







文章目录
视频课
mHarvey:
视频课:(双语字幕)吴恩达深度学习deeplearning.ai 1.1 计算机视觉+卷积神经网络CNN_mHarvey_哔哩哔哩_bilibili 字幕是独立于视频的。这是2018年旧版的。
笔记:fengdu78/deeplearning_ai_books: deeplearning.ai(吴恩达老师的深度学习课程笔记及资源)。笔记把所有句子和PPT都记录了,完全可以只看笔记,不看视频课。看笔记也更快些。
作业+PPT下载:robbertliu/deeplearning.ai-andrewNG: deeplearning.ai , By Andrew Ng, All slide and notebook + data + solutions and video link
作业的翻译版本,在线Notebook:吴恩达《深度学习》作业线上版 - 知乎
啥都会一点的研究生:
视频课:(强推|双字)2021版吴恩达深度学习课程Deeplearning.ai。第四课01 - 1.1计算机视觉+卷积神经网络CNN_啥都会一点的研究生_哔哩哔哩_bilibili 字幕不是独立于视频的。这是2021年新版的,加了一些内容,比如:U-net、Transformer。
作业+PPT下载:b站、公众号,啥都会一点的研究生:视频课配套的资料集的网盘链接 。提取码:5b1w。
第四课:卷积神经网络(Convolutional Neural Networks)
第一周:Convolutional Neural Networks 卷积神经网络
-
Computer vision 计算机视觉
-
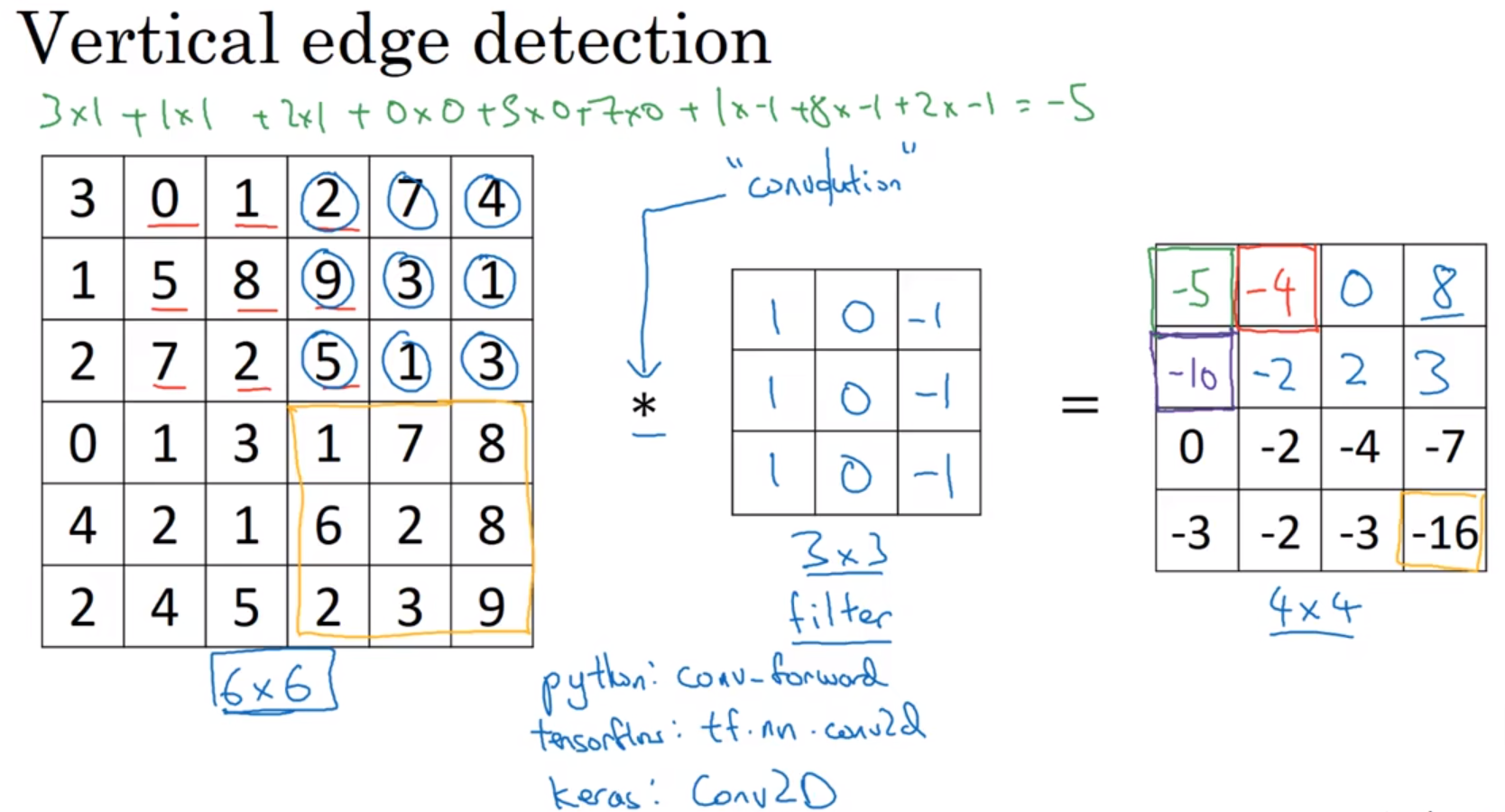
Edge detection example 边缘探测示例
convolution:卷积。符号:星号*。
filter:过滤器。也叫卷积核。
卷积计算方式:一个卷积核,就是图中的3×3矩阵,蒙到图像的同样大小的一块区域,上下对应数字相乘,所有乘积相加,得到结果图像的一个像素值。
- More edge detection 更多边缘探测
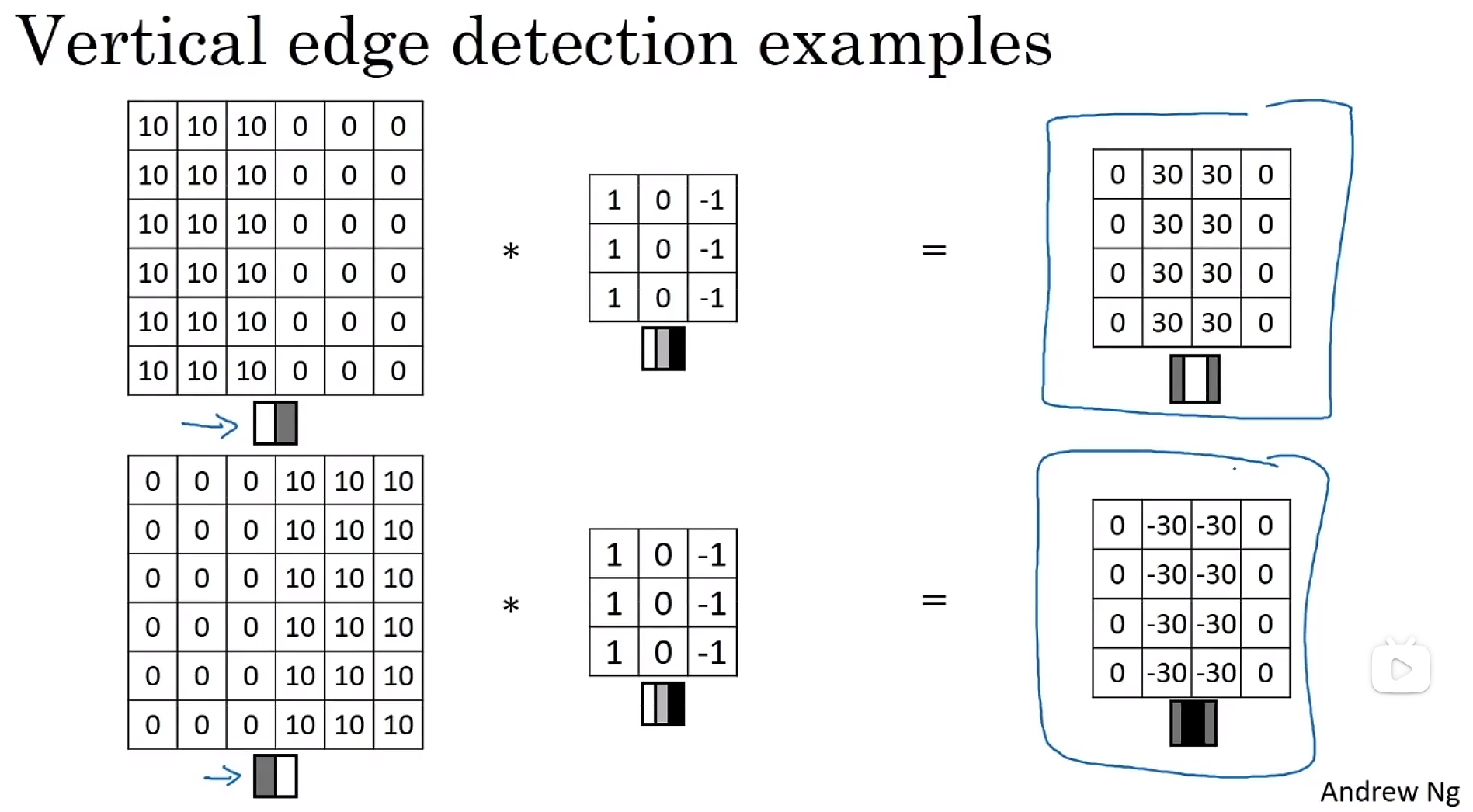
垂直边缘检测的filter,水平边缘检测的filter:

Sobel filter:索贝尔滤波器。增加了中间一行元素的权重,使得结果的鲁棒性会更高一些。
[
1
0
−
1
2
0
−
2
1
0
−
1
]
\left[ \begin{matrix} 1 & 0 & -1 \\ 2 & 0 & -2 \\ 1 & 0 & -1 \end{matrix} \right]
121000−1−2−1
Scharr filter。
可以把filter的值都作为参数,使用反向传播神经网络去学习它们。
- Padding 填充

p:padding count 填充大小,p=1时,就把整个图像外围包一层像素,即长+2,宽+2。填充大小=p时,即长+2p,宽+2p。
Valid and Same convolutions 有效卷积和相同卷积
Valid convolution:不填充输入图像。 输入图像n×n×
n
C
n_{C}
nC * 过滤器f×f×
n
C
n_{C}
nC ——》 输出图像
⌊
(
n
−
f
s
+
1
)
⌋
×
⌊
(
n
−
f
s
+
1
)
⌋
×
n
C
′
⌊(\frac{n-f}{s}+1)⌋ × ⌊(\frac{n-f}{s}+1)⌋ × n_{C}'
⌊(sn−f+1)⌋×⌊(sn−f+1)⌋×nC′ 。
Same convolution:Pad so that output size is the same as the input size. 填充输入图像,使输出大小与输入大小相同。举例:卷积核移动步长=1时尺寸不变,移动步长=stride时卷积完毕后尺寸为
n
o
u
t
p
u
t
=
⌈
n
i
n
p
u
t
s
t
r
i
d
e
⌉
n_{output}=⌈\frac{n_{input} }{stride}⌉
noutput=⌈strideninput⌉。
Same convolution:卷积核移动步长=1时,输入图像n×n,填充后的图像(n+2p)×(n+2p) * 过滤器f×f ——》 输出图像(n+2p-f+1)×(n+2p-f+1)。 要使得输入图像大小n等于输出图像大小(n+2p-f+1),即n=n+2p-f+1,即p=
f
−
1
2
\frac{f-1}{2}
2f−1 。
TensorFlow中padding卷积的两种方式“SAME”和“VALID”_-CSDN博客
filter的大小通常是奇数,如3×3、5×5、7×7,等等。
- Strided convolutions 卷积步长
输入图像n×n
过滤器f×f
padding:p,填充大小,即:进行卷积前,在输入图像的外围包裹p层像素。
stride:s ,卷积步长,即:filter矩阵覆盖输入图像,不管横向还是纵向,都是每隔卷积步长个像素覆盖一次。
输入图像n×n * 过滤器f×f ——》 输出图像
⌊
(
n
+
2
p
−
f
s
+
1
)
⌋
×
⌊
(
n
+
2
p
−
f
s
+
1
)
⌋
⌊(\frac{n+2p-f}{s}+1)⌋ × ⌊(\frac{n+2p-f}{s}+1)⌋
⌊(sn+2p−f+1)⌋×⌊(sn+2p−f+1)⌋
⌊ ⌋:向下取整的符号。
数学中,直接卷积叫做互相关cross-correlation,而把filter进行左右翻转+上下翻转后,再进行卷积,这才叫卷积convolution。
在机器学习中,我们把直接卷积,叫做卷积。
- Convolutions over volumes 三维卷积
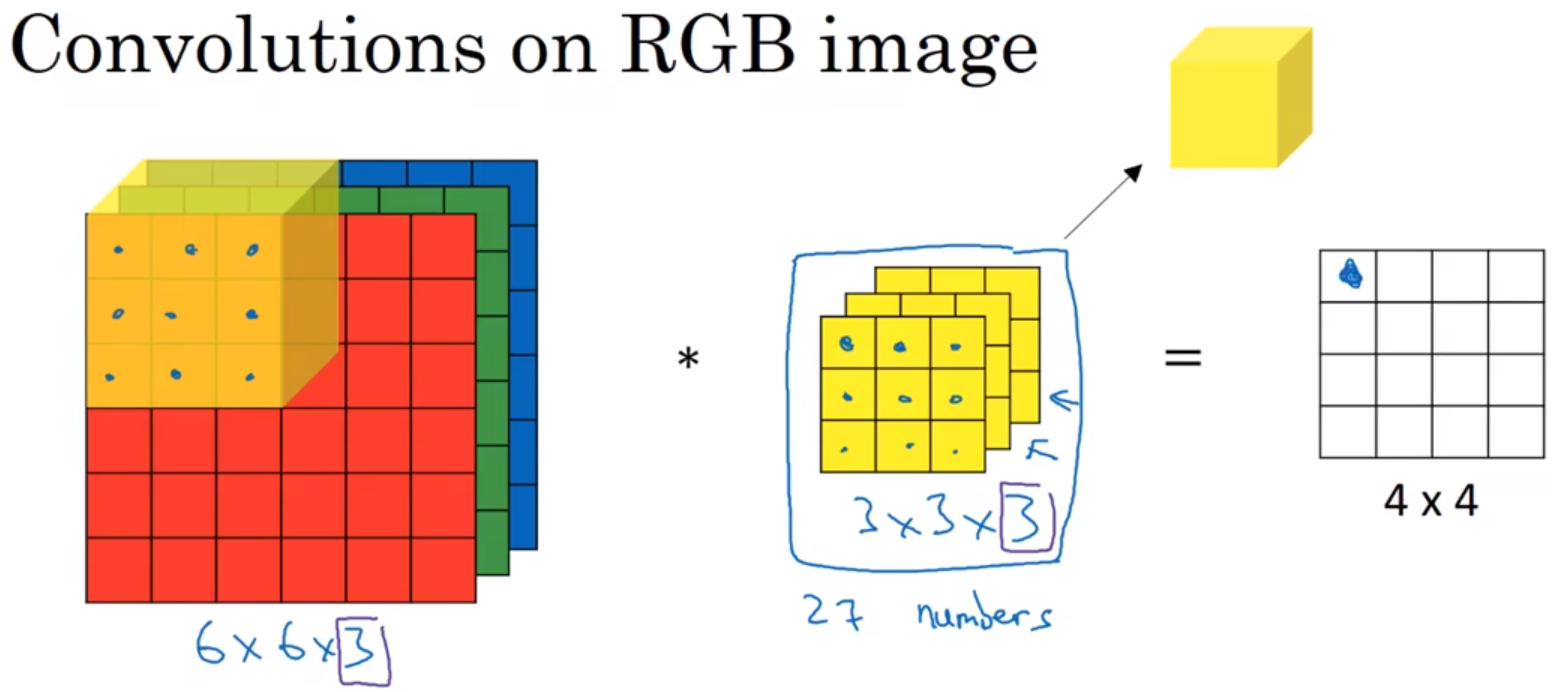
filter的长宽可以随意定,但是filter的高必须和输入图像相同,如图中,输入图像和filter的高都是3。
计算方法是:filter覆盖进入到原图像上,相同位置的数字相乘,然后所有乘积相加。
只检测红色通道的垂直边缘过滤器:RGB图像,第一层是红色层,这层的filter是垂直边缘检测矩阵,
[
1
0
−
1
1
0
−
1
1
0
−
1
]
\left[ \begin{matrix} 1 & 0 & -1 \\ 1 & 0 & -1 \\ 1 & 0 & -1 \end{matrix} \right]
111000−1−1−1
而第二层、第三层的filter,都是0矩阵,即矩阵的所有元素都是0。
检测任意颜色通道的垂直边界的检测器:第一层、第二层、第三层的filter,都是垂直边缘检测矩阵。
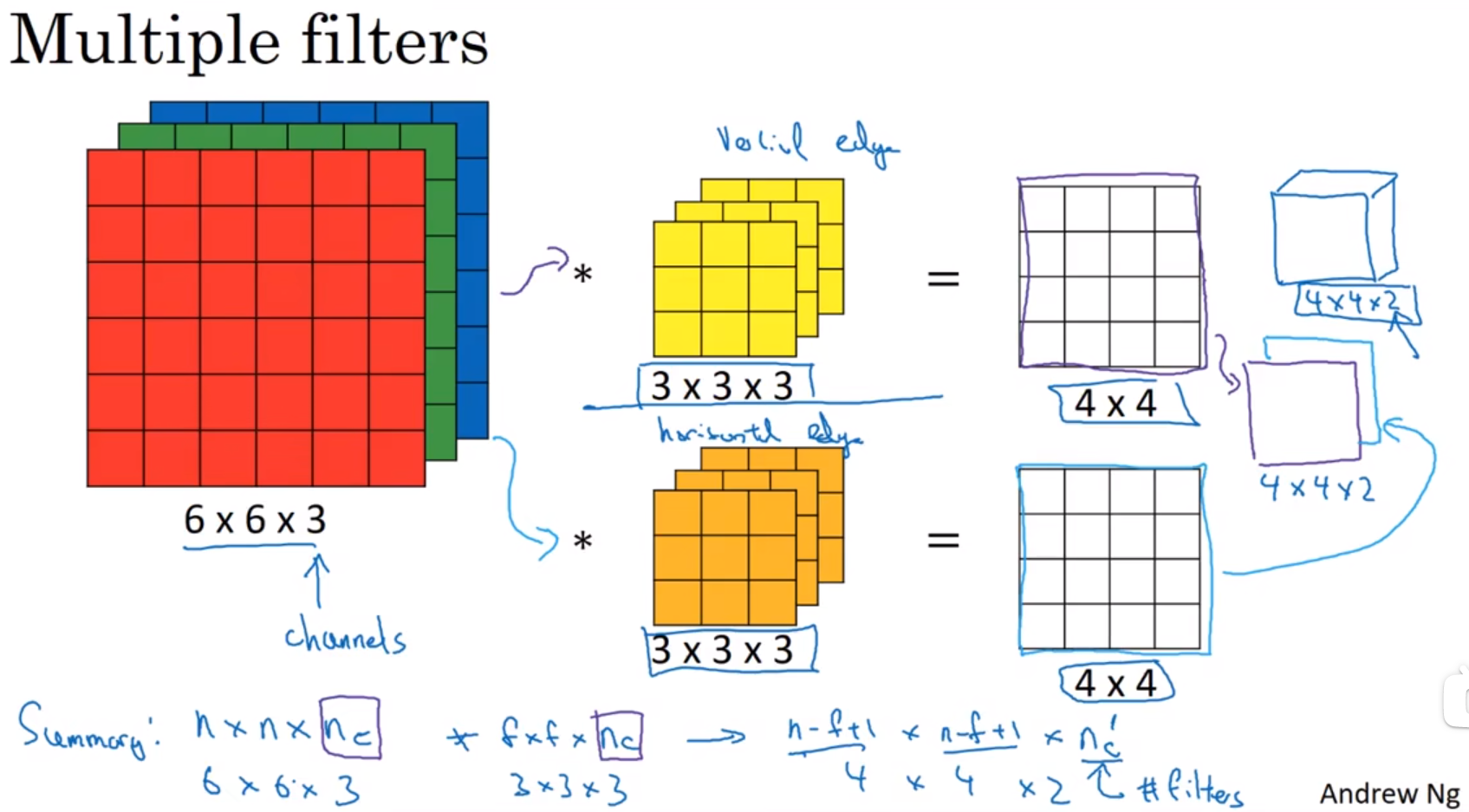
C: channel,通道。depth,深度。
n
C
n_{C}
nC: number of channel,通道数,可以理解为RGB图像有3个通道。also call this the depth of this 3D volume,也叫3维立方体的深度。
n
C
′
n_{C}'
nC′: number of filter that you use,你使用的过滤器数量。
使用2个filter的例子:你可以先把输入图像和垂直边缘检测filter相卷积,得到结果矩阵1,然后把输入图像和平行边缘检测filter相卷积,得到结果矩阵2,两个结果矩阵叠起来,是最终结果。即:你需要检测几种特征,你就需要使用几种filter。
输入图像n×n× n C n_{C} nC * 过滤器f×f× n C n_{C} nC ——》 输出图像 ⌊ ( n + 2 p − f s + 1 ) ⌋ × ⌊ ( n + 2 p − f s + 1 ) ⌋ × n C ′ ⌊(\frac{n+2p-f}{s}+1)⌋ × ⌊(\frac{n+2p-f}{s}+1)⌋ × n_{C}' ⌊(sn+2p−f+1)⌋×⌊(sn+2p−f+1)⌋×nC′
⌊ ⌋:向下取整的符号。
- One layer of a convolutional network 单层卷积神经网络
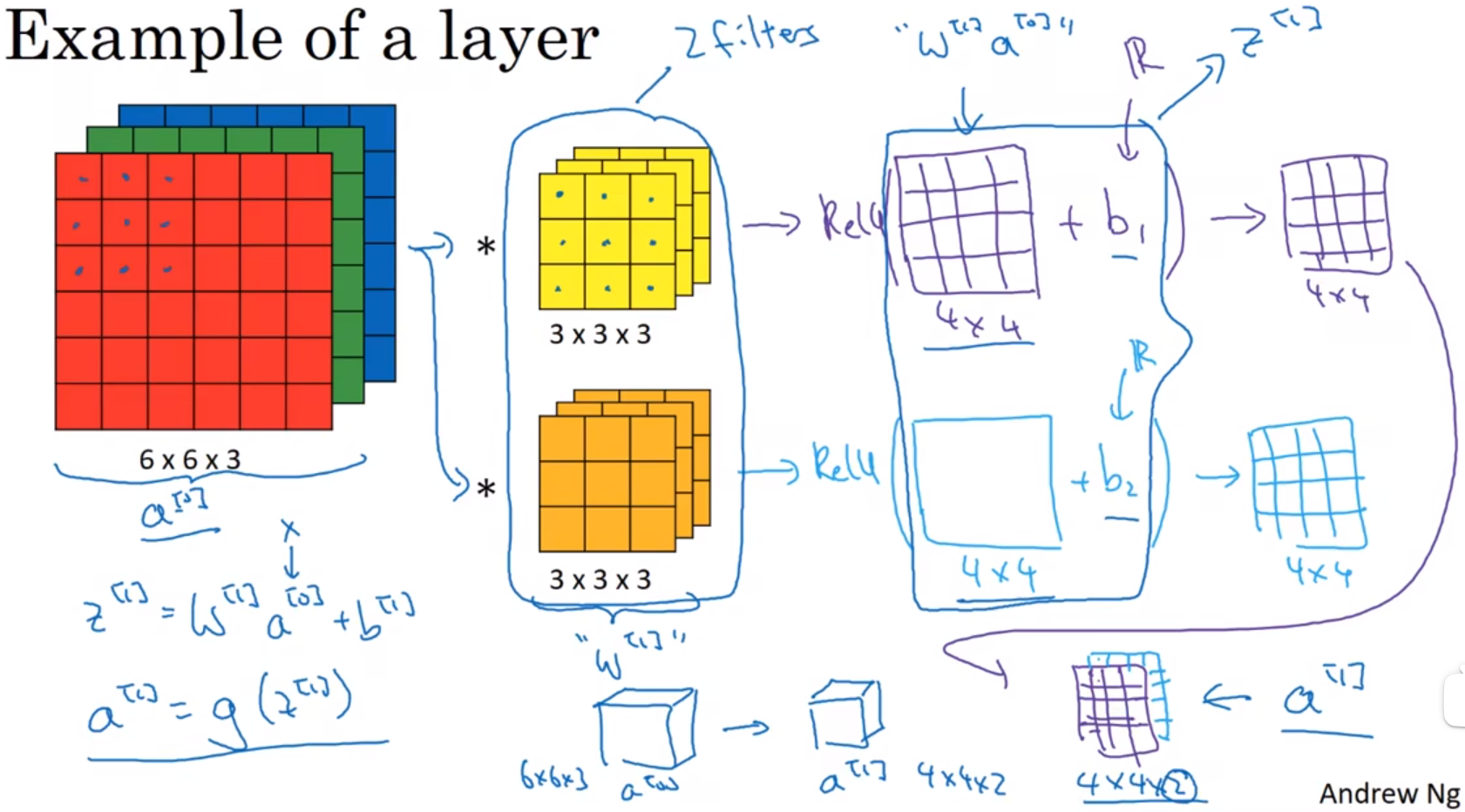
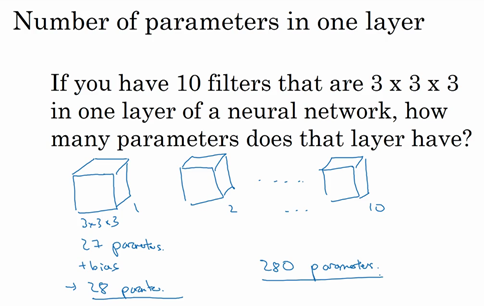
假设你有10个过滤器,神经网络的一层是3×3×3,那么,这一层有多少个参数呢?我们来计算一下,每一层都是一个3×3×3的矩阵,因此每个过滤器有27个参数,也就是27个数。然后加上一个偏差,用参数b表示,现在参数增加到28个。上一页幻灯片里我画了2个过滤器,而现在我们有10个,加在一起是28×10,也就是280个参数。
请注意一点,不论输入图片有多大,1000×1000也好,5000×5000也好,参数始终都是280个。用这10个过滤器来提取特征,如垂直边缘,水平边缘和其它特征。即使这些图片很大,参数却很少,这就是卷积神经网络的一个特征,叫作“避免过拟合”。

