







目录
spark主要是由Scala语言开发,为了方便和其他系统集成而不引入scala相关依赖,部分实现使用Java语言开发,例如External Shuffle Service等。总体来说,Spark是由JVM语言实现,会运行在JVM中。然而,Spark除了提供Scala/Java开发接口外,还提供了Python、R等语言的开发接口,为了保证Spark核心实现的独立性,Spark仅在外围做包装,实现对不同语言的开发支持,本文主要介绍Python Spark的实现原理,剖析pyspark应用程序是如何运行起来的。
知晓pyspark的原理才能更好的了解程序运行的机制以及后续如果程序出错了我们也能够第一时间反应过来是哪里出现问题。
一、spark原理
我们知道spark是用scala开发的,而scala又是基于Java语言开发的,那么spark的底层架构就是Java语言开发的。如果要使用python来进行与java之间通信转换,那必然需要通过JVM来转换。我们先看原理构建图:
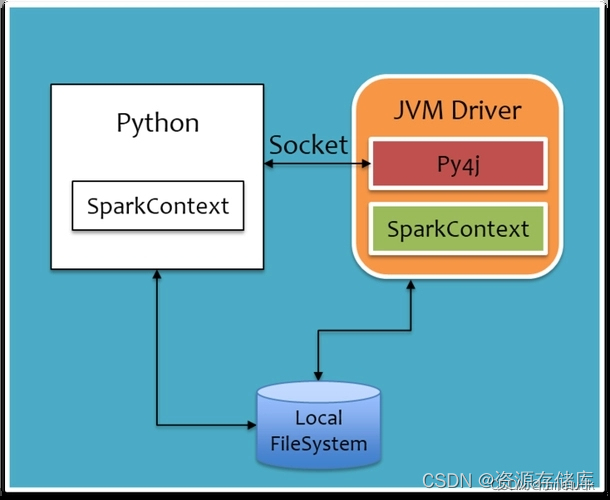
从图中我们发现在python环境中我们编写的程序将以SparkContext的形式存在,Pythpn通过于Py4j建立Socket通信,通过Py4j实现在Python中调用Java的方法,将我们编写成python的SpakrContext对象通过Py4j,最终在JVM Driver中实例化为Scala的SparkContext。
那么我们再从Spark集群运行机制来看:
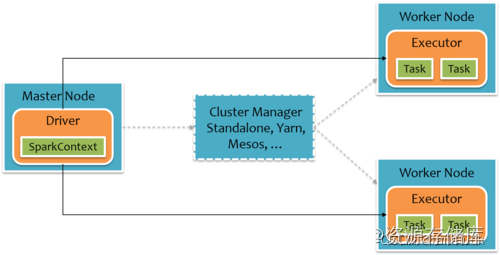
主节点运行Spark任务是通过SparkContext传递任务分发到各个从节点,标橙色的方框就为JVM。通过JVM中间语言与其他从节点的JVM进行通信。之后Executor通信结束之后下发Task进行执行。
此时我们再把python在每个主从节点展示出来:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1113
1113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











