准确率。

图五、QuantizationSimModel之API使用方式。
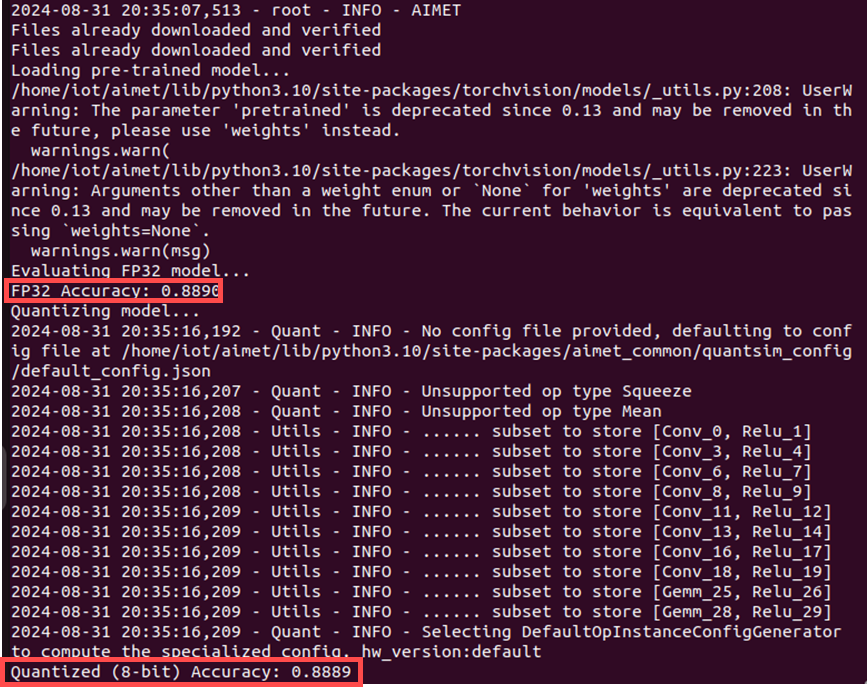
图六、运行程式后之输出,可以看到其量化前后之准确率相当。
如图六所示,可以看到在量化前的准确率为88.90%,而量化后为88.89%,表示量化过程非常成功,几乎没有损失准确率。最后,若想保存量化后的模型,可以使用export函式,其除了移除用于模拟量化效果的特殊量化节点,也能将模型转换为可以直接在标准 PyTorch 环境中运行的格式。
小结
透过以上讲解与搭配程式码进行说明,相信各位对AIMET之量化模拟工具能有更深刻的理解,期待下一篇博文吧!
Q&A
问题一:什么是模型量化,为什么在深度学习之部署中如此重要?
模型量化是将深度学习模型的权重和活化值从32位元浮点数转换为低精度之表示 (如8位元整数) 的过程,其能够降低运算复杂度、减少记忆体占用,并提高推理速度,尤其是在嵌入式装置上。
问题二:AIMET在模型量化过程中扮演什么角色?
能够调整,寻找最佳量化参数,并提供量化感知训练 (Quantization-Aware Training, QAT) 支持,以提高量化模型的精确度,以及产生装备所需的量化模型和参数档。
问题三:在AIMET的量化过程中,参数如'quant_scheme'、'default_output_bw'、和'default_param_bw'分别代表什么?
在 AIMET 的量化过程中,'quant_scheme'是用来指定量化方案,如'tf'表示使用TensorFlow风格的量化。'default_output_bw'设定预设的输出位元宽,通常为8位元。'default_param_bw'设定预设的参数位宽,同样通常为8位。
问题四:在实际专案中,如何选择适当的量化位宽?
许多硬体加速器 (如部分GPU和专用AI芯片) 对8位元硬体损坏有最佳化支援,但对于复杂模型可能需要更高的位宽来保持性能 (如16位元),否则会导致模型能力下降,开发者可以透过实验找到最佳平衡点。
问题五:模型量化过程中,如何处理和评估模型的稳健性和泛化能力?
除了对资料集增强外,也可以使用量化感知训练以提高模型的精确度与稳健性,而在AIMET中也有提供此功能的API,且在开发过程中,也要持续监控模型性能并做好验证。
参考资料
[1] AIMET: AI Model Efficiency Toolkit (AIMET) | Qualcomm Developer
[2] VGG11: https://arxiv.org/abs/1409.1556
[3] QuantizationSimModel: Qualcomm Documentation


















 4420
4420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