- A simple convolution network example 简单卷积网络示例

一张39×39×3的RGB图片,经过3次卷积,得到7×7×40=1960个特征,把这1960个特征经过逻辑回归(二分类)/softmax(多分类),得到预测结果
y
^
\hat{y}
y^,比如你想分类这张图片是否是猫。

Types of layer in a convolutional network 卷积网络中的层类型:
convolution: CONV,卷积层。
Pooling: POOL,池化层。没有参数需要梯度下降来学习的层。
Fully connected: FC,全连接层。普通的神经网络层。
- Pooling layers 池化层
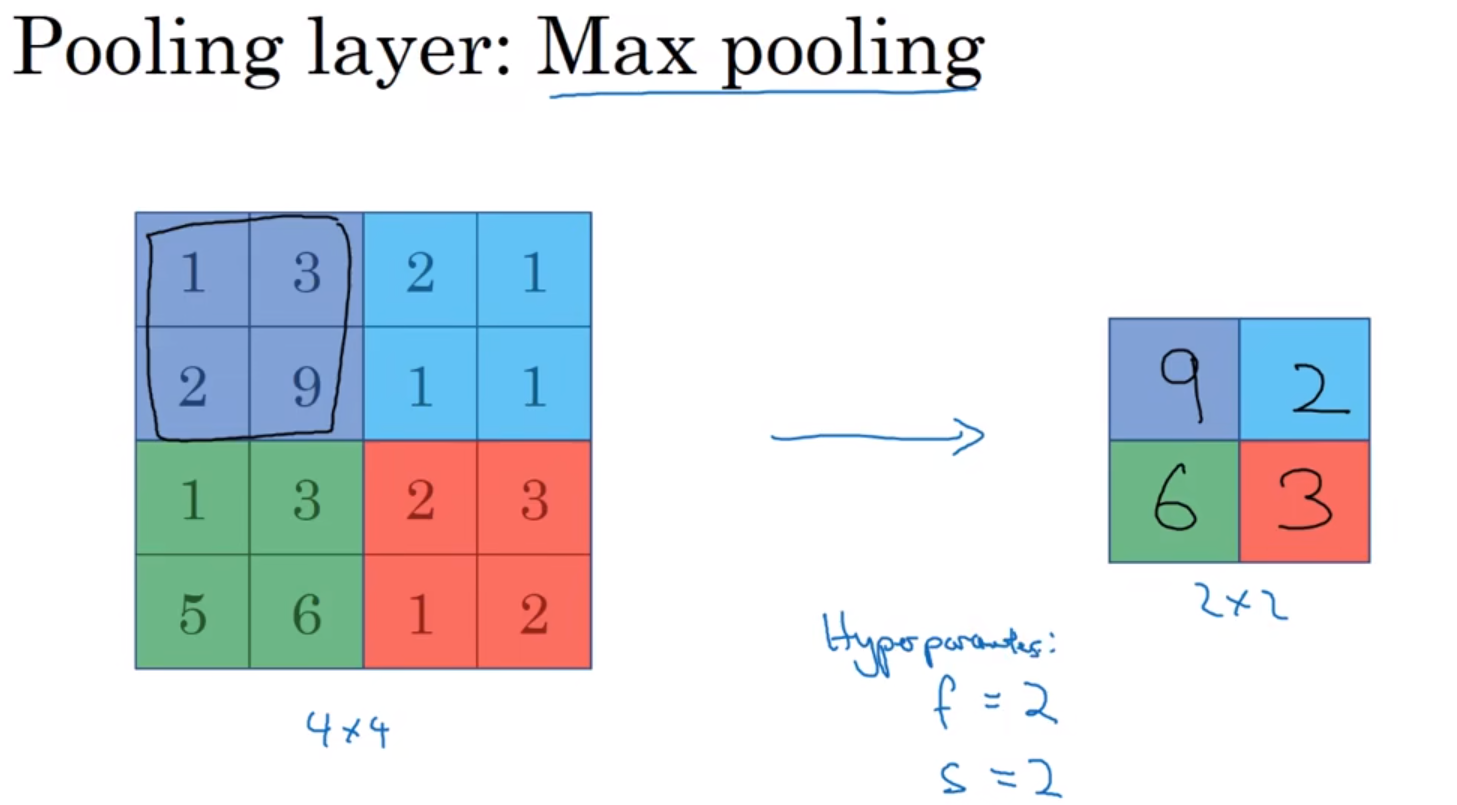
假如输入是一个4×4矩阵,用到的池化类型是最大池化(max pooling)。执行最大池化的输出是一个2×2矩阵。执行过程非常简单,把4×4的输入拆分成不同的区域,我把这个区域用不同颜色来标记。对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
这就像是应用了一个规模为2的过滤器,因为我们选用的是2×2区域,步幅是2,这些就是最大池化的超参数(f=2, s=2)。
它有一组超参数,但并没有参数需要学习。实际上,梯度下降没有什么可学的,一旦确定了f和s,它就是一个固定运算,梯度下降无需改变任何值。
平均池化:这种运算顾名思义,选取的不是每个过滤器的最大值,而是平均值。它不太常用。
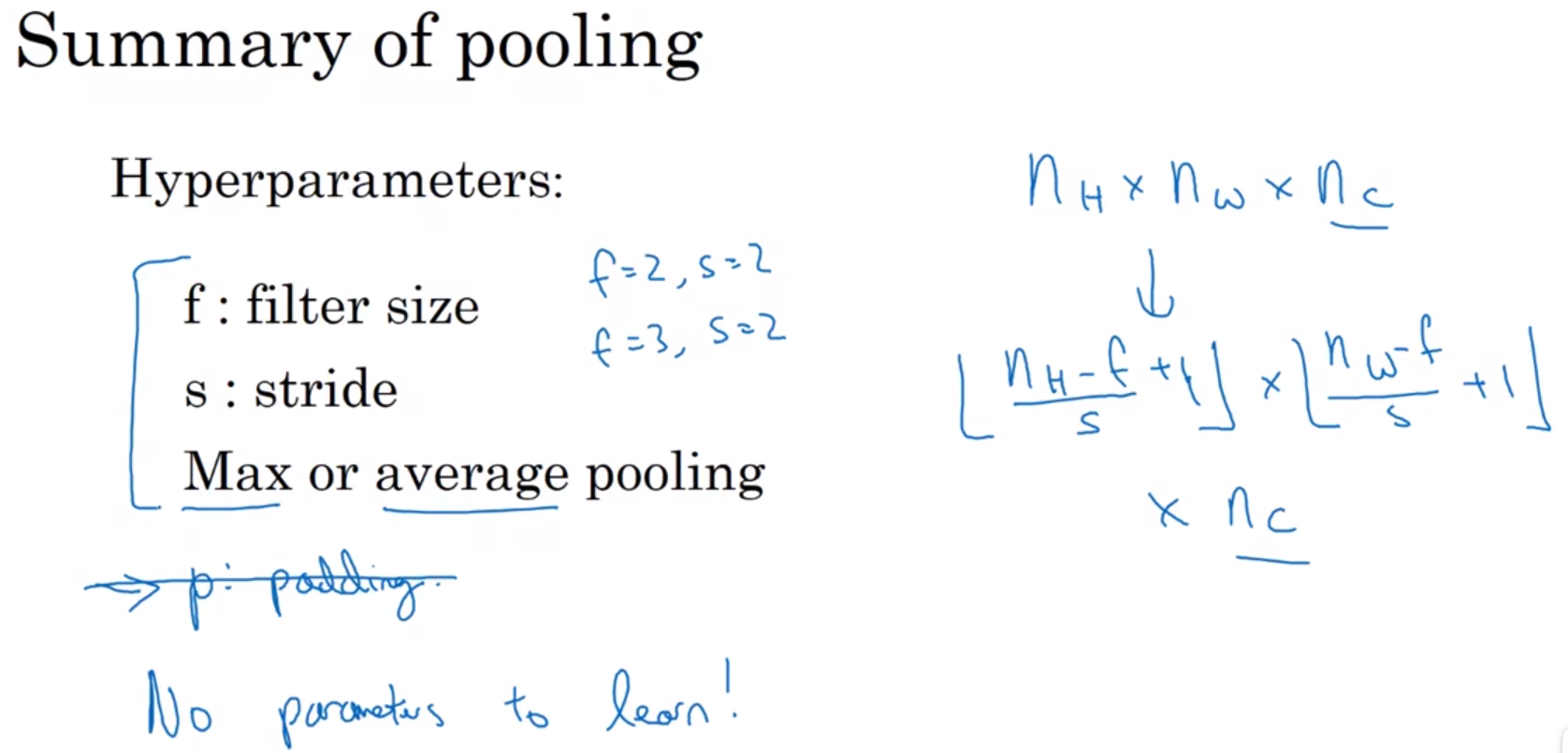
- Convolutional neural network example 卷积神经网络示例
在卷积神经网络文献中,卷积有两种分类。一类卷积是一个卷积层和一个池化层一起作为一层,这就是神经网络的Layer1。另一类卷积是把卷积层作为一层,而池化层单独作为一层。人们在计算神经网络有多少层时,通常只统计具有权重和参数的层。因为池化层没有权重和参数,只有一些超参数。这里,我们把CONV1和POOL1共同作为一个卷积,并标记为Layer1。
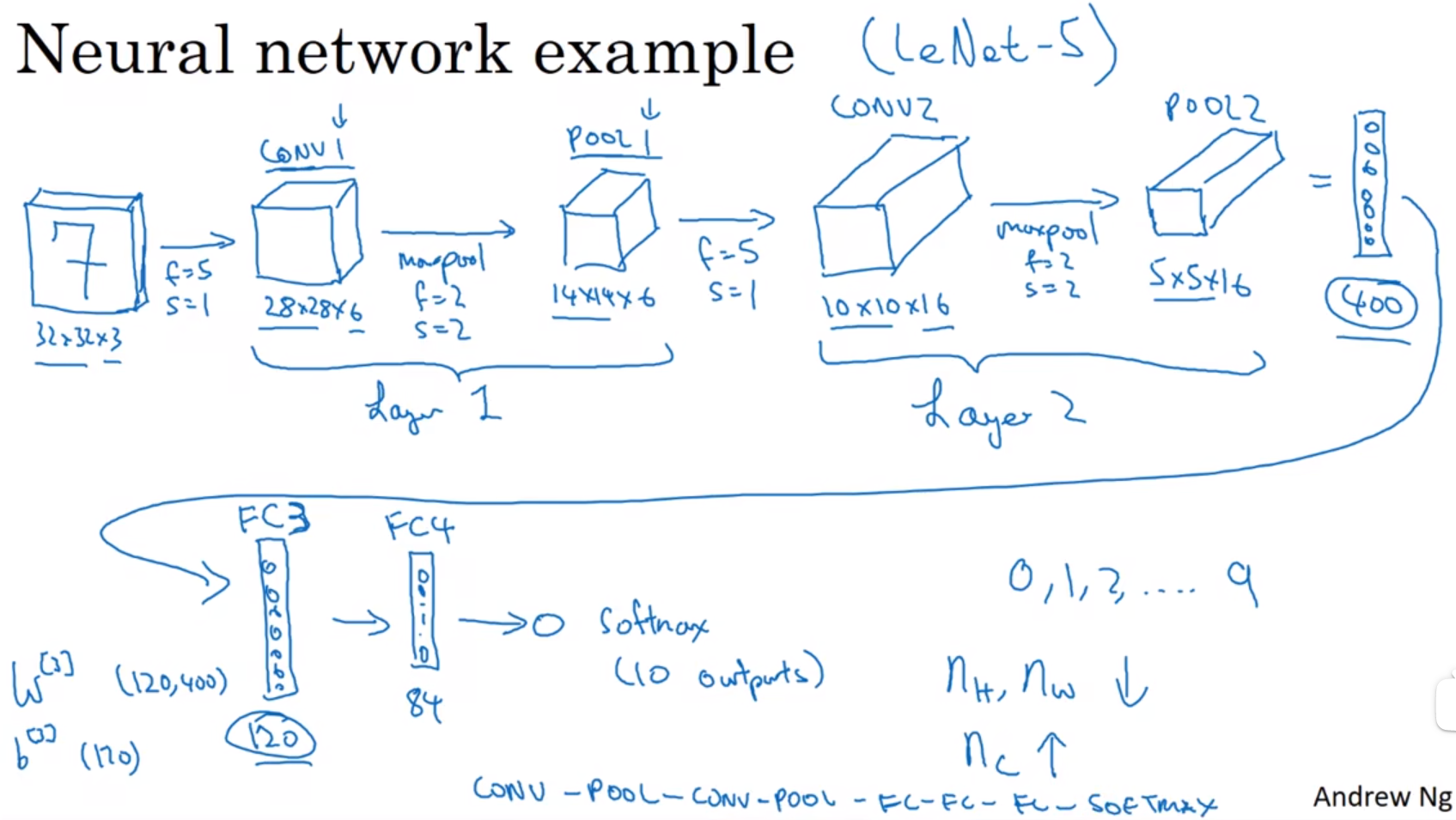
此例中的卷积神经网络很典型,看上去它有很多超参数,关于如何选定这些参数,后面我提供更多建议。常规做法是,尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,选一个在别人任务中效果很好的架构,那么它也有可能适用于你自己的应用程序,这块下周我会细讲。
在神经网络中,另一种常见模式就是一个或多个卷积后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个softmax。这是神经网络的另一种常见模式。

有几点要注意,第一,池化层和最大池化层没有参数;第二卷积层的参数相对较少,前面课上我们提到过,其实许多参数都存在于神经网络的全连接层。
- Why convolutions? 为什么使用卷积?
和只用全连接层相比,卷积层的两个主要优势在于参数共享和稀疏连接,这两点使得卷积层的参数远远小于全连接层。
translation invariance:平移不变性。一张图片,假如上面有只猫,那么平移几个像素后,仍然能够识别出这是只猫。
Parameter sharing: A feature detector(such as a vertical edge detector) that’s useful in one part of the image is probably useful in another part of the image.
Sparsity of connections: In each layer, each output value depends only on a small number of inputs.
参数共享:在图像的一部分有用的特征检测器(例如垂直边缘检测器)可能在图像的另一部分有用。
连接的稀疏性:在每个层中,每个输出值仅取决于少量输入。
第二周:Case Studies 案例学习
- Why look at case studies? 为什么要进行实例探究?
提纲:
Classic networks:LeNet-5、AlexNet、VGG。
ResNet (152)
Inception
- Classic networks 经典网络
经典的神经网络结构:LeNet-5、AlexNet、VGGNet。
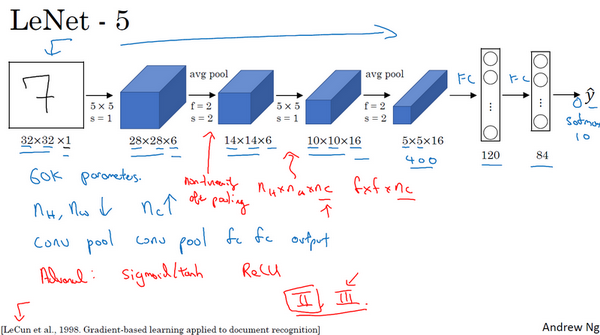
LeNet-5:
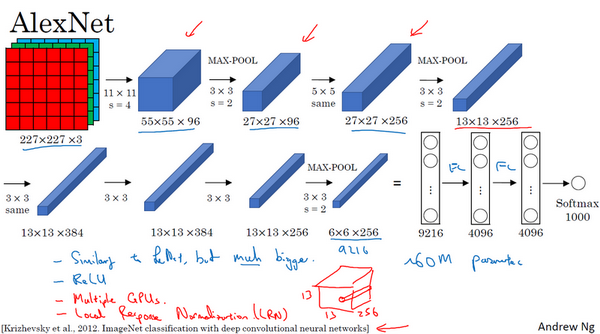
AlexNet:
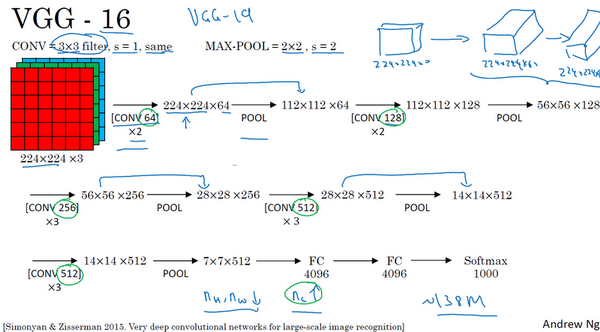
VGGNet:
- Residual Networks (ResNets) 残差网络
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。这节课我们学习跳跃连接(Skip connection),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。我们可以利用跳跃连接构建能够训练深度网络的ResNets,有时深度能够超过100层。
梯度消失、梯度爆炸 ,都是:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。
ResNets是由残差块(Residual block)构建的,首先我解释一下什么是残差块。
普通网络(Plain network)的一段:
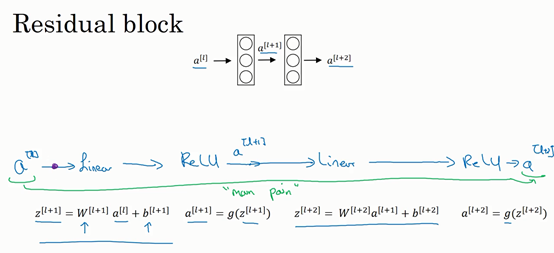
残差网络(Residual Networks (ResNets))的残差块(Residual block):
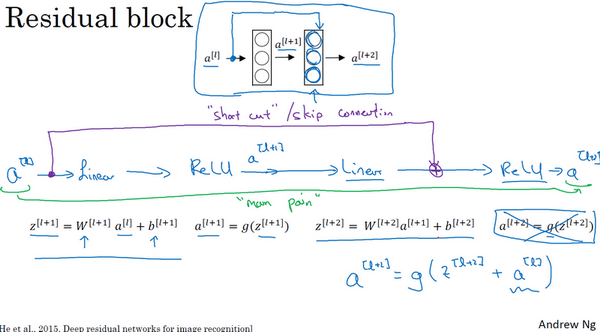
short cut:捷径。
skip connection:跳跃连接。
最后的等式 a [ l + 2 ] = g ( z [ l + 2 ] ) a^{[l+2]}=g(z^{[l+2]}) a[l+2]=g(z[l+2]) 变成了 a [ l + 2 ] = g ( z [ l + 2 ] + a [ l ] ) a^{[l+2]}=g(z^{[l+2]}+a^{[l]}) a[l+2]=g(z[l+2]+a[l]) 。
ResNet的发明者是何凯明(Kaiming He)、张翔宇(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jiangxi Sun),他们发现使用残差块能够训练更深的神经网络。所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起,形成一个很深神经网络,我们来看看这个网络。
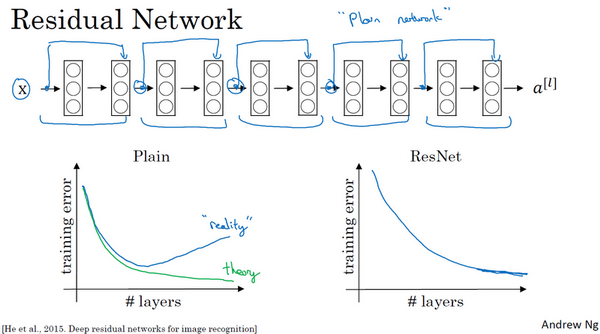
如图所示,5个残差块连接在一起构成一个残差网络。
- Why ResNets work? 残差网络为什么有用?
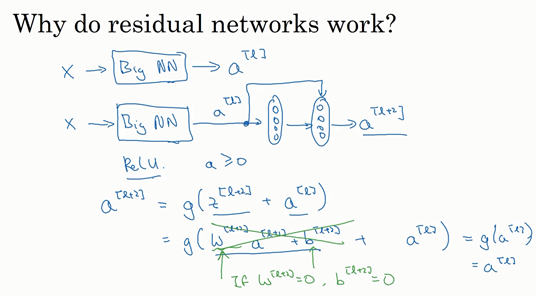
当
w
[
l
+
2
]
=
0
,
b
[
l
+
2
]
=
0
w^{[l+2]}=0, b^{[l+2]}=0
w[l+2]=0,b[l+2]=0 时,有:
a
[
l
+
2
]
=
g
(
z
[
l
+
2
]
+
a
[
l
]
)
=
g
(
w
[
l
+
2
]
a
[
l
+
1
]
+
b
[
l
+
2
]
+
a
[
l
]
)
=
g
(
a
[
l
]
)
=
a
[
l
]
a^{[l+2]}=g(z^{[l+2]}+a^{[l]})=g(w^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]})=g(a^{[l]})=a^{[l]}
a[l+2]=g(z[l+2]+a[l])=g(w[l+2]a[l+1]+b[l+2]+a[l])=g(a[l])=a[l] 。
因为我们假定使用ReLU激活函数,所以所有激活值都是非负的,所以
a
[
l
]
a^{[l]}
a[l] 是非负数,g()是ReLU,所以
g
(
a
[
l
]
)
=
a
[
l
]
g(a^{[l]})=a^{[l]}
g(a[l])=a[l] ,最终
a
[
l
+
2
]
=
a
[
l
]
a^{[l+2]}=a^{[l]}
a[l+2]=a[l]。
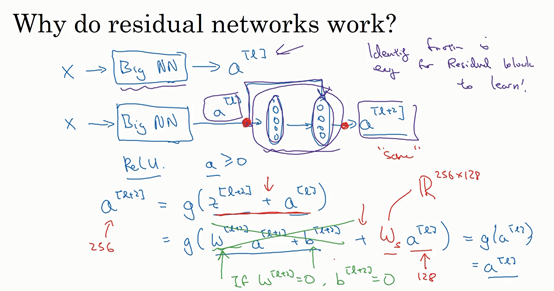
w
s
=
R
256
×
128
w_{s}=R^{256×128}
ws=R256×128 ,
R
256
×
128
R^{256×128}
R256×128 表示256×128的矩阵,图中R左边有一竖,是手写体的R。
这里的意思就是,使用残差网络时要注意矩阵大小。
a
[
l
+
2
]
=
g
(
z
[
l
+
2
]
+
a
[
l
]
)
=
g
(
w
[
l
+
2
]
a
[
l
+
1
]
+
b
[
l
+
2
]
+
a
[
l
]
)
=
g
(
a
[
l
]
)
=
a
[
l
]
a^{[l+2]}=g(z^{[l+2]}+a^{[l]})=g(w^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]})=g(a^{[l]})=a^{[l]}
a[l+2]=g(z[l+2]+a[l])=g(w[l+2]a[l+1]+b[l+2]+a[l])=g(a[l])=a[l]式子中,如果
a
[
l
]
a^{[l]}
a[l]是(128,1),
a
[
l
+
2
]
a^{[l+2]}
a[l+2] 是(256,1),那么需要
w
s
=
R
256
×
128
w_{s}=R^{256×128}
ws=R256×128矩阵,
w
s
w_{s}
ws这个参数是学习出来的。
相同大小的矩阵才能相加
g
(
z
[
l
+
2
]
+
a
[
l
]
)
g(z^{[l+2]}+a^{[l]})
g(z[l+2]+a[l])。注意调整 矩阵
w
s
w_{s}
ws 的大小,来使得矩阵运算的继续进行,网络的继续往下走。如果
a
[
l
+
2
]
a^{[l+2]}
a[l+2] 和
a
[
l
]
a^{[l]}
a[l] 是相同大小,比如卷积时使用same卷积(填充输入图像,使输出大小与输入大小相同),那么就不需要
w
s
w_{s}
ws 参数了。
- Network in Network and 1×1 convolutions 网络中的网络以及 1×1 卷积
过滤器为1×1,这里是数字2,输入一张6×6×1的图片,然后对它做卷积,起过滤器大小为1×1×1,结果相当于把这个图片乘以数字2,所以前三个单元格分别是2、4、6等等。用1×1的过滤器进行卷积,似乎用处不大,只是对输入矩阵乘以某个数字。但这仅仅是对于6×6×1的一个通道图片来说,1×1卷积效果不佳。

如果是一张6×6×32的图片,那么使用1×1过滤器进行卷积效果更好。具体来说,1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。
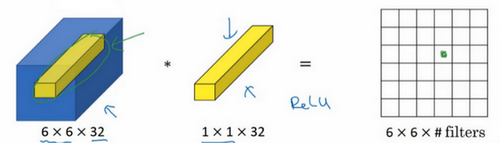
这种方法通常称为1×1卷积,有时也被称为Network in Network。
1×1卷积的一个应用例子:
假设这是一个28×28×192的输入层,你可以使用池化层压缩它的高度和宽度,但无法压缩它的通道数量(深度)。该如何把它压缩为28×28×32维度的层呢?你可以用32个大小为1×1的过滤器,严格来讲每个过滤器大小都是1×1×192维,因为过滤器中通道数量必须与输入层中通道的数量保持一致。但是你使用了32个过滤器,输出层为28×28×32,这就是压缩通道数(
n
C
n_{C}
nC)的方法。
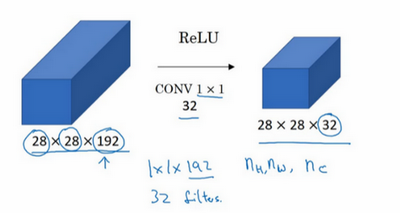
1×1卷积层就是这样实现了一些重要功能的(doing something pretty non-trivial),它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。
- Inception network motivation 谷歌 Inception 网络简介
构建卷积层时,你要决定过滤器的大小究竟是1×1、3×3还是5×5,或者要不要添加池化层。Inception网络或Inception层的作用就是代替人工来确定卷积层中的过滤器类型,或者确定是否需要创建卷积层或池化层。
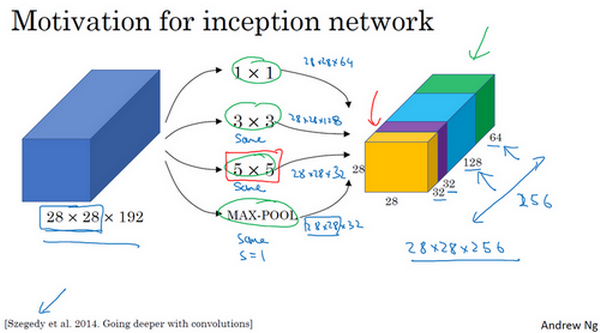
基本思想是Inception网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
Inception层有一个问题,就是计算成本过大。
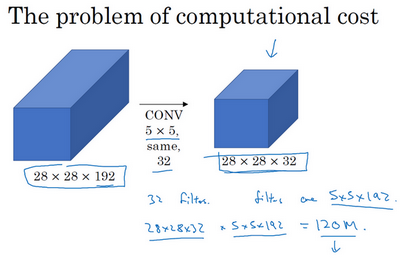
上图,乘法运算的总次数为,每个输出值所需要执行的乘法运算次数(5×5×192)乘以输出值个数(28×28×32),把这些数相乘结果等于1.2亿(120422400)(120 million)。
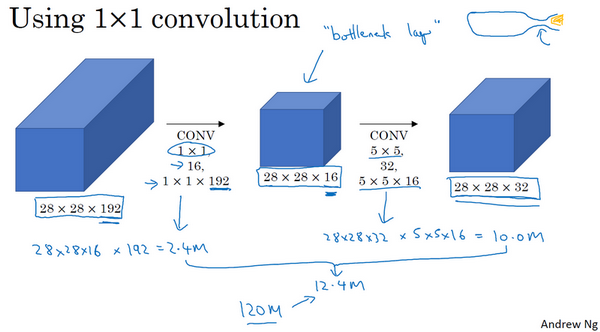
使用1×1卷积,解决计算成本过大的问题。
bottleneck layer:瓶颈层。
上图,使用1×1卷积,乘法运算的总次数为,1240万(12.4 million),是原乘法运算总次数1.2亿(120 million) 的十分之一。
你可能会问,仅仅大幅缩小表示层规模会不会影响神经网络的性能?事实证明,只要合理构建瓶颈层,你既可以显著缩小表示层规模,又不会降低网络性能,从而节省了计算。
- Inception network 。Inception 网络
Inception模块:
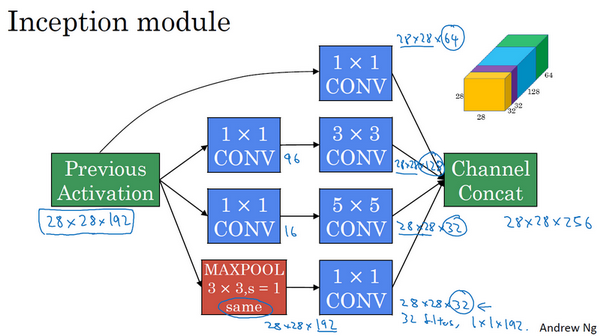
Inception网络:由这几样组成:多个Inception模块、额外的最大池化层(图中红色都是最大池化层)、全连接层+softmax。
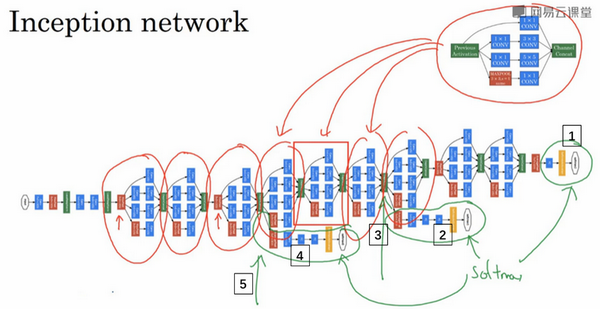
这个特别的Inception网络是由Google公司的作者所研发的,它被叫做GoogleLeNet,这个名字是为了向LeNet网络致敬。Inception有许多版本,比如Inception V2、V3以及V4。
- Using open-source implementations 使用开源的实现方案
当你自己编写代码时,我鼓励你考虑一下将你的代码贡献给开源社区。如果你看到一篇研究论文想应用它的成果,你应该考虑做一件事,我经常做的就是在网络上寻找一个开源的实现。
何凯明的深度残差网络的GitHub代码仓库:KaimingHe/deep-residual-networks: Deep Residual Learning for Image Recognition
何凯明的残差网络论文:Deep Residual Learning for Image Recognition | IEEE Conference Publication | IEEE Xplore
讲了下GitHub仓库的,README.md、开源许可证、URL下载。
- Transfer Learning 迁移学习
数据集的名字:比如ImageNet,或者MS COCO,或者Pascal类型的数据集。
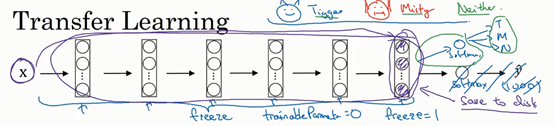
预训练:从网上下载一些神经网络开源的实现,不仅把代码下载下来,也把权重下载下来。你可以去掉这个Softmax层,创建你自己的Softmax单元,用来输出Tigger、Misty和neither三个类别。就网络而言,我建议你把所有的层看作是冻结的,你冻结网络中所有层的参数,你只需要训练和你的Softmax层有关的参数。
不训练某一层神经网络,根据不同的深度学习框架,有这样的参数:trainableParameter=0、freeze=1 。
一个在迁移学习时,减少训练时间的技巧:一个迁移学习的神经网络,它的左半截是冻结参数的网络,右半截是需要训练的Softmax层。迭代训练输入图像时,只走左半截一遍,把得到的中间结果存入硬盘,然后从硬盘取出中间结果,迭代训练(重复训练)右半截。
就是把左半截得到的激活值当做新的X,因为前面的值固定不变嘛,然后每次迭代的时候就不需要反复计算了。
如果你有越多的标定的数据,图片+正确标签,你可以训练越多的层(冻结的层越少)。极端情况下,你可以用下载的权重只作为初始化,用它们来代替随机初始化,接着你可以用梯度下降训练,更新网络所有层的所有权重。
- Data augmentation 数据增强
Mirroring: 镜像
Random Cropping: 随机裁剪
Rotation: 旋转
Shearing: 修剪。沿轴扭曲图像,比如长方形变平行四边形。
Local warping: 局部变形
Color shifting: 彩色转换。有这样一张图片,然后给R、G和B三个通道上加上不同的失真值。
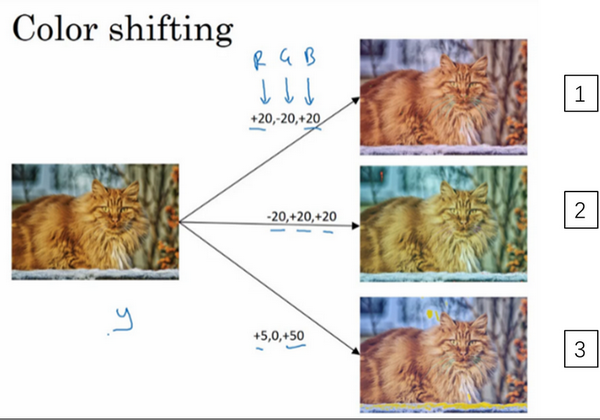
在实践中,R、G和B的值是根据某种概率分布来决定的。这么做的理由是,可能阳光会有一点偏黄,或者是灯光照明有一点偏黄,这些可以轻易的改变图像的颜色,但是对猫的识别,或者是内容的识别,以及标签y,还是保持不变的。所以介绍这些,颜色失真或者是颜色变换方法,这样会使得你的学习算法对照片的颜色更改更具鲁棒性。
对R、G和B有不同的采样方式,其中一种影响颜色失真的算法是PCA,即主成分分析。
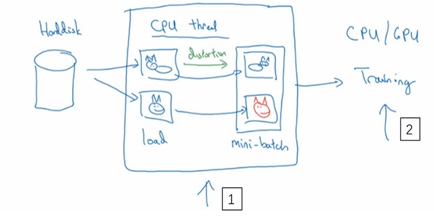
常用的实现数据扩充的方法是使用一个线程或者是多线程,来加载数据,实现变形失真,然后传给其他的线程或者其他进程,来训练。
- The state of computer vision 计算机视觉现状
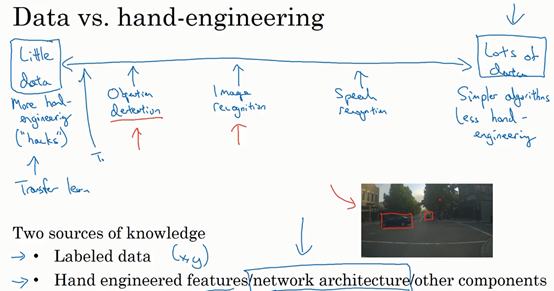
image recognition: 图像识别,图像分类。二分类、多分类。一张图片,里面只有一个物体,里面是猫是狗还是老鼠。
多标签分类:比如一张图片,里面有多个物体,里面是否有猫,是否有狗。比如一个病人的体检报告,它可能被标记上,高血压,高血糖等多个标签。
object detection: 物体检测,目标检测。图像里有多个猫,把图像中的所有猫用边框框出来。
speech recognition: 语音识别。
上图展示了,机器学习在图像领域的数据量,很少。
当数据多时,人们倾向使用更简单的算法和更少的手工工程 using simpler algorithms as well as less hand engineering。相反当你没有那么多的数据时,那时你会看到人们从事更多的是手工工程 hand-engineering,低调点说就是你有很多小技巧可用(整理者注:在机器学习或者深度学习中,一般更崇尚更少的人工处理,而手工工程更多依赖人工处理)。数据少时,需要迁移学习。
Two sources of knowledge:
Labeled data
Hand engineered features / network architecture / other components
两种知识来源:
标记的数据。比如(x,y)应用在监督学习。
手工设计的功能/网络架构/其他组件
在数据多的机器学习方面,完全不需要复杂的网络,只需要构建个简单的网络,然后平推,就能得到非常好的结果。
由于计算机视觉方面,数据严重不足,所以有了很多提高机器学习表现的方法。这些方法在竞赛、论文发表上很有效,但在工业生产上没有用处,即不会用于生产实际的客户服务(我:因为,要么要使用很多算力很多时间,要么会过拟合于给出的数据)。
下面是一些有助于在基准测试中表现出色的小技巧:
Tips for doing well on benchmarks / winning competitions
Ensembling: Train several networks independently and average their outputs.
Multi-crop at test time: Run classifier on multiple versions of test images and average results.
做好基准/赢得比赛的技巧
集成:独立训练多个网络并平均其输出。缺点:需要在3-15个网络上运行同一个图像,所以需要几倍的算力。
测试时多裁剪:对多个版本的测试图像运行分类器,然后平均结果。举例:测试集里有一只猫的图像,把这个图像在中间、左上、右上、左下、右下,各裁剪出一张猫的图像,裁剪出5张猫的小图,然后把原始图片镜像翻转,再次裁剪5次,最终得到10张猫的小图,这叫 10-crop。把这10张小图也用于测试,测试的结果平均一下,作为原始图像的测试结果。比如分类这是否是一只猫的图片,分类10次,结果平均,肯定优于分类一次。
下面是学习方法:
Use open source code
Use architectures of networks published in the literature
Use open source implementations if possible
Use pretrained models and fine-tune on your dataset
使用开源代码
使用文献中发表的网络架构
如果可能,请使用开源实现
使用预训练的模型并对数据集进行微调
第三周:Object Detection 目标检测
- Object localization 目标定位
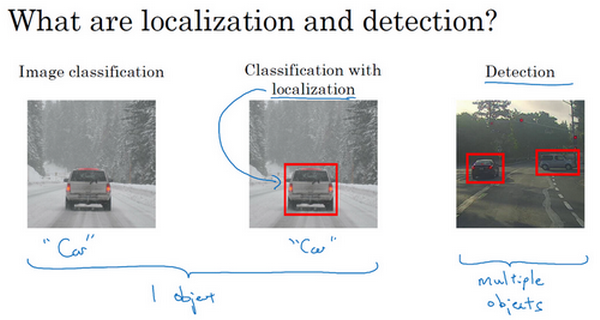
Image classification: 图片分类。图片里只有一个物体,该物体属于哪一类。
Classification with localization: 定位分类问题。图片里只有一个物体,该物体属于哪一类,并框选出物体。
Detection: 检测。图片里有多个物体,该物体属于哪一类,并框选出来。
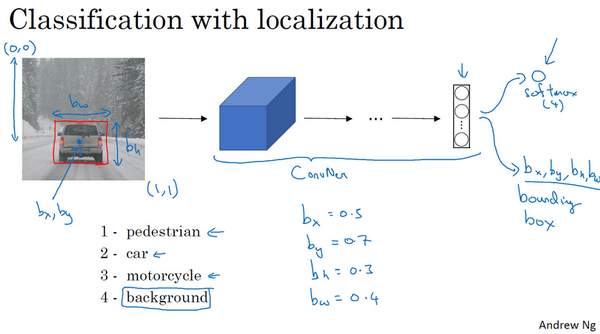
如果你正在构建汽车自动驾驶系统,那么对象可能包括以下几类:行人、汽车、摩托车和背景。背景意味着图片中不含有前三种对象,也就是说图片中没有行人、汽车和摩托车,输出结果会是背景对象。这四个分类就是softmax函数可能输出的结果。
这就是标准的分类过程,如果你还想定位图片中汽车的位置,该怎么做呢?我们可以让神经网络多输出几个单元,输出一个边界框。具体说就是让神经网络再多输出4个数字,标记为 b x b_{x} bx、 b y b_{y} by、 b h b_{h} bh、 b w b_{w} bw,这四个数字是被检测对象的边界框的参数化表示。
我们先来约定本周课程将使用的符号表示,图片左上角的坐标为 ( 0 , 0 ) (0,0) (0,0),右下角标记为 ( 1 , 1 ) (1,1) (1,1)。要确定边界框的具体位置,需要指定红色方框的中心点,这个点表示为 ( b x , b y ) (b_{x},b_{y}) (bx,by),边界框的高度为 b h b_{h} bh,宽度为 b w b_{w} bw。因此训练集不仅包含神经网络要预测的对象分类标签,还要包含表示边界框的这四个数字,接着采用监督学习算法,输出一个分类标签,还有四个参数值,从而给出检测对象的边框位置。
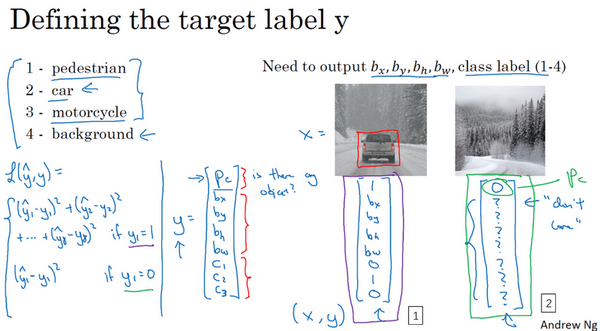
请注意,这有四个分类,神经网络输出的是这四个数字和一个分类标签,或分类标签出现的概率。目标标签
y
y
y 的定义如下:
y
=
[
p
c
b
x
b
y
b
h
b
w
c
1
c
2
c
3
]
y= \begin{bmatrix} p_{c} \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \\ c_{1} \\ c_{2} \\ c_{3} \end{bmatrix}
y=
pcbxbybhbwc1c2c3
它是一个向量,第一个组件 p c p_{c} pc表示是否含有对象,如果对象属于前三类(行人、汽车、摩托车),则 p c = 1 p_{c}= 1 pc=1,如果是背景,则图片中没有要检测的对象,则 p c = 0 p_{c} =0 pc=0。我们可以这样理解 p c p_{c} pc,它表示被检测对象属于某一分类的概率,背景分类除外。
定位分类问题(图片最多只会出现其中一个对象,行人、汽车、摩托车、背景)举例:
图片中有一辆汽车:
y
=
[
1
b
x
b
y
b
h
b
w
0
1
0
]
y= \begin{bmatrix} 1 \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \\ 0 \\ 1 \\ 0 \end{bmatrix}
y=
1bxbybhbw010
假如这是一张训练集图片,标记为
x
x
x,即上图的汽车图片。而在
y
y
y当中,第一个元素
p
c
=
1
p_{c} =1
pc=1,因为图中有一辆车,
b
x
b_{x}
bx、
b
y
b_{y}
by、
b
h
b_{h}
bh、
b
w
b_{w}
bw会指明边界框的位置,所以标签训练集需要标签的边界框。图片中是一辆车,所以结果属于分类2,因为定位目标不是行人或摩托车,而是汽车,所以
c
1
=
0
c_{1}= 0
c1=0,
c
2
=
1
c_{2} = 1
c2=1,
c
3
=
0
c_{3} =0
c3=0,
c
1
c_{1}
c1、
c
2
c_{2}
c2和
c
3
c_{3}
c3中最多只有一个等于1。
图片中没有检测对象:
y
=
[
0
?
?
?
?
?
?
?
]
y= \begin{bmatrix} 0 \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \end{bmatrix}
y=
0???????
p c = 0 p_{c} =0 pc=0, y y y的其它参数将变得毫无意义,这里我全部写成问号,表示“毫无意义”的参数,因为图片中不存在检测对象,所以不用考虑网络输出中边界框的大小,也不用考虑图片中的对象是属于 c 1 c_{1} c1、 c 2 c_{2} c2和 c 3 c_{3} c3中的哪一类。
最后,我们介绍一下神经网络的损失函数,Ground Truth真值是 y y y,你的神经网络的输出是 y ^ \hat{y} y^,如果采用平方误差策略,则 L ( y ^ , y ) = ( y 1 ^ − y 1 ) 2 + ( y 2 ^ − y 2 ) 2 + … ( y 8 ^ − y 8 ) 2 L\left(\hat{y},y \right) = \left( \hat{y_1} - y_{1} \right)^{2} + \left(\hat{y_2} - y_{2}\right)^{2} + \ldots\left( \hat{y_8} - y_{8}\right)^{2} L(y^,y)=(y1^−y1)2+(y2^−y2)2+…(y8^−y8)2,损失值等于每个元素相应差值的平方和。
L ( y ^ , y ) = { ( y 1 ^ − y 1 ) 2 + ( y 2 ^ − y 2 ) 2 + . . . + ( y 8 ^ − y 8 ) 2 i f y 1 = 1 ( y 1 ^ − y 1 ) 2 i f y 1 = 0 L(\hat{y},y)=\begin{cases} (\hat{y_{1}}-y_{1})^{2}+(\hat{y_{2}}-y_{2})^{2}+...+(\hat{y_{8}}-y_{8})^{2} \quad if y_{1}=1\\ (\hat{y_{1}}-y_{1})^{2} \quad if y_{1}=0 \end{cases} L(y^,y)={(y1^−y1)2+(y2^−y2)2+...+(y8^−y8)2ify1=1(y1^−y1)2ify1=0
y
1
y_{1}
y1是y向量这8个数里的第1个数,在这里就是
p
c
p_{c}
pc。
如果图片中存在定位对象,那么
y
1
=
p
c
=
1
y_{1} =p_{c}= 1
y1=pc=1。
如果图片中不存在定位对象,那么
y
1
=
p
c
=
0
y_{1} =p_{c}= 0
y1=pc=0。
为了让大家了解对象定位的细节,这里我用平方误差简化了描述过程。实际应用中,你可以对 c 1 c_{1} c1、 c 2 c_{2} c2、 c 3 c_{3} c3和softmax激活函数应用对数损失函数,并输出其中一个元素值,通常对边界框坐标应用平方差或类似方法,对 p c p_{c} pc应用逻辑回归函数,甚至采用平方预测误差也是可以的。
- Landmark detection 特征点检测
神经网络可以通过输出图片上特征点的
(
x
,
y
)
(x,y)
(x,y)坐标来实现对目标特征的识别,我们看几个例子。
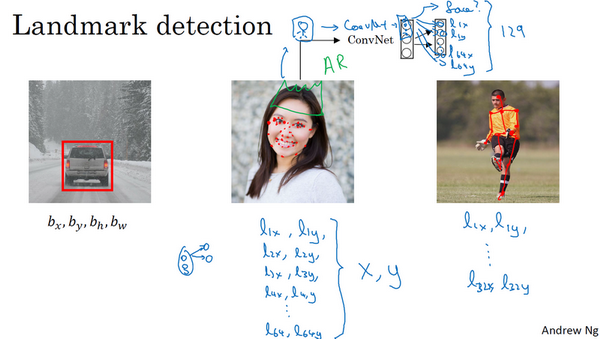
例子1:输出脸部特征点。
1+64×2=129个输出值,即y向量有129个输出值,第一个输出值是1 或 0,1表示有人脸,0表示没有人脸。后续64×2=128个输出值,是64个坐标值,
(
l
1
x
,
l
1
y
)
(l_{1x},l_{1y})
(l1x,l1y)、
(
l
2
x
,
l
2
y
)
(l_{2x},l_{2y})
(l2x,l2y)……
(
l
64
x
,
l
64
y
)
(l_{64x},l_{64y})
(l64x,l64y),比如
(
l
1
x
,
l
1
y
)
(l_{1x},l_{1y})
(l1x,l1y)表示左眼外眼角,
(
l
2
x
,
l
2
y
)
(l_{2x},l_{2y})
(l2x,l2y)表示左眼内眼角。
应用:AR(增强现实)过滤器,比如拍照片时,给头上加个皇冠。
例子2:人体姿态检测。
(
l
1
x
,
l
1
y
)
(l_{1x},l_{1y})
(l1x,l1y)、
(
l
2
x
,
l
2
y
)
(l_{2x},l_{2y})
(l2x,l2y)……
(
l
32
x
,
l
32
y
)
(l_{32x},l_{32y})
(l32x,l32y),坐标值是一些关键特征点,如胸部的中点,左肩,左肘,腰等等。
由于是监督学习,所以训练集是无数标注出特征点坐标值的图片。
要明确一点,特征点1的特性在所有图片中必须保持一致,就好比,特征点1始终是右眼的外眼角,特征点2是右眼的内眼角,特征点3是左眼内眼角,特征点4是左眼外眼角等等。标签在不同的图片中必须保持一致。
- Object detection 目标检测
如何通过卷积网络进行对象检测,采用的是基于滑动窗口的目标检测算法。

假如你想构建一个汽车检测算法,步骤是,首先创建一个标签训练集,就是x表示一张图片,y表示这张图片中有没有汽车。然后,用标签训练集来训练卷积网络。训练完这个卷积网络,就可以用它来,在测试集上,实现滑动窗口目标检测,具体步骤如下。

先用一个小的矩形,把矩形放到图像上,把矩形内的图像输入分类算法,得知矩形内的图像是否有汽车,然后根据步长(可以自己调整大小),滑动矩形到另一个位置,把矩形内的图像输入分类算法,得知矩形内的图像是否有汽车,以此类推,直到矩形走遍整个图像。然后增大矩形,再次使矩形走遍整个图像。然后增大矩形,再次使矩形走遍整个图像。
不论汽车在图片的什么位置,总有一个窗口可以检测到它。
Sliding windows detection 滑动窗口检测 缺点:computational cost 计算成本太高。
【我的想法】:滑动窗口和卷积类似,应该也能用卷积的公式。
卷积公式:输入图像n×n×
n
C
n_{C}
nC * 过滤器f×f×
n
C
n_{C}
nC ——》 输出图像
⌊
(
n
+
2
p
−
f
s
+
1
)
⌋
×
⌊
(
n
+
2
p
−
f
s
+
1
)
⌋
×
n
C
′
⌊(\frac{n+2p-f}{s}+1)⌋ × ⌊(\frac{n+2p-f}{s}+1)⌋ × n_{C}'
⌊(sn+2p−f+1)⌋×⌊(sn+2p−f+1)⌋×nC′
盲猜 滑动窗口公式:输入图像n×n * 过滤器f×f ——》 输出图像
⌊
(
n
−
f
s
+
1
)
⌋
×
⌊
(
n
−
f
s
+
1
)
⌋
⌊(\frac{n-f}{s}+1)⌋ × ⌊(\frac{n-f}{s}+1)⌋
⌊(sn−f+1)⌋×⌊(sn−f+1)⌋
- Convolutional implementation of sliding windows 滑动窗口的卷积实现
把神经网络的全连接层转化成卷积层,用卷积层代替全连接层的过程:
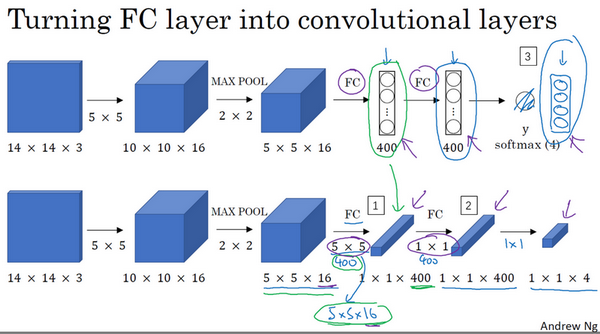
滑动窗口对象检测算法的卷积实现。
参考论文:Sermanet, Pierre, et al. “OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks.” Eprint Arxiv (2013). 作者:Pierre Sermanet,David Eigen,张翔,Michael Mathieu,Rob Fergus,Yann LeCun。
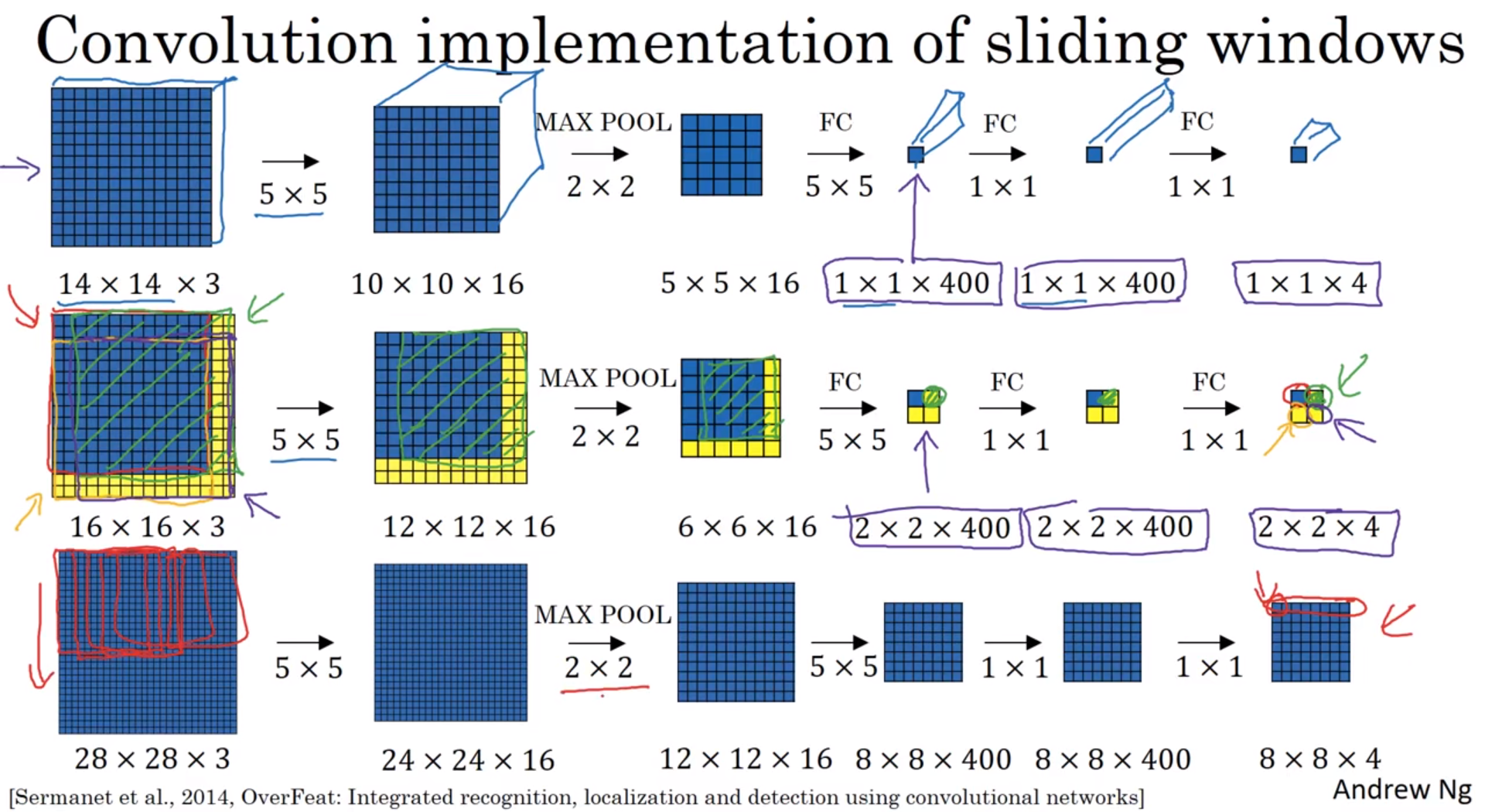
上图的第二行(有黄边的那行),输入层16×16×3,输出层2×2×4。
如果在这个16×16×3的图片上运行滑动窗口算法,滑动窗口大小14×14,步长为2,会在16×16×3的图片的左上、右上、左下、右下,4个方向,裁剪出4个14×14×3的图片。然后对这4个14×14×3的图片,分别执行卷积算法,就和上图第一行那样。
在输出层(2×2×4)这4个子方块中,左上角方块是输入层(16×16×3)左上部分14×14的输出(红色箭头标识),右上角方块是输入层右上部分14×14的输出(绿色箭头标识),左下角方块是输入层左下部分14×14的输出(橘色箭头标识),右下角方块是输入层右下部分14×14输出(紫色箭头标识),也就是这个14×14区域经过卷积网络处理后的结果。
可以把16×16×3整张图,直接执行卷积算法,得到的2×2×4的4个方块,刚好对应,对截图出的4个14×14×3的子图执行卷积算法的结果,就像上图第二行那样。
因为最大池化参数为2,相当于以大小为2的步幅在原始图片上应用滑动窗口算法。
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算,就像这里我们看到的这4个14×14的方块一样。
上图第三行,输入层28×28×3,输出层8×8×4,是一样的例子。如果在这个28×28×3的图片上运行滑动窗口算法,滑动窗口大小14×14,步长为2,会裁剪出8×8=64个子图,刚好对应输出层8×8×4的8×8=64个子方块。
因为最大池化参数为2,相当于以大小为2的步幅在原始图片上应用滑动窗口算法。
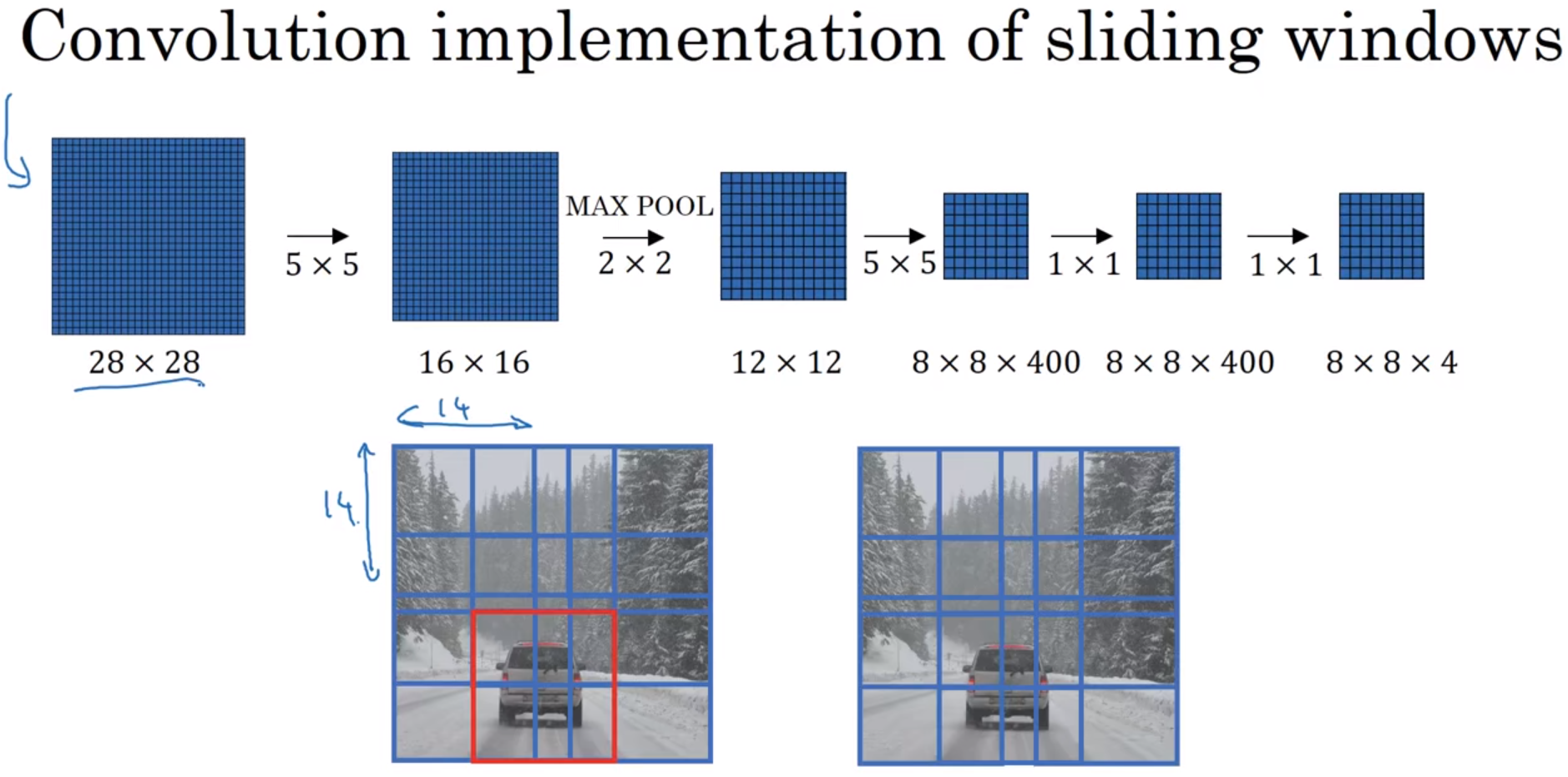
Convolution implementation of sliding windows 滑动窗口的卷积实现。
上图中,第二行(有汽车的两张图)。按照第一行的卷积方法,输入层28×28×3,输出层8×8×4。步长为2(因为卷积方法中,最大池化参数为2),滑动窗口大小14×14(已知输入层,已知输出层,已知步长,带入滑动窗口公式,可以求出滑动窗口大小)。
左图是滑动窗口算法,裁剪出8×8=64张子图,分别进行卷积算法,得到8×8=64个结果,每个结果即该子图有没有汽车。
右图是滑动窗口算法的卷积实现,对28×28的整张图,应用卷积算法,得到8×8的输出层,即8×8=64个结果,每个结果即该子图有没有汽车。一次卷积得到所有预测值。
滑动窗口的卷积实现,缺点:边界框的位置可能不够准确。
【我的想法:
对整张图应用一次卷积,效果相当于,使用某个固定的步长+某个固定的滑动窗口大小,进行滑动窗口算法。如果要使用不同的步长、不同的滑动窗口大小,进行滑动窗口算法,那么需要对整张图进行多次卷积,而且卷积的步长参数、卷积步骤中的过滤器大小等,需要改变。
所以,对整张图应用一次卷积,会使得边界框,不够大、不够小,只框选进了目标的一部分,有“边界框的位置可能不够准确”问题。
而,如果对整张图进行多次卷积,其效果相当于,不同大小的方框+不同的步长,用滑动窗口算法,不会有“边界框的位置可能不够准确”问题,但依然会有“计算成本太高”问题。】
- Bounding box predictions 。边界框预测
解决上节课“边界框的位置可能不够准确”的问题。
其中一个能得到更精准边界框的算法是YOLO算法,YOLO(You only look once)意思是你只看一次。
提出YOLO的论文:Redmon, Joseph, et al. “You Only Look Once: Unified, Real-Time Object Detection.” (2015):779-788. 。作者:Joseph Redmon,Santosh Divvala,Ross Girshick和Ali Farhadi。
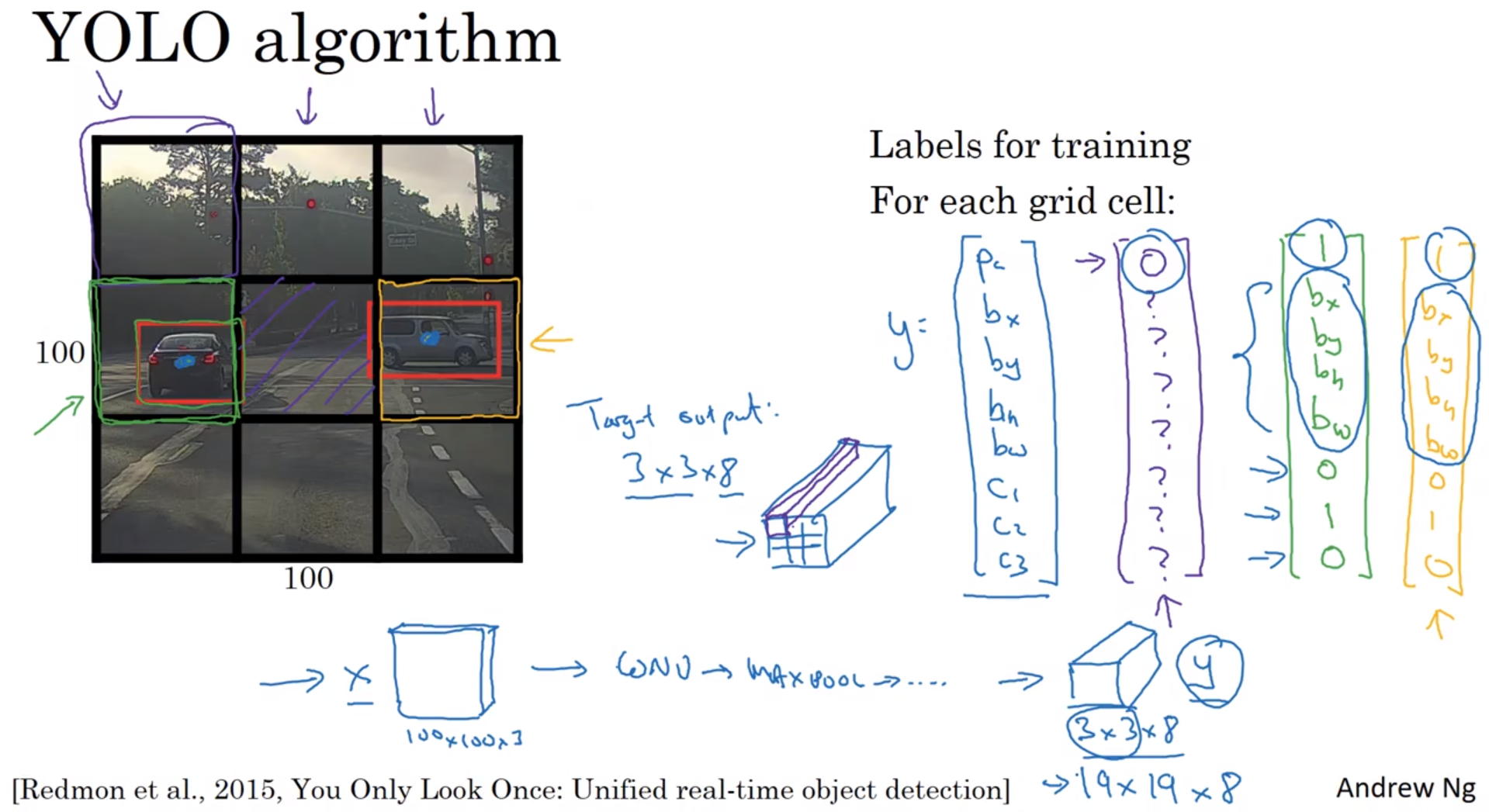
举例:
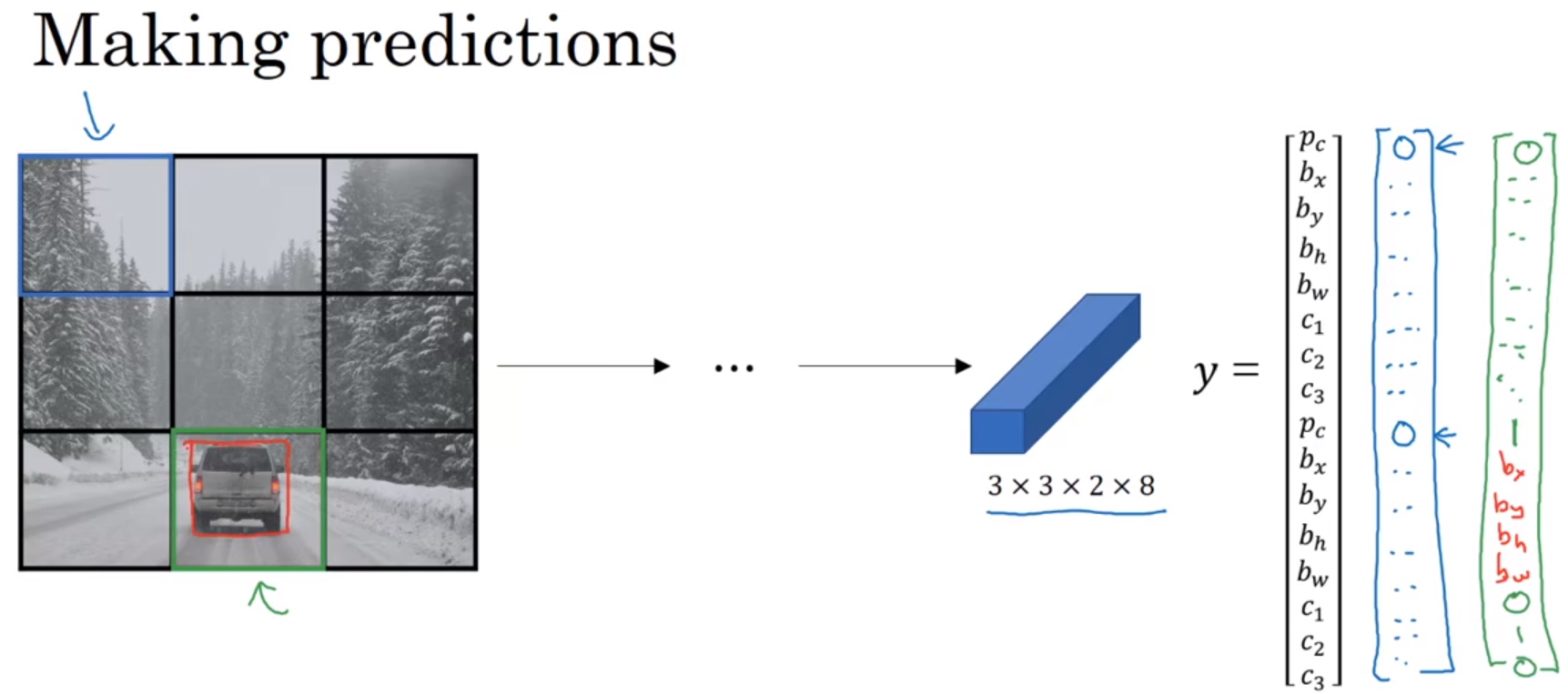
输入图像是100×100的,然后在图像上放一个3×3网格(实际实现时会用更精细的网格,可能是19×19)。采用图像分类和定位算法,本周第一个视频中介绍过的,逐一应用在图像的9个格子中。具体一点,对于9个格子中的每一个指定一个标签
y
y
y,
y
y
y是8维的。
y
=
[
p
c
b
x
b
y
b
h
b
w
c
1
c
2
c
3
]
y= \begin{bmatrix} p_{c} \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \\ c_{1} \\ c_{2} \\ c_{3} \end{bmatrix}
y=
pcbxbybhbwc1c2c3
对于每个格子,你都有一个8维向量
y
y
y,因为这里是3×3=9的网格,所以目标输出尺寸是3×3×8。你就可以从输出知道,3×3=9个网格,每个网格里是否有对象(是否是背景)(
p
c
p_{c}
pc),有哪种对象(行人、汽车、摩托车)(
c
1
、
c
2
、
c
3
c_{1}、c_{2}、c_{3}
c1、c2、c3),并框选出对象(
b
x
、
b
y
、
b
h
、
b
w
b_{x}、b_{y}、b_{h}、b_{w}
bx、by、bh、bw)。
只要每个格子中对象数目没有超过1个,这个算法应该是没问题的。一个格子中存在多个对象的问题,我们稍后再讨论。
把对象分配到一个格子的过程是,你观察对象的中点,然后将这个对象分配到其中点所在的格子,所以即使对象可以横跨多个格子,也只会被分配到9个格子其中之一,就是3×3网络的其中一个格子。
首先这和图像分类和定位算法非常像,我们在本周第一节课讲过的,就是它显式地输出边界框坐标,边界框可以具有任意宽高比,能输出更精确的坐标,不会受到滑动窗口分类器的步长大小限制。
其次,这是一个卷积实现,你并没有在3×3=9网格上跑9次算法。相反,这是单次卷积实现。你使用了一个卷积网络,在处理这3×3计算中很多计算步骤是共享的,所以这个算法效率很高。
因为这是一个卷积实现,实际上它的运行速度非常快,可以达到实时识别。
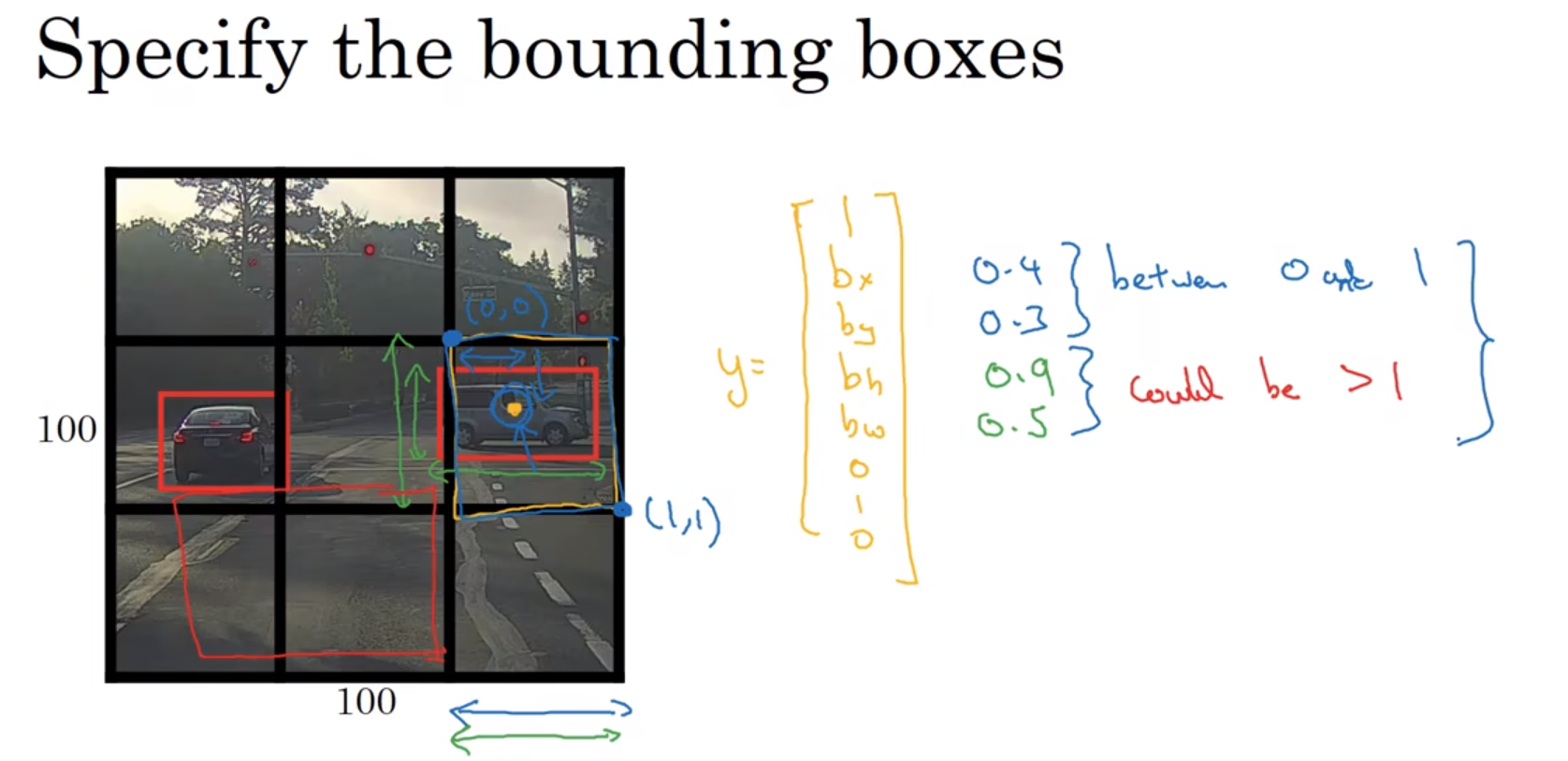
小细节:如何编码这些边界框
b
x
b_{x}
bx、
b
y
b_{y}
by、
b
h
b_{h}
bh、
b
w
b_{w}
bw。
以上图 右边的车+框住这个车的中心点的黑色方格(3×3网格中的一个) 举例:
y
=
[
1
b
x
b
y
b
h
b
w
0
1
0
]
y= \begin{bmatrix} 1 \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \\ 0 \\ 1 \\ 0 \end{bmatrix}
y=
1bxbybhbw010
在YOLO算法中,对于这个黑色方格,我们约定左上这个点是
(
0
,
0
)
(0,0)
(0,0),然后右下这个点是
(
1
,
1
)
(1,1)
(1,1)。
b
x
b_{x}
bx 和
b
y
b_{y}
by 必须在0和1之间,
b
h
b_{h}
bh 和
b
w
b_{w}
bw 必须大于等于0,可以大于1。比如这张图,
(
b
x
,
b
y
)
=
(
0.4
,
0.3
)
(b_{x},b_{y})=(0.4,0.3)
(bx,by)=(0.4,0.3),位于黑色方格的坐标系内,
b
h
=
0.9
b_{h}=0.9
bh=0.9、
b
w
=
0.5
b_{w}=0.5
bw=0.5。可见,算法拟合的边界框(红色方框),中心点在黑色方格内,边界未必在黑色方格内。
指定边界框的方式有很多,上方讲的只是其中一种,是管用的。如果你去读YOLO的研究论文,YOLO的研究工作有其他参数化的方式,可能效果会更好,但也更复杂。
YOLO论文是相对难度较高,看不懂很正常。资深研究员也会看不懂其中的一些细节,需要看原代码,或者询问作者。
【我的想法:
边界框(红色方框):算法生成的框,框选目标物体。
黑色网格(方格):图片被3×3黑色网格分割成一个个方格。】
- Intersection over union 交并比

Intersection over union 交并比:IoU,用于评价对象定位算法 Evaluating object localization。
I
o
U
=
预测边框与真实边框的交集的面积
预测边框与真实边框的并集的面积
IoU=\frac{预测边框与真实边框的交集的面积}{预测边框与真实边框的并集的面积}
IoU=预测边框与真实边框的并集的面积预测边框与真实边框的交集的面积 。
一般约定,在计算机检测任务中,0.5是阈值,用来判断预测的边界框是否正确。如果
l
o
U
≥
0.5
loU≥0.5
loU≥0.5,就说检测正确。这个值是人为规定的,如果你想更严格一点,可以把阈值定为0.6或更高。
loU越高,边界框越精确。
如果预测边界框和实际边界框完美重叠,loU就是1,因为交集就等于并集。
More generally, IoU is a measure of the overlap between two bounding boxes.
更一般地,IoU是两个边界框之间重叠的度量。
- Non-max suppression 非极大值抑制

如上图。
输出结果的大小:19×19×5。网格大小是19×19,每个网格输出5个数字,
p
c
p_{c}
pc表示当前网格是汽车(要识别的物体)的概率,
b
x
、
b
y
、
b
h
、
b
w
b_{x}、b_{y}、b_{h}、b_{w}
bx、by、bh、bw是框选物体的红框。
Each output prediction is 每个输出预测为:
y
=
[
p
c
b
x
b
y
b
h
b
w
]
y= \begin{bmatrix} p_{c} \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \end{bmatrix}
y=
pcbxbybhbw
Non-max suppression algorithm 非极大值抑制算法:
Discard all boxes with $p_{c}≤0.6$
While there are any remaining boxes:
Pick the box with the largest $p_{c}$ .
Output that as a prediction.
Discard any remaining box with IoU≥0.5 with the box output in the previous step.
Non-max suppression algorithm 非极大值抑制算法-翻译版:
丢弃所有$p_{c}≤0.6$的方框
While 当还有其他方框的时候:
选择$p_{c}$最大的方框。
输出它作为一个预测。
丢弃任何这样的剩余盒子:与上一步输出的盒子,IoU≥0.5。
在这张幻灯片中,我只介绍了算法检测单个对象的情况,如果你尝试同时检测三个对象,比如说行人、汽车、摩托,那么输出向量就会有三个额外的分量。事实证明,正确的做法是独立进行三次非极大值抑制。
- Anchor Boxes 锚箱
anchor box 使用原因:1、让一个格子检测出多个对象。2、让你的学习算法能够更有针对性,特别是如果你的数据集有一些很高很瘦的对象,比如说行人,还有像汽车这样很宽的对象,这样你的算法就能更有针对性的处理。
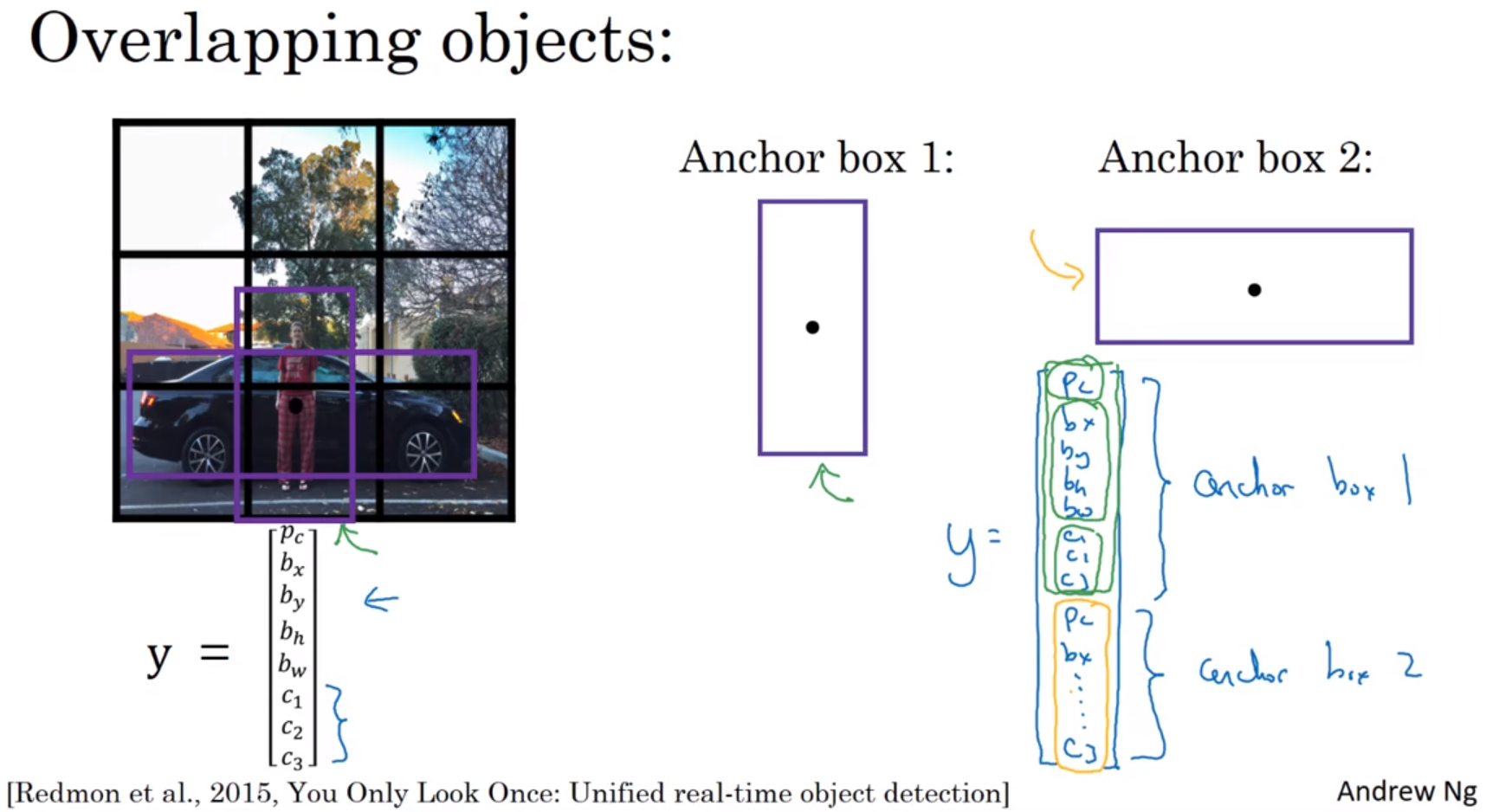

Anchor box algorithm 锚箱算法:
Previously:
Each object in training image is assigned to to grid cell that contains that object's midpoint.
With two anchor boxes:
Each object in training image is assigned to grid cell that contains object's midpoint and anchor box for the grid cell with highest IoU. (grid cell, anchor box)
Anchor box algorithm 锚箱算法-翻译版:
以前:
训练图像中的每个对象,被分配到包含该对象中点的网格单元中。
有两个锚箱后:
训练图像中的每个对象,被分配到包含该对象中点的网格单元中,也被分配到与边界框有最高IoU的锚箱中。(网格单元、锚箱)
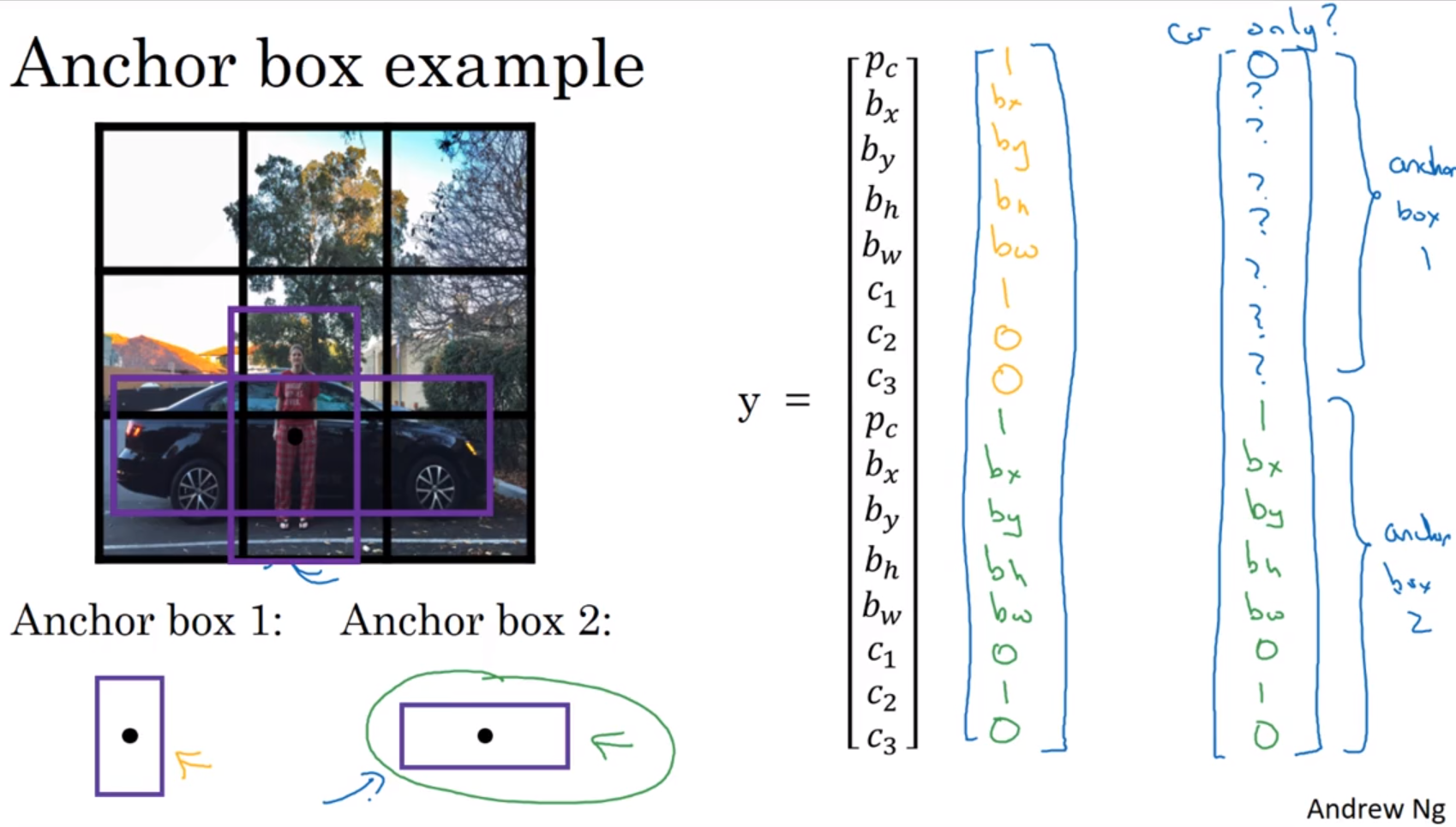
y = [ p c b x b y b h b w c 1 c 2 c 3 p c b x b y b h b w c 1 c 2 c 3 ] y= \begin{bmatrix} p_{c} \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \\ c_{1} \\ c_{2} \\ c_{3} \\ p_{c} \\ b_{x} \\ b_{y} \\ b_{h} \\ b_{w} \\ c_{1} \\ c_{2} \\ c_{3} \end{bmatrix} y= pcbxbybhbwc1c2c3pcbxbybhbwc1c2c3
对于每个格子,你都有一个16维向量 y y y,因为这里是3×3=9的网格,所以目标输出尺寸是3×3×16=3×3×(2×8)。你就可以从输出知道,3×3=9个网格,每个网格里有2个anchor box(每个网格里有2个anchor box,能让一个格子中检测出两个不同形状的对象)。每个网格里是否有anchor box 1 (或anchor box 2)的形状匹配的对象( p c p_{c} pc),有哪种对象(行人、汽车、摩托车)( c 1 、 c 2 、 c 3 c_{1}、c_{2}、c_{3} c1、c2、c3),并框选出对象( b x 、 b y 、 b h 、 b w b_{x}、b_{y}、b_{h}、b_{w} bx、by、bh、bw)。
Anchor box算法处理不好的2种情况:1、有2个anchor box,在把输入图片用网格分割后,某一个网格单元里,有3个对象。2、你设定了2个锚箱,在把输入图片用网格分割后,2个对象都分配到一个格子中,而且它们的anchor box形状也一样
k-means算法:自动选择anchor box的方法。来自后期的YOLO论文。
- Putting it together: YOLO algorithm 。组合起来:YOLO算法
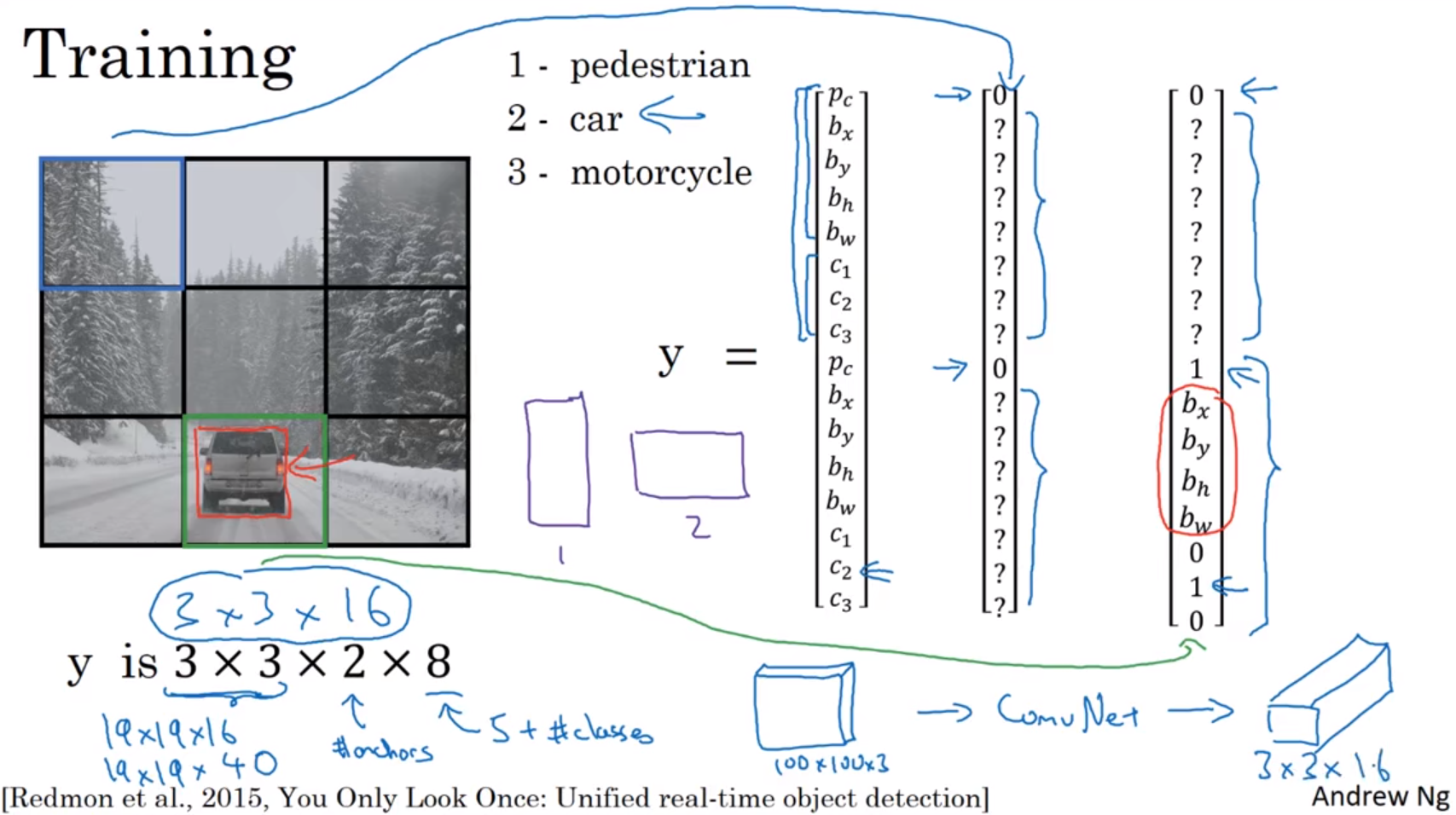

Outputting the non-max supressed outputs:
1、For each grid call, get 2 predicted bounding boxes.
2、Get rid of low probability predictions.
3、For each class(pedestrian, car, motorcycle) use non-max suppression to generate final predictions.
运行非极大值抑制的过程:
1、对于每个网格调用,获取2个预测边界框。
2、摆脱低概率预测。
3、对于每个类别(行人、汽车、摩托车),使用非最大值抑制生成最终预测。
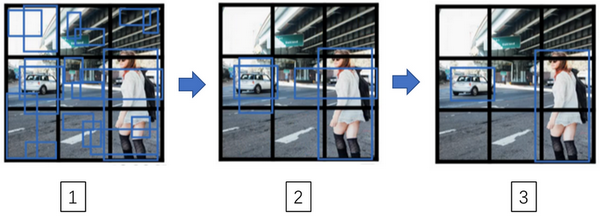
这就是运行非极大值抑制的过程。如果你使用两个anchor box,那么9个格子中,每个都有两个预测的边界框(编号1)。接下来你抛弃概率很低的预测边界框(编号2)。
最后,如果你有三个对象检测类别,你希望检测行人、汽车、摩托车,那么你要做的是,对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框,用非极大值抑制来处理行人类别,用非极大值抑制处理车子类别,用非极大值抑制处理摩托车类别,运行三次来得到最终的预测结果(编号3)。
- Region proposals (Optional) 。候选区域(选修)

R-CNN: region with CNN , region with convolutional neural network. 区域卷积神经网络。这里不再针对每个滑动窗运行检测算法,而是使用图像分割算法,只选择一些非背景的(有对象存在的)窗口,叫做Region proposals候选区域,在少数窗口上运行卷积网络分类器。这样,要处理的位置会少的多,可以减少卷积网络分类器的运行时间。
segmentation algorithm 图像分割:对象周围绘制一个多边形,并为该对象的每个像素进行着色。比如:图片上一只猫,图像分割后,猫变成了一个猫形状的色块。

R-CNN: Propose regions. Classify proposed regions one at a time. Output label + bounding box.
Fast R-CNN: Propose regions. Use convolution implementation of sliding windows to classify all the proposed regions.
Faster R-CNN: Use convolutional network to propose regions.
R-CNN:候选区域。挨个对候选区域运行一次分类算法,输出标签+边界框。
快速R-CNN:候选区域。使用滑动窗口的卷积实现,对所有候选区域进行分类。
更快的R-CNN:使用卷积网络得到候选区域。即:使用卷积神经网络代替了传统的分割算法,来获得候选区域色块。这比Fast R-CNN快得多。
速度快慢:YOLO > Faster R-CNN > Fast R-CNN > R-CNN 。
R-CNN论文:用于精确目标检测和语义分割的丰富特征层次 Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation | IEEE Conference Publication | IEEE Xplore
Fast R-CNN论文:Fast R-CNN | IEEE Conference Publication | IEEE Xplore
Faster R-CNN论文:Faster R-CNN:使用区域提议网络实现实时目标检测:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | IEEE Journals & Magazine | IEEE Xplore
Faster R-CNN的python版本代码:rbgirshick/py-faster-rcnn: Faster R-CNN (Python implementation) – see https://github.com/ShaoqingRen/faster_rcnn for the official MATLAB version
吴恩达:我把这个视频定为可选视频是因为我用到候选区域这一系列算法的频率没有那么高。候选区域是一个有趣的想法,但这个方法需要两步,首先得到候选区域,然后再分类,相比之下,能够一步做完,类似于YOLO或者你只看一次(You only look once)这个算法,在我看来,是长远而言更有希望的方向。
本周其他论文链接:
你只看一次:统一的,实时的对象检测。You Only Look Once: Unified, Real-Time Object Detection | IEEE Conference Publication | IEEE Xplore
YOLO9000: 更好,更快,更强。YOLO9000: Better, Faster, Stronger | IEEE Conference Publication | IEEE Xplore
YOLO_v2的Tensorflow代码:allanzelener/YAD2K: YAD2K: Yet Another Darknet 2 Keras
YOLO官网:YOLO: Real-Time Object Detection
- 基于U-Net的语义分割(Semantic segmentation with U-Net)
语义分割 semantic segmentation、实例分割 instance segmentation、全景分割 panoptic segmentation 的区别:
语义分割:仅考虑像素的类别,不分割同一类的不同实体。
实例分割:分割不同的实体,仅考虑前景物体。
全景分割:背景仅考虑类别,前景需要区分实体。

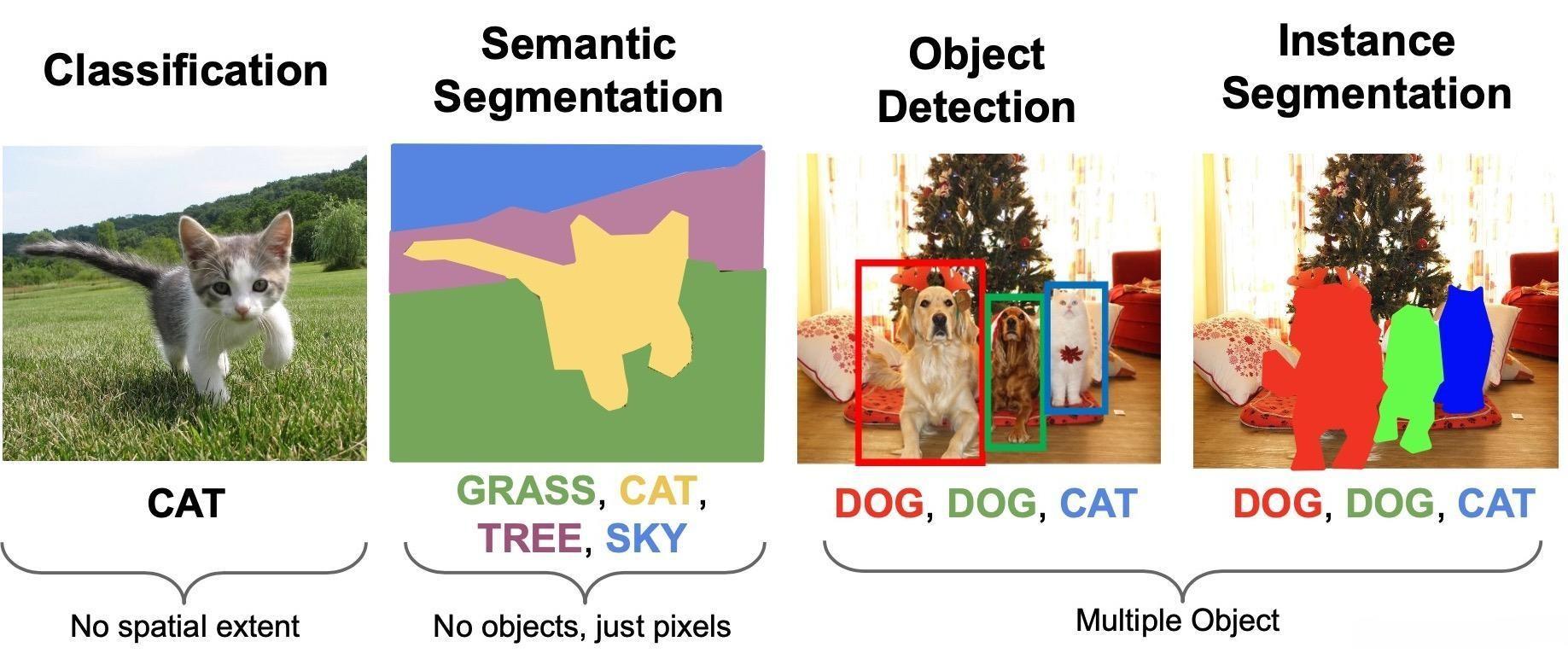
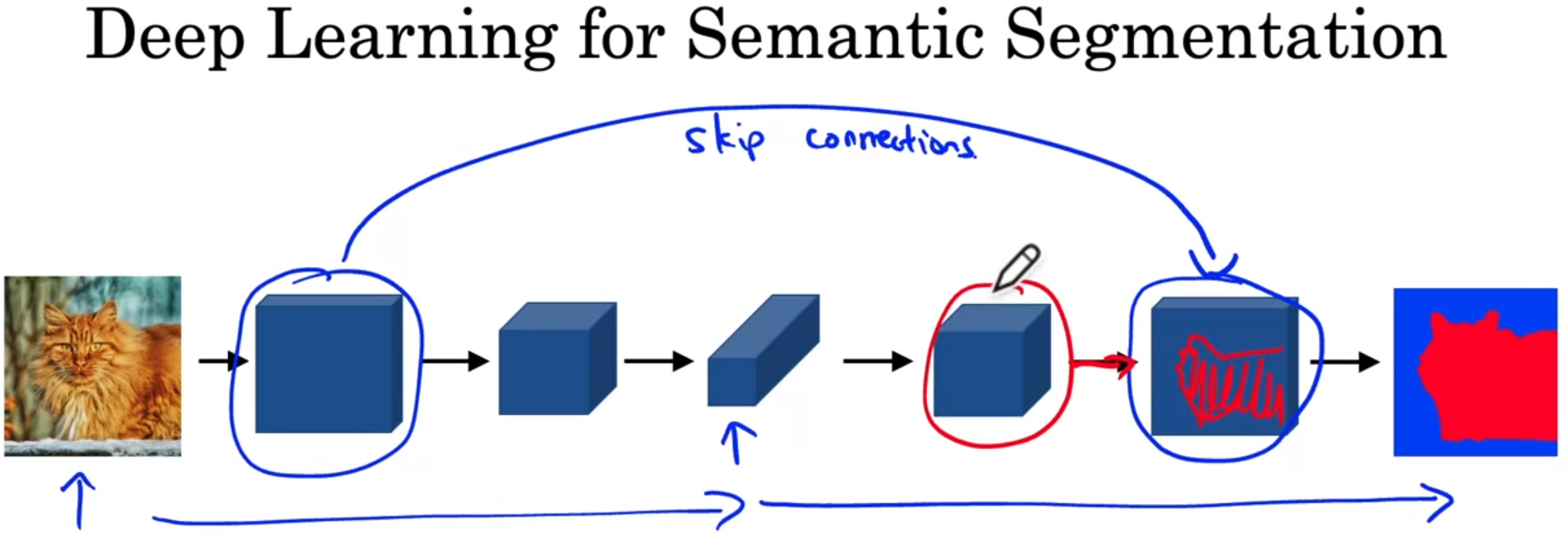
semantic segmentation:语义分割。绘制检测到的对象周围的轮廓,以便你确切知道哪些像素属于对象,哪些像素不属于。输入一张图片,语义分割会把每一类物体准确地用同一种颜色表示。

语义分割的用途之一是,一些自动驾驶汽车团队使用它来弄清楚哪些像素可以安全驶过,因为它们表示一个可行驶的表面。
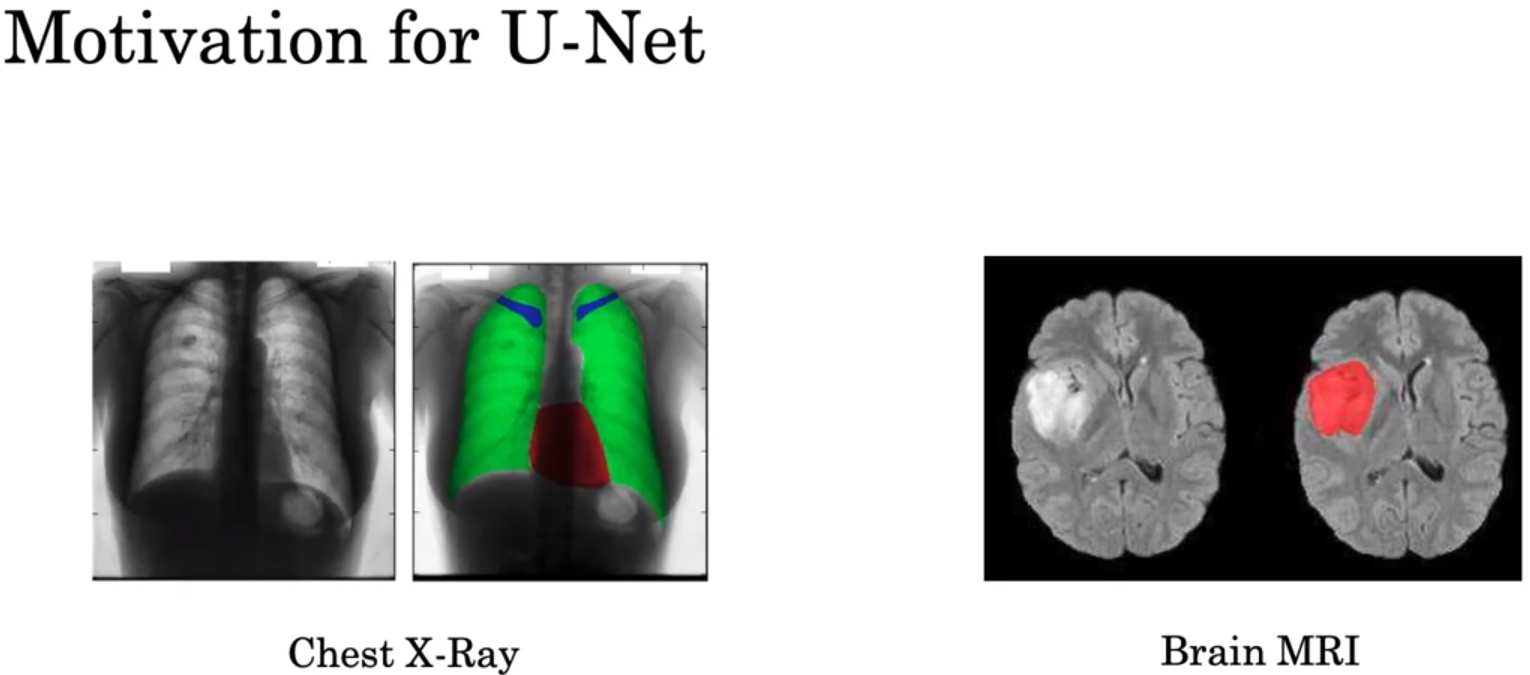
上方两幅图分别来自论文:
Fully Convolutional Architectures for Multiclass Segmentation in Chest Radiographs | IEEE Journals & Magazine | IEEE Xplore
Automatic Brain Tumor Detection and Segmentation Using U-Net Based Fully Convolutional Networks

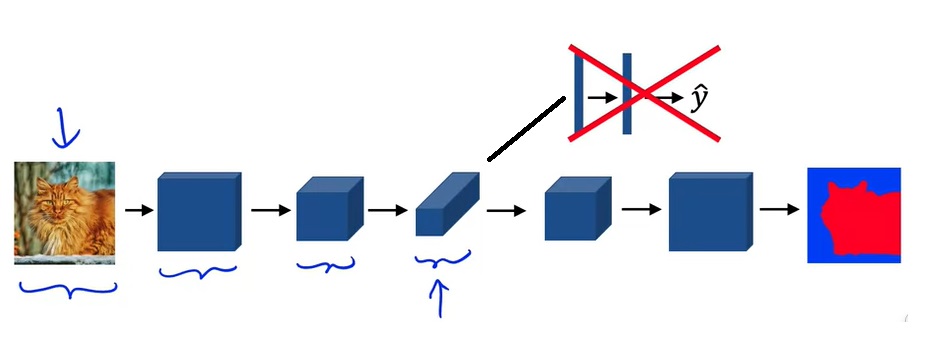
上图,上方分支是图像分类的过程。下方分支是语义分割的过程。
语义分割的过程中,图像通过卷积,从长宽变小到长宽变大。通过卷积使图片长宽变大这个过程,就是转置卷积。
image recognition / object recognition: 图像识别,图像分类。二分类、多分类。一张图片,里面只有一个物体,里面是猫是狗还是老鼠。比如手写数字识别。
transpose convolution 转置卷积。
- 转置卷积(Transpose Convolutions)
反卷积/逆卷积(Deconvolution)、转置卷积(Transpose Convolution)、Fractional Convolution / Fractionally Strided Convolution 是同一操作的不同名字。反卷积是和卷积概念相对应,转置卷积则和卷积操作中的稀疏矩阵相对应,Fractional Convolution的名称则对应于步长大于1的卷积。这种操作能扩大特征图。
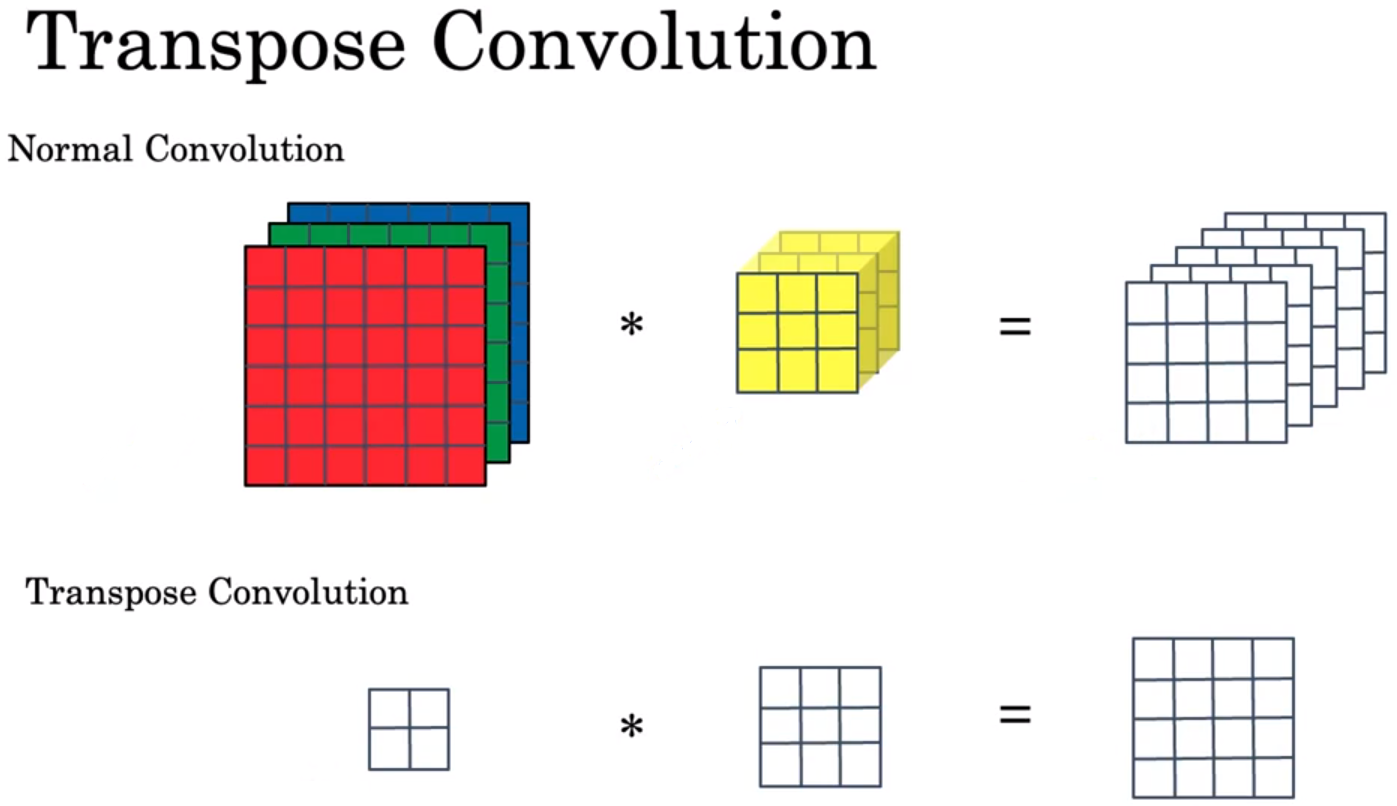
上图是卷积与转置卷积。
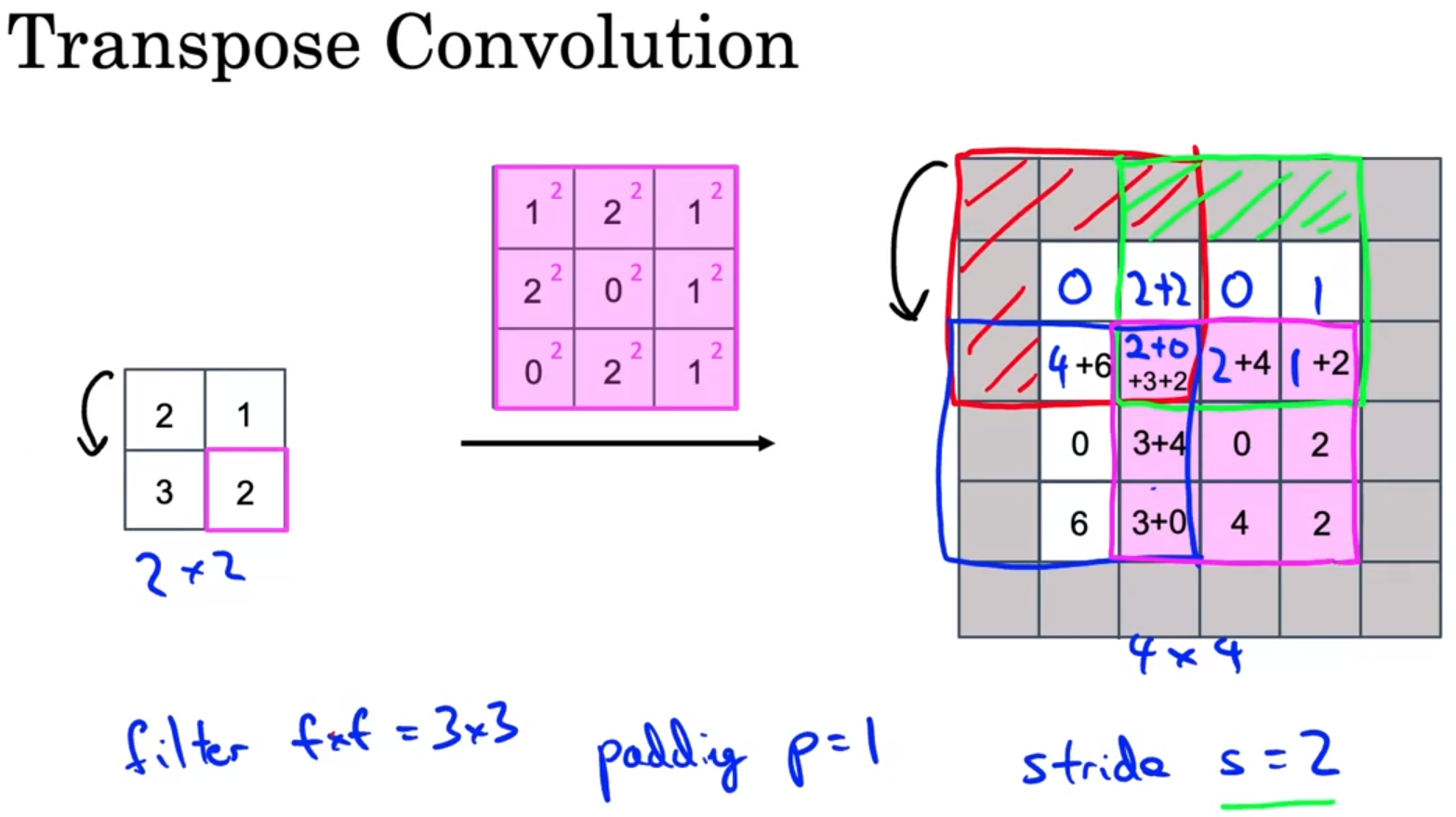
转置卷积并不能恢复原卷积的输入,它仅仅是将卷积的步骤反向进行而已。比如上图左中右三个方框,卷积是右×中=》左,转置卷积是左×中=》右。
转置卷积的具体步骤如下:
图来自:吴恩达《深度学习专项》笔记(十二):目标检测与语义分割简介 (YOLO, U-Net)_大局观选手周弈帆的博客-CSDN博客
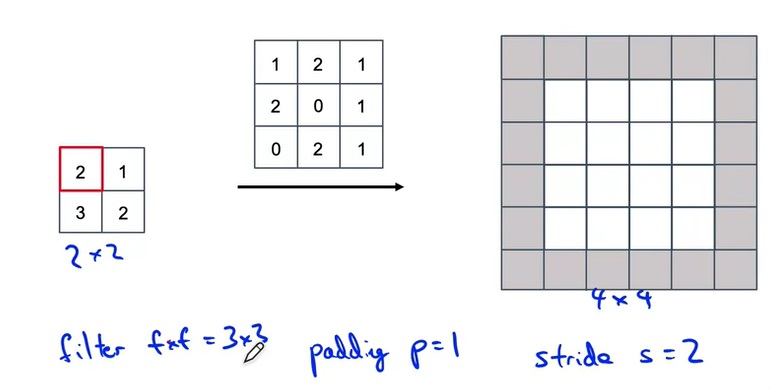
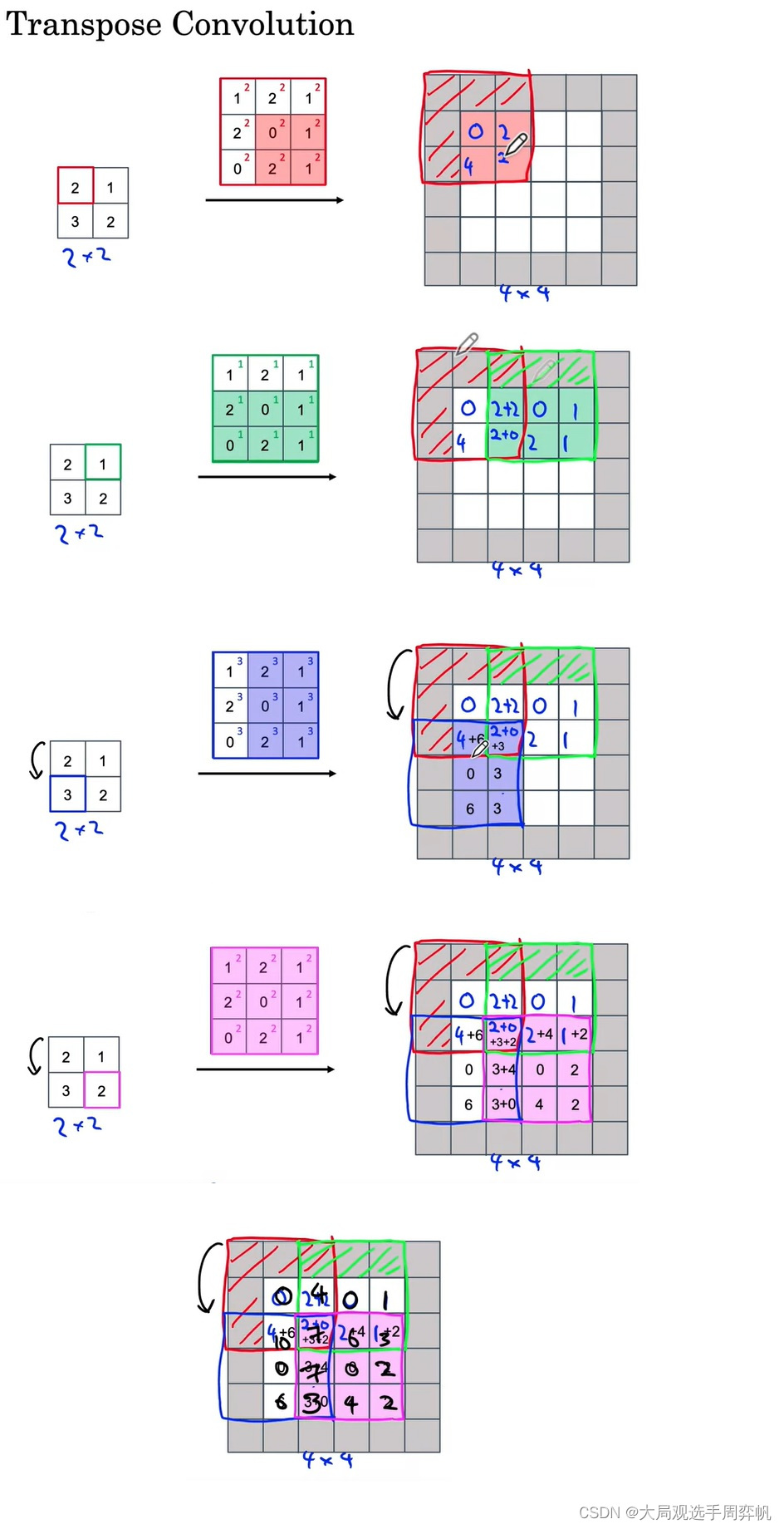
看到另一种计算转置卷积的方法:
卷积系列:Deconvolution(反卷积)/Transpose Convolution(转置卷积)/Fractional convolution_反卷积英文_burning_planet的博客-CSDN博客
反卷积是一种特殊的正向卷积,通俗的讲,就是原矩阵补0+卷积。先按照一定的比例通过补0来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。
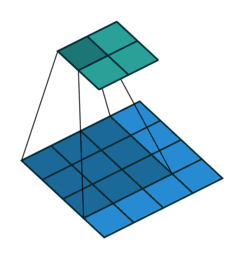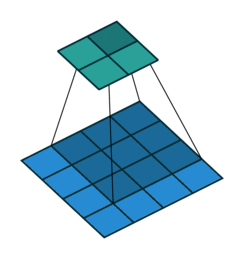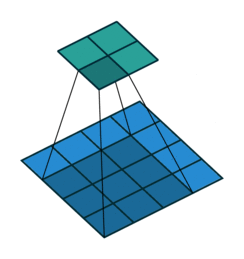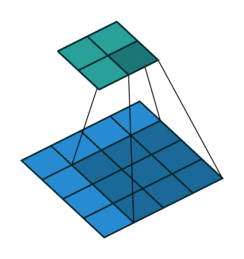
|
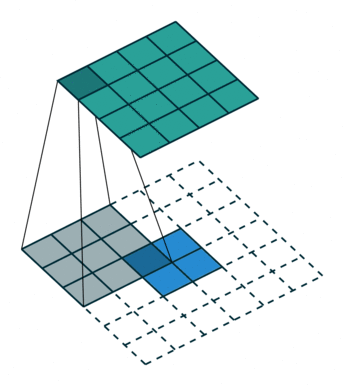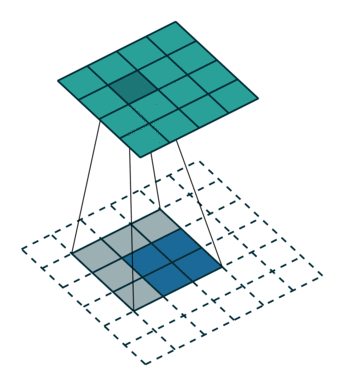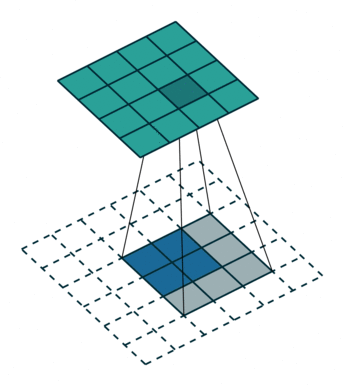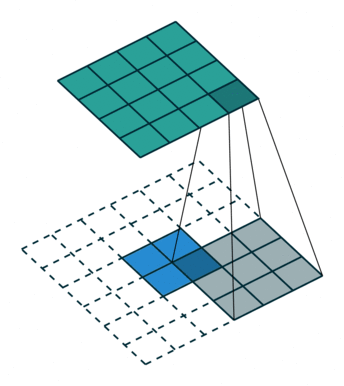
|
上图,阴影是卷积核,蓝色是原图,绿色是卷积后的图。
下图,阴影是卷积核,蓝色是原图,绿色是卷积后的图。
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个: 使得图像符合显示区域的大小; 生成对应图像的缩略图。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
卷积可以下采样,反卷积可以上采样。
- U-Net架构直觉(U-Net Architecture intuition)
U-Net除了对图像使用了先缩小再放大的卷积外,还使用了一种跳连(不是ResNet中残差连接的跳连,而是把两份输入拼接在了一起)。这样,在反卷积层中,不仅有来自上一层的输入,还有来自前面相同大小的正卷积的结果。这样做的好处是,后半部分的网络既能获得前一个卷积的抽象、高级(比如类别)的输入,又能获得前半部分网络中具体,低级的特征(比如形状)。这样,后面的层能够更好地生成输出。
- U-Net架构(U-Net Architecture)
提出U-Net的论文:U-Net: Convolutional Networks for Biomedical Image Segmentation | SpringerLink 。
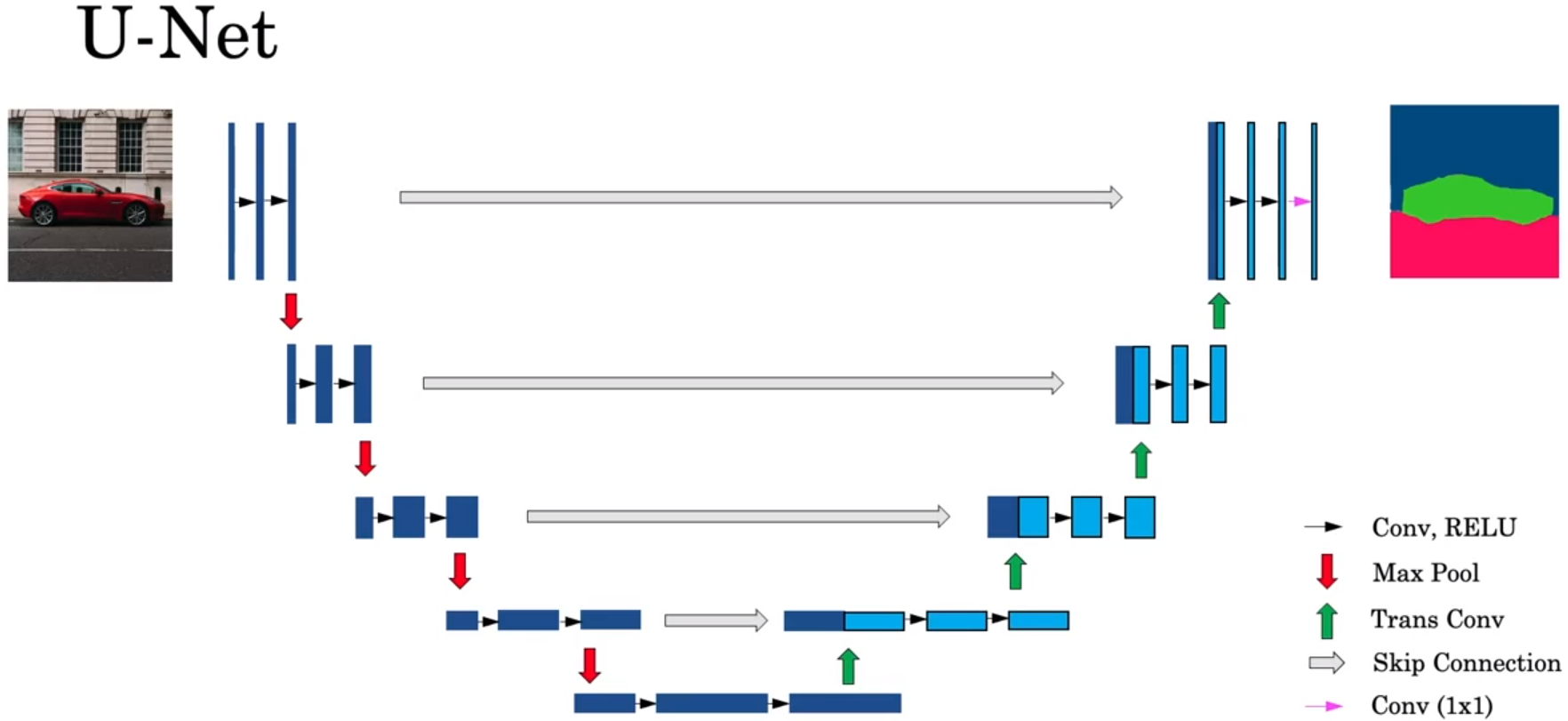
U-Net具体的结构如上图。
上图,每个灰箭头Skip Connection 的右边第一个方块,是两个部分(浅蓝色部分+深蓝色部分)的合并,浅蓝色的部分是由转置卷积Transpose Convolutions 得到的,深蓝色的部分把 灰箭头Skip Connection 的左边 从右到左的第一个方块复制过来得到的。
上图,输入图片是h×w×3(height高度 × width宽度 × RGB这3个通道),输出是h×w×
n
c
l
a
s
s
e
s
n_{classes}
nclasses。如果你要识别3个类,比如车、马路、建筑,那么
n
c
l
a
s
s
e
s
n_{classes}
nclasses=3。
输入图片的h×w上的每个像素,会得到
n
c
l
a
s
s
e
s
n_{classes}
nclasses维的向量,向量中的数字表明,该像素来自这些不同类别的可能性有多大。举例:某像素得到的3维向量是,[车,马路,建筑]=[0.9,0.1,0.1],提取argmax后,该像素是车。
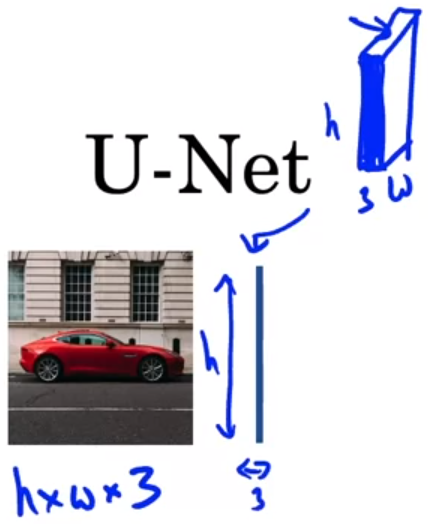
离图片最近的竖线,其实就指代图片,只不过把图片侧过来放。比如,图片是h×w×3(height高度 × width宽度 × RGB这3个通道),那通过竖线只能看到h×3。其他竖线也是只能看到h×通道数。
第四周:Face recognition 人脸识别
- 什么是人脸识别?(What is face recognition?)
第五课:序列模型(Sequence Models)
第五课:序列模型(Sequence Models) 这部分,都没有做课后实验和作业。
第四课:卷积神经网络(Convolutional Neural Networks) 这部分做了2018版本的课后实验和作业,但2021版本加了U-Net,没做U-Net的实验(如果有的话)。
第一周:循环神经网络(Recurrent Neural Networks)【序列模型、语言模型+序列生成、对新序列采样。RNN、GRU、LSTM、双向RNN、深度RNN】
- 为什么选择序列模型?(Why Sequence Models?)
序列模型的应用领域:语音识别、音乐生成、处理情感分类、DNA序列分析、机器翻译、视频行为识别、命名实体识别。

- 数学符号(Notation)
x
(
i
)
<
t
>
x^{ (i)<t> }
x(i)<t>:第
i
i
i个训练样本的输入序列中第 t 个元素。
T
x
(
i
)
T_{x}^{(i)}
Tx(i):第
i
i
i个训练样本的输入序列长度。
y
(
i
)
<
t
>
y^{ (i)<t> }
y(i)<t>:第
i
i
i个训练样本的输出序列中第 t 个元素。
T
y
(
i
)
T_{y}^{(i)}
Ty(i):第
i
i
i个训练样本的输出序列的长度。
NLP: Natural Language Processing, 自然语言处理
一个命名实体识别(识别句子中的每个单词是否是名字)的例子:
x: Harry Potter and Herminoe Granger invented a new spell。
y: 110110000。
该例子中:
T
x
(
i
)
T_{x}^{(i)}
Tx(i)=
T
y
(
i
)
T_{y}^{(i)}
Ty(i)=9。
Harry 是
x
(
i
)
<
1
>
x^{ (i)<1> }
x(i)<1>,spell是
x
(
i
)
<
9
>
x^{ (i)<9> }
x(i)<9> 。
110110000是从
y
(
i
)
<
1
>
y^{ (i)<1> }
y(i)<1>到
y
(
i
)
<
9
>
y^{ (i)<9> }
y(i)<9> 。中间第t个数为
y
(
i
)
<
t
>
y^{ (i)<t> }
y(i)<t>。
怎样表示一个序列里单独的单词?
定义一个词典,用one-hot表示法来表示词典里的每个单词。
词典 = [ a 。。。 H a r r y 。。。 z u l u ] 词典= \begin{bmatrix} a \\ 。。。\\ Harry \\ 。。。\\ zulu \end{bmatrix} 词典= a。。。Harry。。。zulu
在词典中Harry是第4075个单词,在输入序列中
x
<
1
>
x^{<1>}
x<1>表示Harry这个单词,它就是一个第4075行是1,其余值都是0的向量,因为那是Harry在这个词典里的位置。
x
<
1
>
=
H
a
r
r
y
=
[
0
。。。
1
。。。
0
]
x^{<1>}=Harry= \begin{bmatrix} 0 \\ 。。。\\ 1 \\ 。。。\\ 0 \end{bmatrix}
x<1>=Harry=
0。。。1。。。0
<UNK>:对于不在你词典中的单词,创建一个新的标记,也就是一个叫做Unknow Word的伪造单词,用<UNK>作为标记,来表示不在词表中的单词。
- 循环神经网络模型(Recurrent Neural Network Model)
一个命名实体识别(识别句子中的每个单词是否是名字)的例子:
x: Harry Potter and Herminoe Granger invented a new spell。
y: 110110000。
为什么不使用标准神经网络?
1、输入和输出数据在不同例子中可以有不同的长度。
2、标准神经网络不共享从文本的不同位置上学到的特征。具体来说,如果神经网络已经学习到了在位置1出现的Harry可能是人名的一部分,那么如果Harry出现在其他位置,比如
x
<
t
>
x^{<t>}
x<t>时,它也能够自动识别其为人名的一部分的话,这就很棒了。
3、
x
<
1
>
x^{<1>}
x<1>……
x
<
t
>
x^{<t>}
x<t>……
x
<
T
x
>
x^{< T_{x}>}
x<Tx> 都是10000维的one-hot向量(词典里有10000个单词,用one-hot表示法表示每个单词),输入层大小=输入单词数✖10000,那么标准神经网络的第一层的权重矩阵就会有着巨量的参数。
循环神经网络(Recurrent Neural Network,RNN)-前向传播:

在时间步t(位置t)上,有公式:
a
<
0
>
=
0
⃗
a^{< 0 >}=\vec{0}
a<0>=0
a
<
t
>
=
g
1
(
W
a
a
a
<
t
−
1
>
+
W
a
x
x
<
t
>
+
b
a
)
a^{< t >} = g_{1}(W_{aa}a^{< t - 1 >} + W_{ax}x^{< t >} + b_{a})
a<t>=g1(Waaa<t−1>+Waxx<t>+ba)
y
^
<
t
>
=
g
2
(
W
y
a
a
<
t
>
+
b
y
)
\hat{y}^{< t >} = g_{2}(W_{ya}a^{< t >} + b_{y})
y^<t>=g2(Wyaa<t>+by)
g
1
g_{1}
g1是tanh / ReLU,tanh是更通常的选择。
g
2
g_{2}
g2是取决于你的输出。比如二分类问题,就用sigmoid,命名实体识别就是二分类问题;比如k分类问题,就用softmax。
矩阵下标的符号约定:第一个下标表示,该矩阵是用来计算什么,第二个下标表示,该矩阵乘以什么。
W
a
a
W_{aa}
Waa:a表示计算a,a表示乘以a。
W
a
x
W_{ax}
Wax:a表示计算a,x表示乘以x。
W
y
a
W_{ya}
Wya:y表示计算y,a表示乘以a。
公式简化为:
a
<
t
>
=
g
(
W
a
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
a
)
a^{<t>} =g( W_{a} [ a^{< t-1 >}, x^{<t>} ] + b_{a} )
a<t>=g(Wa[a<t−1>,x<t>]+ba)
y
^
<
t
>
=
g
(
W
y
a
<
t
>
+
b
y
)
\hat{y}^{< t >} = g(W_{y}a^{< t >} +b_{y})
y^<t>=g(Wya<t>+by)
简化后的下标的符号约定:只有一个下标,下标表示,它是用来计算什么。
W
a
W_{a}
Wa:a表示计算a。
b
a
b_{a}
ba:a表示计算a。
W
y
W_{y}
Wy:y表示计算y。
b
y
b_{y}
by:y表示计算y。
简化步骤:
W
a
[
a
<
t
−
1
>
,
x
<
t
>
]
=
W
a
a
a
<
t
−
1
>
+
W
a
x
x
<
t
>
W_{a} [ a^{< t-1 >}, x^{<t>} ] = W_{aa}a^{< t - 1 >} + W_{ax}x^{< t >}
Wa[a<t−1>,x<t>]=Waaa<t−1>+Waxx<t> 。
W
a
=
[
W
a
a
:
W
a
x
]
W_{a} = [W{aa} : W{ax}]
Wa=[Waa:Wax],
W
a
W_{a}
Wa是将矩阵
W
a
a
W_{aa}
Waa和矩阵
W
a
x
W_{{ax}}
Wax水平并列放置。
[
a
<
t
−
1
>
,
x
<
t
>
]
[ a^{< t-1 >}, x^{<t>} ]
[a<t−1>,x<t>]是将这两个向量一上一下堆在一起,
[
a
<
t
−
1
>
x
<
t
>
]
\begin{bmatrix}a^{<t-1>} \\ x^{<t>} \end{bmatrix}
[a<t−1>x<t>]。
[
W
a
a
:
W
a
x
]
[W{aa} : W{ax}]
[Waa:Wax] ✖
[
a
<
t
−
1
>
x
<
t
>
]
\begin{bmatrix}a^{<t-1>} \\ x^{<t>} \end{bmatrix}
[a<t−1>x<t>] =
W
a
a
a
<
t
−
1
>
+
W
a
x
x
<
t
>
W_{aa}a^{< t - 1 >} + W_{ax}x^{< t >}
Waaa<t−1>+Waxx<t> 。
W
y
a
W_{ya}
Wya记为
W
y
W_{y}
Wy。
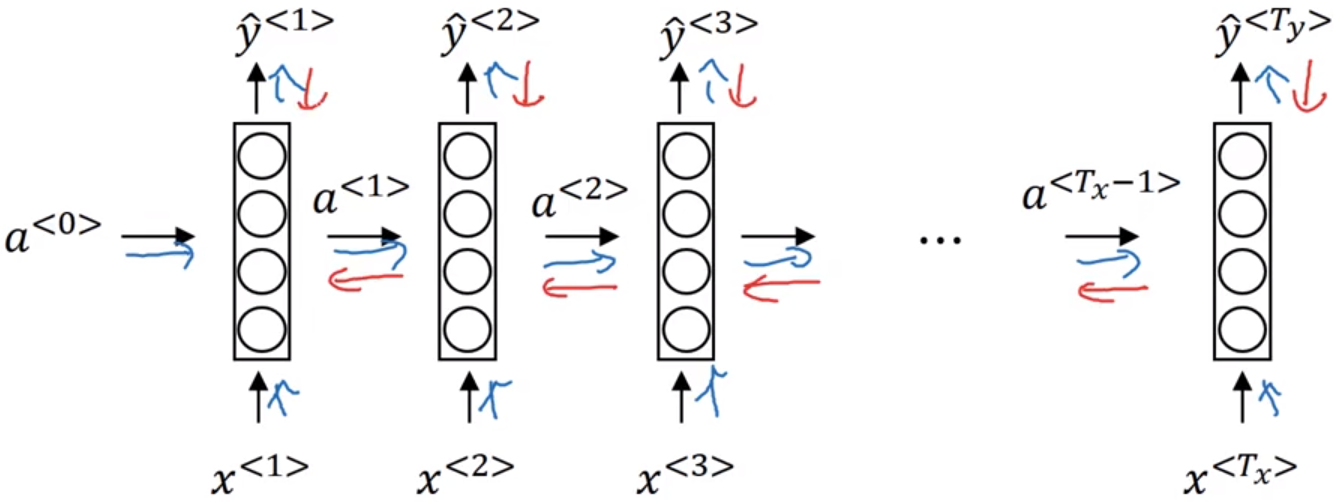
- 通过时间的反向传播(Backpropagation through time)
下图是RNN的前向传播(蓝色箭头)和反向传播(红色箭头)。
标准逻辑回归损失函数 (逻辑回归就是分类),也叫交叉熵损失函数(Cross Entropy Loss):
在时间步t(位置t)上的损失函数:
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
=
−
y
<
t
>
log
y
^
<
t
>
−
(
1
−
y
<
t
>
)
log
(
1
−
y
^
<
t
>
)
L^{<t>}( \hat{y}^{<t>}, y^{<t>} ) = - y^{<t>} \log \hat{y}^{<t>} - ( 1- y^{<t>} ) \log(1-\hat{y}^{<t>} )
L<t>(y^<t>,y<t>)=−y<t>logy^<t>−(1−y<t>)log(1−y^<t>)
整个序列的损失函数:
L
(
y
^
,
y
)
=
∑
t
=
1
T
x
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
L(\hat{y}, y) = \sum_{t = 1}^{T_{x}} L^{< t >} ( \hat{y}^{< t >},y^{< t >} )
L(y^,y)=∑t=1TxL<t>(y^<t>,y<t>)
RNN反向传播的名字:通过(穿越)时间反向传播(backpropagation through time)。
- 不同类型的循环神经网络(Different types of RNNs)
下图,从左到右5张图:
(1)一对一。没有 RNN 的普通处理模式,就是一个小型的标准的神经网络,从固定大小的输入到固定大小的输出(例如图像分类)。
(2)一对多。序列输出(例如图像字幕获取图像并输出句子,例如音乐生成或者序列生成)。
(3)多对一。序列输入(例如,将给定句子分类为表达积极或消极情绪的情绪分析)。
(4)多对多。序列输入和序列输出(例如机器翻译:RNN 读取英语句子,然后输出法语句子,英语句子单词数 ≠ 法语句子单词数,词汇不是一一对应)。
(5)多对多。同步序列输入和输出(例如,对视频的每一帧进行视频分类,例如,命名实体识别)。

- 语言模型和序列生成(Language model and sequence generation)
P(The apple and pair salad) =
3.2
×
1
0
−
13
3.2 × 10^{-13}
3.2×10−13
P(The apple and pear salad) =
5.7
×
1
0
−
10
5.7 × 10^{-10}
5.7×10−10
P(句子)=
P
(
y
<
1
>
,
y
<
2
>
,
。。。
,
y
<
T
y
>
)
P( y^{<1>}, y^{<2>}, 。。。, y^{<T_{y}>} )
P(y<1>,y<2>,。。。,y<Ty>)
语言模型所做的就是,它会告诉你某个特定的句子它出现的概率是多少。
语言模型做的最基本工作就是输入一个句子,准确地说是一个文本序列(
y
<
1
>
,
y
<
2
>
,
。。。
,
y
<
T
y
>
y^{<1>}, y^{<2>}, 。。。, y^{<T_{y}>}
y<1>,y<2>,。。。,y<Ty>。对于语言模型来说,用y来表示这些序列比用x来表示要更好。),然后语言模型会估计某个句子序列中各个单词出现的可能性。
那么如何建立一个语言模型呢?分为以下3步:
1、对应语言的文本语料库(corpus)。
2、句子标记化。即:建立一个字典,然后将每个单词都转换成对应的one-hot向量,也就是字典中的索引。
<EOS>:放在句子结尾用于表示句子结束。可以把该标记附加到训练集中每一个句子的结尾。字典中可以加上<EOS>。
<UNK>:用该标记,来表示不在词典中的单词。字典中必须加上<UNK>。
句号等标点符号:如果你想把句号或者其他符号也当作标志,那么你可以将句号也加入你的字典中。也可以不把标点符号加入字典。
3、使用RNN来构建文本序列的概率模型。
x
<
t
>
=
y
<
t
−
1
>
x^{<t>} = y^{<t-1>}
x<t>=y<t−1> 。
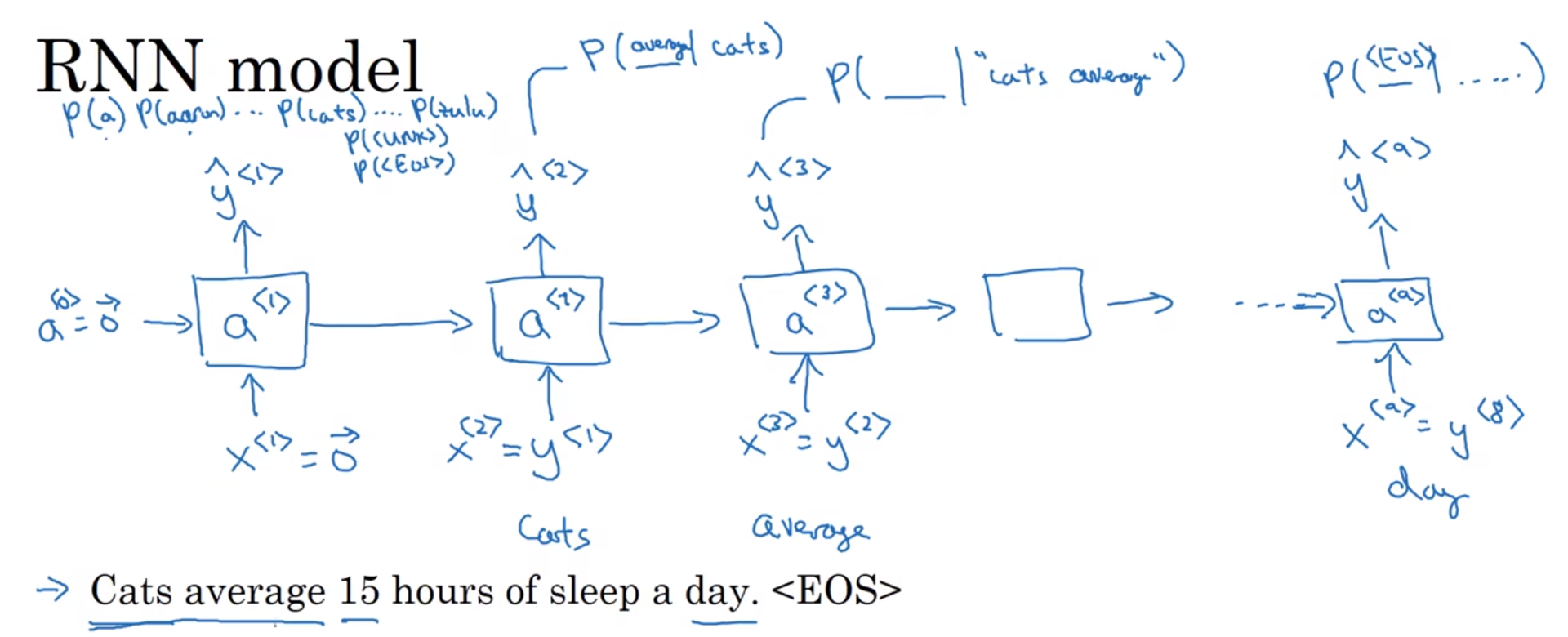
句子 Cats average 15 hours of sleep a day.<EOS> 有9个单词(这里在字典里包含<EOS>,不包含句号,所以认为该句子有9个词),所以该句子的RNN网络中,有9个输入x和9个输出
y
^
\hat{y}
y^ 。
时间步1:通过一个softmax层来预测字典中的任意单词会是第1个词的概率。输入
x
<
1
>
x^{<1>}
x<1>,输出
y
^
<
1
>
\hat{y}^{<1>}
y^<1> 。
时间步2:计算出第2个词会是什么。输入
x
<
2
>
=
y
<
1
>
x^{<2>} = y^{<1>}
x<2>=y<1>,输出
y
^
<
2
>
\hat{y}^{<2>}
y^<2> 。
时间步3:计算出第3个词会是什么。输入
x
<
3
>
=
y
<
2
>
x^{<3>} = y^{<2>}
x<3>=y<2>,输出
y
^
<
3
>
\hat{y}^{<3>}
y^<3> 。
以此类推。
softmax损失函数:
L
(
y
^
<
t
>
,
y
<
t
>
)
=
−
∑
i
y
i
<
t
>
log
y
^
i
<
t
>
L( \hat{y}^{<t>}, y^{<t>}) = - \sum_{i} y_{i}^{<t>} \log \hat{y}_{i}^{<t>}
L(y^<t>,y<t>)=−∑iyi<t>logy^i<t> ,i 我猜是字典里的单词数,因为
y
^
<
t
>
\hat{y}^{<t>}
y^<t> 输出的是,字典大小这么多个概率值,即:句子中下一个单词,可能是字典中第 i 个词的概率。
总体损失函数:
L
=
∑
t
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
L = \sum_{t} L^{< t >}( \hat{y}^{<t>}, y^{<t>} )
L=∑tL<t>(y^<t>,y<t>) 。就是把所有单个预测的损失函数都相加起来。
假如一个新句子,它只包含3个词(
y
<
1
>
,
y
<
2
>
,
y
<
3
>
y^{<1>}, y^{<2>}, y^{<3>}
y<1>,y<2>,y<3> ),那么:
P(句子) =
P
(
y
<
1
>
,
y
<
2
>
,
y
<
3
>
)
P(y^{<1>}, y^{<2>}, y^{<3>})
P(y<1>,y<2>,y<3>) =
P
(
y
<
1
>
)
P
(
y
<
2
>
∣
y
<
1
>
)
P
(
y
<
3
>
∣
y
<
1
>
,
y
<
2
>
)
P(y^{<1>}) P(y^{<2>} | y^{<1>}) P(y^{<3>} | y^{<1>}, y^{<2>})
P(y<1>)P(y<2>∣y<1>)P(y<3>∣y<1>,y<2>) 。
该句子的RNN网络有3个输入x和3个输出
y
^
\hat{y}
y^,这3个相乘的P,就是3个
y
^
\hat{y}
y^ 中的对应单词的概率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









